【导读】
本文将深入解析CLIP的对比学习机制、模型架构与训练奥秘,并揭示其在实际应用中的潜力与局限。不论是希望了解技术前沿,还是寻找落地灵感,CLIP都值得你细细品味。
如今,大型语言模型(LLM)备受瞩目。工程师们常常对比并盛赞ChatGPT、Llama、Gemini和Mistral等革命性模型,它们确实以其强大能力赢得了大量关注。然而,开发者们往往忽略了其他许多同样对机器学习行业产生重大影响的模型。
本文将介绍OpenAI开发的标志性模型之一------CLIP。该模型于2021年发布,可应用于多种自然语言处理或计算机视觉项目,并在不同任务中实现领先性能。虽然许多工程师仅将CLIP视为嵌入模型------这并没有错------但其应用范围实际上极为广泛。
本文将详细解析CLIP模型,包括其架构、训练过程、性能表现以及实际应用。
对比学习
在深入讨论CLIP架构之前,我们首先需要理解对比学习(Contrastive Learning) 的核心概念,这一方法在CLIP设计中扮演着关键角色。
对比学习属于自监督学习方法,其目标是训练嵌入模型生成能够将相似样本在空间中拉近、相异样本推远的嵌入表示。
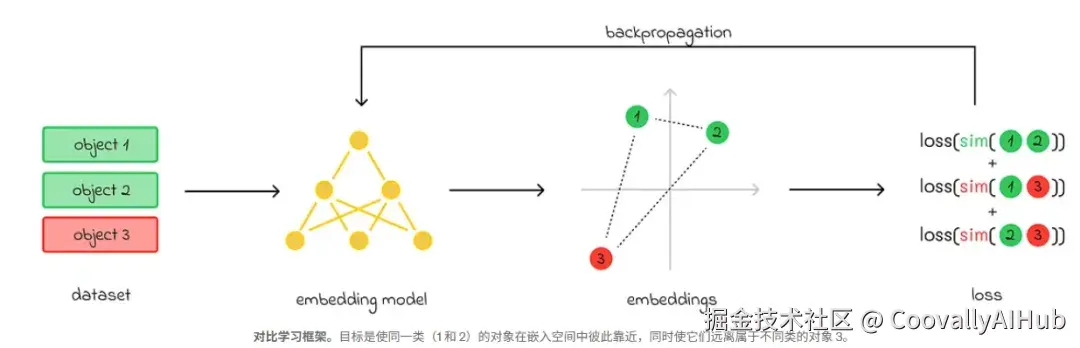
简而言之,在对比学习中,模型处理成对的对象。训练过程中,模型并不知道这些对象在现实中是否真正相似。在通过计算出的嵌入预测它们的距离(相似度)后,损失函数被计算出来。主要分为两种情况:
- 初始对象相似: 损失函数值引导权重更新,调整嵌入表示,使下一次相似度更接近;
- 初始对象不相似: 模型更新权重,使得该对嵌入的相似度在下一次计算中降低。
架构与训练
CLIP开发团队收集了包含4亿对(图像,文本) 的大规模数据集,每张图像都配有文字描述。
其目标是构建有意义的嵌入表示,使得它们之间的相似度能够衡量文本描述与图像的匹配程度。为此,作者采用了两种已有的模型架构:
- 文本嵌入模型
- 图像嵌入模型
初始的4亿对图像和文本被分成批次。每个批次中的图像和文本分别通过图像或文本嵌入模型生成嵌入表示。如果批次中有n对嵌入,则会生成n个图像嵌入和n个文本嵌入。
接着,计算图像嵌入与文本嵌入之间的余弦 pairwise 相似度矩阵。
相似度矩阵主对角线上的每个元素代表批次中原本配对在一起的图像和文本之间的相似度。由于文本描述与图像对应良好,主对角线上的相似度应被最大化。
而非对角线上的元素并非原始配对,来自不同样本对,因此它们的相似度应被最小化。
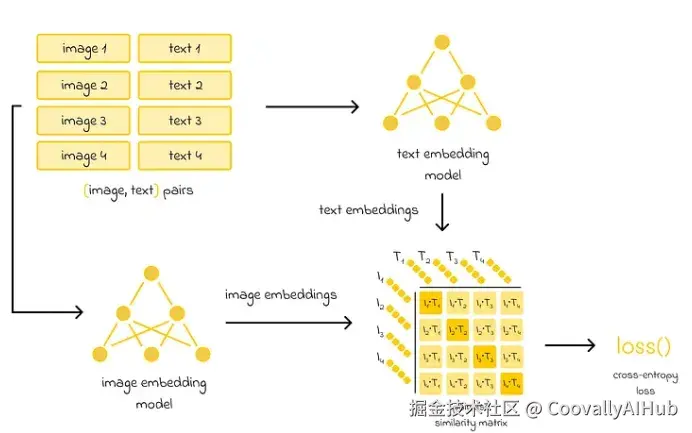
计算出的相似度随后输入交叉熵损失函数,用于更新两个嵌入模型的权重。
细节要点
CLIP的核心参数是用于编码文本和图像的嵌入模型:
- 文本编码采用基于Transformer的模型,其架构与BERT相似;
- 图像编码可使用传统卷积网络(如ResNet)或视觉Transformer模型(ViT)。
两个模型均从头开始训练,默认生成大小为512的嵌入向量。鉴于数据集规模庞大(4亿对),ViT通常比ResNet更受青睐。
优势亮点
CLIP具有以下几个显著优势:
- 可应用于多种任务,而不仅仅是嵌入生成(具体示例见下一部分);
- 零样本 (Zero-shot)CLIP****性能可与基于ResNet特征的简单线性分类监督基线模型相媲美;
- 计算效率高:许多计算可并行运行。
应用场景
- 嵌入表示
最直接的应用是利用CLIP生成文本和图像的嵌入表示。这些嵌入可单独用于文本或图像任务,例如在相似性搜索流水线或RAG系统中。
此外,如果需将图像与对应文本描述关联,可同时使用文本和图像嵌入。
- 图像分类
除了生成图像和文本嵌入,CLIP最强大的能力之一是以零样本学习方式解决其他任务。
例如,在图像分类任务中,如果给定一张动物图像,目标是从动物列表中识别其类别,我们可以嵌入每个动物名称。然后通过寻找与图像嵌入最相似的文本嵌入,直接确定动物类别。
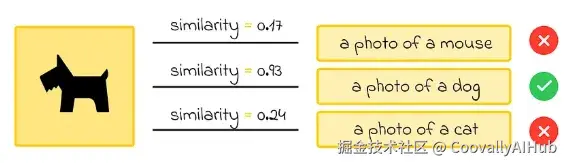
研究表明,对于此类识别任务,使用以下提示结构嵌入每个文本(类别名称)效果更佳:"一张<动物类别>的照片"。对于其他任务类型,最佳提示可能有所不同。
- 光学字符识别(OCR)
OCR指从图像中识别文本的任务,通常由专门训练的监督模型解决。然而,CLIP的强大能力使其能够以零样本方式识别图像中的文本。
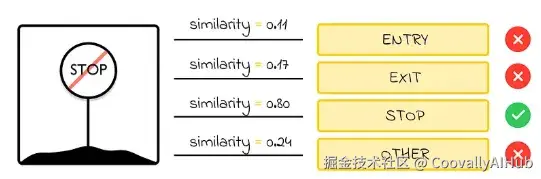
如果图像中可能出现的所有文本已知,可以类似方式编码所有可能选项,并选择最相似的配对。但由于可能的单词或文本数量通常远大于图像分类任务中的标签数量,编码所有选项会非常耗时且低效。因此,CLIP很少用于长文本序列的OCR任务。
在OCR方面,CLIP更擅长处理短词或符号识别。例如,用CLIP设置数字识别任务很容易,因为只有10个类别(每个类别代表0到9之间的数字)。
一个有趣的发现是,零样本CLIP在著名MNIST手写数字识别任务上仅达到88%的准确率,而其他简单模型轻松达到99%的准确率。需要注意的是,尽管CLIP具有令人印象深刻的零样本能力,但仍可能存在某些特定图像类型是CLIP未训练过的。

需注意以下几点:
CLIP不擅长某些抽象任务,例如计算照片中的物体数量、估计图像中两个物体的接近程度等;
在标准计算机视觉任务上,CLIP的零样本性能与其他传统模型(如ImageNet)相当。但作者指出,若要超越这些模型,CLIP所需的训练硬件需比现有硬件强数千倍,这在当前条件下难以实现。
结语
本文深入探讨了CLIP的架构原理。通过在4亿对(图像,文本)数据上训练,CLIP在多项任务中达到了领先水平。尽管CLIP在某些下游抽象任务上表现不佳,但其零样本技术在执行其他标准计算机视觉任务方面仍具有出色能力。