论文地址:https://ieeexplore.ieee.org/document/10906597
代码地址:https://github.com/jarch-ma/AFANet
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
本研究旨在通过利用从少量样本 中学习的先验知识来识别新概念。然而,对于视觉密集型任务 (如少样本语义分割 ),像素级标注既耗时又昂贵。因此,在本文中,本研究利用更具挑战性的图像级标注 ,并提出了一种用于弱监督少样本语义分割 (WFSS) 的自适应频率感知网络 (AFANet) 。具体来说,本研究首先提出了一个跨粒度频率感知模块 (CFM) ,它将 RGB 图像解耦为高频和低频分布 ,并通过重新对齐它们来进一步优化语义结构信息。与大多数现有的 WFSS 方法以离线学习 的方式使用来自多模态语言视觉模型(例如 CLIP)的文本信息不同,本研究进一步提出了一个 CLIP 引导的空间适配器模块 (CSM),它通过在线学习 对文本信息执行空间域自适应转换 ,从而为 CFM 提供丰富的跨模态语义信息 。在 Pascal-5i 和 COCO-20i 数据集 上的大量实验表明,AFANet 实现了最先进的性能 。
引言
**深度学习方法在图像分割任务中取得了显著的成果,但这些方法通常需要大量的训练数据,而数据收集和手动标注过程耗时且昂贵。**对于像小样本语义分割这样视觉密集型任务,像素级标注的成本尤为突出。为了应对这些挑战,弱监督语义分割(WSSS)和小样本语义分割(FSS)被提出,并在医学图像分析、自动驾驶和军事目标识别等领域发挥着重要作用。WSSS致力于为图像提供像素级预测,可以被视为一项视觉密集型任务。目前常用的弱监督标注方法包括图像级标签、边界框标签、涂鸦标签和点标签。其中,**图像级标签虽然不提供目标位置信息,但其获取最便捷、标注成本最低,因此成为弱监督语义分割任务中最普遍的标准设置。而 FSS的目标是使用少量样本预测各种目标,这更符合现实开放场景中难以获取且长尾分布数据的特点。**FSS通常包括两个阶段:元训练阶段,在该阶段模型在与测试阶段类别不相交的基础数据集上进行训练;元测试阶段,在该阶段模型可以快速适应并泛化到未见类别的少样本任务,从而分割新类别中的新目标。然而,FSS设置下基础数据集的标注仍然费力且昂贵。
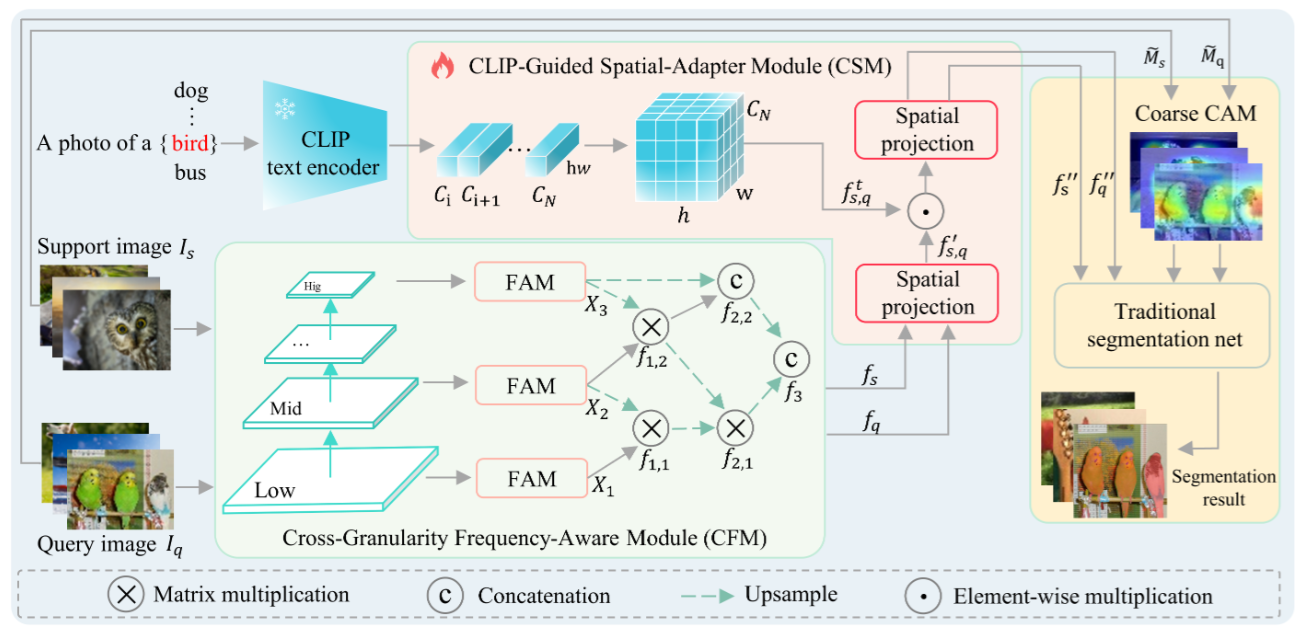
**本研究将FSS任务中传统的像素级标签替换为更具挑战性的图像级标签,即弱监督小样本语义分割(WFSS)。**与大多数现有的WSSS或FSS网络模型类似,目前WFSS的研究主要集中在获得更精确的种子类别激活图(CAM)(也称为伪掩码)或细化目标边界以获得更清晰的轮廓。**然而,WFSS任务的内在性质表明,基类数据只能为网络提供有限的(少样本)和微薄的(图像级标签)语义信息。因此,解决WFSS任务的关键在于如何在上述有限的约束条件下获得更多的支持信息。**最近的研究表明,网络中的特征可以进一步解耦频域分布信息。受此启发,本研究在元训练期间借助频域来寻求理想的语义转换,并提出了一种用于WFSS的自适应频率感知网络(AFANet)。
目前的网络模型通常依靠图像的RGB颜色域来定位和预测目标,通过提供颜色、纹理和表面特征等信息。然而,这种表示方法仍然无法满足WFSS任务的要求。自然图像可以进一步分解为空间频率成分。低频分布信息表示图像中缓慢或平滑的变化,高频分布信息表示图像中快速的变化或图像细节。前者可以提供图像的全局特征和整体结构信息,而后者可以提供局部细节和次要特征信息。进一步的研究表明,卷积层的输出特征图也可以被视为不同频率信息的混合,并且这些混合特征图可以通过倍频程卷积进行解耦。因此,本研究提出了一个跨粒度频率感知模块(CFM)来解耦金字塔网络中的跨粒度信息特征,并通过重新对齐进一步优化语义空间结构信息。通过CFM重新对齐和优化语义空间结构信息,AFANet有效地解决了当前网络模型在WFSS任务中的局限性,在目标预测和定位方面提供了前所未有的细节和准确性。
此外,**认识到当前网络模型在满足WFSS任务需求方面的局限性,研究人员探索了替代方法。一种有前途的选择是利用跨模态模型,例如CLIP(对比语言-图像预训练)。**与依赖RGB颜色域信息的传统模型不同,CLIP通过联合学习从网络上大量的图像-文本对中学习。该模型不仅捕获复杂的视觉细节,还能理解文本上下文,使其特别擅长理解和解释复杂的视觉场景。然而,目前对CLIP的研究主要集中在以离线学习的方式优化提示或生成种子CAM。尽管CLIP通过大量实验证明了其在识别未见类别方面的强大零样本能力,但仅依赖于先验知识的粗略离线学习利用仍然与下游任务的数据分布存在显著差异。
受此启发,本研究进一步提出了一个CLIP引导的空间适配器模块(CSM)。CSM可以根据下游任务的语义分布特征对CLIP的跨模态文本信息进行空间域自适应转换。通过这种微调和适应,CSM可以有效地解决先验知识与下游任务数据分布之间的差异。据我们所知,这是CLIP首次以在线学习的方式与下游任务网络模型进行协同更新。这种学习方法显著增强了模型对新任务的适应性,实现了模型与任务之间的紧密结合,从而在实际应用中取得了优异的性能。
论文创新点
✨ 本研究提出了一个名为AFANet的弱监督小样本语义分割模型,其创新点主要体现在以下几个方面: ✨
-
🎶 跨粒度频率感知模块(CFM): 🎶
- 本研究首次将图像的频率域信息引入到弱监督小样本语义分割任务中。
- CFM模块利用八度卷积将不同网络层级(低、中、高)提取的RGB图像特征分解为高频和低频分布,并通过重新对齐操作优化频率域的空间结构信息,从而提供比传统RGB特征更全面的语义信息。
- 不同粒度的特征融合能够更全面地表示图像的局部细节和全局信息,而频率域的重新对齐则优化了空间结构信息,有效避免了信息冗余或误导。
-
🚀 CLIP引导的空间适配器模块(CSM): 🚀
- 本研究提出了CSM模块,该模块利用在线学习的方式,使CLIP的跨模态文本信息能够自适应地与下游任务进行协同更新。
- CSM模块首先将CLIP文本信息的空间维度调整为与频率域信息一致,然后在频率域信息的引导下,通过空间域的自适应变换来减少先验知识与网络模型之间的分布差异。
- 这种在线学习的方法显著增强了模型对新任务的适应性,实现了模型与任务的紧密结合。
-
💡 频率域信息指导CLIP在线学习: 💡
- 本研究创新性地使用频率域信息指导CLIP的在线学习过程。
- 通过将图像的频率域信息与CLIP的文本信息进行融合,CSM模块能够更好地捕捉图像的语义信息,并将其与CLIP的先验知识进行有效结合,从而提高分割精度。
-
🌐 跨层级特征融合: 🌐
- 本研究采用金字塔网络结构,提取了不同层级的特征信息,并将这些特征在频率域进行分解和重组,最后通过邻域连接解码器(NCD)建立跨层级频率域特征之间的上下文关联,从而实现更精确的语义分割。
-
🔄 引入在线学习机制: 🔄
- 与以往基于CLIP的弱监督小样本语义分割方法不同,本研究采用在线学习的方式对CLIP进行微调,使其能够更好地适应下游任务的数据分布,从而提高模型的泛化能力和鲁棒性。
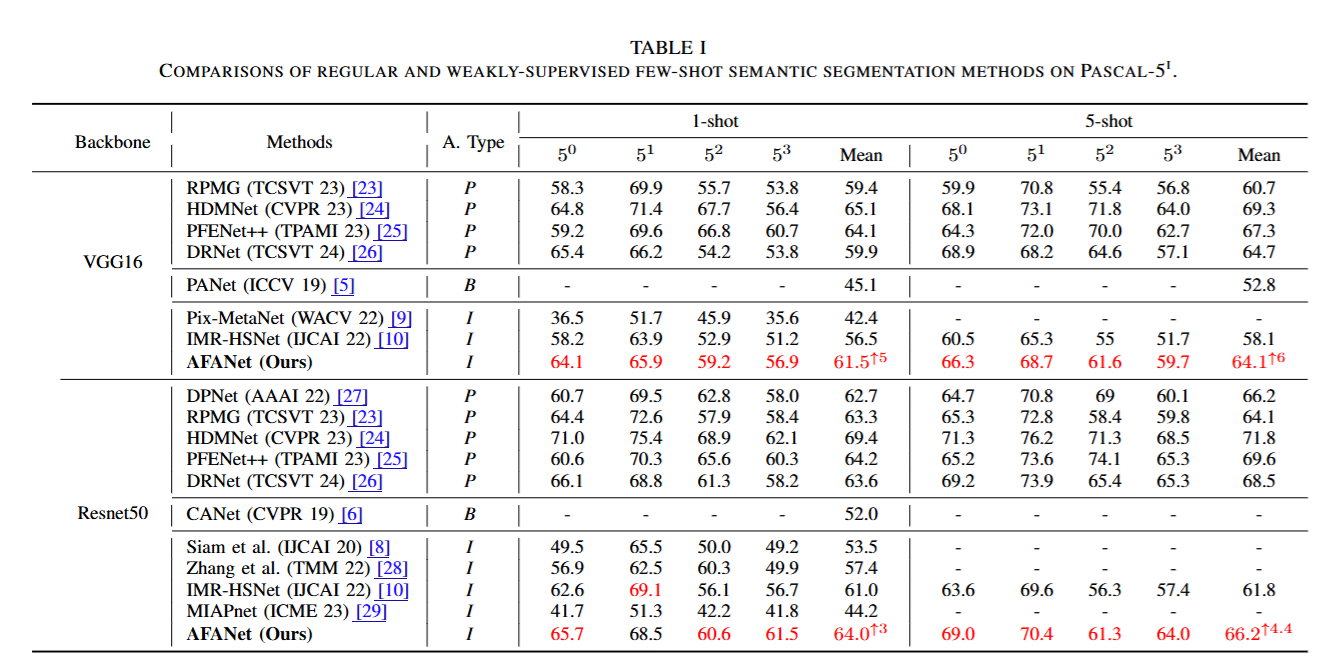
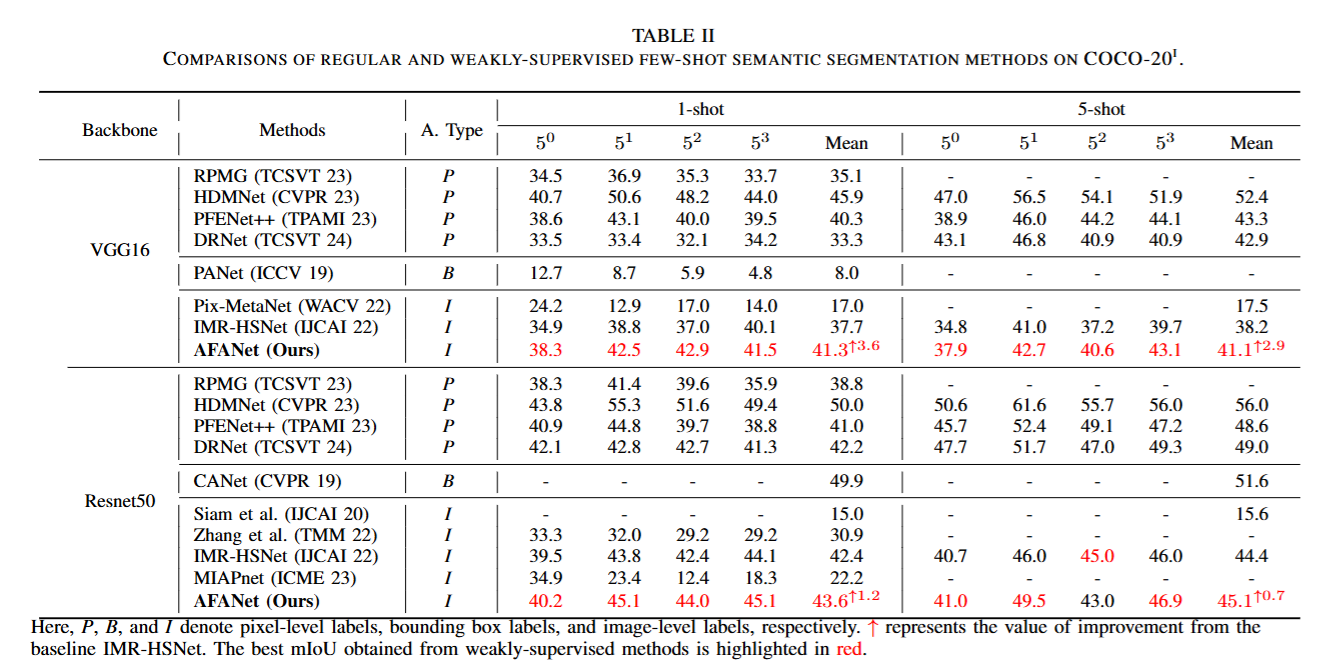
论文实验