PyTorch实战(6)------模型微调详解
0. 前言
在本节中,我们将首先简要了解 AlexNet 的架构以及如何使用 PyTorch 构建一个 AlexNet 模型。然后,我们将探索 PyTorch 的预训练 CNN 模型库,最后使用一个预训练的 AlexNet 模型进行微调,应用于图像分类任务,并进行预测。
1. AlexNet
AlexNet 是 LeNet 的继任者,其架构上进行了增量式的改进,例如使用了 8 层( 5 层卷积层和 3 层全连接层),模型参数从 60000 增加到 6000 万,并且使用了 MaxPool 代替 AvgPool。此外,AlexNet 的训练和测试使用了一个更大的数据集------ImageNet,其大小超过 100 GB,而 LeNet 则使用了 MNIST 数据集。AlexNet 的出现真正革新了卷积神经网络 (Convolutional Neural Network, CNN),使其成为在图像相关任务中,比其他经典机器学习模型(如支持向量机 SVM)更强大的模型。下图显示了 AlexNet 的架构:

如我们所见,AlexNet 的架构延续了 LeNet 的常见模式,采用了顺序堆叠的卷积层,并在输出端之前使用了一系列全连接层。PyTorch 使得将这样的模型架构转化为实际代码变得非常容易。使用 PyTorch 实现 AlexNet 架构:
python
class AlexNet(nn.Module):
def __init__(self, number_of_classes=1000):
super(AlexNet, self).__init__()
self.feats = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=11, stride=4, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=192, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.clf = nn.Linear(in_features=256, out_features=num_classes),
def forward(self, inp):
op = self.feats(inp)
op = op.view(op.size(0), -1)
op = self.clf(op)
return op其中 __init__ 函数包含了整个分层结构的初始化,包括卷积层、池化层和全连接层,并且使用了 ReLU 激活函数。forward 函数则是将数据点 x 传入已初始化的网络中。请注意,forward 方法的第二行已经执行了展平操作,因此我们不需要像LeNet那样单独定义该函数。
除了自己初始化模型架构并进行训练之外,PyTorch 通过其 torchvision 包提供了一个 models 子包,里面包含了用于解决不同任务的 CNN 模型定义,例如图像分类、语义分割、目标检测等,常用的图像分类任务模型包括:
AlexNetVGGResNetSqueezeNetDenseNetInception v3GoogLeNetShuffleNet v2MobileNet v2ResNeXtWide ResNetMnasNetEfficientNet
在下一小节中,我们将使用一个预训练的 AlexNet 模型作为示例,展示如何使用 PyTorch 对其进行微调。
2. 使用 PyTorch 微调 AlexNet
接下来,我们使用 PyTorch 提供的预训练 CNN 模型库,首先下载并转换数据集。在本节中,我们将使用一个小型的蜜蜂和蚂蚁的图像数据集。数据集包含 240 张训练图像和 150 张验证图像,两个类别(蜜蜂和蚂蚁)的图像数量相等。从 Kaggle 下载数据集,并将解压后的文件存储在 hymenoptera_data 目录中。
(1) 导入所需库,加载并转换数据集:
python
import os
import time
import copy
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms
ddir = 'hymenoptera_data'
data_transformers = {
'train': transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.490, 0.449, 0.411], [0.231, 0.221, 0.230])]),
'val': transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.490, 0.449, 0.411], [0.231, 0.221, 0.230])])}
img_data = {k: datasets.ImageFolder(os.path.join(ddir, k), data_transformers[k]) for k in ['train', 'val']}
dloaders = {k: torch.utils.data.DataLoader(img_data[k], batch_size=8, shuffle=True)
for k in ['train', 'val']}
dset_sizes = {x: len(img_data[x]) for x in ['train', 'val']}
classes = img_data['train'].classes
print(classes)
dvc = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")(2) 可视化训练数据集的样本图像:
python
def imageshow(img, text=None):
img = img.numpy().transpose((1, 2, 0))
avg = np.array([0.490, 0.449, 0.411])
stddev = np.array([0.231, 0.221, 0.230])
img = stddev * img + avg
img = np.clip(img, 0, 1)
plt.imshow(img)
if text is not None:
plt.title(text)
# Generate one train dataset batch
imgs, cls = next(iter(dloaders['train']))
# Generate a grid from batch
grid = torchvision.utils.make_grid(imgs)
imageshow(grid, text=[classes[c] for c in cls])使用 NumPy 的 np.clip() 方法,以确保图像像素值限制在 0 到 1 之间,从而使可视化更加清晰。输出如下所示:

(3) 定义微调流程,这本质上是在预训练模型上进行的训练过程:
python
def finetune_model(pretrained_model, loss_func, optim, epochs=10):
start = time.time()
model_weights = copy.deepcopy(pretrained_model.state_dict())
accuracy = 0.0
for e in range(epochs):
print(f'Epoch number {e}/{epochs - 1}')
print('=' * 20)
# for each epoch we run through the training and validation set
for dset in ['train', 'val']:
if dset == 'train':
pretrained_model.train() # set model to train mode (i.e. trainbale weights)
else:
pretrained_model.eval() # set model to validation mode
loss = 0.0
successes = 0
# iterate over the (training/validation) data.
for imgs, tgts in dloaders[dset]:
imgs = imgs.to(dvc)
tgts = tgts.to(dvc)
optim.zero_grad()
with torch.set_grad_enabled(dset == 'train'):
ops = pretrained_model(imgs)
_, preds = torch.max(ops, 1)
loss_curr = loss_func(ops, tgts)
# backward pass only if in training mode
if dset == 'train':
loss_curr.backward()
optim.step()
loss += loss_curr.item() * imgs.size(0)
successes += torch.sum(preds == tgts.data)
loss_epoch = loss / dset_sizes[dset]
accuracy_epoch = successes.double() / dset_sizes[dset]
print(f'{dset} loss in this epoch: {loss_epoch}, accuracy in this epoch: {accuracy_epoch}')
if dset == 'val' and accuracy_epoch > accuracy:
accuracy = accuracy_epoch
model_weights = copy.deepcopy(pretrained_model.state_dict())
print()
time_delta = time.time() - start
print(f'Training finished in {time_delta // 60}mins {time_delta % 60}secs')
print(f'Best validation set accuracy: {accuracy}')
# load the best model version (weights)
pretrained_model.load_state_dict(model_weights)
return pretrained_model在 finetune_model() 函数中,我们需要输入预训练模型(即模型的架构以及权重)、损失函数、优化器和训练epoch数。与从随机初始化的权重开始不同,微调过程中使用 AlexNet 的预训练权重开始。
(4) 在开始微调(训练)模型之前,定义一个辅助函数可视化模型的预测结果:
python
def visualize_predictions(pretrained_model, max_num_imgs=4):
torch.manual_seed(1)
was_model_training = pretrained_model.training
pretrained_model.eval()
imgs_counter = 0
fig = plt.figure()
with torch.no_grad():
for i, (imgs, tgts) in enumerate(dloaders['val']):
imgs = imgs.to(dvc)
tgts = tgts.to(dvc)
ops = pretrained_model(imgs)
_, preds = torch.max(ops, 1)
for j in range(imgs.size()[0]):
imgs_counter += 1
ax = plt.subplot(max_num_imgs//2, 2, imgs_counter)
ax.axis('off')
ax.set_title(f'pred: {classes[preds[j]]} || target: {classes[tgts[j]]}')
imageshow(imgs.cpu().data[j])
if imgs_counter == max_num_imgs:
pretrained_model.train(mode=was_model_training)
return
pretrained_model.train(mode=was_model_training)(5) 使用 PyTorch 的 torchvision.models 加载预训练的 AlexNet 模型:
python
model_finetune = models.alexnet(weights=torchvision.models.AlexNet_Weights.IMAGENET1K_V1).to(device=dvc)该模型对象包含以下两个主要组成部分:
features:特征提取部分,包含所有的卷积层和池化层classifier:分类器部分,包含所有的全连接层,最终连接到输出层
(6) 打印特征提取部分模型结构:
python
print(model_finetune.features)输出结果如下内容:
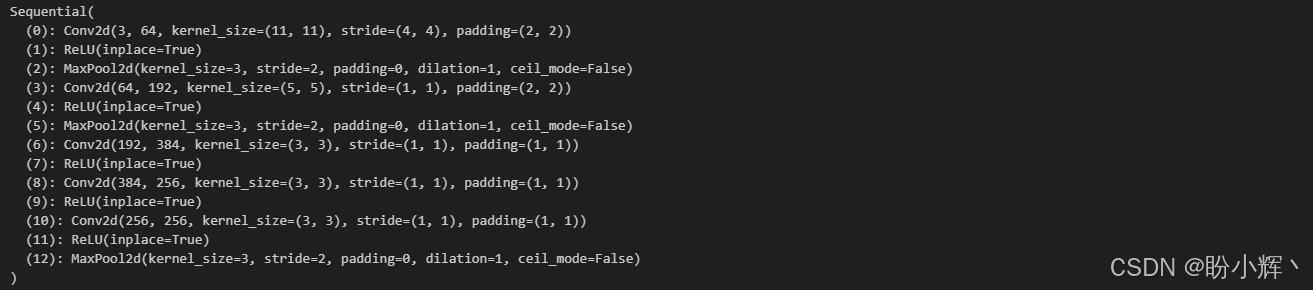
(7) 接下来,检查分类器部分:
python
print(model_finetune.classifier)输出结果如下所示:

可以看到,预训练模型的输出层大小为 1000,但我们的微调数据集只有 2 个类别。因此,需要对此进行调整:
python
model_finetune.classifier[6] = nn.Linear(4096, len(classes)).to(device=dvc)(8) 定义优化器和损失函数,然后执行训练过程:
python
loss_func = nn.CrossEntropyLoss()
optim_finetune = optim.SGD(model_finetune.parameters(), lr=0.0001)
# train (fine-tune) and validate the model
model_finetune = finetune_model(model_finetune, loss_func, optim_finetune, epochs=10)输出结果如下所示:
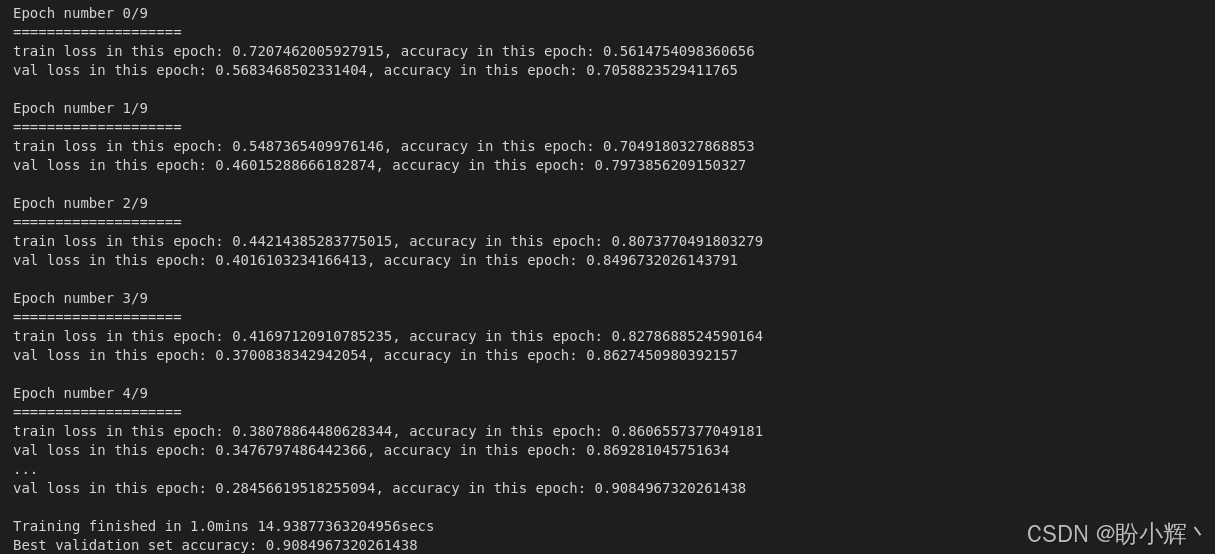
可视化模型预测结果,以查看模型是否确实从数据集中学习到了相关特征:
python
visualize_predictions(model_finetune)输出结果如下所示:

可以看到,预训练的 AlexNet 模型能够在这个相对较小的图像分类数据集上进行迁移学习。这展示了迁移学习的强大能力,以及使用 PyTorch 微调经典模型的简便性。
在下一节中,我们将讨论 AlexNet 的一个更深、更复杂的卷积神经网络------VGG 网络。
3. 使用 PyTorch 微调 VGG
我们已经学习了 AlexNet 卷积神经网络架构。接下来,我们继续探索更复杂的 CNN 模型,但构建这些模型架构的核心原则是相同的。我们将采用模块化的模型构建方法,将卷积层、池化层和全连接层组合成块(模块),然后将这些块按顺序或分支的方式堆叠起来。在本节中,我们将介绍 VGGNet。
VGG (Visual Geometry Group) 与拥有 8 层和 6000 万参数的 AlexNet 相比,VGG 包含 13 层( 10 个卷积层和 3 个全连接层)和 1.38 亿参数。VGG 基本上是在 AlexNet 架构的基础上堆叠了更多层,同时使用了更小的卷积核( 2x2 或 3x3)。
因此,VGG 的创新之处在于其架构带来的 VGG 之前未有的深度,VGG 架构如下所示:

上述的 VGG 架构称为 VGG13,因为它包含了 13 层。其他变体包括 VGG16 和 VGG19,分别包含 16 层和 19 层。还有另一组变体------VGG13_bn、VGG16_bn 和 VGG19_bn,其中 bn 表示这些模型还包含批归一化 (batch normalization) 层。
PyTorch 的 torchvision.models 提供了预训练的 VGG 模型(包括前面讨论的六种变体),这些模型是在 ImageNet 数据集上训练的。接下来,我们使用预训练的 VGG13 模型对一个小型的蜜蜂和蚂蚁数据集进行预测。
(1) 首先,导入所需库:
python
import os
import time
import copy
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms(2) 下载数据,并设置蜜蜂和蚂蚁的数据集及数据加载器,同时定义数据预处理操作。为了对这些图像进行预测,需要下载 ImageNet 数据集的 1000 个类别标签。下载完成后,创建类别索引( 0 到 999 )与对应类别标签之间的映射:
python
ddir = 'hymenoptera_data'
data_transformers = {
'train': transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.490, 0.449, 0.411], [0.231, 0.221, 0.230])]),
'val': transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.490, 0.449, 0.411], [0.231, 0.221, 0.230])])}
img_data = {k: datasets.ImageFolder(os.path.join(ddir, k), data_transformers[k]) for k in ['train', 'val']}
dloaders = {k: torch.utils.data.DataLoader(img_data[k], batch_size=8, shuffle=True, num_workers=2)
for k in ['train', 'val']}
dset_sizes = {x: len(img_data[x]) for x in ['train', 'val']}
dvc = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
import ast
with open('./imagenet1000_clsidx_to_labels.txt') as f:
classes_data = f.read()
classes_dict = ast.literal_eval(classes_data)
print({k: classes_dict[k] for k in list(classes_dict)[:5]})输出前五个类别的映射,如下所示:
shell
{0: 'tench, Tinca tinca', 1: 'goldfish, Carassius auratus', 2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias', 3: 'tiger shark, Galeocerdo cuvieri', 4: 'hammerhead, hammerhead shark'}(3) 定义模型预测可视化函数,函数接受预训练模型对象和要进行预测的图像数量,并输出带有预测结果的图像:
python
def imageshow(img, text=None):
img = img.numpy().transpose((1, 2, 0))
avg = np.array([0.490, 0.449, 0.411])
stddev = np.array([0.231, 0.221, 0.230])
img = stddev * img + avg
img = np.clip(img, 0, 1)
plt.imshow(img)
if text is not None:
plt.title(text)
def visualize_predictions(pretrained_model, max_num_imgs=4):
was_model_training = pretrained_model.training
pretrained_model.eval()
imgs_counter = 0
fig = plt.figure()
with torch.no_grad():
for i, (imgs, tgts) in enumerate(dloaders['val']):
imgs = imgs.to(dvc)
ops = pretrained_model(imgs)
_, preds = torch.max(ops, 1)
for j in range(imgs.size()[0]):
imgs_counter += 1
ax = plt.subplot(max_num_imgs//2, 2, imgs_counter)
ax.axis('off')
ax.set_title(f'pred: {classes_dict[int(preds[j])]}')
imageshow(imgs.cpu().data[j])
if imgs_counter == max_num_imgs:
pretrained_model.train(mode=was_model_training)
return
pretrained_model.train(mode=was_model_training)(4) 加载预训练的 VGG13 模型:
python
model = models.vgg13(weights=torchvision.models.VGG13_Weights.DEFAULT).to(device=dvc)VGG13 模型大约需要 508 MB 的硬盘空间。
(5) 最后,我们使用预训练模型对蜜蜂和蚂蚁数据集进行预测:
python
visualize_predictions(model)输出结果如下所示:

经过训练的 VGG13 模型(尽管是在完全不同的数据集上训练的)能正确预测蜜蜂和蚂蚁数据集中的所有测试样本。我们可以看到,尽管模型是在与目标任务不同的数据集上训练的,但仍然能够从图像中提取相关的视觉特征。
小结
本文详细讲解了使用 PyTorch 微调经典 CNN 模型的方法。以 AlexNet 为例,介绍了其架构特点,并演示了完整的微调流程:数据加载与增强、模型结构调整、训练优化等,在蜜蜂/蚂蚁数据集上进行训练。进一步展示了 VGG13 的迁移学习能力,无需微调即可实现准确预测,验证了深度 CNN 的特征提取优势。
系列链接
PyTorch实战(1)------深度学习概述
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络