摘要
在机器人学习领域,Conference on Robot Learning (CoRL) 已经成为全球顶级的学术舞台。每年的大会都会集中展示最前沿的研究成果,也常常预示着未来的发展方向。
近两年,视觉-语言-动作模型(VLA, Vision-Language-Action Models) 在学术界和工业界迅速走红。它们不再只是"看"和"听",而是真正能够将感知和语言理解转化为具体的机器人动作。
与传统的机器人学习方法相比,VLA 模型的最大优势在于通用性与零样本能力:研究者无需为每个任务单独设计策略或收集大量专门数据,机器人就能够通过视觉输入和语言指令直接执行动作。
不过,要让 VLA 真正落地,还面临几大挑战:
● 数据与对齐问题:如何在视觉、语言和动作之间建立稳健映射?
● 泛化与迁移:能否从仿真走向真实,甚至跨场景完成任务?
● 计算与部署:在资源受限的硬件上,是否还能保持高效推理?
带着这些问题,研究者们在 CoRL 提出了不少新的尝试与思路。接下来,我们将从模型架构创新、训练与数据策略、任务应用拓展等多个方面逐一盘点并推荐几篇今年 CoRL 上的代表性 VLA 工作。

π0.5: a Vision-Language-Action Model with Open-World Generalization

图1|π0.5 模型从多种异构数据源中迁移知识,包括其他机器人数据、高层子任务预测、语言指令以及互联网数据,以实现对不同环境和物体的广泛泛化能力。π0.5 能够控制移动操作机器人,在训练数据中未出现的新房间(如厨房和卧室)中执行清洁任务,并完成持续 10 到 15 分钟的复杂多阶段操作行为
推荐理由
这是今年 CoRL 上极具代表性的一篇 VLA 泛化能力突破性工作。
● 创新点:提出了一种协同训练(co-training)框架,将来自不同机器人、语义预测、网络数据和语言指令等多源信息融入训练,实现了跨场景泛化。
● 亮点:π0.5 在全新环境中展现出长时序、多步骤的操作能力,首次证明 VLA 可以在真实家庭场景中完成10-15 分钟的复杂操作序列(如整理房间、清洁厨房),远超以往实验室演示的局限。
● SOTA 价值:在开放世界泛化问题上迈出了关键一步,为 VLA 模型真正走出实验室、服务真实环境提供了里程碑式的验证。
论文内容
π0.5 基于 π0 模型扩展而来,采用了分层结构 + 多源数据协同训练的设计。
● 数据来源:不仅有约 400 小时的移动机器人真实家庭操作数据,还引入了其他类型机器人实验数据、实验室相关任务数据、大规模网络数据(图像-文本)、语义预测任务以及人类监督下的语言指令。值得注意的是,97.6% 的训练数据并非来自移动机器人,而是来自这些异构来源。
● 模型架构:采用两阶段训练:先在多模态任务上进行大规模预训练,再针对移动操作任务微调。推理时,模型先预测高层语义子任务(如"拿起菜板"),再生成对应的低层次动作序列。
● 核心贡献:
○ 证明了通过协同训练和多模态知识迁移,可以显著增强 VLA 的开放世界泛化能力;
○ 展示了一个端到端的学习系统,能在从未见过的家庭中完成长时序、多步骤的操作任务;
○ 系统化分析了不同数据源在泛化中的作用,揭示了多模态知识迁移的重要性。
实验表明,π0.5 不仅能完成诸如挂毛巾、铺床等精细操作,还能执行高达 15 分钟的清洁任务。这让机器人具备了更接近人类的灵活性和泛化能力,为未来的家用与服务机器人打开了新的可能
项目主页: ++A VLA with Open-World Generalization++
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
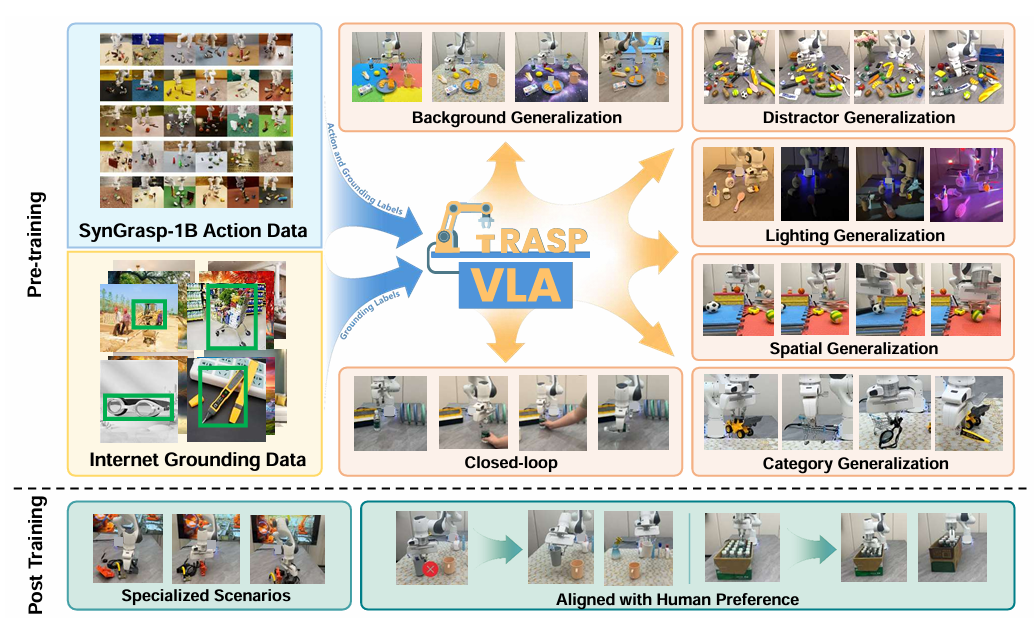
图2|GraspVLA 是一个抓取领域的基础模型,仅在规模达数十亿的合成动作数据上进行预训练,并与互联网语义数据进行联合训练。它具备直接仿真到现实迁移(sim-to-real transfer)的能力,并在多个方面展现出强大的零样本泛化性能,同时还能在少样本场景和适应人类偏好等特定任务中表现出优越的适应性
推荐理由
这篇论文是首个基于十亿规模合成抓取数据预训练的 VLA 基础模型,直接挑战了机器人学习中过度依赖真实数据的问题。
● 创新点:构建了全球首个SynGrasp-1B 数据集(10,000 个物体、240 类别、十亿帧抓取交互),并提出**Progressive Action Generation (PAG)**机制,将感知任务与动作生成统一为"推理链式"流程。
● 亮点:证明了合成数据在 VLA 训练中的巨大潜力,模型不仅能实现sim-to-real 泛化,还能支持open-vocabulary grasping,对透明物体和长尾类别表现尤为突出。
● SOTA 价值:相较于 AnyGrasp 等传统抓取检测算法,GraspVLA 不仅在常见物体上保持性能,还在透明物体、语义丰富的物体类别上显著超越,成为该方向的新一代基准。
论文内容
论文提出GraspVLA,一个完全基于合成数据预训练的抓取 VLA 模型,核心设计如下:
● 数据层面:构建了SynGrasp-1B,利用光线追踪渲染和物理模拟生成,覆盖 10,000+ 物体、240 类别,结合大规模 domain randomization,确保几何与视觉的多样性。
● 模型层面:提出Progressive Action Generation (PAG),将感知(如视觉定位、抓取位姿预测)作为中间步骤,逐步推理动作,形成一个Chain-of-Thought (CoT) 风格的动作生成框架。
● 训练策略:在合成数据上训练完整 CoT 流程,在互联网数据上训练部分感知任务,通过两者结合缓解 sim-to-real gap,并支持对开放类别的语义泛化。
● 实验结果:
○ 在真实场景与 LIBERO 仿真基准上均展现了强大的零样本泛化能力;
○ 在未见过的长尾物体(如充电器、毛巾、泳镜)上依然能够成功抓取;
○ 相比 AnyGrasp,GraspVLA 在透明物体上显著超越,并支持自然语言指令;
○ 展现了few-shot 自适应能力,可根据用户需求调整策略(如保持杯子清洁、不碰杯口内部)。
GraspVLA 首次验证了"仅靠合成数据,也能训练出强大 VLA 抓取模型",并通过 PAG 机制实现了语义与动作的统一推理。这一成果极大降低了真实数据采集的成本,为未来基于 VLA 的机器人操作研究打开了新方向
项目主页:GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
ControlVLA: Few-shot Object-centric Adaptation for Pre-trainedVision-Language-Action Models
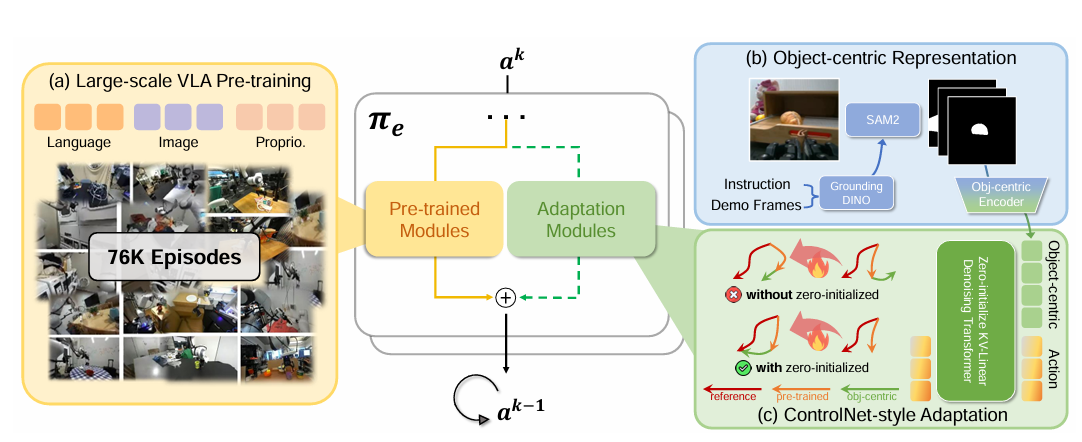
图3|ControlVLA 采用类似 ControlNet 的微调策略,将以物体为中心的表示(object-centric representations)与预训练的 VLA 模型进行融合。通过零初始化的权重和偏置,模型能够在保留预训练模型丰富先验知识的同时,实现对控制信息的有效整合
推荐理由
这篇论文聚焦于如何让 VLA 模型在少量演示下快速适应新任务,解决了现实场景中"数据稀缺"的痛点。
● 创新点:引入ControlNet 风格的架构,在预训练 VLA 模型中嵌入零初始化的投影层,将物体中心(object-centric)****表示融合进来,实现高效的任务特定微调。
● 亮点:仅需10--20 个演示,在 6 个多样化任务(如倒方块、叠衣服)中达到了 76.7% 成功率,而传统方法需要上百个演示才能达到类似水平。
● SOTA 价值:证明了 VLA 模型可通过少量额外数据完成下游任务适配,大幅提升机器人部署的实用性。
论文内容
ControlVLA 旨在将预训练的 VLA 模型与物体中心表示有机结合,提升少样本条件下的学习效率:
● 方法设计:在 VLA 模型的基础上,引入额外的交叉注意力层(cross-attention layers),并采用零初始化的 key-value 投影权重,确保模型在保留原有技能先验的同时,逐渐吸收任务相关的物体表示,避免过拟合或性能退化。
● 优势:
○ 技能先验:利用大规模 VLA 预训练带来的通用策略;
○ 任务高效性:物体中心表示降低输入空间复杂度,使策略在物体位姿或外观变化下更稳健;
○ 适配稳定性:ControlNet 风格条件化设计,避免微调过程引入噪声。
● 实验结果:
○ 在 8 个真实世界任务中,仅用 10--20 次演示就达到 76.7% 成功率,远超基线(20.8%);
○ 覆盖多种任务:刚性物体、软体物体、精细操作、可变形体(布料折叠)、以及长时序操作;
○ 展现了对未见过的物体和背景的鲁棒性。
ControlVLA 提供了一条极具实用价值的路径:让通用 VLA 模型通过少量演示快速专精,有效解决机器人在真实环境中面临的数据匮乏问题。这让机器人具备了"即学即用"的潜力,向真正的广泛部署迈出关键一步
项目主页:ControlVLA
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control

图4|在多样任务与场景中的灵巧操作能力。DexVLA 方法能够在多种机器人形态和不同场景下实现通用化的灵巧操作
推荐理由
这篇论文直击 VLA 模型在动作表征与训练效率上的瓶颈。
● 创新点:提出了扩展至十亿参数规模的扩散式动作专家(Diffusion Expert),并结合跨具身课程学习(Embodied Curriculum Learning),解决 VLA 仅扩展视觉-语言部分而忽视动作层的架构失衡问题。
● 亮点:只用100 小时示范数据,DexVLA 就能在多个机器人平台上学会复杂技能(如双臂折衣服、精细倒饮料),并且在**长时序任务(laundry folding)**上大幅超越 π0。
● SOTA 价值:在保证高效训练(单卡 A6000、60Hz 推理)的同时,展现了跨具身、跨任务的泛化能力,是目前最有潜力的 VLA 动作建模方向之一。
论文内容
DexVLA 针对 VLA 中"视觉-语言部分大规模扩展,但动作层薄弱"的问题,提出了Plug-in Diffusion Expert+Embodied Curriculum Learning 双创新:
● 动作专家(Diffusion Expert):
○ 使用十亿参数的扩散模型,具备多头架构,每个头对应不同机器人形态;
○ 大幅提升了复杂运动技能的学习能力,突破以往百万级参数动作模块的限制。
● 具身课程学习:分三阶段训练:
○ 跨具身预训练:在多机器人数据上训练扩散动作专家,学习具身无关的低层运动技能;
○ 具身对齐:将 VLA 高层语义与具体机器人体态匹配,实现任务可迁移;
○ 任务适配:通过子步骤推理(如折衣服分为"抚平皱褶-对齐袖子-固定折叠"),学习长时序复杂任务。
● 实验结果:
○ 在单臂、双臂、灵巧手等多种机器人上,表现出高度适应性;
○ 在衣物折叠、箱子抓取、饮料倒取等任务中,无需额外微调即可获得高成功率;
○ 与 π0、OpenVLA 相比,DexVLA 在长时序和复杂 dexterous 任务上显著领先。
DexVLA 强调 动作表征的扩展与课程化训练,不仅突破了现有 VLA 在动作层的短板,还展示了在低数据成本下完成跨具身、跨任务学习的可能性。它让机器人能够在更复杂、更长时序的任务中展现出真正的泛化智能,成为 CoRL 上最具代表性的"动作范式升级"工作。
项目主页:DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
TrackVLA: Embodied Visual Tracking in the Wild
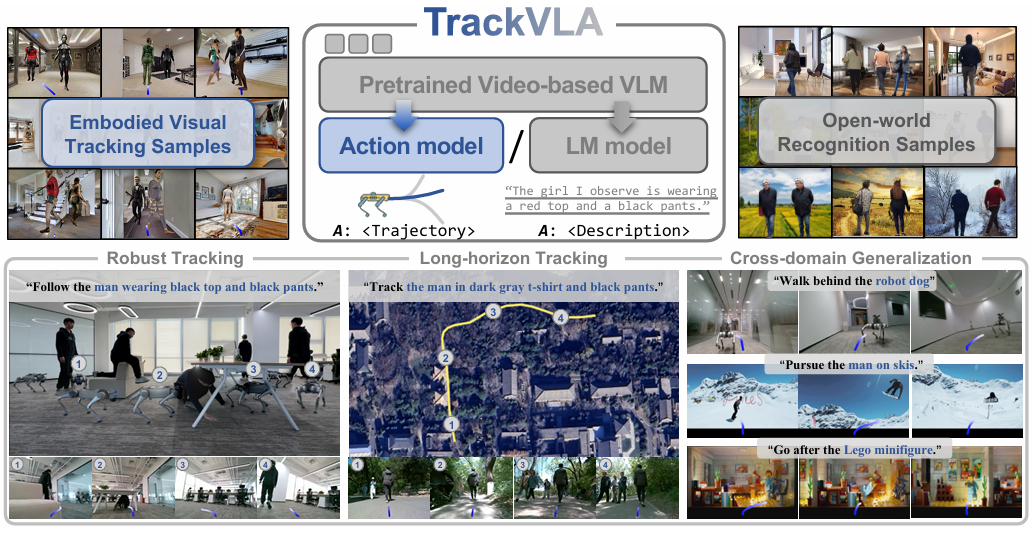
图5|TrackVLA 是一种视觉-语言-动作(VLA)模型,能够同时实现物体识别与视觉跟踪,并在 170 万样本的数据集上进行了训练。该模型展现出鲁棒的跟踪能力、长时序跟踪能力,以及在多种复杂环境中的跨域泛化能力
推荐理由
这篇论文把目标识别与轨迹规划统一到一个 VLA 框架中,解决了以往方法模块化解耦导致误差累积的问题。
● 创新点:提出了一个共享 LLM 骨干的统一模型,分别通过语言建模头处理识别任务、通过扩散式 anchor head生成轨迹,实现识别与规划的紧耦合。
● 亮点:建立了EVT-Bench(Embodied Visual Tracking Benchmark),规模达到 170 万样本,覆盖不同难度和场景。
● SOTA 价值:在 Gym-UnrealCV 基准上实现零样本 SOTA,并在自建 EVT-Bench 上显著超越基线,尤其在高动态、强遮挡的场景中依然稳健运行(10 FPS 实时速度)。
论文内容
TrackVLA 针对 embodied visual tracking(EVT)的核心挑战:目标识别与轨迹规划的耦合。
● 现有问题:传统方法将两者分开,易产生误差累积(识别错误 → 规划失败)。
● 方法设计:
○ 统一框架:识别与轨迹生成共享 token 编码与 LLM 转发机制;
○ 双任务解码:识别用语言建模头解码,规划用 anchor-based diffusion 生成轨迹;
○ 联合训练:同时优化识别与轨迹规划任务,形成紧耦合策略。
● 数据构建:
○ 识别样本:85.5 万条,来源于 ReID 数据集 + 开放域 VQA 数据;
○ 跟踪样本:85.5 万条,来自自建 EVT-Bench,涵盖 100+ 高保真虚拟人类、动态场景、多难度等级。
● 实验结果:
○ 在 Gym-UnrealCV 基准上零样本 SOTA;
○ 在 EVT-Bench 上显著优于基线,尤其在拥挤环境和复杂语言指令下表现突出;
○ 出色的sim-to-real 泛化:在现实环境中对未见目标依旧保持鲁棒跟踪;
○ 运行效率达 10 FPS,可支持实时机器人部署。
TrackVLA 展示了VLA 模型在目标跟踪任务上的潜力,通过统一识别与轨迹生成,突破了传统模块化方法的限制。在复杂、高动态的场景中,它不仅表现出强大的泛化能力,还能实时运行,是 CoRL 上将 VLA 推向具身跟踪应用的重要一步。
项目主页:TrackVLA: Embodied Visual Tracking in the Wild
Long-VLA: Unleashing Long-Horizon Capability of Vision-Language-Action Model for Robot Manipulation
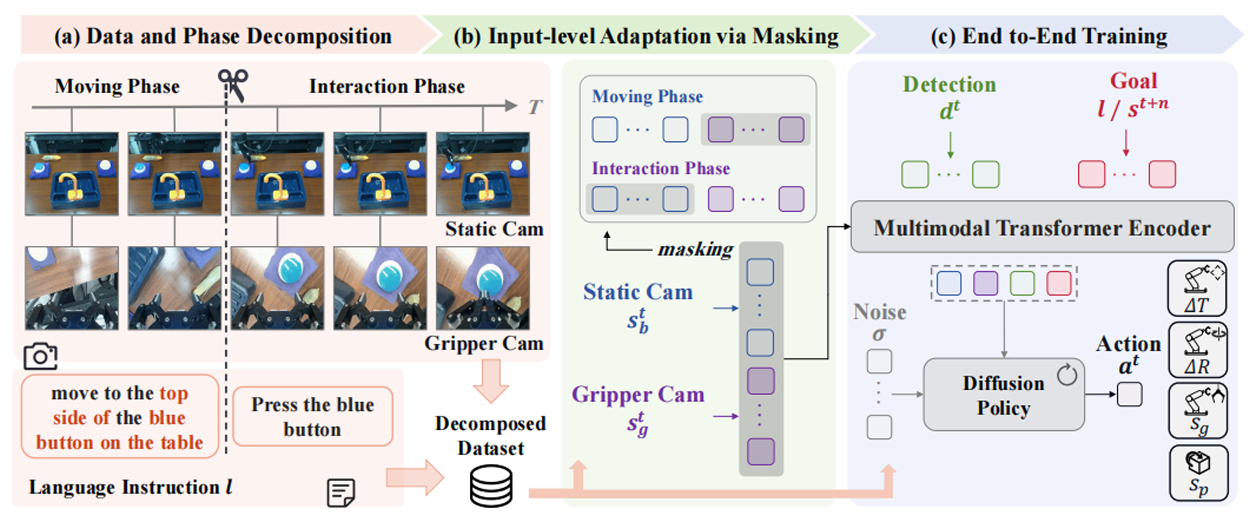
图6|Long-VLA 概览。(a) 任务分解:结合视觉观测与语言标注进行任务拆解;(b) 相位感知掩码(phase-aware masking):在不改变输入结构的情况下,使模型在注意力计算时有选择性地关注相关 token;(c) 端到端训练:基于带有相位感知掩码的分解数据进行端到端训练
推荐理由
这篇论文首次提出专门面向 长时序、多步骤机器人操作 的端到端 VLA 模型。
● 创新点:提出phase-aware input masking,将子任务分解为移动阶段与交互阶段,让模型在不同阶段关注对应的感知信息,从而提升任务衔接能力。
● 亮点:方法兼具可扩展性与架构无关性,无需改变 VLA 主干结构即可集成,保持大规模数据驱动的高效训练范式。
● SOTA 价值:在新提出的L-CALVIN 长时序操作基准以及真实机器人实验中均显著优于现有方法,建立了长时序 VLA 的新基线。
论文内容
Long-VLA 针对当前 VLA 在长时序任务中的主要瓶颈------技能衔接(skill chaining)问题:
● 现有不足:
○ 主流做法是将任务拆解为多个子策略,但缺乏对任务间依赖的建模,导致误差在子任务边界累积;
○ 在线优化与模块化架构方法虽然一定程度缓解了问题,但与 VLA 的端到端、大规模训练理念不兼容。
● 方法设计:
○ Phase-aware input masking:
■ 在移动阶段使用第三人称视角,专注于导航和场景理解;
■ 在交互阶段使用自我中心(egocentric)视角,提升精细操作精度;
■ 减少表示切换带来的不稳定性,从输入层面改善技能衔接。
○ 模块化与兼容性:该方法作为一个架构无关的输入适配模块,可直接嵌入现有 VLA 模型,不改变整体结构。
● 实验结果:
○ 提出了新的长时序评测基准 L-CALVIN;
○ 在仿真与真实环境的多任务测试中,Long-VLA 一致超过现有最优方法;
○ 展现出跨任务、跨环境的强泛化能力,尤其在需要复杂技能链路的任务(如物体搬运+操作组合)中优势明显。
Long-VLA 开启了长时序 VLA 学习的新方向,通过轻量但高效的phase-aware masking机制,有效解决了技能链衔接问题,同时保持端到端和可扩展性。这一成果为机器人在真实环境中执行复杂、多步骤任务提供了新的范式,是 CoRL 上长时序任务方向的里程碑式工作。
项目主页:Long-VLA

从今年 CoRL 的多篇工作可以看出,VLA 的研究正呈现出几个鲜明趋势:
第一,泛化能力走向开放世界。 从 π0.5 到 GraspVLA,研究者们在积极探索如何让机器人走出实验室,真正适应陌生环境与长尾物体。无论是引入异构多源数据,还是借助大规模合成数据集,目标都是让 VLA 模型具备更强的跨场景迁移能力。
第二,适配效率成为核心议题。 ControlVLA 展现了仅需十几次演示就能让机器人掌握新任务的可能性,说明未来 VLA 的落地应用,不能只依赖庞大的预训练,还必须在数据有限的真实环境中"即学即用"。
第三,动作层面的表征被重新重视。 DexVLA 的扩散式动作专家、TrackVLA 的统一识别与规划,都是在补齐 VLA 框架中过去偏重"视觉+语言"而忽视"动作建模"的短板。研究正在从感知-语言的耦合,扩展到感知-语言-动作的真正一体化。
第四,长时序复杂任务逐渐成为新前沿。 Long-VLA 通过输入掩码机制来解决技能衔接问题,标志着 VLA 模型正从"短平快"的操作,走向可以完成需要多步骤推理和持久执行的真实任务。
整体来看,这些趋势共同指向了一个方向:未来的 VLA,不仅要能看懂、听懂,更要能在开放环境下长期、稳健地行动。

今年的 CoRL 上,VLA 相关研究可以说是全面开花。从泛化到少样本适配,从合成数据到长时序任务,研究者们不断在突破 VLA 的边界。可以看到,VLA 不再只是"能听懂指令、能做简单动作"的实验室玩具,而是逐渐具备了跨****环境迁移、快速适配、复杂技能链路和长期执行的能力。
这些进展意味着,未来的机器人或许不需要为每个新任务都从头训练,而是能够像人一样,凭借积累的经验和灵活的适应能力,去应对真实世界的多样挑战。CoRL 展示出的这些探索,正在为"通用型机器人智能"的实现一步步铺路。
附CORL paper list链接:https://www.corl.org/program