点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月01日更新到: Java-113 深入浅出 MySQL 扩容全攻略:触发条件、迁移方案与性能优化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节完成的内容如下:
- Spark Super Word Count 程序 Scala语言编写
- 将数据写入MySQL、不写入MySQL等编码方式
- 代码的详细解释与结果

进程通信与序列化机制
Spark作为分布式计算框架,其核心架构基于Driver-Executor模式。在这个架构中:
-
SparkContext的角色:SparkContext是Spark应用程序的入口点,代表Driver程序与集群资源管理器(如YARN、Mesos或Standalone)进行通信。它负责:
- 申请集群资源
- 将用户程序转换为任务
- 调度任务到Executor上执行
- 监控任务执行状态
-
进程通信与序列化:
- 由于Driver和Executor运行在不同的JVM进程中,所有跨进程的数据传输都需要序列化
- Spark使用Java序列化或Kryo序列化来传输闭包和函数对象
- 闭包(closure)中引用的所有外部变量都会被序列化并传输到Executor端
-
自定义RDD操作的注意事项:
Driver端初始化工作:
- RDD的转换操作(如map、filter等)定义在Driver端
- 广播变量的创建和分发
- 累加器的初始化
- 示例:
val rdd = sc.parallelize(1 to 100) // 在Driver端初始化
Executor端实际执行:
- 真正的数据处理在Executor节点上执行
- 每个Task处理RDD的一个分区
- 示例:
rdd.map(_ * 2) // map函数会在Executor端执行
-
典型问题与解决方案:
- 序列化错误:当自定义函数引用了不可序列化的对象时
scala
class NonSerializable {}
val obj = new NonSerializable
rdd.map(x => x + obj) // 会导致序列化错误 解决方案:要么使对象可序列化,要么在函数内部创建对象- 闭包陷阱:变量在Driver端初始化但在Executor端使用
scala
var counter = 0
rdd.foreach(x => counter += x) // 不会按预期工作
scss
解决方案:使用累加器(Accumulator)来实现跨节点的计数- 最佳实践:
- 尽量使用Spark内置的转换操作和动作
- 自定义函数应尽量简单且可序列化
- 避免在RDD操作中创建大对象
- 对于需要在多个操作中重用的数据,考虑使用广播变量
理解Driver和Executor的分工是编写高效Spark程序的关键,这有助于避免常见的分布式计算陷阱和提高程序性能。
测试代码
遇到问题
scala
class MyClass1(x: Int) {
val num = x
}
object SerializableDemo {
def main (args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SerializableDemo")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd1 = sc.makeRDD(1 to 20)
def add1(x: Int) = x + 10
val add2 = add1 _
// 过程和方法 都具备序列化的能力
rdd1.map(add1(_)).foreach(println)
rdd1.map(add2(_)).foreach(println)
// 普通的类不具备序列化能力
val object1 = new MyClass1(10)
// 报错 提示无法序列化
// rdd1.map(x => object1.num + x).foreach(println)
}
}解决方案1
scala
case class MyClass2(num: Int)
val object2 = MyClass2(20)
rdd1.map(x => object2.num + x).foreach(println)解决方案2
scala
class MyClass3(x: Int) extends Serializable {
val num = x
}
val object3 = new MyClass3(30)
rdd1.map(x => object3.num + x).foreach(println)解决方案3
scala
class MyClass1(x: Int) {
val num = x
}
lazy val object4 = new MyClass1(40)
rdd1.map(x => object4.num + x).foreach(println)完整代码
scala
package icu.wzk
import org.apache.spark.{SparkConf, SparkContext}
class MyClass1(x: Int) {
val num = x
}
case class MyClass2(num: Int)
class MyClass3(x: Int) extends Serializable {
val num = x
}
object SerializableDemo {
def main (args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SerializableDemo")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd1 = sc.makeRDD(1 to 20)
def add1(x: Int) = x + 10
val add2 = add1 _
// 过程和方法 都具备序列化的能力
rdd1.map(add1(_)).foreach(println)
rdd1.map(add2(_)).foreach(println)
// 普通的类不具备序列化能力
val object1 = new MyClass1(10)
// 报错 提示无法序列化
// rdd1.map(x => object1.num + x).foreach(println)
// 解决方案1 使用 case class
val object2 = MyClass2(20)
rdd1.map(x => object2.num + x).foreach(println)
// 解决方案2 实现 Serializable
val object3 = new MyClass3(30)
rdd1.map(x => object3.num + x).foreach(println)
// 解决方法3 延迟创建
lazy val object4 = new MyClass1(40)
rdd1.map(x => object4.num + x).foreach(println)
sc.stop()
}
}注意事项
- 如果在方法、函数的定义中引入了不可序列化的对象,也会导致任务不能够序列化
- 延迟创建的解决方案比较简单,且实用性广
RDD依赖关系
基本概念
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。 RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,可根据这些信息来重新运算和恢复丢失的数据分区。
 RDD和它的依赖的父RDDs的关系有两种不同的类型:
RDD和它的依赖的父RDDs的关系有两种不同的类型:
- 窄依赖(narrow dependency):1:1或n:1
- 宽依赖(wide dependency):n:m 意味着有 shuflle
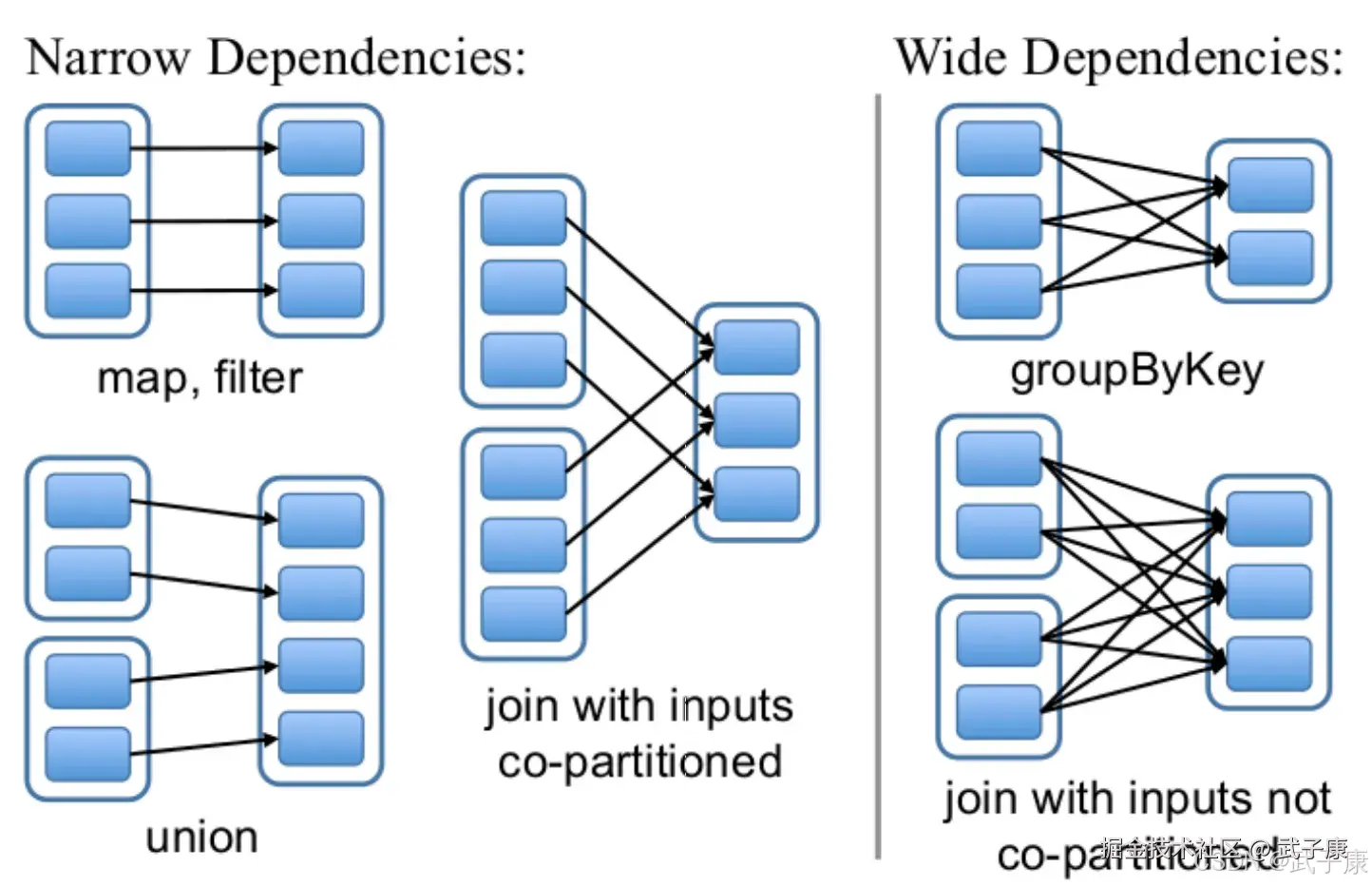 RDD任务切分中间分为:Driver program、Job、Stage(TaskSet) 和 Task
RDD任务切分中间分为:Driver program、Job、Stage(TaskSet) 和 Task
- Driver program:初始化一个SparkContext即生成一个Spark应用
- Job:一个Action算子就会生成一个Job
- Stage:根据RDD之间的依赖关系不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage
- Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task
- Task是Spark中任务调度的最小单位,每个Stage包含许多Task,这些Task执行的计算逻辑是相同的,计算的数据是不同的
- DriverProgram -> Job -> Stage -> Task 每一层都是 1 对 N 的关系
再回WordCount
代码部分
你可以用代码执行,也可以在 SparkShell 中执行。
scala
package icu.wzk
import org.apache.spark.{SparkConf, SparkContext}
object ReWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SparkFindFriends")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd1 = sc.textFile("goodtbl.java")
val rdd2 = rdd1.flatMap(_.split("\\+"))
val rdd3 = rdd2.map((_, 1))
val rdd4 = rdd3.reduceByKey(_ + _)
val rdd5 = rdd4.sortByKey()
rdd5.count()
// 查看RDD的血缘关系
rdd1.toDebugString
rdd5.toDebugString
// 查看依赖
rdd1.dependencies
rdd1.dependencies(0).rdd
rdd5.dependencies
rdd5.dependencies(0).rdd
sc.stop()
}
}提出问题
上面的WordCount中,一共有几个Job,几个Stage,几个Task?  答案:1个Job,3个Stage,6个Task
答案:1个Job,3个Stage,6个Task
RDD持久化/缓存
基本概念
涉及到的算子:persist、cache、unpersist 都是 Transformation 算子
缓存机制详解
缓存是将计算结果写入不同的存储介质的过程,用户可以通过定义存储级别(StorageLevel)来指定缓存的具体方式。Spark目前支持以下几种存储级别:
- MEMORY_ONLY:只存储在内存中(默认级别)
- MEMORY_AND_DISK:优先存储在内存,内存不足时溢出到磁盘
- MEMORY_ONLY_SER:序列化存储在内存中
- MEMORY_AND_DISK_SER:序列化存储在内存,内存不足时溢出到磁盘
- DISK_ONLY:只存储在磁盘上
- OFF_HEAP:存储在堆外内存(Tachyon)
缓存的重要性
通过缓存机制,Spark避免了RDD上的重复计算,能够极大提升计算的速度。例如,在一个迭代算法中,如果某个RDD被多次使用,缓存它可以避免每次使用时都重新计算。
RDD持久化或缓存是Spark最重要的特征之一,也是Spark构建迭代算法和快速交互式查询的关键所在。典型的应用场景包括:
- 机器学习中的迭代算法(如梯度下降)
- 交互式数据查询(如Spark SQL)
- 图计算算法(如PageRank)
性能优势
Spark之所以非常快,一个重要原因就是支持在内存、缓存中持久化数据。当持久化一个RDD后:
- 每个计算节点都会把计算的分片结果保存在内存中
- 对该数据集进行后续操作(Action)时,可以直接使用缓存的数据
- 避免了重复计算带来的性能损耗
持久化执行原理
使用persist()方法时需要注意:
- 调用persist()只是将一个RDD标记为需要持久化,并不会立即执行计算
- 真正的计算和持久化操作会在遇到第一个行动操作(Action)时触发
- 持久化是惰性执行的,与Spark的整体计算模型一致
例如:
python
rdd = sc.parallelize(range(1, 100))
# 标记持久化
rdd.persist(StorageLevel.MEMORY_ONLY)
# 此时还未真正计算和缓存
print(rdd.count()) # 第一次行动操作,触发计算和缓存
print(rdd.sum()) # 直接使用缓存数据,无需重新计算相关操作
- cache():等同于persist(StorageLevel.MEMORY_ONLY)
- unpersist():手动移除缓存
- 注意:缓存占用内存空间,不再需要时应及时释放
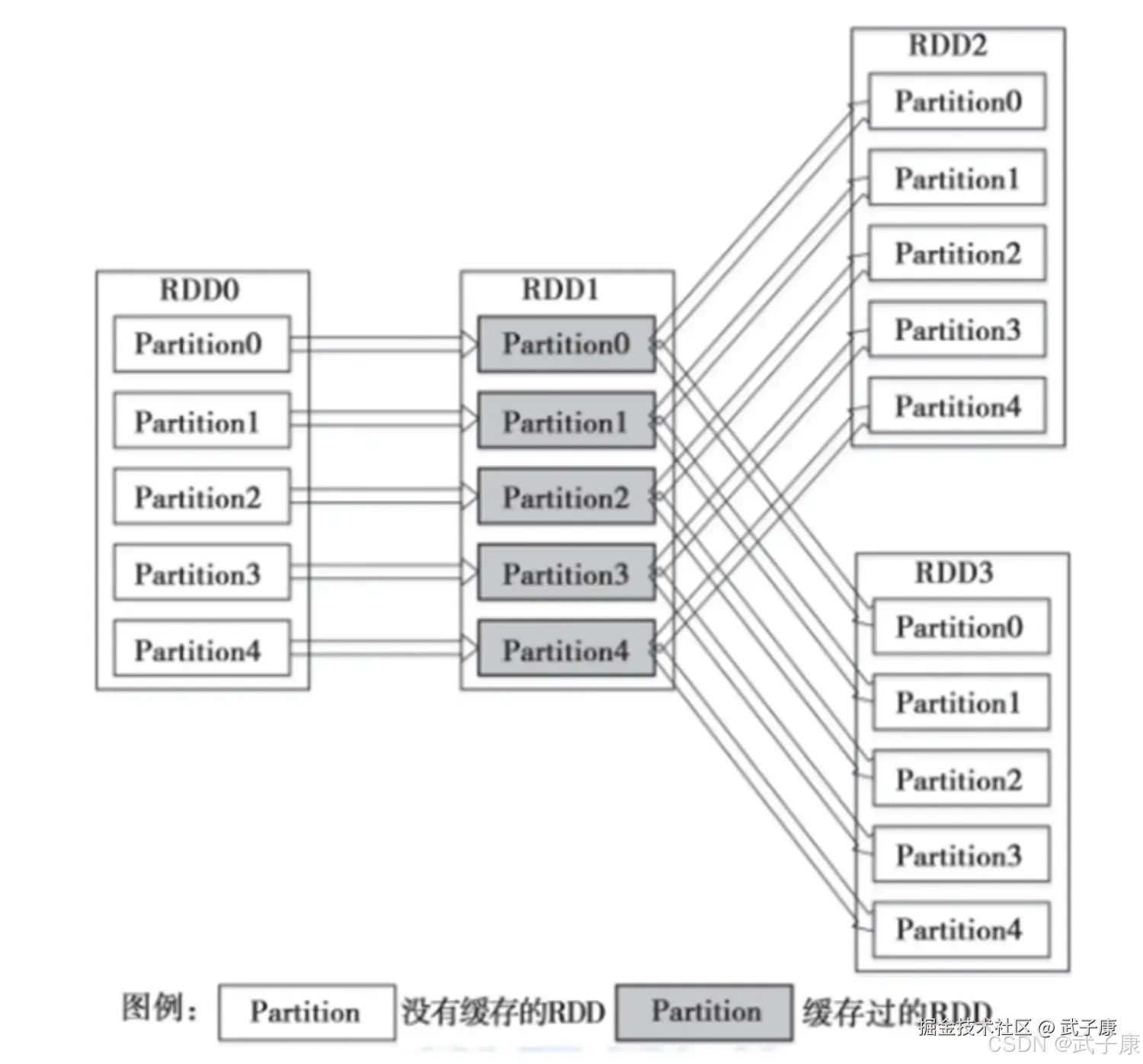
-
RDD缓存的重要性 :在Spark应用中,如果一个RDD会被多次使用(例如在多个action操作中被调用),且该RDD的计算过程涉及复杂的转换操作(如多表join、聚合计算等),那么将其缓存(通过
persist()或cache()方法)可以显著提升性能。例如,在对一个大型日志数据集先进行filter操作后,如果后续需要多次执行count和collect等操作,缓存过滤后的RDD能避免重复执行耗时的过滤计算。 -
缓存的容错机制详解 :
Spark的RDD缓存采用"血缘关系(Lineage)+重算"的容错机制。当缓存的RDD分区因节点故障或内存不足被清除时:
- Spark会通过RDD的血缘关系图(记录所有转换操作的DAG)确定需要重算的分区
- 仅重新执行从原始数据到该分区的转换链(如
textFile→map→filter) - 重算过程是自动触发的,对用户透明。例如,若缓存了经过10次转换的RDD,丢失后不需要手动重新计算,系统会自动从最近的持久化点开始重算。
-
分区级重算的优势 :
RDD的分区特性(Partition)使得故障恢复非常高效:
- 每个分区独立存储和计算,如200个分区的RDD只丢失2个分区时,仅需重算这2个分区
- 重算过程可以并行执行,不同worker节点可以同时计算不同丢失分区
- 与完整重算相比,分区级恢复能节省90%以上的计算资源(假设仅有10%分区丢失)
- 实际案例:在TB级数据分析中,某个节点故障导致5%分区丢失,系统在30秒内就完成了受影响分区的重算,而完整重算需要10分钟
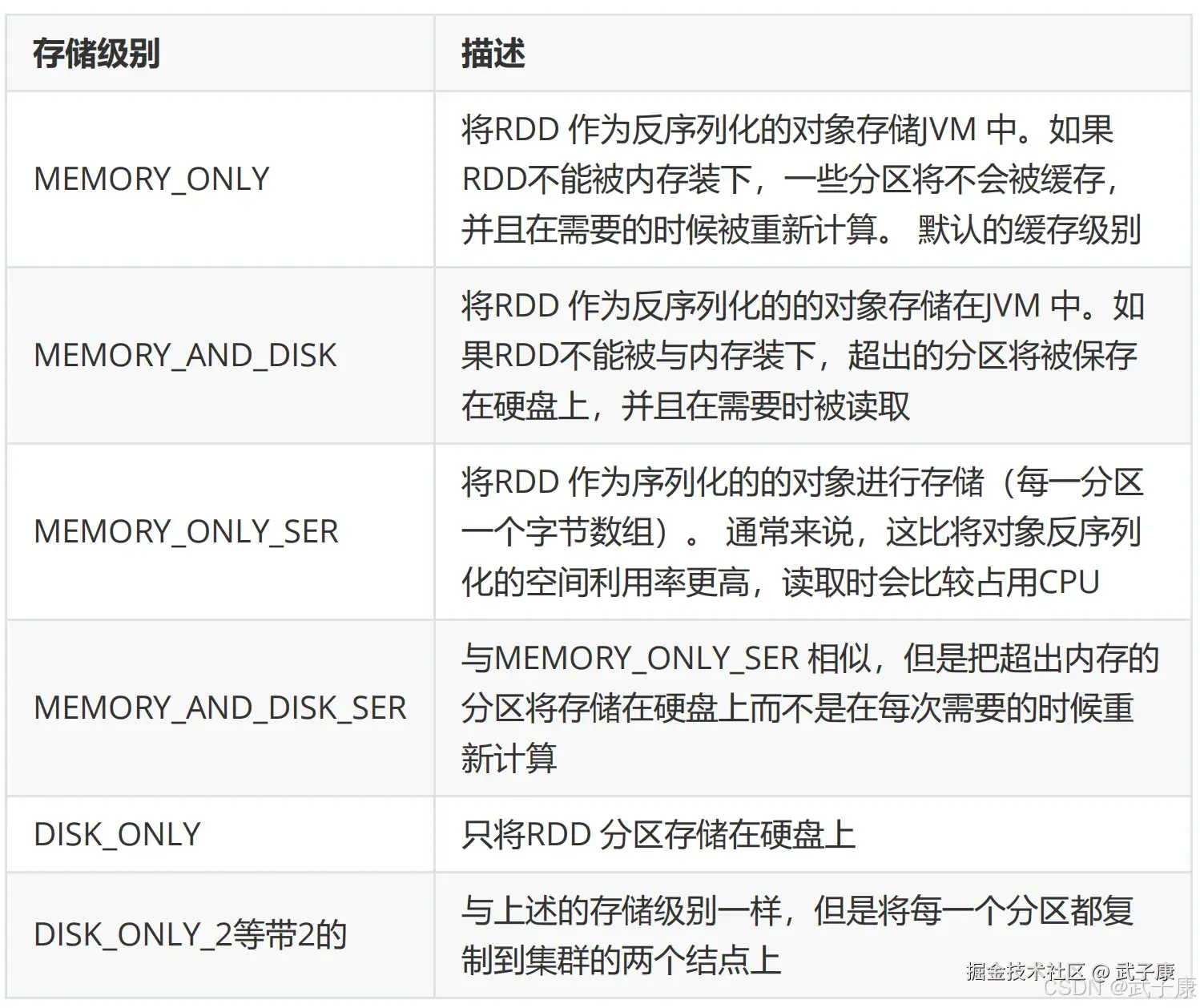
持久化级别
使用 cache() 方法时,会调用 persist(MEMORY_ONLY),即
shell
cache() == persist(StorageLevel.Memory.ONLY)对于其他的存储级别,如下图:
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
- DISK_ONLY_2