前言
又是一年"金九银十"秋招季,大模型相关的技术岗位竞争也到了白热化阶段。为满足大家碎片化时间复习补充面试知识点的需求(泪目,思绪回到前两年自己面试的时候),笔者特开设 《大模型工程面试经典》 专栏,持续更新工作学习中遇到大模型技术与工程方面的面试题及其讲解。每个讲解都由一个必考题和相关热点问题组成,小伙伴们感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。
一、面试题: 如何准备专业领域微调数据集
1.1 问题浅析
这个问题看似基础,但在实际面试中非常考验大家工程思维和落地经验的问题。大家往往只会回答"收集一些专业文档"、"准备相应格式的问答对",实际上这些远远不够。要真正准备一个能够支撑微调的高质量数据集,需要经历一整套的系统流程:
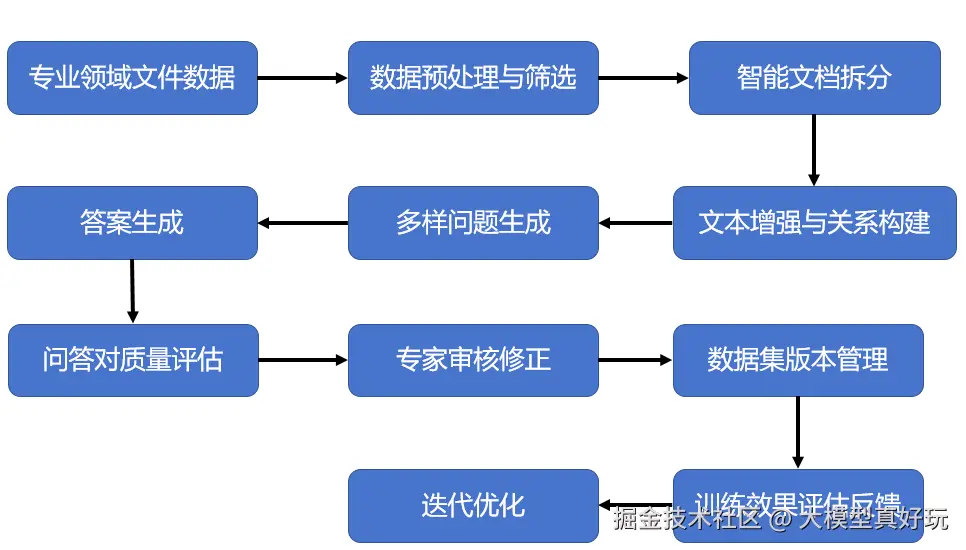
从大的方面来说创建高质量的微调数据集往往需要经历两个阶段:
1.数据处理: 用于将原始文档转化为问答对
2.数据验证与优化: 用于进一步提升微调问答对质量
只有经历这两个阶段,零散的资料才能变成一个直接用于训练的专业微调数据集。
1.2 标准答案
要准备一个真正专业、可以落地的微调数据集,绝不能只停留在简单的问答收集,而是要遵循一个完整的工程化流程。
数据处理阶段:
首先面对给定专业领域的文档,我们需要尽量挑选格式规范、内容专业的文档内容,然后需要对这些文档进行拆分,把长篇复杂的文本切分成一个个小主题的文档片段,然后再梳理这些文档片段之间的关系,必要的时候需要对文档片段进行补充和扩写,也就是所谓的文本增强。紧接着,在整理好了基础文本之后,我们需要对这些问题进行多样化的问题生成,基于同一知识点构造多维度提问,并整理回答内容,需要确保回答准确、自然,并且真正贴合专业语境。
具体来说,数据处理阶段我们需要先谨慎的选择原始文档,推荐优先选取权威性强、专业度高的资料,而不是随意从网络上抓取的零散文章。以医疗场景为例,像临床指南、医学教科书、专业期刊文章往往比零散的问答社区的内容更适合作为数据集的底稿。在数据清洗和切分阶段需要去掉和数据无关的部分,比如文档里的广告语、HTML标签、低质量的对话片段等等。在切分时则要尽量把长篇文档拆解为拥有独立主题的一个个文档片段。比如一份法律文档长达数万字需要按照条款和章节进行切分,之后才能便于我们创建统一主题下的多组问答对。最后是多样化的问题生成,同一知识点可以用不同方式提问,比如"请解释一下某条法律条文"、"如果发生了某个场景应如何使用这条法律","这条条文的限制条件是什么",只有基于同一主题的多样化问答对,才能更好的让模型学到新的知识。

数据验证与优化迭代:
数据集并不是一遍就能定型的。一个高质量的专业微调数据集,一定要经过多轮选代。比如,在实际进行微调前,可以让模型自主进行进行质量评估与筛选,淘汰掉不合格的样本。也可以结合专家意见进行修正,确保领域内的专业性和权威性。然后最好做好数据集的版本管理,一方面能够让每一次修改都能被追溯,另一方面,我们也可以建立微调效果与数据集之间的关系,便于之后持续打磨数据。
二、相关热点问题
2.1 微调往往需要准备多少条数据?
答案: 这个问题没有精准答案,但有一些行业共识。首先,如果只是做轻量级的指令微调,比如让模型掌握某个领域的基本表达风格和知识点,往往只需要几千到几万条高质量样本就能看到明显效果。其次,如果是大规模的通用能力提升,例如提升大模型的逻辑推理、代码编写等能力,数据规模通常需要达到几十万甚至上百万条,才能在 benchmark上拉开差距。此外,数据的质量比数量更重要。一万条经过精心清洗、带有专业审核的数据,往往比十万条混乱、噪声很大的数据更能带来更大的提升。
2.2 工业环境下微调数据集的创建?
答案: 在实际工程中,微调数据集的创建几乎不可能只靠单一方式完成。最常见的做法是模型生成与人工审核结合。先通过大模型生成初稿,快速扩展问答对,再由人工或专家进行校对、筛选与修正。
2.3 强化学习微调应该如何构建数据集?
答案: 强化学习微调的数据集会比较特殊,此时我们不再只需要'标准答案',而是需要准备多个候选答案与对应的打分信号。具体来说,强化学习微调的数据集往往包括同一提示下的多条候选回答,以及由人类或奖励模型给出的偏好排序(比如A比B好,B比C好)。只有这种数据才能驱动模型在训练中学会'更偏向人类偏好的输出,也就是我们常说的偏好对齐。
三、总结
本期分享系统介绍了如何创建大模型微调数据集这一面试热点问题,创建微调数据集是影响微调效果的最关键环节,回答好这一问题非常重要,大家按模板回答一定是加分项!小伙伴们阅读后感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。