前言
通过上一篇 基于 Embedding 的本地图像搜索 我们验证了使用 clip 对批量图片进行嵌入后,基于关键字进行搜索的可行性。下面我们基于以上内容实现一个更加完整的图像搜索功能,可以对任意文件夹中的图片实现关键字搜索或者基于图片进行搜索,即以图找图。
带有搜索功能的图片浏览器
相册功能
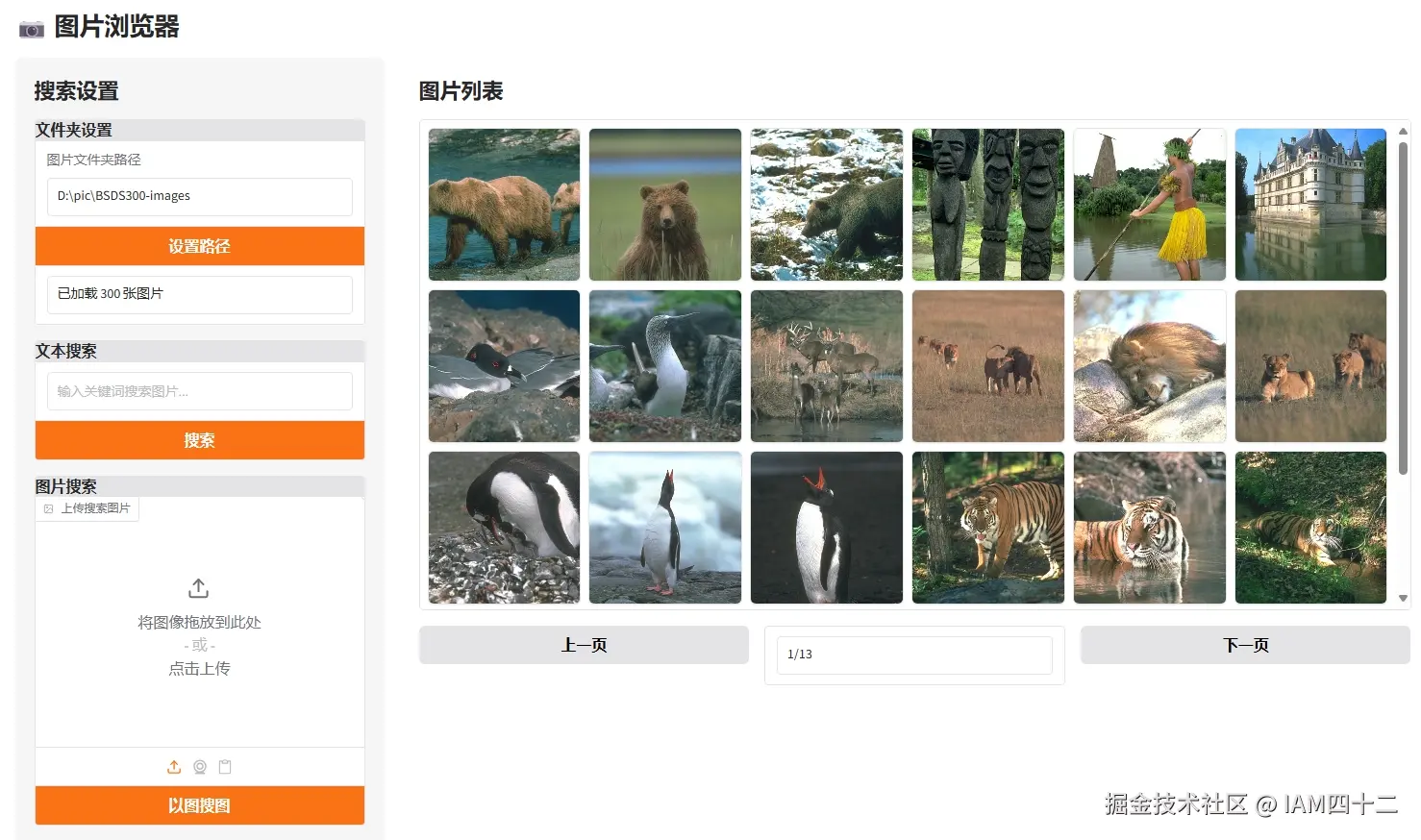
首先我们借助 Gradio 实现一个本地图片浏览器的功能,配置指定文件夹之后,可以将图片以列表的方式进行展现。
- UI 实现
python
with gr.Column(scale=3, elem_id="right-panel"):
gr.Markdown("## 图片列表")
# 图片展示区域
with gr.Column(elem_classes="gallery-container"):
gallery = gr.Gallery(
label="",
columns=6,
rows=4,
height="auto",
object_fit="cover",
show_label=False
)
# 分页控制
with gr.Row():
prev_page_btn = gr.Button("上一页")
page_info = gr.Textbox(label="页码", value="0/0", interactive=False, show_label=False)
next_page_btn = gr.Button("下一页")为了更高效和友好的展示图片,这里采取了分页策略。
- 加载图片
python
def load_images_from_folder(self, folder_path: str):
"""加载文件夹中的图片"""
self.image_paths = []
supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.gif')
if not os.path.exists(folder_path):
return False
for root, _, files in os.walk(folder_path):
for file in files:
if file.lower().endswith(supported_formats):
self.image_paths.append(os.path.join(root, file))
self.current_page = 0
self.is_searching = False
return True根据指定文件夹遍历查询后,展现所有图片内容。为了方便展示,这里以BSDS300 数据集为例。实际测试用个人电脑中日常生活拍照以及其他照片测试效果也很好。
BSDS300(Berkeley Segmentation Dataset 300)是计算机视觉领域广泛使用的基准数据集,主要用于图像分割、边缘检测和超分辨率重建等任务。涵盖自然场景的多样主题(如动物、建筑、植物、人物等),包含 300 张图片。
对图片进行嵌入
可以正常加载所有图片之后,按照上一节的思路对所有图片进行嵌入,并存储嵌入结果和图片路径。
python
def load_images_from_folder(self, folder_path: str):
"""加载文件夹中的图片"""
// 保持不变
if self.search_clip is None:
self.search_clip = SearchCLIClip()
# 为每张图片生成特征
self.image_features, self.image_paths = self.search_clip.load_or_compute_embeddings(folder_path,
self.image_paths)
self.current_page = 0
self.is_searching = False
return True
def load_or_compute_embeddings(self, folder_path, image_paths):
unique_name = hashlib.sha256(folder_path.encode('utf-8')).hexdigest()
pickle_path = os.path.join(PKL_CACHE_PATH, f"{unique_name}.pkl")
if os.path.exists(pickle_path):
print("加载缓存特征...")
with open(pickle_path, "rb") as f:
temp_features, temp_paths = pickle.load(f)
if len(temp_paths) == len(image_paths):
return temp_features, temp_paths
else:
f.close()
os.remove(pickle_path)
return self.compute_embeddings(pickle_path, image_paths)
else:
return self.compute_embeddings(pickle_path, image_paths) 每次设置不同目录时,通过 sha256() 计算目录地址的唯一值,作为生成嵌入特征的文件的文件名。这样对于相同的文件夹就不用每次都耗时计算嵌入内容了。嵌入的计算方式再上一节已经介绍过了,不再赘述。
对于批量图片进行嵌入计算,具体耗时和图片的大小及设备算力都有关,但总的来说不会很耗时。比如以上 300 张图片在我的设备上 4 秒就跑完了,生成的嵌入文件总的大小约 626KB
基于文字进行搜索
python
def search_by_text(query: str):
"""通过文本搜索图片"""
result_paths = text_search(query)
total_pages = get_total_pages()
return result_paths, gr.update(value=f"1/{total_pages}")
def search(self, text, image_features, image_paths, top_k=2):
with torch.no_grad():
text_inputs = self.processor(text=text, return_tensors="pt", padding=True).to(device)
text_emb = self.model.get_text_features(**text_inputs)
sims = torch.nn.functional.cosine_similarity(image_features, text_emb, dim=1)
top_idx = torch.topk(sims, top_k).indices # shape: [top_k]
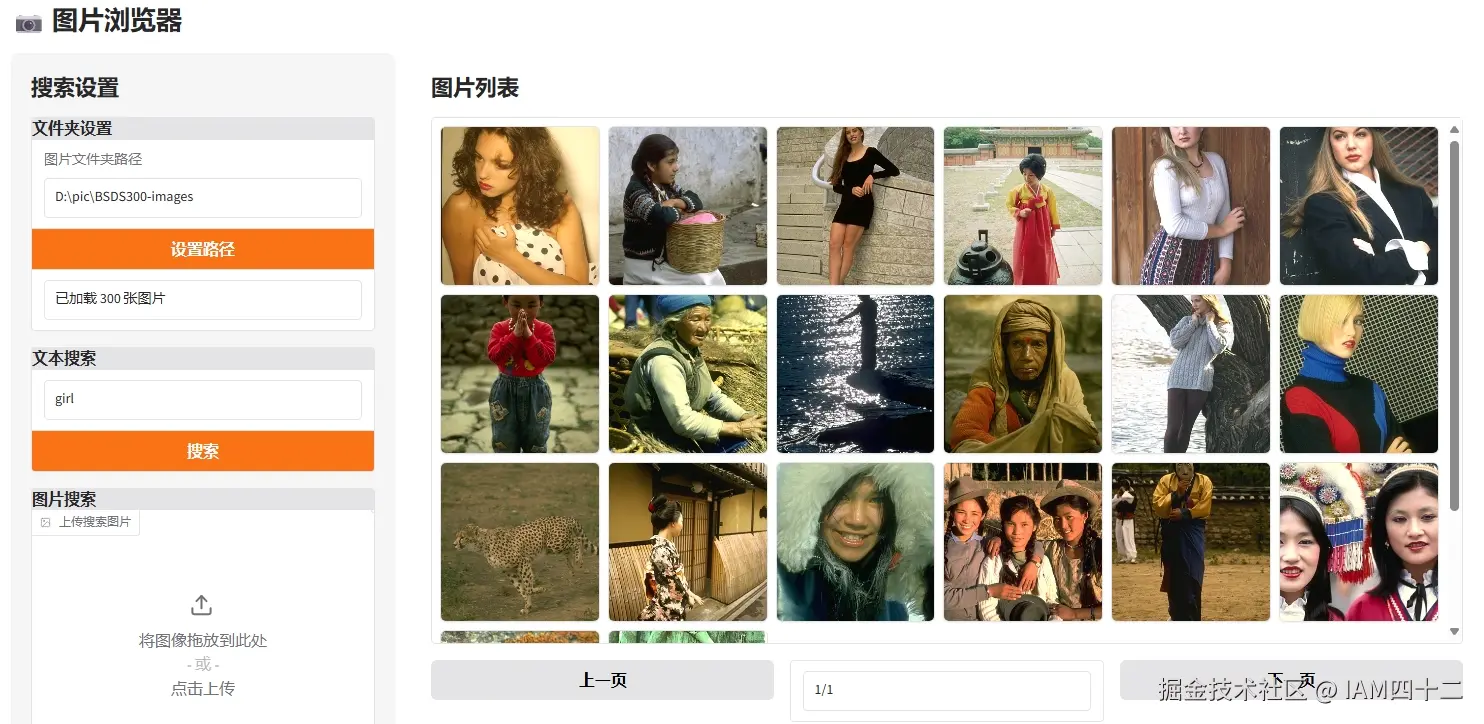
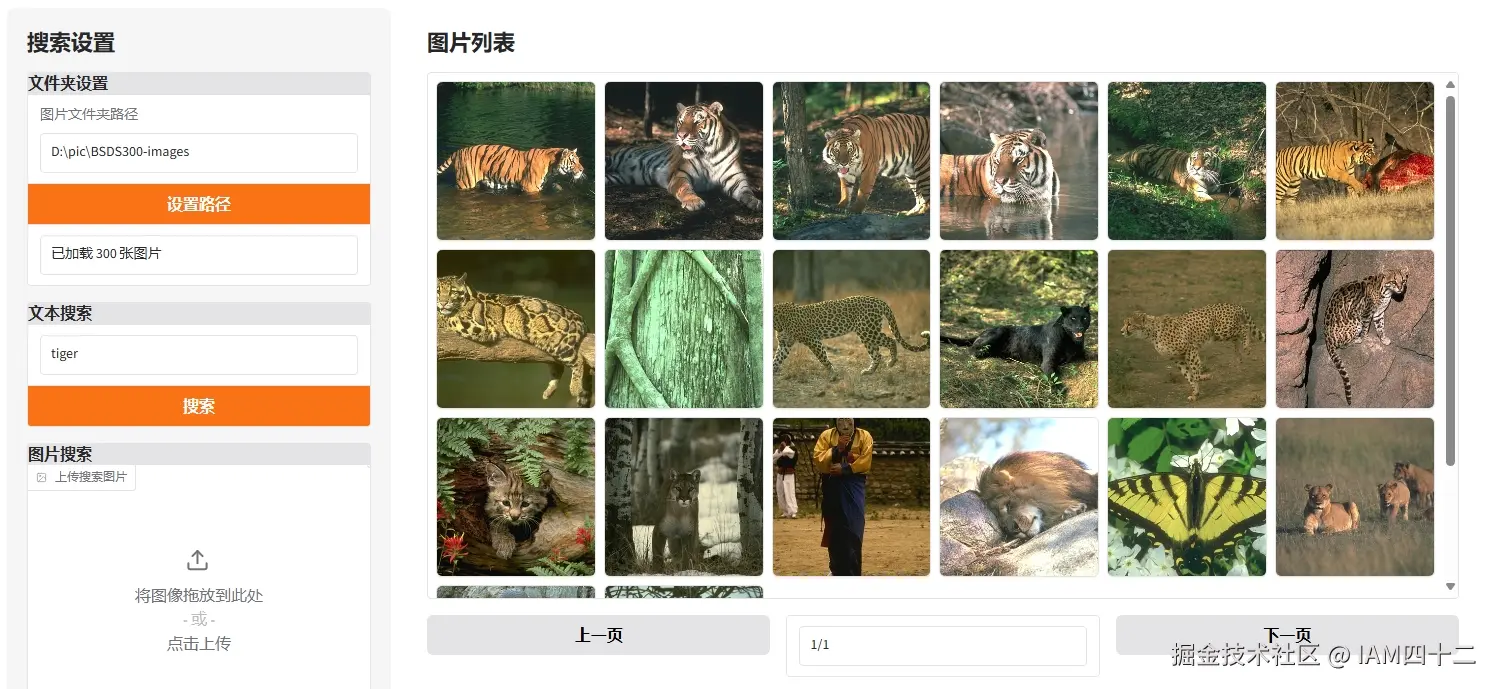
return [(image_paths[i], sims[i].item()) for i in top_idx]基于文本的搜索和上一节的思路相同,计算输入文本嵌入和已有嵌入集合的相似度,返回 topN。可以看一下效果
- 搜索 girl
- 搜索 tiger
- 搜索 sky
| query | result |
|---|---|
| sky | 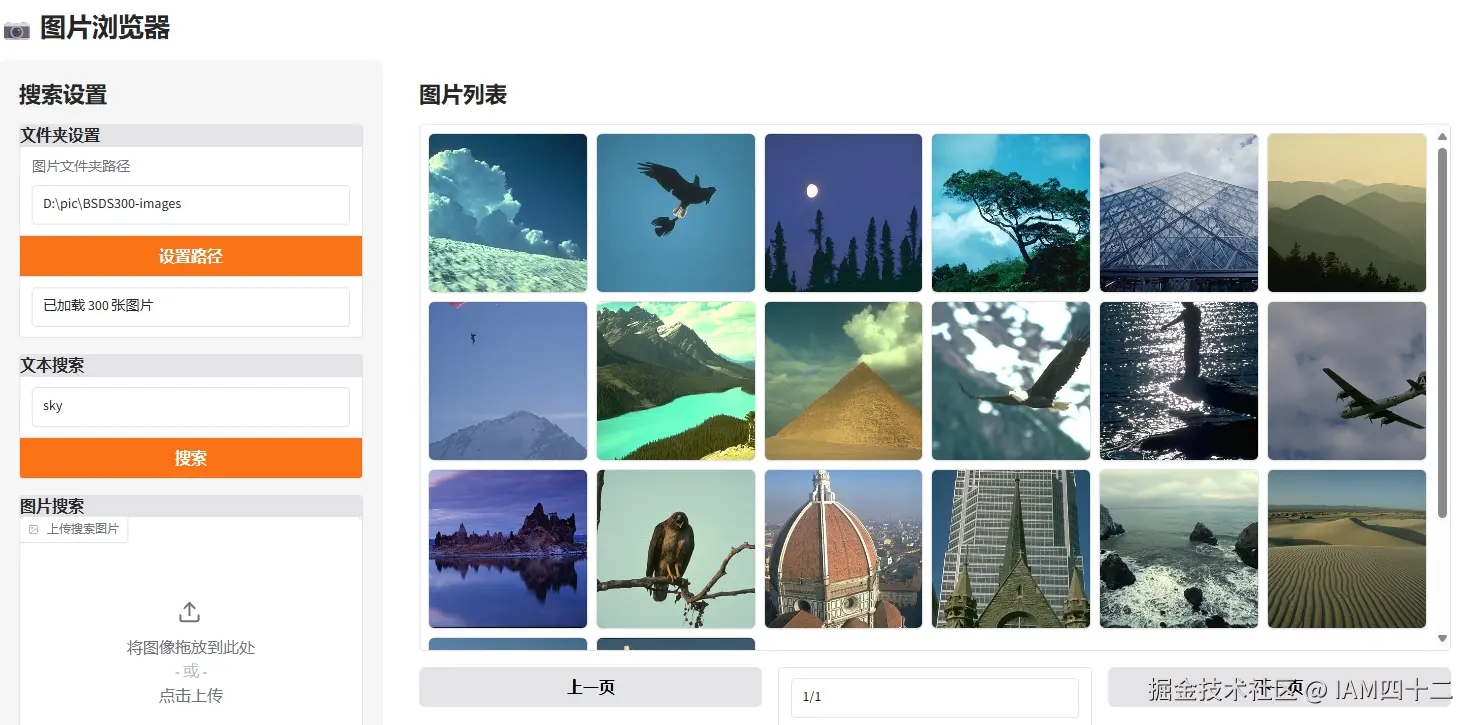 |
| moon light in the sky | 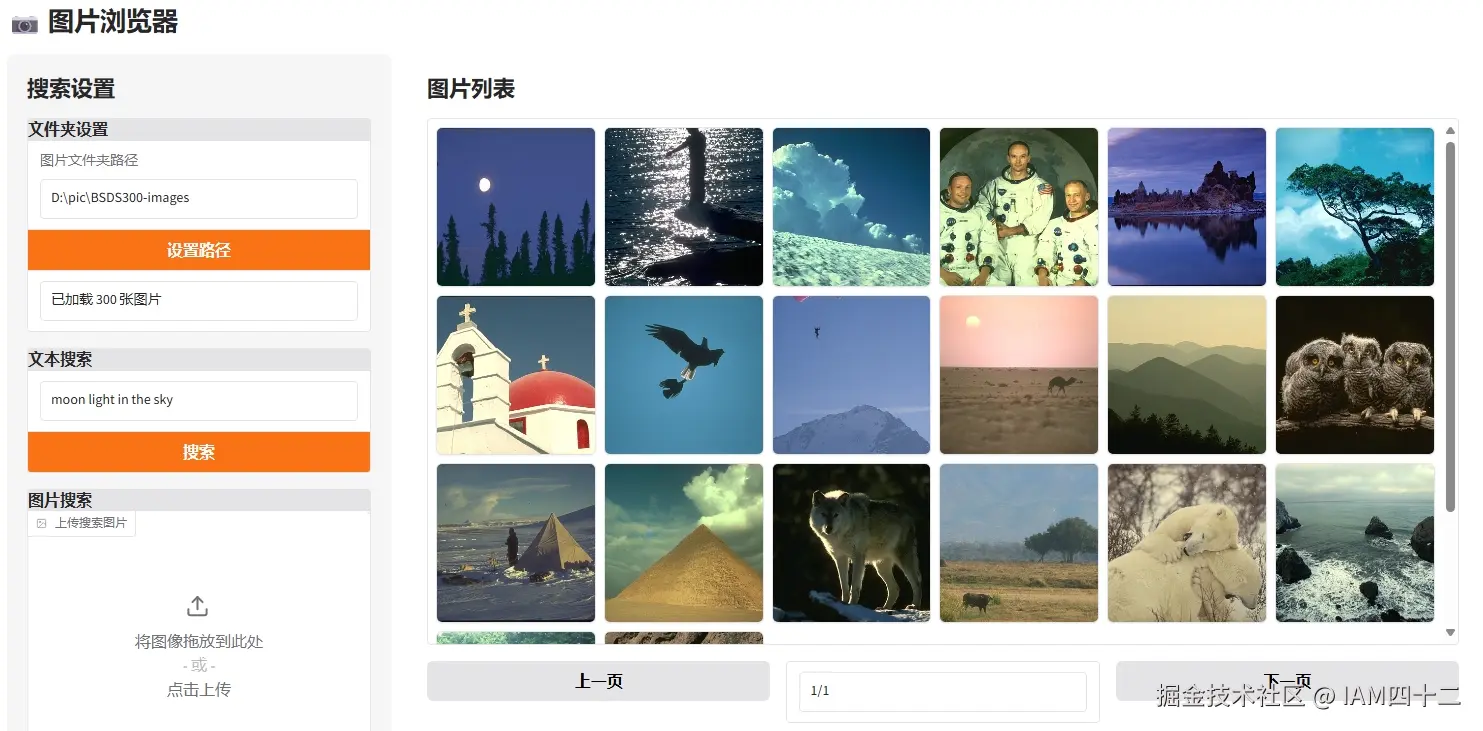 |
可以看到这个搜索结果还是非常不错的,搜索关键词和图片内容的匹配度还是很高的。试想如果你的旅行相册相册里有数千张图片,如果可以根据关键字筛选其中的内容,是不是可以省下从大量图片中找内容的时间呢。
在最后一组搜索结果中,通过对比我们可以看到,通过更加详细的描述,可以召回更精确的结果。通过 moon light in the sky 这种比 sky 更精细的描述,夜空中有月亮的图片出现的位置一下子蹿升到了首位。
可以看到这里都是以英文举例,因为实测发现clip 对中文的支持并不是很好。毕竟 openai 训练 clip 的时候标签大概率都是英文为主,对中文的支持会相对弱一些,当然对于这个问题我们也有应对方式,这个后面再说。
基于图片进行搜索
基于图片进行搜索可以解决两个问题
- 模型对输入文本的语言类型有约束,对你所熟悉的语言嵌入效果不好
- 无法用语言描述的内容,正所谓一图胜千言,用图片作为示例进行搜索,解决表达的问题
python
def search_with_image(self, image_input, image_features, image_paths, top_k=2):
with torch.no_grad():
img = Image.open(image_input).convert("RGB")
inputs = self.processor(images=img, return_tensors="pt", padding=True).to(device)
img_features = self.model.get_image_features(inputs.pixel_values).squeeze(0)
sims = torch.nn.functional.cosine_similarity(image_features, img_features, dim=1) #
top_idx = torch.topk(sims, top_k).indices # shape: [top_k]
return [(image_paths[i]) for i in top_idx]基于图片进行搜索的思路和文本完全一致,唯一的区别就是用于计算相似度的内容变成了图片的嵌入,相当于单张图片的嵌入和多张图片的嵌入直接比较,返回相似度的 topN,我们看一下实际效果。
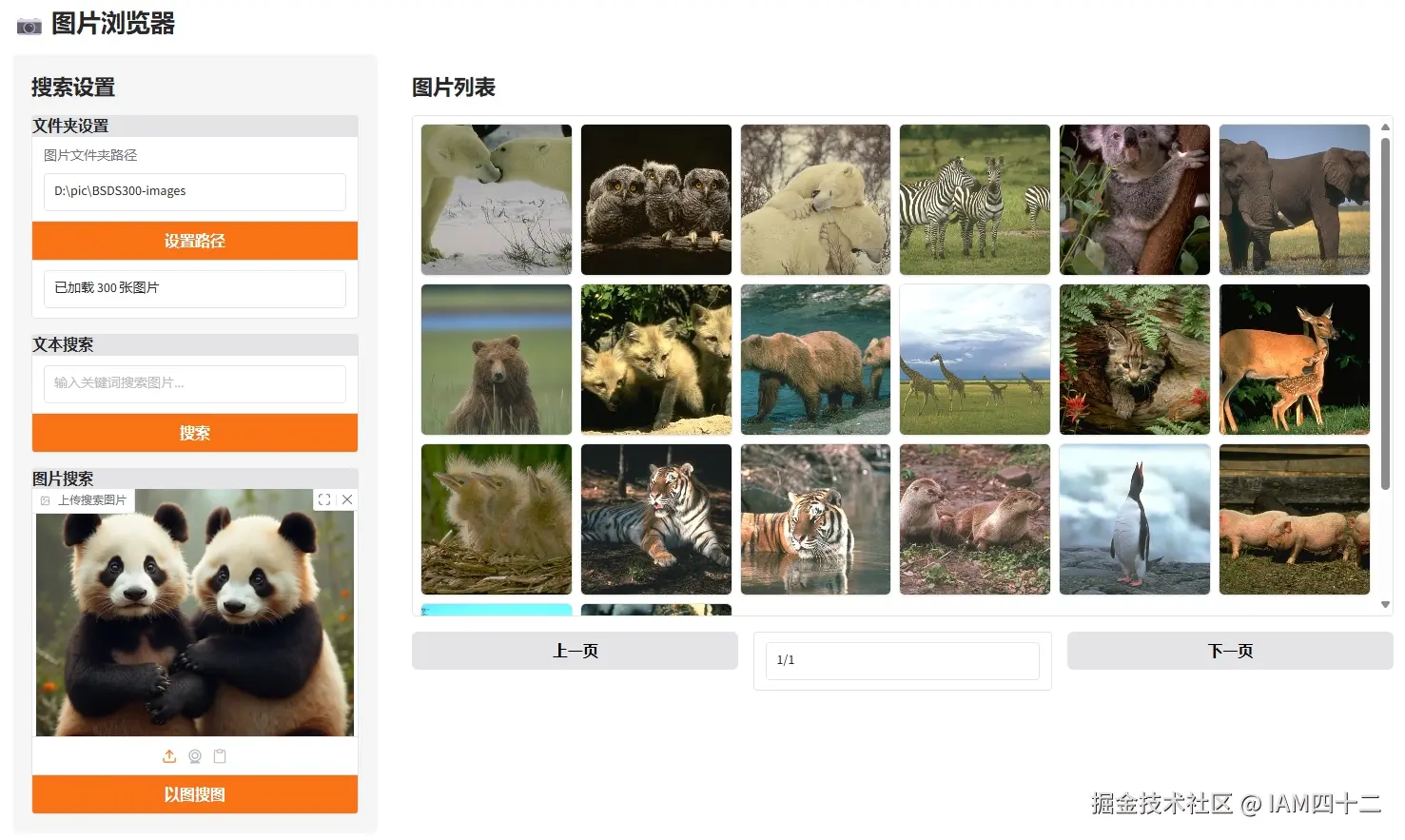
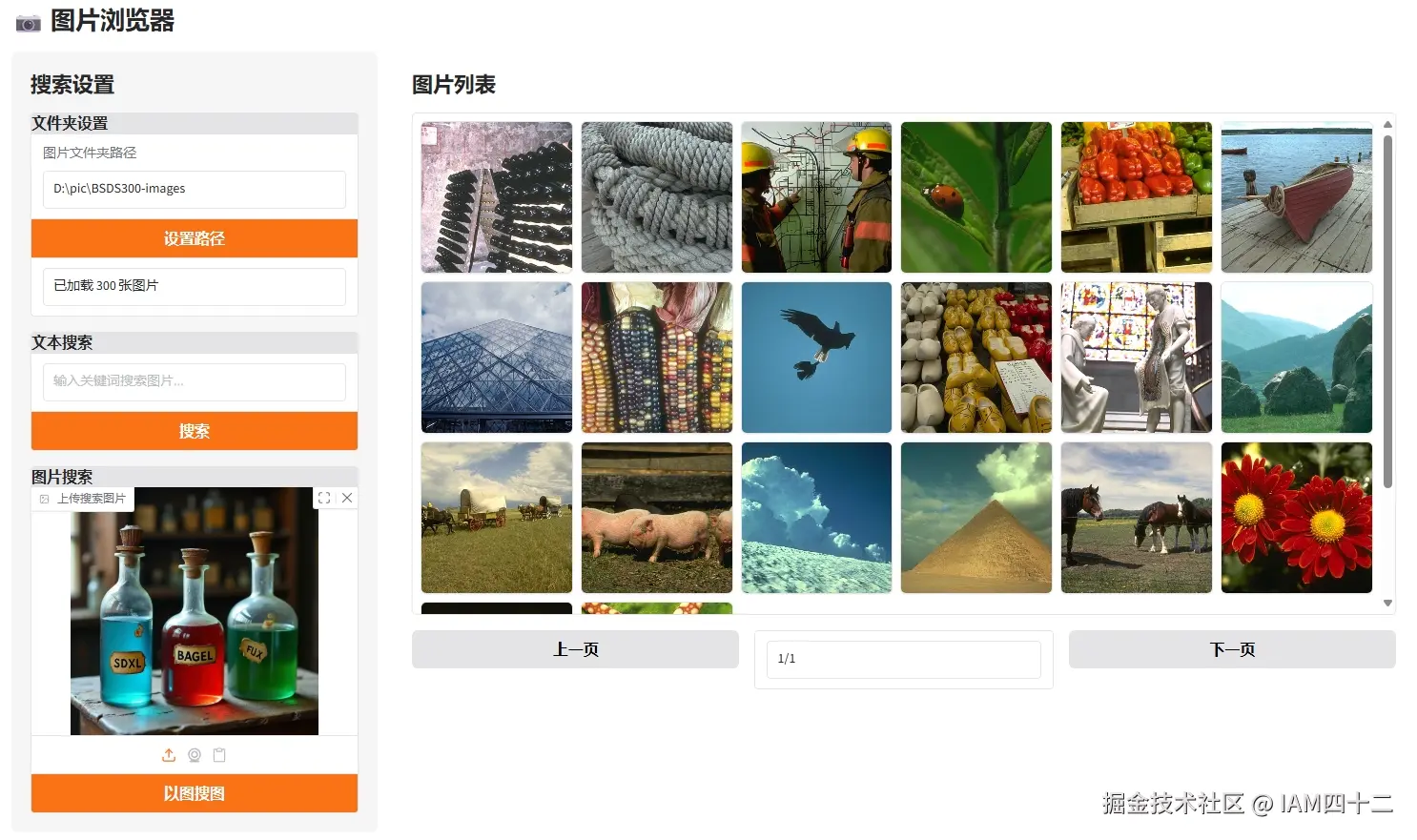
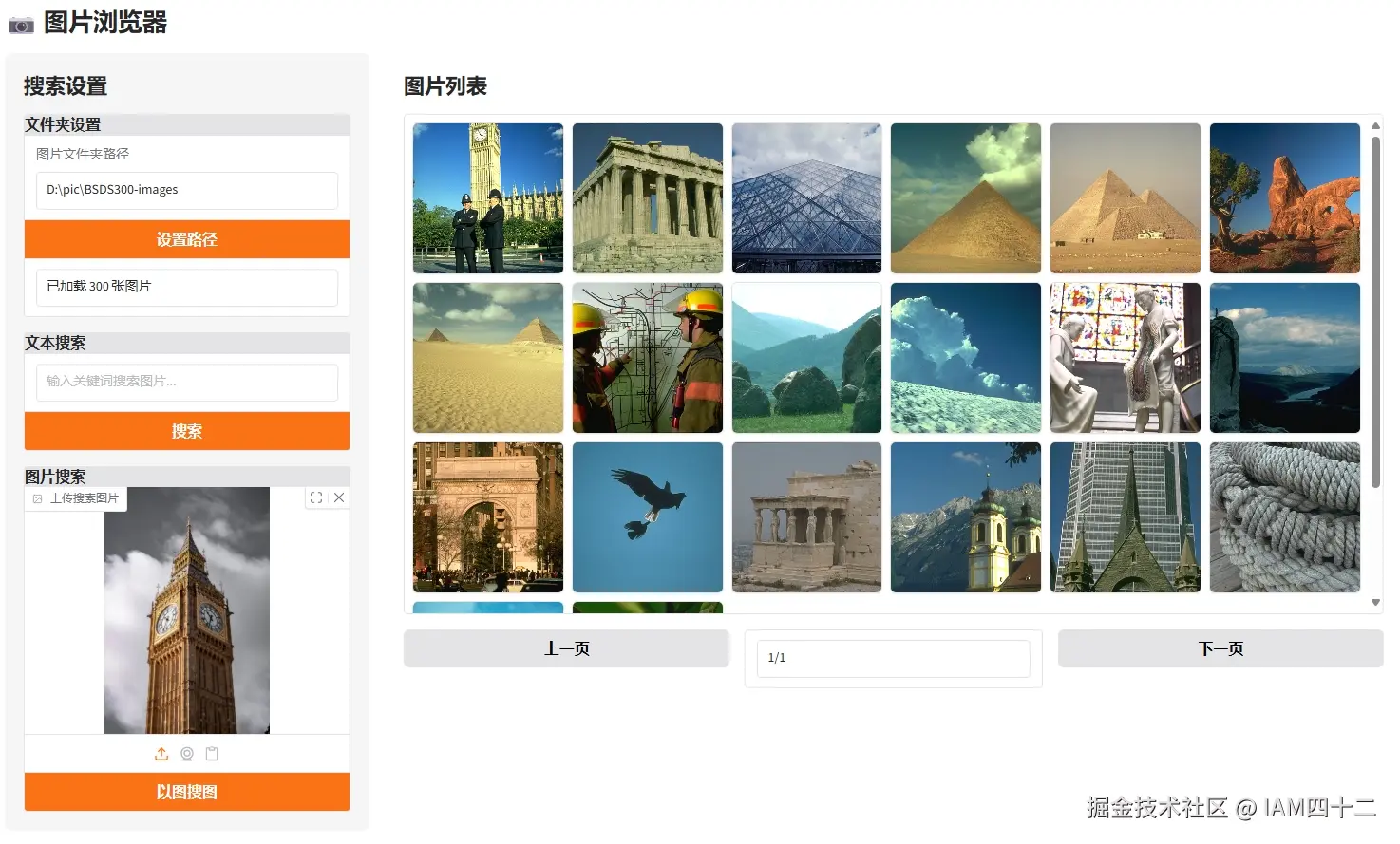
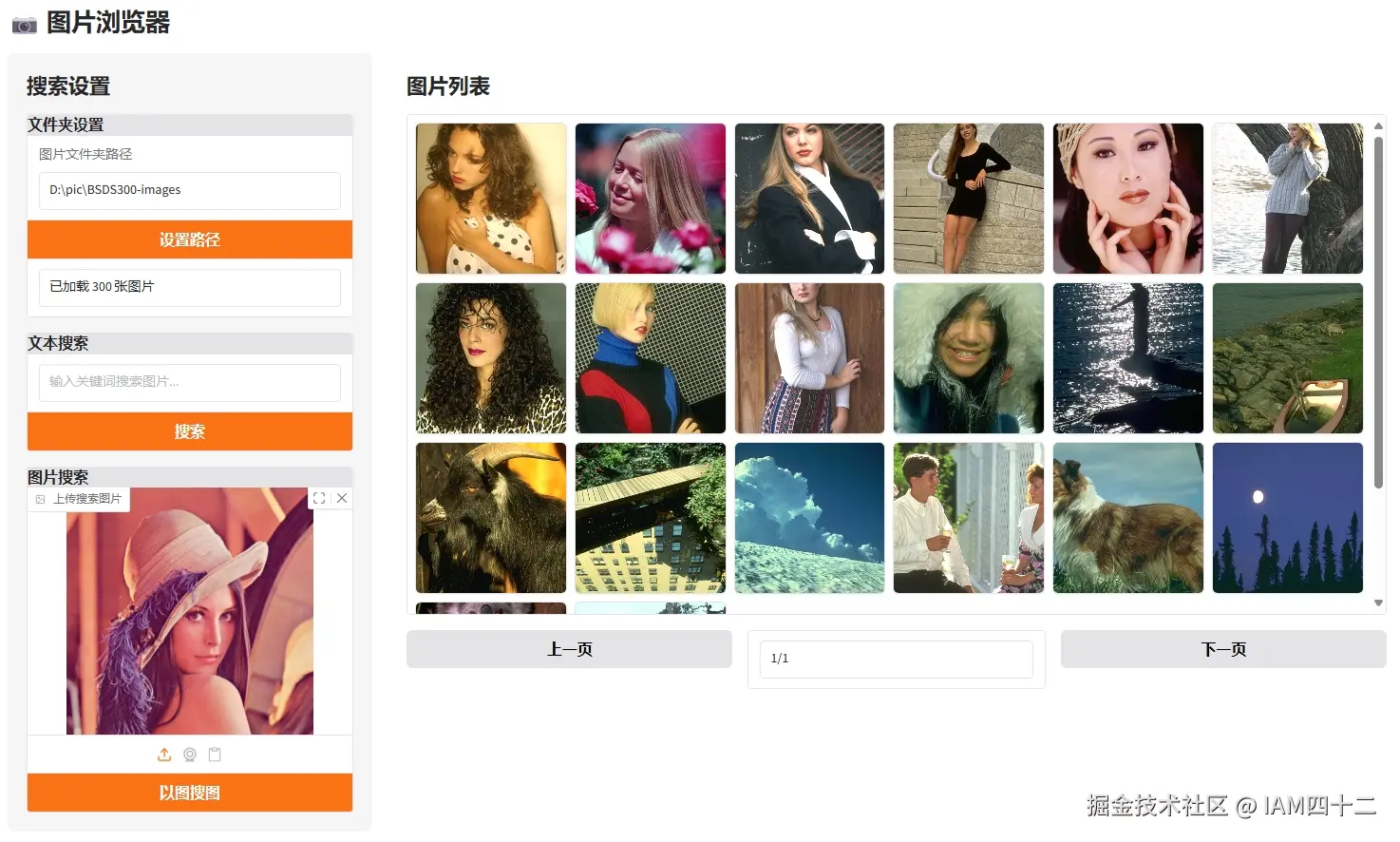
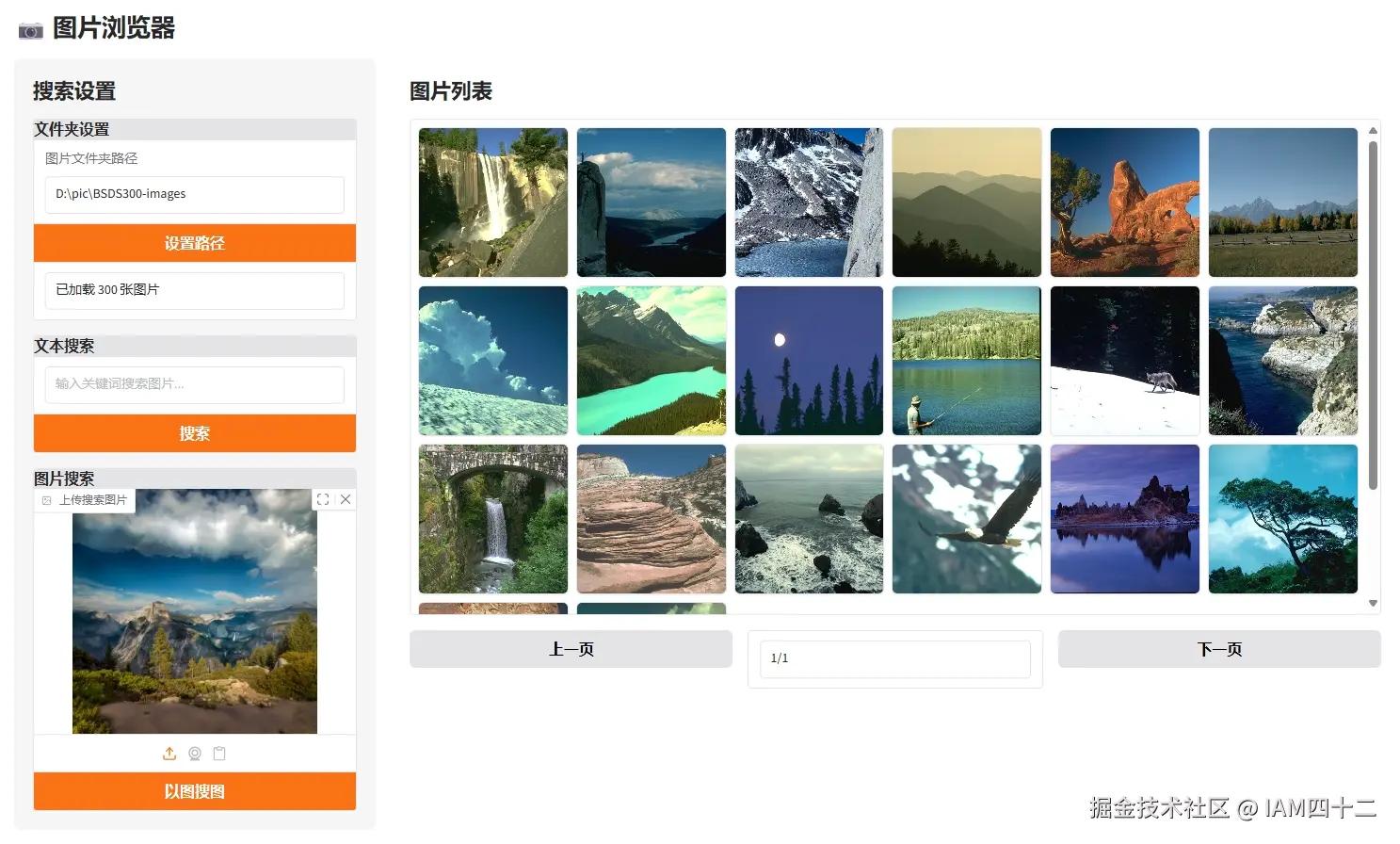
从这些示例可以看到,其实用图片进行搜索效果其实更好,泛化能力更强。图片中无法用语言描述的细节特征,通过模型自行 embedding 是可以捕捉到的,而利用这些额外的信息就能实现更精确的召回。
这样,我们就实现了一个简单的同时支持文本与图片搜索的本地图片浏览器。通过对本地相册的一次性嵌入,就可以基于文字描述或者图片进行搜索,搜索结果会返回和输入内容相似甚至完全相同的结果。当然,这样一个简单的实现还存在诸多问题和可以优化的点,我们可以简单分析一下。
问题与优化思路
嵌入结果的存储
对于嵌入结果,这里为了方便我们直接使用 pickle 进行存储。实际上可以使用数据库进行存储,这里又有两种思路。一种是使用传统的数据库比如 sqlite、MySQL 这类数据库纯粹进行嵌入数据的存储,查询的时候将内容取出手动进行嵌入向量相似度的计算;另外一种方式是直接使用向量数据库,查询时直接从向量数据库完成相似度计算,省去手动计算的步骤。
嵌入的计算
前面说过,clip 对于中文嵌入的效果支持并不是很好,对于这一点我们可以借助一些针对中文进行过优化的其他产品进行嵌入计算,比如使用阿里达摩院的 Chinese-CLIP 。
再有,以上的实现是以相册地址为维度进行计算中,如果相册中的内容发生了变化,图片数量有增减,或者数量没变内容却发生了变化,那么嵌入结果是需要重新计算的,否则查询结果就会出现问题。那么,何时触发嵌入结果的再次计算又变成了一个问题,当然这是一个工程问题,需要结合实际场景去考虑。
小结
通过对各种媒介进行嵌入,无论是文本还是图片,还是语音和视频。嵌入结果将抽象的内容转换成了多维的向量表示,虽然维度变多了,但其中的内容却变得简单了,变成了数字。而且这些向量之间的大小关系是有现实意义的,更相近的向量意味着现实生活中二者也更加相似,从这一点出发我们可以做非常多的事情。