目录
[1. 并查集原理](#1. 并查集原理)
[2. 并查集实现](#2. 并查集实现)
[3. 并查集应用](#3. 并查集应用)
1. 并查集原理
在一些应用问题中,需要将n个不同的元素根据某种联系划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于哪个集合的运算。
适合于描述这类问题的抽象数据类型称为并查集(union-findset)。
比如:某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不
同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3,
4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个
数。(负号下文解释)
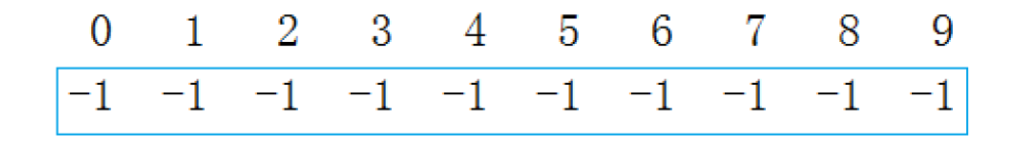
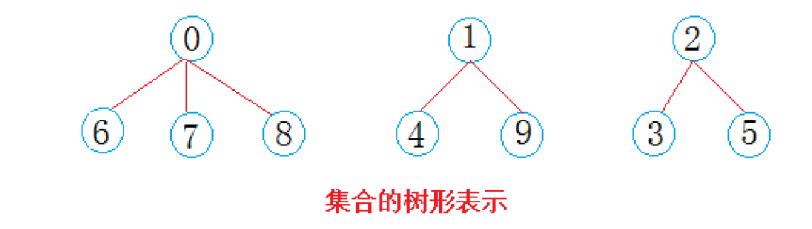
毕业后,学生们要去公司上班,每个地方的学生自发组织成小分队一起上路,于是:
西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识
了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。
一趟火车之旅后,每个小分队成员就互相熟悉,称为了一个朋友圈,之前每个小队,队长带领队员,我们可以视作一棵树,大家组成的朋友圈就可以视作森林,这个森林就是并查集,即并查集就是森林。
与堆的实现类似,并查集主要通过数组下标表示关系。

现在假设一组数据,我们可以将其映射到数组的每个位置上,数组初始化为-1。
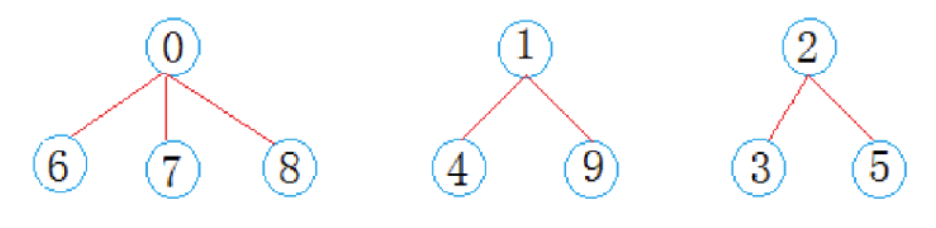
根据小团体的标号,我们就可以将每个人映射到数组中,为了表示数据间的相互关系,现在队员映射到的位置里面存储队长映射位置的下标,同时队长每有一个队员,队长位置存储的值就-1。
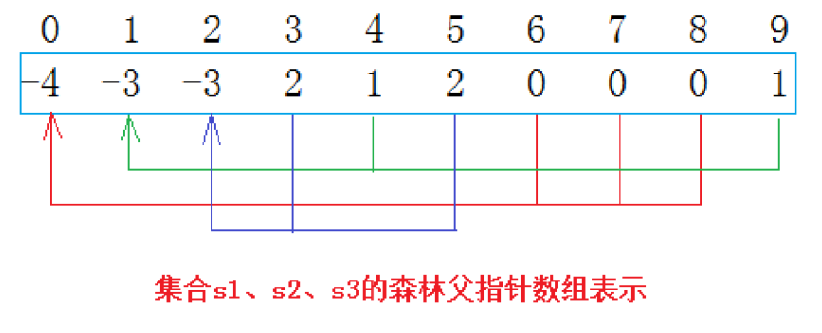
最终根据映射关系我们就可以做出上图
从上图可以看出:编号6,7,8同学属于0号小分队,该小分队中有4人(包含队长0,每一个-1就代表一个人);编号为4和9的同学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3个人(包含队长1)。
仔细观察数组中内值分布,可以得出以下结论:
1. 数组的下标对应集合中元素的编号
2. 数组中如果为负数,负号代表根,数字代表该集合中元素个数
3. 数组中如果为非负数,代表该元素双亲在数组中的下标
在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个
小圈子的学生相互介绍,最后成为了一个小圈子:
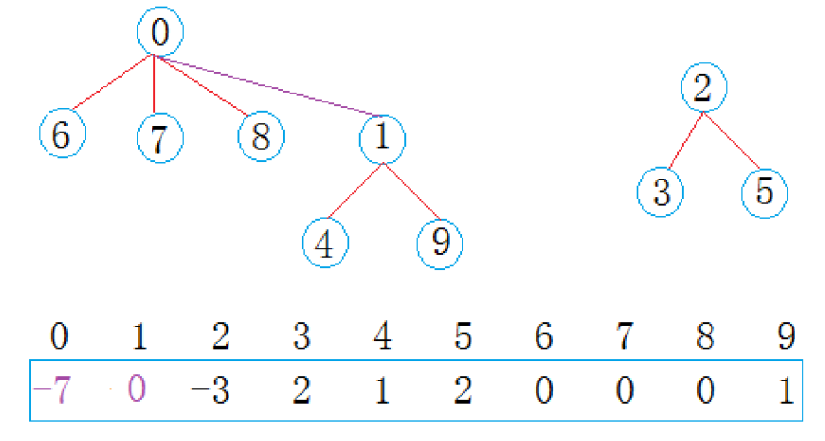
现在0集合有7个人,2集合有3个人,总共两个朋友圈。同时1内部就要存储其父亲的映射位置,0映射位置存储数据也要变成-7,表示这个集合中共有7个人。
通过以上例子可知,并查集一般可以解决一下问题:
1. 查找元素属于哪个集合
沿着数组表示树形关系往上一直找到根(即:树中中元素为负数的位置)2. 查看两个元素是否属于同一个集合
沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在3. 将两个集合归并成一个集合
将两个集合中的元素合并将一个集合名称改成另一个集合的名称4. 集合的个数
遍历数组,数组中元素为负数的个数即为集合的个数。
2. 并查集实现
cpp
class UnionFindSet
{
public:
// 初始时,将数组中元素全部设置为-1
UnionFindSet(size_t size)
: _ufs(size, -1)
{
}
// 给一个元素的编号,找到该元素所在集合的名称
int FindRoot(int index)
{
// 如果数组中存储的是负数,找到根,否则一直继续
while (_ufs[index] >= 0)
{
index = _ufs[index];
}
return index;
}
//将两个元素合并到一个集合中
bool Union(int x1, int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
// 根相同,x1已经与x2在同一个集合
if (root1 == root2)
return false;
// 将两个集合中元素合并
_ufs[root1] += _ufs[root2];
// 将其中一个集合名称改变成另外一个(改变指向的根)
_ufs[root2] = root1;
return true;
}
// 数组中负数的个数,即为集合的个数
size_t Count()const
{
size_t count = 0;
for (auto e : _ufs)
{
if (e < 0)
++count;
}
return count;
}
private:
vector<int> _ufs;
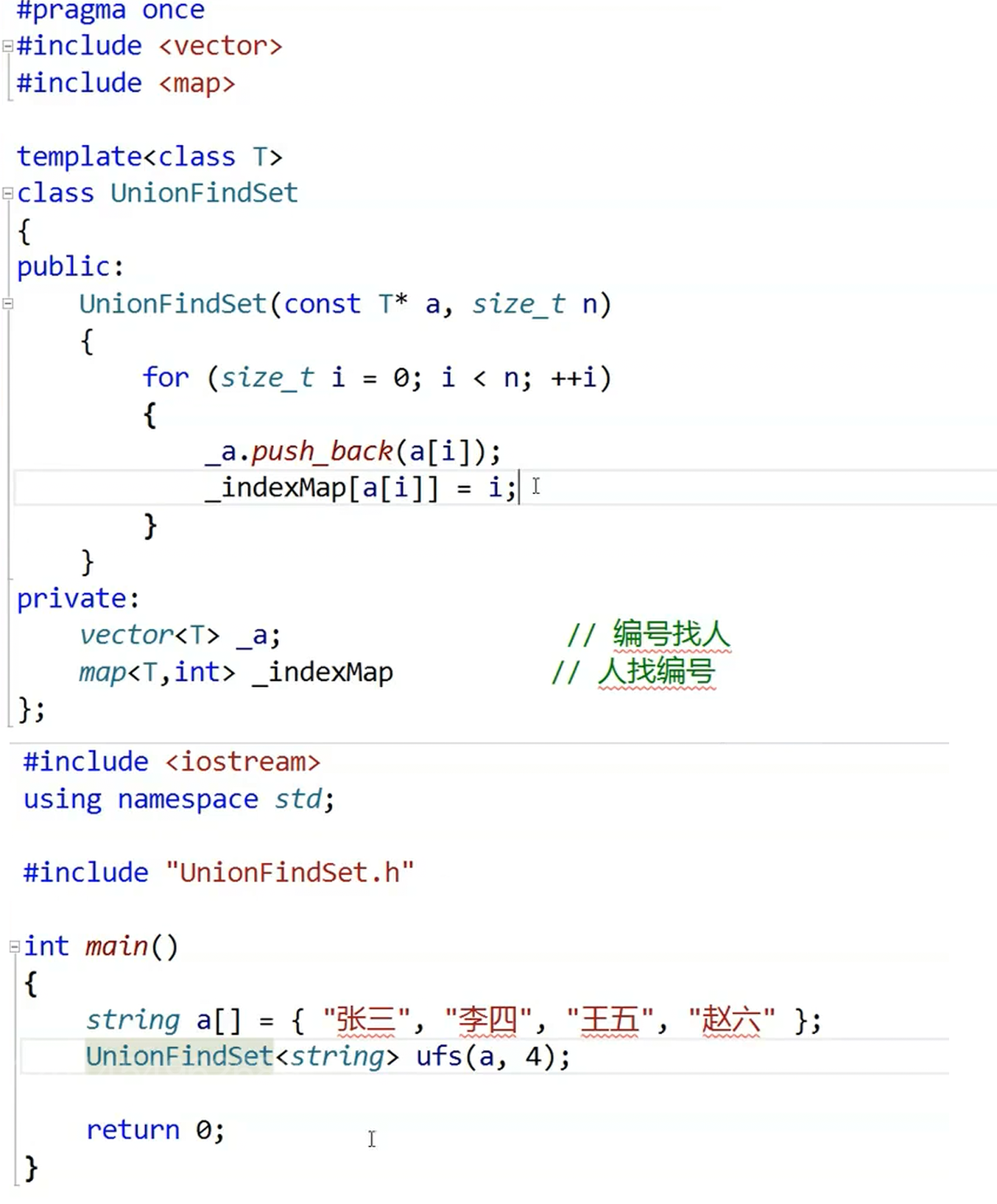
};注:以上的情况仅仅针对可以直接映射到数组的数据,如果针对的数据无法直接映射到数组下标,那么需要先增加一层映射,用来给数据增加编号。
如下图,数据是人名的情况,我们可以先使用map,让数据从0、1、2、3........依次编号。
2.1并查集的优化问题
在上面的实现当中,将两个集合合并的过程中,其实并没有具体的规则,比如将哪个集合合并到哪个集合上。
但是在具体的实践过程中,随着数据量级的不断增大,集合的合并可能会造成,整体的树太高,从而导致寻找根的效率答复下降。
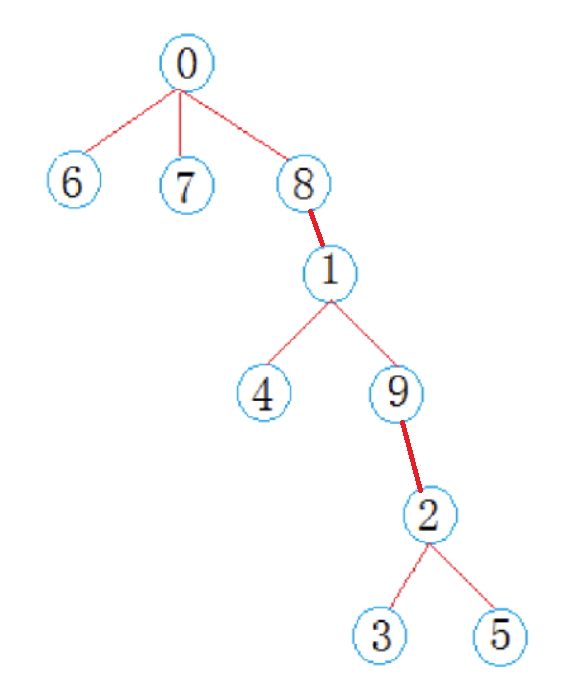
如上图,对于5来说找到根的0的效率是比较差的,整体的路径比较长。
因此并查集也衍生出了压缩路径的优化需求。
思路一,就是合并时将数据量小的合集往大合集合并。
cpp
//将两个元素合并到一个集合中
bool Union(int x1, int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
// 根相同,x1已经与x2在同一个集合
if (root1 == root2)
return false;
//数据量小的合集往大合集合并
if (abs(root1) < abs(root2))
swap(root1, root2);
// 将两个集合中元素合并
_ufs[root1] += _ufs[root2];
// 将其中一个集合名称改变成另外一个(改变指向的根)
_ufs[root2] = root1;
return true;
}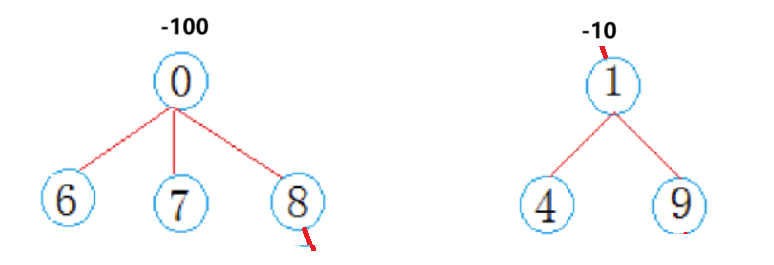
以上图为例,假设左边集合根有99个孩子,右边有9个,左边是大合集,这个时候我们发现如果我们合并,不断是大集合合并到小集合,还是小集合合并到大集合,对于某一个集合来说,其所有的节点都比原先要多出一层的路径,所以如果大集合合并到小集合,100节点多出一层路径,而小集合合并到大集合只会有10个节点多出一层。
所以通过集合合并时,小合集合并到大合集的优化方式可以起到很好优化效果。
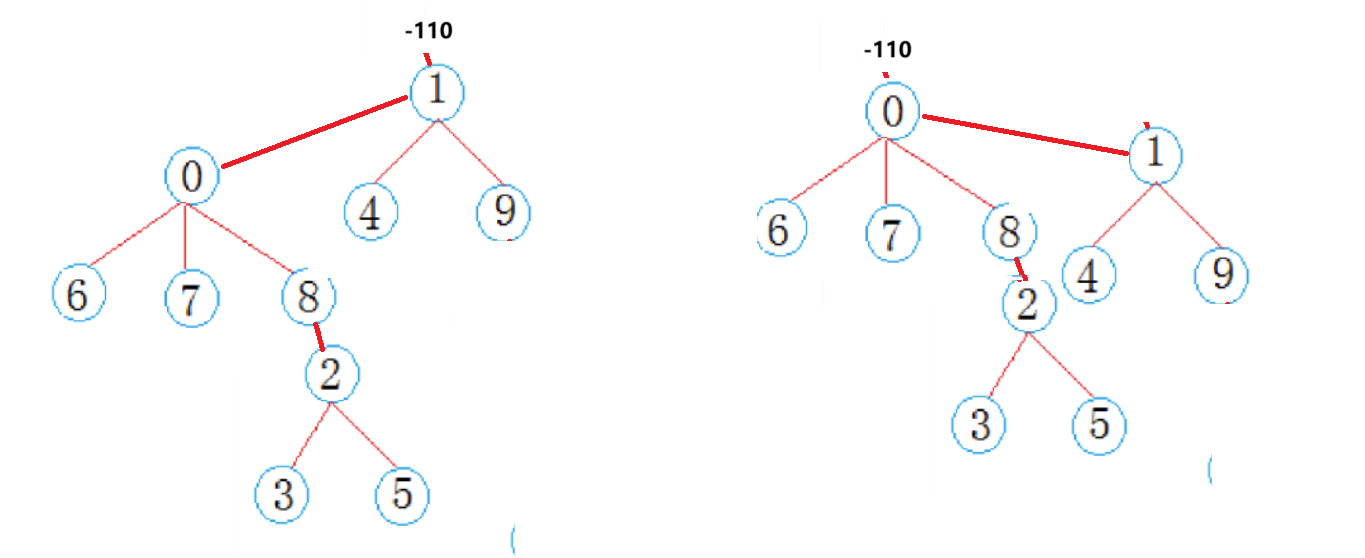
思路二:是在FindRoot函数中,我们可以将多层节点的父亲直接变成最顶层节点
cpp
// 给一个元素的编号,找到该元素所在集合的名称
int FindRoot(int index)
{
// 如果数组中存储的是负数,找到根,否则一直继续
while (_ufs[index] >= 0)
{
index = _ufs[index];
}
//压缩路径
while(_ufs[x] >= 0){
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return index;
}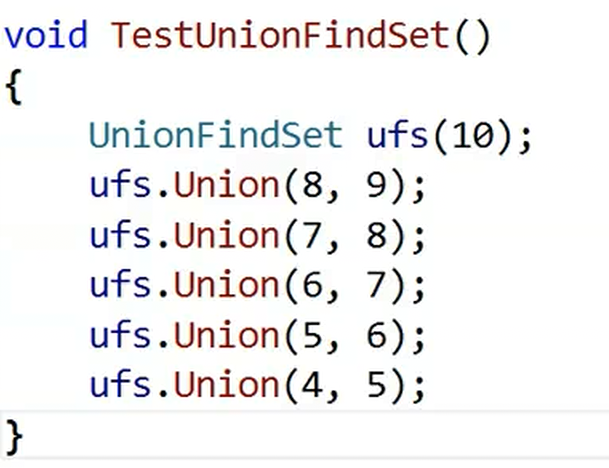
如上图,假设我们不加优化,合并后就会变成下图
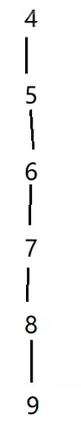
我们发现对于9来说寻找根的效率退化非常大。每次合并,我们直接将节点合并到最顶层的根,树高就可以控制了。
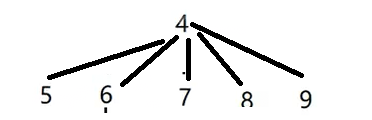
3. 并查集应用

对于这道题目,不管是直接还是间接相连,从并查集的角度出发,只要相连,就意味着节点间存在关系,属于同一个集合中。因此并查集中的集合的个数也就是我们本体中省份的个数。
cpp
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
// 手动控制并查集
//本体节点天然就可以视作编号,可以直接映射
vector<int> ufs(isConnected.size(), -1);
// 查找根
auto findRoot = [&ufs](int x)
{
while (ufs[x] >= 0)
x = ufs[x];
return x;
};
//遍历,根据提供的直接或间接连接的关系将节点合并到同一个集合中
for (size_t i = 0; i < isConnected.size(); ++i)
{
for (size_t j = 0; j < isConnected[i].size(); ++j)
{
if (isConnected[i][j] == 1)
{
// 合并集合
int root1 = findRoot(i);
int root2 = findRoot(j);
if (root1 != root2)
{
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
}
//集合个数就是省份的个数
int n = 0;
for (auto e : ufs)
{
if (e < 0)
++n;
}
return n;
}
};
本题中是要我们根据符号判断是否相悖,我们可以将相等视作两个字母可以合并到一个集合中,如果后续我们判断不相等的字母却在同一个集合中,就说明前后条件是相悖。
cpp
/*
解题思路:
1. 将所有"=="两端的字符合并到一个集合中
2. 检测"!=" 两端的字符是否在同一个结合中,如果在不满足,如果不在满足
*/
class Solution {
public:
bool equationsPossible(vector<string>& equations) {
vector<int> ufs(26, -1);
auto findRoot = [&ufs](int x)
{
while (ufs[x] >= 0)
x = ufs[x];
return x;
};
// 第一遍,先把相等的值加到一个集合中
//因为这里是字母,要通过-'a'才能映射到数组中
for (auto& str : equations)
{
if (str[1] == '=')
{
int root1 = findRoot(str[0] - 'a');
int root2 = findRoot(str[3] - 'a');
if (root1 != root2)
{
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
// 第二遍,如果不相等的字母在一个集合,就说明相悖了
// 返回false
for (auto& str : equations)
{
if (str[1] == '!')
{
int root1 = findRoot(str[0] - 'a');
int root2 = findRoot(str[3] - 'a');
if (root1 == root2)
{
return false;
}
}
}
return true;
}
};