
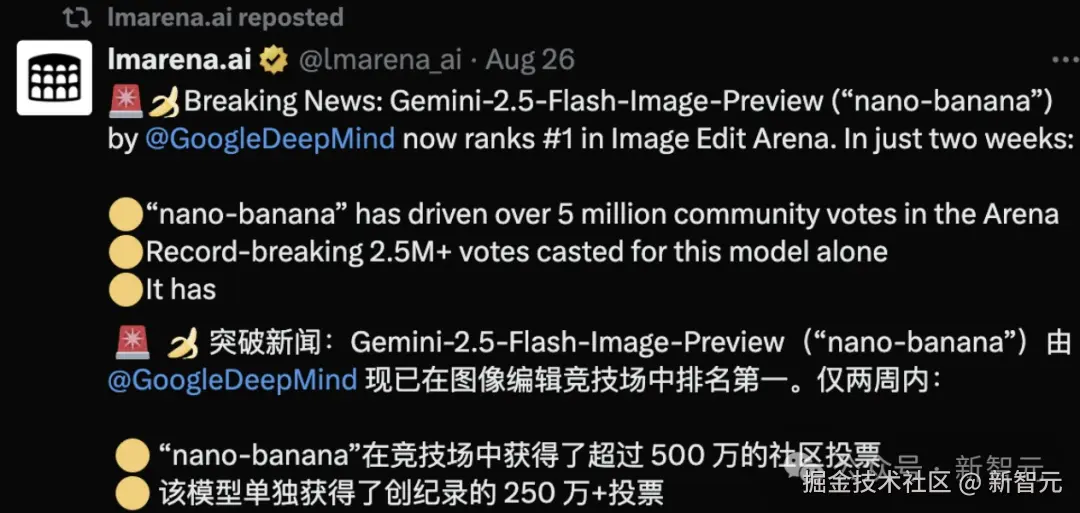
「【新智元导读】8 月,nano‑banana 登顶 LMArena 文生图像榜单,带动 LMArena 社区流量暴增 10 倍,月活用户 300 万 +。nano‑banana 在 LMArena 启动盲测后,短短两周便吸引了超过 500 万次总投票,并单独赢得了 250 万 + 直接投票,创下历史最高参与度。自 2023 年推出以来,LMArena 已成为谷歌、OpenAI 等 AI 大厂扎堆厮杀的竞技场。」
今年 8 月,一款名为「纳米香蕉」的神秘 AI 图像编辑器轻松登顶 Image Edit Arena 榜首,直接把 LMArena8 月份的平台流量拉爆:
流量暴增 10 倍,月活 300 万 +。

该模型自在 LMArena 启动盲测以来,短短两周便吸引了超过 500 万次总投票,并单独赢得了 250 万 + 直接投票,创下历史最高参与度。
nano‑banana 的神秘身份,也在 LMArena 社区引发广泛猜测。
在谷歌认领「纳米香蕉」,将其正式定名为 Gemini 2.5 Flash Image 之前,已不少网友猜到谷歌是 Nano Banana 的真正主人。
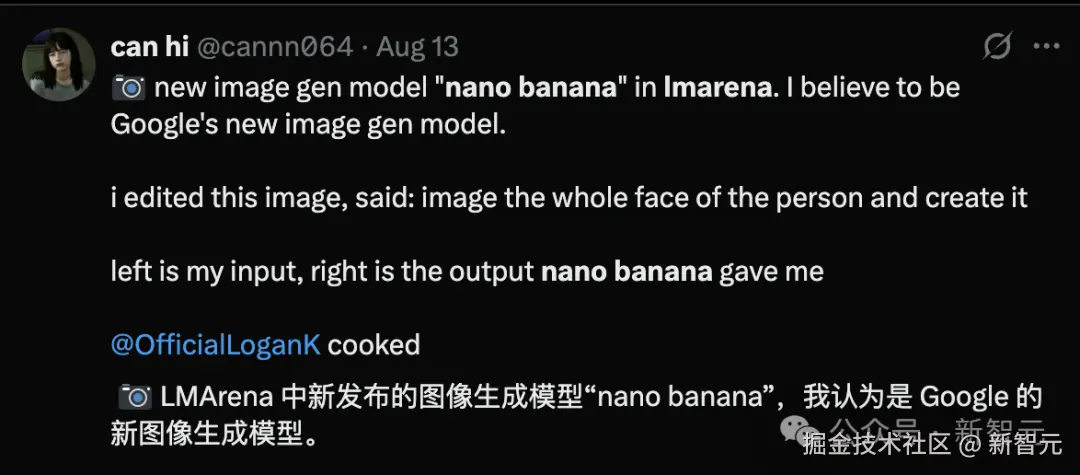
还有网友贴出了在 LMArena 上使用正版「纳米香蕉」的方法,该方法不仅免费,而且不需要登录。
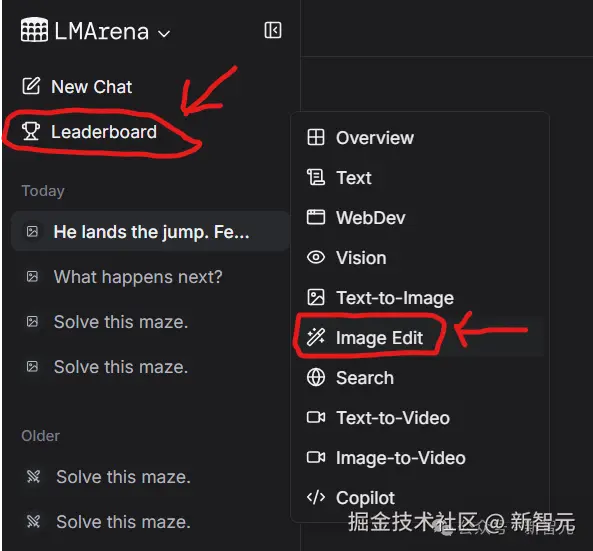
不仅能让用户「近距离」接触各种最新模型,LMArena 还为大模型比拼,提供了一个真实的「罗马竞技场」,它让谷歌、OpenAI 等公司的最新模型,在这里真刀真枪对决,接受成千上万用户的检阅。
用户的投票和反馈,决定了这些大模型的排名,也为大模型厂商迭代模型,提供了真实的用例数据,使他们能够更加有的放矢地改进模型。
nano‑banana 爆红,让 LMArena 流量狂涨 10 倍,据 LMArena 首席技术官 Wei-Lin Chiang 证实,该站月活跃用户已超过 300 万。
无论谷歌,还是 LMArena 都成为这场流量盛宴中的最大赢家。

「从 Chatbot Arena 到 LMArena」

LMArena 联合创始人 Wei-Lin Chiang 和 Anastasios Angelopoulos
LMArena 前身叫 Chatbot Arena,最初起源于 2023 年伯克利的一项研究项目,后来更名为 LMArena。
Chatbot Arena 像一个用户社区评测中心,它改变了通过学科测试来评测 AI 技术的传统方式,将评价权交给了社区用户,并且采用匿名、众包的成对比较,来评估大模型。
用户还可以选择模型进行自我测试。
ChatGPT、Llama 1 等大模型的发布,为 Chatbot Arena 的出现提供了一个契机。
因为,当时人们还没有一个评测大模型的有效方法,于是 Chiang 就与伯克利研究人员 Anastasios Angelopoulos,以及 Ion Stoica 共同创办了 Chatbot Arena,也就是后来的 LMArena。
他们的想法,是做一个以社区为中心的公开的、基于网络的平台,邀请所有人来参与评测。
很快,Chatbot Arena 就引起了许多关注,成千上万的人前来投票,他们就利用这些用户投票数据,整理出了第一版排行榜。
最初上榜的,多是一些开源模型,唯一商用模型只有 Claude 和 GPT。
随着更多模型的不断加入,Chatbot Arena 的关注度也越来越高。各 AI 大厂纷纷请求将自己产品排名,并试图登上这个排行榜的榜首。
Chatbot Arena 的走红,也让众多科技公司将之视为 AI 技术的风向标,他们像华尔街交易员盯盘一样,密切关注着 Chatbot Arena 榜单的变化。
这一切都让 Meta AI 产品管理总监 Joseph Spisak 感到十分惊讶,他惊叹于几个学生竟能产生如此重大的影响力。
Chiang 希望 LMArena 能够成为一个对所有人都开放可及的平台,希望更多的用户来测试这些模型,表达他们的看法和偏好,以此帮助社区以及模型提供方,能够更好地基于这些真实用例来评估 AI。
正如 Chiang 所言,在 LMArena 社区中,最受欢迎、增长最快的模型,往往来自于真实场景中的用例。「纳米香蕉」就是最成功的例子之一。
匿名登场和盲测机制,让 nano-banana 在 LMArena 自然爆红,当时普通用户无法手动挑选 nano-banana,只有在 Battle 里随机遇到它,社区里大量帖子讨论「刷很多局才等到香蕉」的体验。
目前,Gemini 2.5 Flash Image 成为 LMArena 的「双料冠军」,获得了 Image Edit Arena、Text-to-Image 两个榜单的第一名。
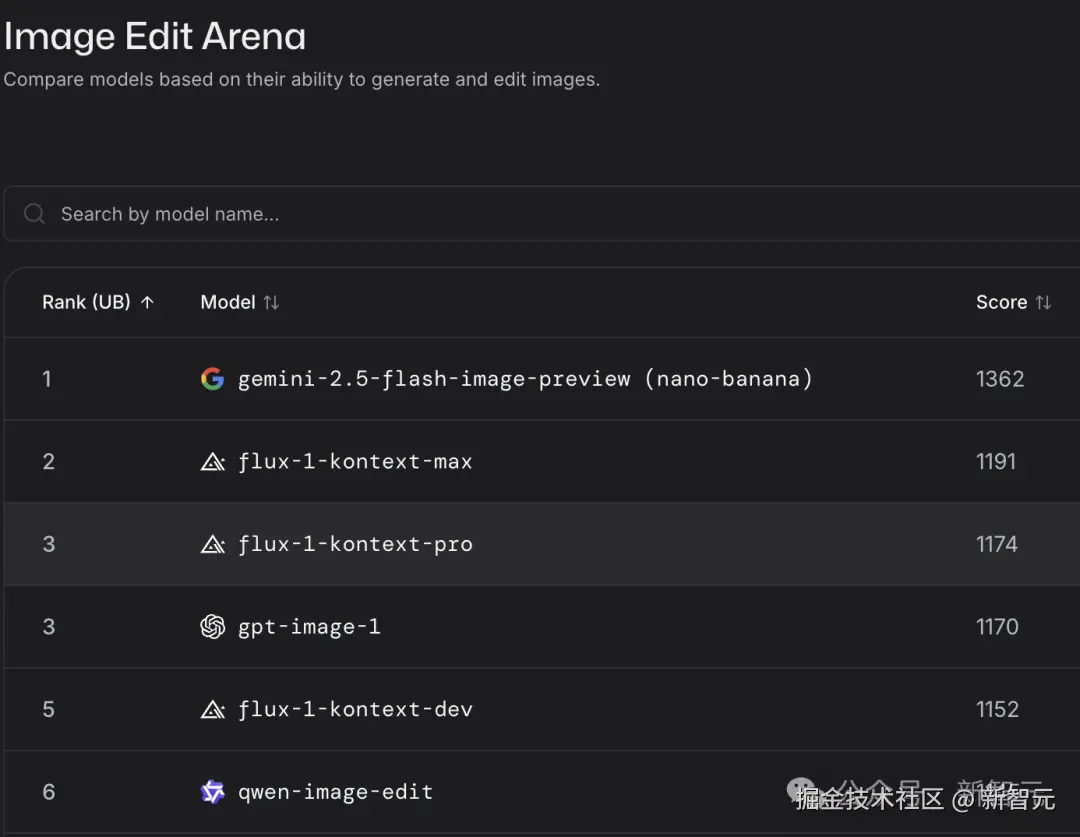
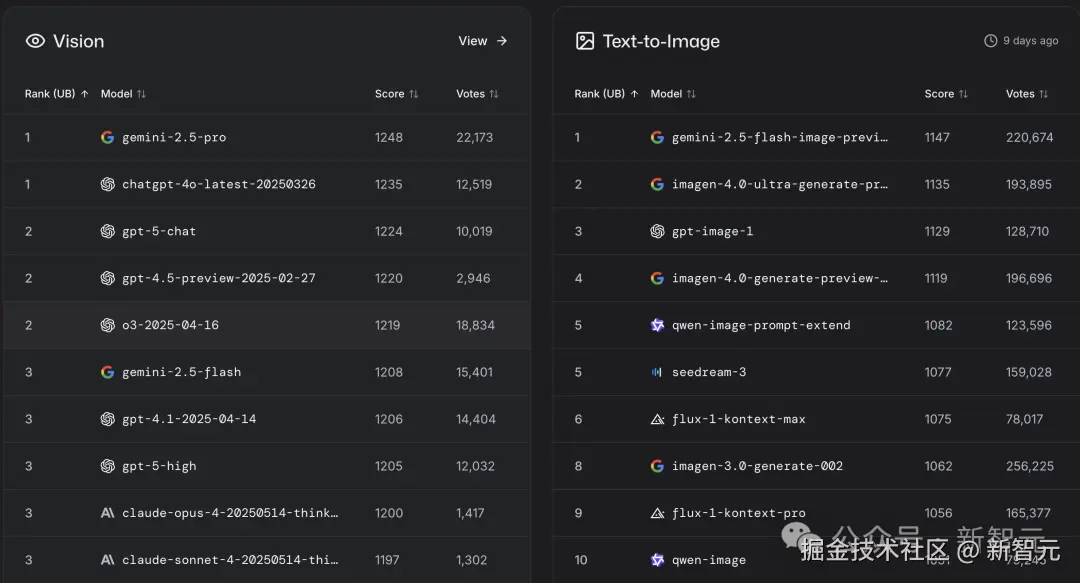
从 LMArena 排名上,还可以看出各个领域表现最佳的模型。
比如,在编码领域,Claude 排名最佳。在创意领域,Gemini 位居前列。
也许是 Meta 内部 AI 团队调整的缘故,Chiang 并没有听到太多 Llama 4 的消息。但他认为 Meta 正在构建的「全模型」,也许代表着未来行业的一大趋势。
「大模型厂商为何钟情「屠榜」?」
OpenAI、谷歌、Anthorpic 等大模型厂商,为什么都喜欢将它们的模型放到 LMArena 等排行榜上?
是为了建立品牌曝光度,还是获得用户反馈来改进他们的模型?
显然,曝光与背书,是一个最直观的短期效应。
LMArena 是业内关注度最高的公开榜之一,累计投票已达数百万次。而且科技媒体也喜欢频繁引用 LMArena 的数据,这些都可以为大模型品牌带来显著的口碑与流量红利。
其次,是更贴近「真实使用」的用户反馈。
LMArena 采用匿名、随机配对的投票方式,并用 Elo 计分,这样做减少了「品牌光环」「位置偏置」等主观影响,能真实反映用户对模型回答质量的评价。
Elo 系统最初用于国际象棋计分,也是 LMArena 排行榜背后的核心机制。在该规则下,每个选手(或模型)都有一个实力分数(Elo 分),每场对战后,会根据结果和预期,更新双方的 Elo 分。
这让每次用户投票都成为一场对战,模型 Elo 分经过成千上万次对战收敛,排名就可以更真实地反映用户偏好。
此外,LMArena 提供了一个跨厂商、跨开源 / 闭源的同台竞技舞台,这天然就会带来更高流量的曝光,也为用户提供了更丰富的选型信息。
正如 Chiang 所言,希望将 LMArena 打造成一个人人都能参与、都能表达自己观点的开放空间。
这里的一切都是社区机制来驱动,鼓励大家提问和投票,表达自己对不同模型的评价。
对于大模型厂商来说,LMArena 提供了一个很好的「照镜子」的机会。
大模型厂商可以看清自己在所在领域的排行情况,以及获得 LMArena 根据社区反馈提供的报告和分析,详细评估自己模型的表现,对症下药提升模型能力。
「需要新的 LLM 基准测试吗?」
当所有模型,都非常接近基准测试了,还需要新的基准测试吗?
Chiang 认为这一点是非常必要的。但是其中一个核心原则,是这些基准要扎根于真实世界用例。
比如,能够超越传统的基准测试,转向更贴近真实用户场景的基准测试,尤其是善于使用 AI 工具完成任务的专业人士所驱动的基准。
以 LMArena 最新推出的 WebDev 基准测试为例,用户可以用提示词让一个模型搭建网站。这种基准测试,可以更好地将 AI 技术与真实世界用例紧密相连,使其更快在实际应用场景落地。
针对 MIT 关于「大多数投资 AI 的公司都没有看到投资回报」的报告,Chiang 认为这是一项很有意思的研究。
他认为该研究反映了「将 AI 与真实世界用例紧密相连尤为重要」,这也正是他要将 LMArena 平台扩展到更多行业的原因。
希望通过更多扎根于真实用例的基准测试,去弥合技术与实用场景的鸿沟,并为之提供可衡量的标准。
Chiang 表示,LMArena 的目标是利用平台数据来理解模型的局限性,保持数据研究流程的透明,并将数据发布出来,以此推动社区平台的持续建设。
对于大模型厂商和「用户观众」来说,这里是一个永不落幕的竞技场。
参考资料: