大家好,我是直奔標杆!专注Java开发者AI转型干货分享,从零基础到实战落地,和大家一起稳步进阶,今天带来《Spring AI 零基础到实战》系列的第二十五课,也是个人知识库实战的第四篇------RAG的来源追溯,帮大家解决AI回答"无凭无据"的核心痛点~
回顾上一节课(第二十四课),我们已经基于Spring AI内置组件解耦了RAG检索链路,还通过SSE与响应式编程,实现了多轮流式对话接口,相信很多小伙伴已经把基础功能跑通了。但做过企业级产品的朋友都知道,demo能跑通不代表能落地,其中一个关键问题就是:AI的回答没有"依据"。
举个很实际的例子:当用户在知识库中询问"年假与调休的合并规则",大模型能输出一套完整的解答,但用户凭什么相信这是公司规定的原话,而不是大模型基于概率"瞎编"的幻觉?这也是企业级RAG与个人demo的核心区别之一------来源可追溯(Citations)。
所谓来源追溯,就是在AI回答的末尾添加类似1、2的上标,点击就能跳转到对应的原始文档,让AI的每一句话都有迹可循、有据可查。本节课,我们就摒弃纯文本提取流,深入ChatResponse底层数据结构,从SSE数据流中剥离RAG命中文档的元数据,真正实现"字字有出处,句句有回音",一起把知识库做得更专业、更靠谱!
本节学习目标(建议收藏,对照实操)
-
底层透视:吃透ChatResponse的数据结构,搞懂RAG检索到的文档是如何被Spring AI框架挂载的,打破"黑盒"认知;
-
末端帧劫持:放弃便捷但不灵活的字符串流封装,掌握Flux<ChatResponse>对象流的高阶转换技巧,掌控数据流主动权;
-
架构契约:在SSE协议生命周期的末端(EOF),优雅追加JSON格式元数据,制定前后端联调标准,筑牢溯源防线。
核心原理:大模型响应元数据(Metadata)的作用
很多小伙伴可能会疑惑,RAG检索到的文档,用完之后就丢了吗?其实不然------当QuestionAnswerAdvisor从向量库中检索出高相关度的文档切片(比如4块)并喂给大模型时,会将这些文档(包含我们入库时添加的source_filename等标签)打包成"装箱单",附着在大模型的最终响应体中。
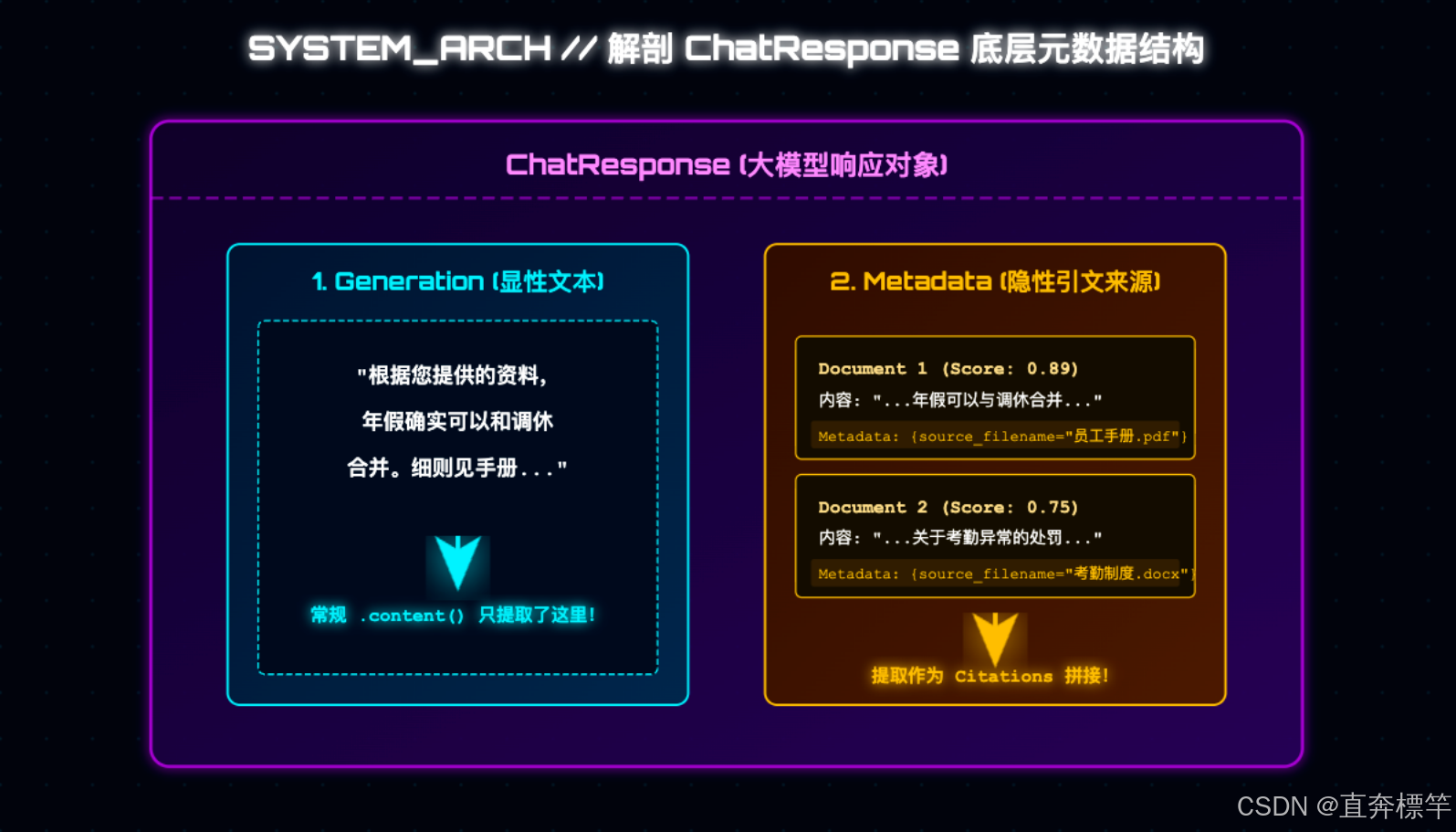
简单来说,这些元数据就是AI回答的"身份证",里面包含了回答所参考的原始文档名称、页码等关键信息,我们要做的,就是把这些信息提取出来,以规范的格式返回给前端。
实操核心:重构ChatServiceImpl,提取引文信息
上一节课,我们为了快速跑通流式响应,使用了chatClient.prompt()....stream().content()这个语法糖,虽然简单,但代价很大------它会底层提取字符串,直接丢弃包含参考文献、Token消耗等关键信息的ChatResponse对象。
要实现来源追溯,必须舍弃这个便捷的语法糖,改用.chatResponse()获取原始的Flux<ChatResponse>流,手动拦截、拆解数据流。这里给大家明确我们的设计思路,前后端配合更顺畅:
-
流的前段:只推送大模型生成的正文(比如data: 调休相关规定为...),保持纯净,不影响前端打字机效果;
-
流的末尾(EOF):当大模型推理结束后,追加一段用特殊标记包裹的JSON数据(格式示例:CITATIONS_START{"sources":"手册.pdf"}CITATIONS_END),前端检测到标记后,即可解析并渲染为引用卡片。
下面直接上核心代码(ChatServiceImpl.java重构),关键步骤都加了注释,大家可以直接复制实操,遇到问题欢迎在评论区交流:
java
public class ChatServiceImpl implements ChatService {
/** 1. 制定前后端溯源契约,约定特殊标记,避免解析冲突 */
private static final String CITATIONS_START = "[CITATIONS_START]";
private static final String CITATIONS_END = "[CITATIONS_END]";
public Flux<String> streamChatWithCitations(String chatId, String message) {
// 核心修改:获取原始ChatResponse流,并添加缓存,避免重复调用大模型
Flux<ChatResponse> responseFlux = this.chatClient.prompt()
// 此处省略上节课的prompt构建逻辑,保持不变
// 切换为chatResponse(),获取完整响应对象,而非仅字符串
.chatResponse()
.cache();
// 2. 提取大模型生成的正文流,用于前端打字机展示
Flux<String> textFlux = responseFlux.map(chatClientResponse -> {
return chatClientResponse.chatResponse().getResult().getOutput().getText();
});
// 3. 提取元数据,在流末尾追加溯源信息
Flux<String> citationsFlux = responseFlux.last()
.mapNotNull(this::extractCitationsFromResponse) // 提取溯源信息
.filter(c -> !c.isEmpty()) // 过滤空数据,避免无效推送
.flux();
// 合并正文流和溯源流,先后推送给前端
return Flux.concat(textFlux, citationsFlux);
}
/**
* 核心工具方法:从ChatResponse元数据中提取RAG命中文档的来源信息
* 关键说明:QuestionAnswerAdvisor会在流结束时,将检索到的Document列表挂载到response的Metadata中
* 挂载的key固定为QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS
*/
private String extractCitationsFromResponse(ChatClientResponse chatClientResponse) {
// 1. 从响应上下文获取RAG检索到的文档列表
Object documentsObj = chatClientResponse.context()
.get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS);
// 此处省略非空判断(实际项目中需添加,避免空指针)
List<Object> docs = (List<Object>) documentsObj;
// 2. 按文件名聚合页码,保证页码有序、去重(用TreeSet实现)
Map<String, TreeSet<Object>> filePageMap = new LinkedHashMap<>();
for (Object obj : docs) {
if (obj instanceof Document doc) {
// 获取文档文件名(入库时注入的source_filename标签)
String filename = (String) doc.getMetadata().get("source_filename");
if (filename == null) continue; // 跳过无文件名的文档
// 不存在则创建新的TreeSet,保证页码有序
filePageMap.computeIfAbsent(filename, k -> new TreeSet<>());
// 获取页码(仅PDF文件有,由PagePdfDocumentReader注入)
Object pageObj = doc.getMetadata().get("page_number");
if (pageObj != null) {
filePageMap.get(filename).add(pageObj);
}
}
}
// 3. 构造结构化溯源数据,方便前端解析渲染
List<Map<String, Object>> sources = new ArrayList<>();
for (Map.Entry<String, TreeSet<Object>> entry : filePageMap.entrySet()) {
Map<String, Object> item = new LinkedHashMap<>();
item.put("file", entry.getKey()); // 文档文件名
item.put("pages", new ArrayList<>(entry.getValue())); // 页码列表(无页码则为空)
sources.add(item);
}
// 4. 转换为JSON格式,并用约定标记包裹,返回给前端
try {
String jsonStr = objectMapper.writeValueAsString(Map.of("sources", sources));
return CITATIONS_START + jsonStr + CITATIONS_END;
} catch (JsonProcessingException e) {
log.error("溯源信息JSON序列化失败", e);
return "";
}
}
}底层细节剖析(避坑关键,必看)
很多小伙伴实操时会遇到"提取不到元数据"的问题,核心原因是没搞懂Spring AI的底层流转逻辑,这里给大家拆解清楚,避免踩坑:
Spring AI框架的设计非常克制,在SSE流式响应过程中,前面推送的数百个数据包,只包含大模型生成的零散文本,元数据是不完整的。只有当框架检测到FinishReason(即大模型宣告推理完毕)时,才会将完整的请求生命周期报告(包含Token消耗、RAG检索结果等),统一塞进Metadata中,相当于"最后补送的装箱单"。
我们代码中使用的responseFlux.last(),就是专门获取这个"末端帧",从而提取到完整的溯源信息------这就是"末端帧劫持"的核心逻辑。
大家可以查看org.springframework.ai.chat.client.advisor.api.BaseAdvisor的源码,更直观理解这个过程(关键片段如下):
java
default Flux<ChatClientResponse> adviseStream() {
return chatClientResponseFlux.map((response) -> {
// 检测大模型推理是否完成,完成则调用after方法追加扩展内容(即Metadata)
if (AdvisorUtils.onFinishReason().test(response)) {
response = this.after(response, streamAdvisorChain);
}
return response;
}).onErrorResume((error) -> Flux.error(new IllegalStateException("Stream processing failed", error)));
}实操验证:启动服务,测试溯源效果
好在我们上一节课构建的ChatController具备良好的解耦性,这一步无需修改HTTP通信层逻辑,直接启动Spring Boot服务,用浏览器访问测试地址即可:
测试地址:http://localhost:8080/api/chat/stream?chatId=春风不晚\&message=java开发手册\&model=deepseek
【预期效果】:浏览器中会先看到AI的打字机流式输出,在数据流的最后,会追加我们封装的溯源信息,格式如下:
bash
data: 按照提供的文档信息
...
data:[CITATIONS_START]{"sources":[{"file":"阿里巴巴Java开发手册(终极版).pdf","pages":["1","7"]}]}[CITATIONS_END]前端开发小伙伴只需添加一行正则匹配,解析CITATIONS_START和CITATIONS_END之间的JSON数据,就能在对话下方渲染出类似"引用来源:阿里巴巴Java开发手册(终极版).pdf"的标签,点击即可跳转原始文档------这样一来,AI回答的可解释性和商业公信力直接拉满!
重点避坑:.cache()的作用,防止重复计费
这里有一个非常关键的细节,也是很多小伙伴容易忽略的点------我们在获取responseFlux时,添加了.cache()操作符,这可不是多余的,而是能帮大家省成本、提速度的关键!
先给大家讲清楚原理:Flux是"冷流",每订阅一次就会重新执行整个链路。我们的代码中,需要两次消费这个流:
-
第一次消费:将流转换成SSE格式,推送给前端,实现打字机效果;
-
第二次消费:等流结束后,提取元数据,追加溯源标记。
如果不加.cache():两次消费会触发两次大模型调用,不仅响应变慢,还会产生双倍费用(真实项目中一定要注意,避免浪费);
加了.cache():第一次调用大模型获取的流数据会被缓存,第二次消费直接从内存中读取,不会重复调用大模型,既省成本又提效。
延伸提示:在Spring AI结合WebFlux的开发中,只要涉及"流式响应给用户"+"后台处理完整内容"(比如存库、敏感词审核),就必须加.cache(),这是实战中总结的高频避坑点!
本节课总结(一起复盘,加深记忆)
本节课,我们跳出了"傻瓜式语法糖"的舒适区,完成了一次底层架构的深度实操:
-
舍弃.stream().content(),通过.chatResponse()获取原始Flux<ChatResponse>流,掌控流式响应的微观生命周期;
-
利用responseFlux.last()拦截SSE末端帧,提取RAG命中文档的元数据,实现来源追溯;
-
制定前后端溯源契约,通过特殊标记包裹JSON数据,实现无缝联调;
-
掌握.cache()的核心用法,避免重复调用大模型,降低成本、提升响应速度。
其实做AI知识库,"靠谱"比"花哨"更重要,来源追溯就是让知识库靠谱的核心环节------打破AI幻觉,让每一句回答都有凭有据,这才是企业级产品该有的样子。
下期预告(提前剧透,敬请期待)
【第二十六课:Spring AI 个人知识库实战(五)------增强联网搜索能力】
到目前为止,我们的本地知识库RAG主线已经全部通关,但它依然是一座"数据孤岛":如果用户问"今天的北京天气?",本地Redis向量库中没有相关数据,AI只能回复"不知道"。
一个智能的知识库,绝不能被禁锢在本地!下一节课,我们将给ChatClient注入最后的灵魂------大模型函数调用(Function Calling),让AI在本地找不到答案时,自动唤醒外部工具(比如联网搜索引擎、实时天气API),拥有主动探索真实世界的能力!
跟着直奔標杆,一步一个脚印,把Spring AI实战落地,咱们下节课见~
往期内容回顾(连贯学习,不迷路)
-
Java开发者AI转型第二十二课!Spring AI 个人知识库实战(一)------架构搭建与核心契约落地
-
Java开发者AI转型第二十三课!Spring AI个人知识库实战(二):异步ETL流水线搭建与避坑指南
-
Java开发者AI转型第二十四课!Spring AI 个人知识库实战(三)------记忆交互+SSE流式响应落地
我是直奔標杆,专注Java开发者AI转型干货分享,每一节课都贴合实战、拒绝空谈。大家在实操过程中遇到任何问题,欢迎在评论区留言交流,一起学习、一起进步,早日实现AI转型目标!