Flink+Dinky实现UDF自定义函数

前言
在大数据中,Apache Flink 以其流批一体的架构 、亚秒级延迟 和精确一次处理的特性,成为实时计算领域的领头羊。但当面对千变万化的业务场景时,你是否遇到过这样的困境:
- 内置函数无法解析特殊加密的JSON数据?
- 需要实现行业特定的指标算法(如金融风控模型)?
- 要对敏感字段进行定制化的脱敏处理?
这正是 Flink UDF(用户自定义函数) 大显身手的时刻!UDF 如同给你的数据处理流水线装上了万能工具箱,让你突破内置功能的边界,将业务逻辑直接植入计算引擎的心脏地带。
本文接下来就详细介绍一下如何在Dinky界面中引入UDF包,并注册到Flink作业里实现自定义功能。
Flink
创建项目
使用Flink官方示例脚手架,以下是linux命令,如果想要在windows环境下执行可以在windows的git bash里执行该命令。
bash
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.16.2 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false为了和官方示例做区分,我修改了上述命令的archetypeVersion、groupId、artifactId和package
bash
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.17.2 \
-DgroupId=com.guoguo \
-DartifactId=udf-demo \
-Dversion=0.1 \
-Dpackage=udfdemo \
-DinteractiveMode=false添加依赖
添加如下maven依赖到pom.xml文件中,否则对于UDF开发的代码会报错。
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version> <!-- 与Flink集群版本一致 -->
<scope>provided</scope>
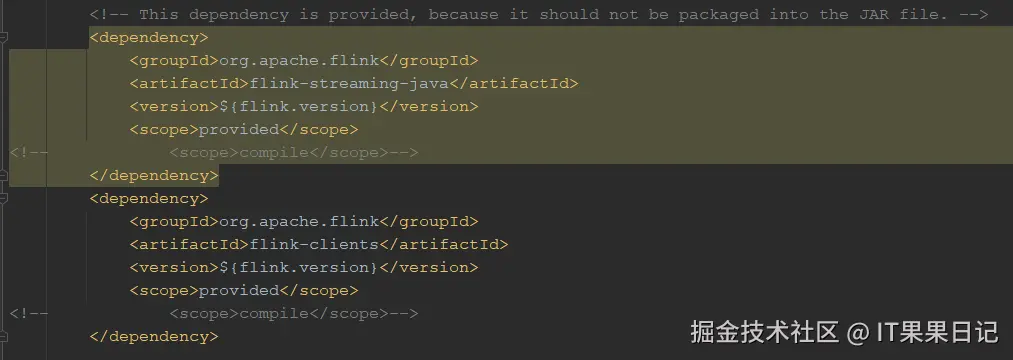
</dependency>对于Maven依赖的作用域,官方自带的是provided,它表示该依赖在编译、测试阶段包含,运行阶段不包含,适用于运行环境本身已经包含了这些依赖的场景,如远程Flink和Dinky环境。
如果想要在idea本地运行Flink官方示例,则需要将这个<scope>标签内的provided 改为compile,或者删除<scope>标签,因为默认就是compile。compile表示该依赖在编译、测试和运行阶段都会被包含,适用于本地运行的场景。
代码
新建了一个AddHelloPrefix类,继承ScalarFunction类,实现eval接口,这个类用来在输入字符串的开头添加Hello字符串前缀。
java
package udfdemo;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.functions.ScalarFunction;
public class AddHelloPrefix extends ScalarFunction {
// 基本字符串处理
public String eval(String input) {
return "Hello " + (input != null ? input : "null");
}
// 支持整数类型(多态)
public String eval(Integer input) {
return "Hello " + (input != null ? input.toString() : "null");
}
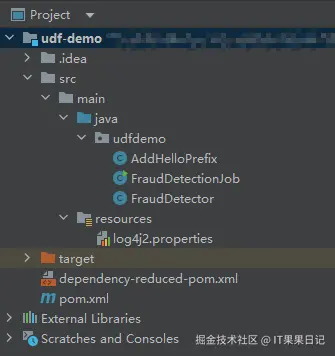
}此时代码结构如下图,FraudDetectionJob和FraudDetector是官方自带的示例,可删除。
打包
执行以下maven命令将UDF代码打包
bash
mvn clean packageUDF打包后是要放在Dinky环境中执行的,所以<scope>标签使用的是provided ,打包后的压缩包结构如下,没有一些依赖的其他jar包,非常简洁。
Dinky
上传jar包
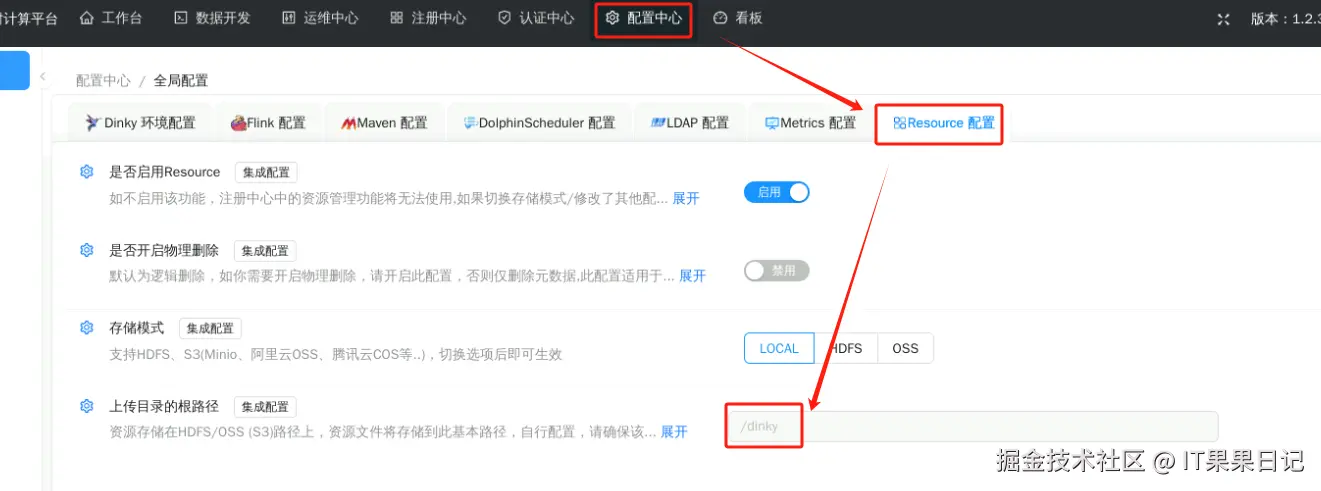
进入Dinky界面,点击顶部注册中心菜单,选择左侧资源菜单
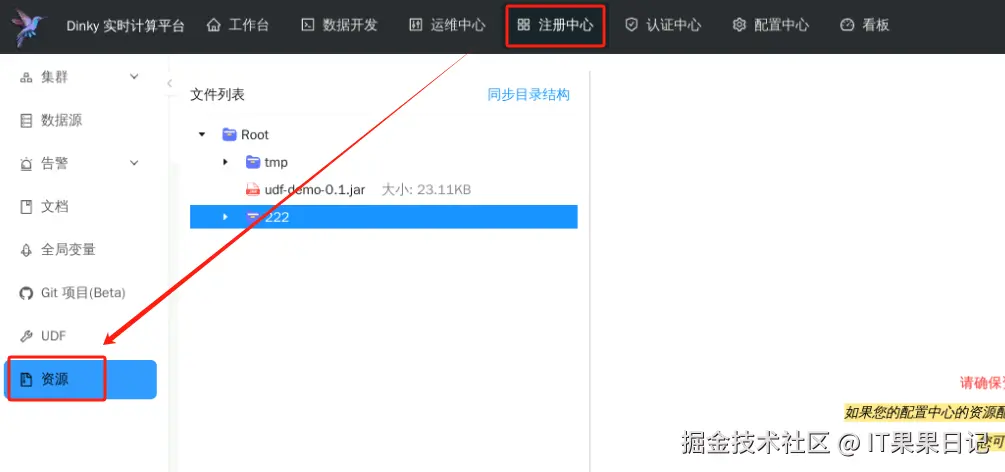
在Root目录下新建一个文件夹,鼠标右键在新建的文件夹下,会有上传按钮,就可以上传上一步打包好的jar包。
在配置中心的Resource配置里,找到上传资源的路径,也可以在该路径下直接将文件拷贝过去。拷贝完了之后在资源界面里(上图)有一个同步目录结构,点击它就会将新上传的文件刷新出来。
创建作业
进入Dinky的数据开发界面,创建一个FLink SQL作业,在作业的开头加入两行代码
sql
-- 引入UDF包依赖,路径是上一步上传资源里的路径
ADD JAR 'file:///dinky/udf-demo-0.1.jar';
-- 注册UDF,udfdemo是包名,AddHelloPrefix是自定义函数名,add_hello_prefix是udf的别名
CREATE FUNCTION add_hello_prefix AS 'udfdemo.AddHelloPrefix' LANGUAGE JAVA;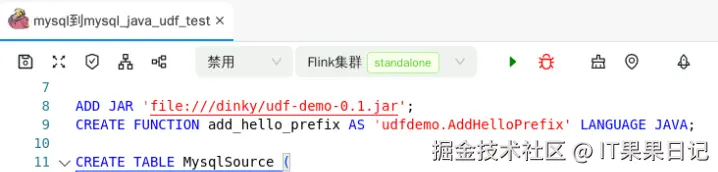
在作业的最后使用UDF查询
sql
-- 使用UDF查询
SELECT
name,
add_hello_prefix(name) AS greeting,
add_hello_prefix(age) AS age_greeting
FROM users;
查询结果如下

参考
基于 DataStream API 实现欺诈检测 | Apache Flink
Flink SQL 使用自定义 UDF 函数在业务场景中,我们经常需要对身份证信息进行加密在保存,这时我们就需要对身份 - 掘金