一、前言
【理想汽车智驾方案介绍专题 -3】MoE+Sparse Attention 高效结构解析
在前面的 3 篇文章中,笔者已经比较详细地介绍了 V、L、A 模块,本帖介绍 World Model + 强化学习打通自动驾驶闭环仿真链路。
自动驾驶达到人类驾驶水平是远远不够的,这项技术的使命是超越人类的驾驶水平,使得驾驶过程更加安全、可靠、轻松。通常大家认为强化学习是自动驾驶超越人类驾驶水平的核心技术,但是以往的一些尝试都没有取得比较明显的成果。理想认为这里主要有两个限制因素:
- **无法实现车端端到端训练:**传统的车端架构不能实现端到端的可训练,强化学习做一种稀疏的弱监督过程,在当前的架构上无法实现高效无损的信息传递,强化学习的效果的大大降弱;
- **缺乏真实的自动驾驶交互环境:**过去都是基于 3D 的游戏引擎,场景真实性不足,缺少真实的交互自动驾驶交互环境,而且场景建设效率低下且场景建设规模小,模型很容易学偏,发生 hack reward model,模型往往不可用。
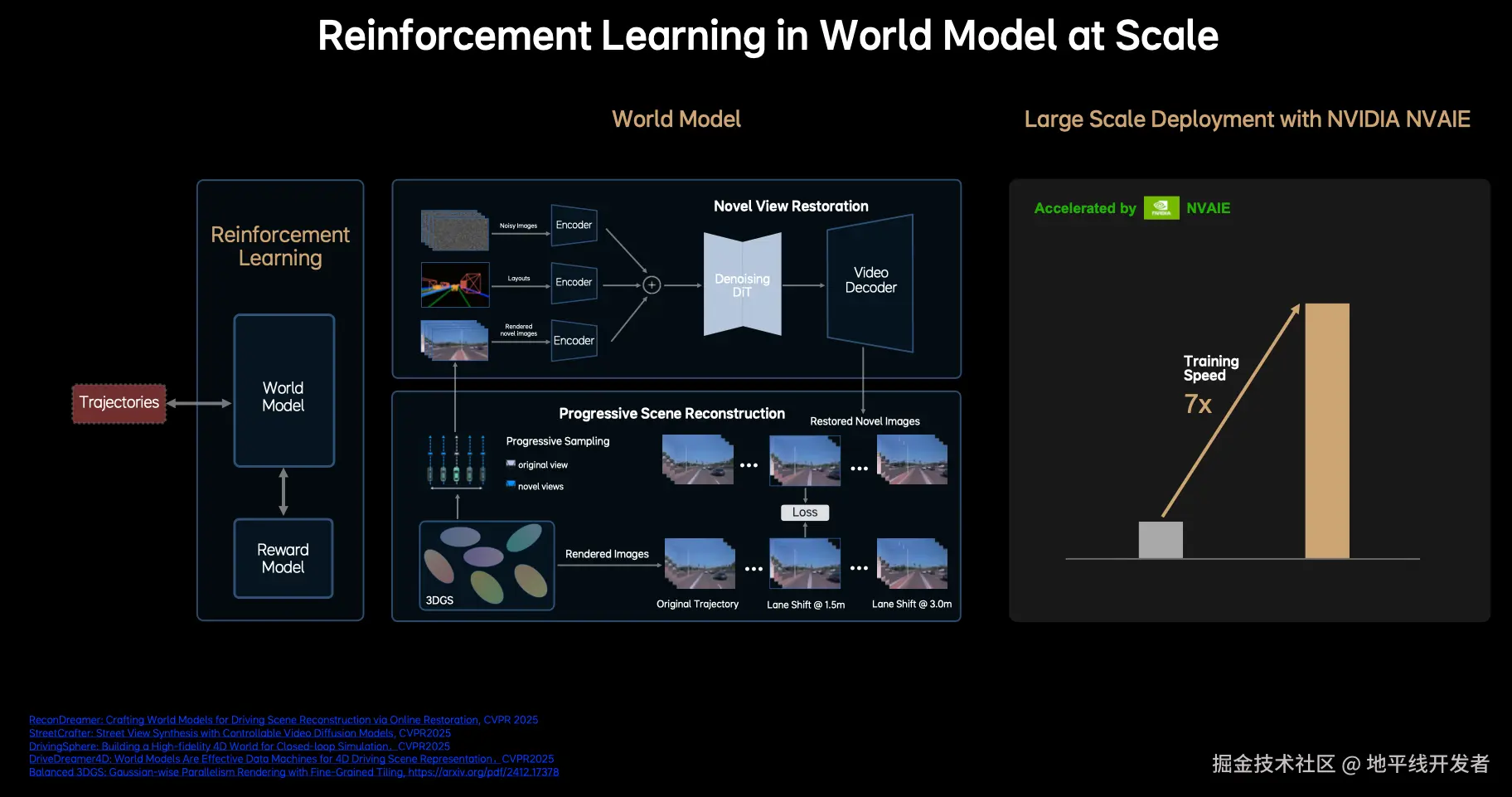
VLA 模型的出现解决了上述第一个限制,第二个限制则依赖于真实、良好的 3D 交互环境数据做 3D 重建和生成。
纯生成模型的具备良好的泛化能力能够生成多变的场景,但也会出现不符合物理世界规律的幻觉,必然不满足自动驾驶场景的严格要求。纯重建模型依赖于真实数据呈现出 3D 场景,在大视角变幻下可能出现空洞和变形,也无法满足自动驾驶场景的需求。
理想的解决方案是:以真实数据的 3D 重建为基础,在不同的视角下添加噪音来训练模型的生成能力,从而恢复模糊的视角,这样的话生成模型就具有了多视角的生成能力。
自动驾驶场景重建和生成结合的相关技术细节可参见理想团队今年 CVPR2025 中的四篇论文:StreetCrafter、DrivingSphere、DriveDreamer4D 与 ReconDreamer,参考文献中贴出了链接。
本帖将以 DrivingSphere 为例来解析这个过程。
二、DrivingSphere
2.1 解决问题
- 开环模拟在动态决策评估方面的问题:目前的开环模拟方式(例如根据公开数据集进行固定路线的路点预测),虽然能生成很逼真的传感器数据,但它没有动态反馈机制,无法评估自动驾驶系统在动态场景下的决策能力。此外,它的数据分布是固定的,数据种类不多,很难检验算法在不同情况下的适应能力。
- 闭环模拟在视觉真实性和传感器兼容性上的问题:传统的闭环模拟方法(例如基于交通流或游戏引擎的方法),虽然支持通过反馈来驱动多个智能体之间的交互,但存在两个主要问题:
- 它无法处理视觉传感器传来的信息,与基于视觉的端到端模型不太适配。
- 它输出的传感器数据与真实世界的情况差异较大,导致训练场景和验证场景存在"差异",难以有效检验算法在输入真实数据时的表现。
2.2 创新点
- 闭环仿真框架与 4D 世界表示
- DrivingSphere 是首个融合了几何先验信息的生成式闭环仿真框架。它构建 4D 世界表示(就是把静态背景和动态对象融合成占用网格),能生成逼真且可控制的驾驶场景。这样就解决了开环仿真没有动态反馈,以及传统闭环仿真视觉效果和真实数据有差距的问题。
- 我们首次将文本提示和 BEV 地图结合起来,用于驱动 3D 占用生成。借助场景扩展机制,我们可以构建城市规模的静态场景,而且这个场景的区域可以无限扩大。
- 多维度仿真能力突破
- 模块化设计与技术整合
2.3 模型结构
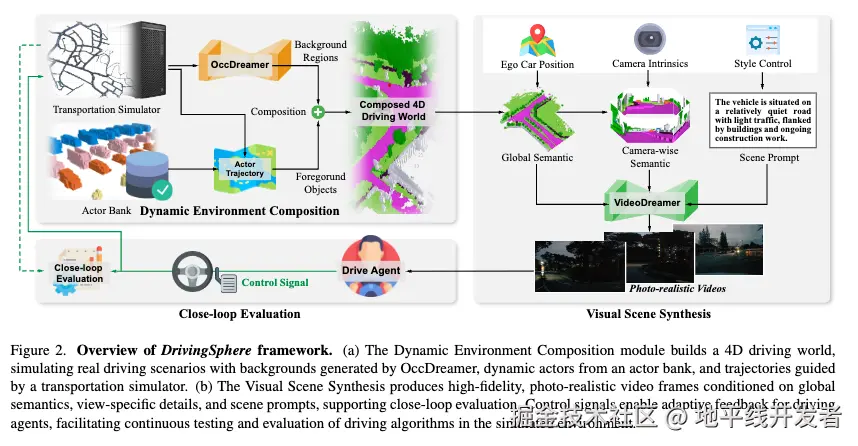
如上图所示,DrivingSphere 由动态环境组成模块(Dynamic Environment Composition)、视觉场景合成模块(Visual Scene Synthesis)和闭环反馈机制(Agent Interplay and Closed-Loop Simulation)组成,下面将逐一对这 3 个模块进行介绍。
2.3.1 动态环境组成模块
该模块构建包含静态背景与动态主体的 4D 驾驶世界,核心技术围绕 OccDreamer 扩散模型与动作动态管理展开。
将 4D 世界表示定义为:
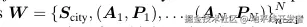
其中 S_ city 为静态背景,An 为动态智能体,Pn 为智能体时空位置序列。
所有元素以占用网格(Occupancy Grid) 形式存储,支持空间布局与动态智能体的统一建模。
OccDreamer 结构如下图所示,基于 BEV 地图与文本提示,生成城市级 3D 静态场景,解决传统方法依赖固定数据集的局限。其技术路径为 3 阶段架构,即:
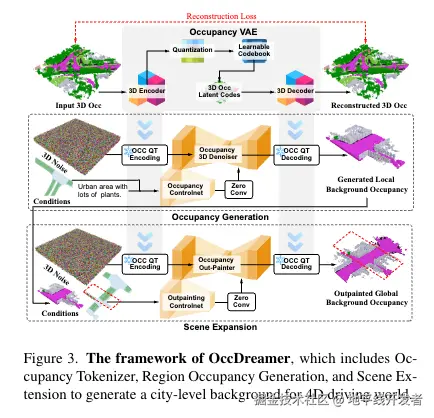
- 占用标记器(Occupancy Tokenizer):使用 VQVAE 将 3D 占用数据映射为潜在特征 \(Z^S\),通过组合损失函数(CE 损失、Lovász 损失)优化重建精度。
- 可控区域生成:结合 CLIP 文本嵌入与 ControlNet 驱动的 BEV 地图编码,通过扩散模型实现文本 - 几何联合控制的区域占用生成。
- 场景扩展机制:利用相邻区域重叠掩码作为条件约束,通过扩散模型迭代扩展场景,确保城市级空间一致性。
2.3.2 视觉场景合成模块
该模块将 4D 占用数据转换为高保真多视图视频,核心在于双路径条件编码与 ID 感知表示。
VideoDreamer 框架
VideoDreamer 的输入数据为 4D 驾驶世界和智能体增强嵌入;输出为多视图、多帧的高保真视频序列,支持自动驾驶系统的感知测试。其结构如下图所示:
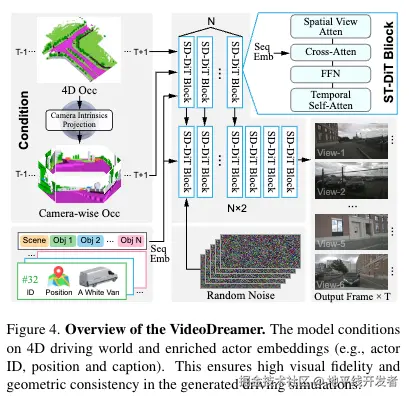
主要由时空扩散 Transformer(ST-DiT)、条件编码机制、噪声处理与视频生成组成,下面进行逐一介绍。
- 时空扩散 Transformer(ST-DiT):
- 作为核心网络架构,包含多个 ST-DiT 模块,每个模块集成:
- 视图感知空间自注意力(VSSA):处理多视图特征的空间一致性,将视图、高度、宽度维度合并为序列,降低跨视图注意力的计算复杂度。
- 时间自注意力:捕捉视频帧间的时间依赖关系,确保动作连续性(如车辆运动轨迹平滑)。
- 交叉注意力:注入场景上下文与智能体身份信息(如\(F_{\text{fuse}}\)),增强生成视频的语义准确性。
- 前馈网络(FFN):特征非线性变换,提升表示能力。
- 作为核心网络架构,包含多个 ST-DiT 模块,每个模块集成:
- 条件编码机制:
- 全局几何特征:通过 4D 占用编码器提取场景的整体空间结构(如道路布局、建筑物位置)。
- 智能体 ID 与位置编码:使用傅里叶编码将智能体的 3D 位置和唯一 ID 转换为特征向量,确保不同帧中同一智能体的外观一致性(如红色车辆在各视角中保持颜色和形状)。
- 文本描述嵌入:通过 T5 模型编码智能体的文本说明(如 "一群行人"),指导语义细节生成。
- 噪声处理与视频生成流程:
-
输入随机噪声,通过扩散模型的去噪过程逐步生成视频帧。
-
自回归生成策略:基于前一帧生成后续帧,确保时间维度的连贯性(如车辆转弯动作的平滑过渡)。
-
2.3.3 闭环反馈机制
闭环反馈机制是 DrivingSphere 实现动态仿真的核心模块,通过自动驾驶代理与模拟环境的双向交互,形成 "代理动作 - 环境响应" 的实时循环,支持算法在真实场景下的验证。其技术核心与创新点为:
- 双向动态反馈
- 代理动作直接影响环境(如自我代理转向导致周边车辆避障),环境变化又反作用于代理感知,模拟真实交通中的交互复杂性。
- 多智能体协同控制
- 通过交通流引擎实现大规模智能体协同(如车流、行人集群),支持复杂场景(如十字路口通行、环岛绕行)的仿真。
- 数据闭环验证
- 支持 "仿真 - 测试 - 优化" 的迭代流程:通过闭环反馈暴露算法缺陷(如紧急制动误触发),指导模型改进。
三、参考文献
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Balanced 3DGS: Gaussian-wise Parallelism Rendering with Fine-Grained Tiling
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation