最近,OpenAI 的 GPT Realtime 和 Google 的 Gemini 2.5 接连亮相,给语音助手带来了「真正的"实时对话"」体验 ------ 你说一句,它就秒接;它正说,你也能随时打断,回应自然不尬聊。这才是真正像人一样"插话"的自然对话模式。
这其实得益于全双工语音对话模型 ------它颠覆了过去"你说我等句子结束再听"的半双工形式,实现了"说"和"听"同时进行 。它靠感知模块分分钟捕捉你语音细节,再凭模型精准判断:该回应、该等待,还是该打断。依靠策略,让对话更自然,延迟低、互动快。实测响应延迟降低 3 倍以上,50% 对话不到 500 毫秒就回复到了出声阶段。
就在最近,OpenAI 发布了 GPT-Realtime 语音模型,不仅能无缝处理打断和修正,还能捕捉笑声、停顿等非语言线索,甚至支持对话中无缝切换语言。几乎同时,社交平台Soul也展示了其自研端到端全双工语音通话大模型,打破传统"轮次对话"模式,赋予 AI 自主决策对话节奏的能力。

💡 技术揭秘:什么是全双工语音交互?
简单来说,全双工语音交互允许设备在接收语音输入的同时并行处理和响应,就像人类面对面聊天一样自然。与传统半双工模式(你需要说完再等待响应)不同,全双工支持:
● 实时打断:随时修正或更改指令
● 边听边说:无需等待对方说完再响应
● 无效语音拒识:智能过滤背景噪音和非指令语音
这种技术让智能音箱能在播放音乐时同时接收指令,让车载助手在导航时处理来电,让会议系统实时分离多个发言者的声音并提供翻译。
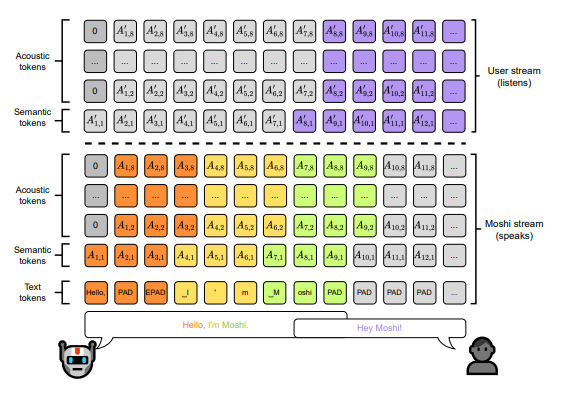
想让这些模型像真人一样灵活交谈,光算法还不够------「数据」才是重中之重。语音中各种打断、反馈(比如"嗯""对对")、双说重叠、自然停顿、口语化表达,都需要真实、多样且标注精准的对话样本。这才能让模型学会何时接什么、怎么回更自然。
全双工语音模型尤其如此,它需要大量标注精准的语音数据来学习:
● 多人语音分离:识别和分离重叠的语音信号
● 上下文理解:捕捉对话中的语境和情感波动
● 多语言处理:适应不同语言和方言的表达特点
● 副语言信息:识别笑声、叹息、停顿等非语言线索
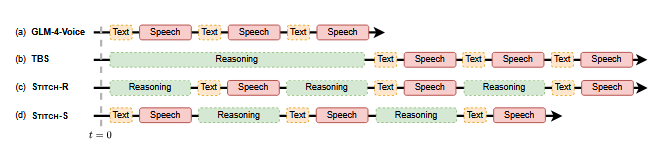
现在市面上语音训练数据多半是"整段录音 + 完整话轮",缺少那些"说一半响应""被切入打断"这种自然且难建模的片段。甚至连行业评测集最近都才刚升级到支持"overlap handling"的标准版本 Full-Duplex-Bench v1.5------明确考察用户打断、背景话音、侧谈打断等场景下的响应质量与流畅性。
🔥 海天瑞声打造9000小时中文全双工语音对话数据集****

海天瑞声专注打造**「 9000小时中文全双工语音对话数据集」,该数据集具有以下核心优势:**
✅ 产品特色:
数据集包含约 10000 名发音人 ,总时长约 9000 小时 ,覆盖不同年龄层,发音人性别平均,手机录制,丰富的停顿标注、口语化表达,字准率 97%。
✅ 场景丰富:
涵盖日常闲聊、家庭生活、朋友交流、商务会议、AI助手、新能源(电动汽车、电动自行车)等场景
✅ 精确标注,支持多种任务:
每段音频都经过专业的分轨处理,每个说话人都有独立音轨,覆盖对话打断、话轮抢接、两人交互等复杂场景,并附有:
-
高精度转写文本(字准率97%)
-
说话人标签(性别、年龄、口音区)信息
-
时间戳标注、环境标注、以及特殊场景标记
-
副语言信息(笑声、叹息、停顿、反馈词等)
-
语音重叠和噪音标签
✅ 合规可靠,商用无忧:
我们严格遵循国际标准认证(ISO/IEC 27001、ISO/IEC 27701:2019),数据集具备合规采集与授权流程,支持商业模型部署,无需担心版权风险。
从 GPT Realtime 到 Gemini 2.5,「全双工」 才是语音助手下一代交互的核心竞争力, 而要打造出这种「真正流畅、可打断的对话体验」,您的模型背后必须有人类训练师无法复制的------超靠谱的**「9000小时中文全双工语音对话数据集」**,让它助力您的项目也能像 GPT Realtime 那样"随时插话,像人一样自然对话"。
参考文献:
1https://arxiv.org/abs/2405.19487
2https://arxiv.org/abs/2507.23159
3https://openai.com/index/introducing-gpt-realtime/
4https://arxiv.org/abs/2507.23159
5https://arxiv.org/abs/2507.15375
6https://arxiv.org/abs/2410.00037
如您希望申请数据集样例,欢迎联系我们
电话咨询:400-679-7787
邮件咨询:contact@dataoceanai.com