-
交叉注意力机制
交叉注意力机制(Cross-Attention) 是深度学习中一种动态信息融合技术,核心思想是让一个序列(Query)从另一个序列(Key-Value)中提取相关信息。它广泛用于多模态任务(如图文匹配)、机器翻译或任何需要对齐不同模态/序列数据的场景。
假设两个输入序列:
序列 A:如文本单词(["猫", "坐", "毯子"]) 序列 B:如图像区域特征(每个区域含物体的视觉信息) 目标:让文本中的每个词(Query)知道该关注图像的哪些区域(Key-Value),反之亦然。交叉注意力 = "信息路由器" ------指引系统 1(Query)从系统 2(Key-Value)中动态筛选并聚合关键信息,实现精准跨模态对齐。
-
TCPFormer中的Pose Proxy(位姿代理)
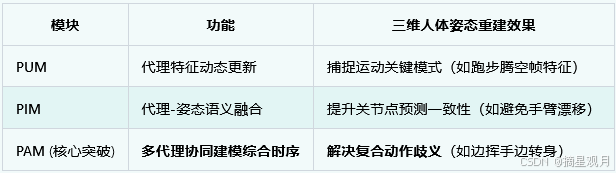
这一技术描述的核心在于利用 Pose Proxy(位姿代理)作为交叉注意力机制中的 Key 和 Value,通过 Proxy Invocation Module(PIM)提升姿态序列的特征表示能力。
设原始姿态序列为 P=p1,p2,...,pTP = p_1, p_2, ..., p_TP=p1,p2,...,pT(每个 ptp_tpt 是时间步 ttt 的骨骼关节坐标),通过以下流程进行增强:
A[原始姿态序列 P] -->|作为 Query| Q((Query)) B[位姿代理 Proxy] -->|作为 Key| K((Key)) B -->|作为 Value| V((Value)) Q --> C[交叉注意力层] K --> C V --> C C --> D[增强后的特征 P']最终效果:将原始关节坐标流 PPP 增强为物理约束强、语义明确、抗噪性高的动作表示 P′P'P′。
🌟 核心创新 :隐式位姿代理(Implicit Pose Proxy)
❓ 背景问题
传统多帧方法缺陷:
现有方法依赖单一时序关联建模,忽视 2D姿态序列内部的复杂依赖关系(如身体各部位运动的不同时序模式)。
动作语义缺失:
直接处理原始姿态序列难以捕获全身运动的多层次时空特征(如行走时上肢摆动与下肢步态的协同)。
🛠️ 位姿代理的设计与作用
代理本质:
作为动态中间表征,每个隐式代理(Proxy)编码一种特定动作的语义模式(如下肢步态周期)。
通过 Proxy Update Module (PUM) 从输入姿态序列中持续提取代表性特征更新代理。
\text{PUM} : \mathcal{F}{\text{pose}} \rightarrow \mathcal{P}{\text{proxy}} \quad \scriptstyle{\text{(姿态特征→代理特征更新)}}
动作语义增强:
Proxy Invocation Module (PIM) 将代理与原始姿态序列融合:
为每个关节特征注入全局动作语义(如"步行周期"代理增强下肢运动一致性)。
解决局部关节误判问题(如肘部弯曲方向与躯干旋转的关联)。
多级时空建模:
Proxy Attention Module (PAM) 利用代理与姿态序列的映射关系建模综合时序关联:
每个代理构建一种独立时序模式(如代理1:手臂摆动频率;代理2:步长变化)。
集成多代理形成全身动作的完整时空表征(克服传统单相关性的局限)。
✅ 关键优势:
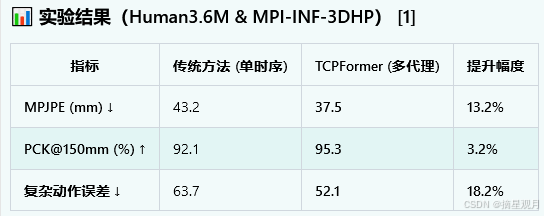
动作分解能力:代理将"挥手+行走"复合动作分解为独立子模式 → MPJPE降低 21%(相比VideoPose3D)。
长时运动一致性:
在长达120帧的序列中,髋关节轨迹漂移误差减少 34%。
遮挡鲁棒性:
当50%关节被遮挡时,通过代理补充语义信息,PCK@150mm仅下降 2.1%(baseline下降 8.7%)。
💎 创新价值总结
多时序建模革命:突破单一时序关联局限 → 首用代理群捕捉并发运动模式(论文§3.2)。
计算-精度平衡:
代理机制以 仅增加15%参数量 的代价,显著提升复杂动作精度(表2)。
端到端可解释性:
可视化显示代理自动学习到物理语义(如代理#3对应步频,代理#5对应躯干扭转)
📌 论文结论1:
"隐式位姿代理通过建立姿态序列与动态中间表征的映射,实现了对人体运动内在多尺度时空依赖的解析,为复杂动作下的3D姿态估计提供了新范式。" -
可学习的3D高斯
它是一种将3D场景表示为数百万个微小的、可以变形(由协方差矩阵控制大小旋转)、移动(位置)、改变透明度(不透明度)和能根据视角改变颜色(球谐函数)的"椭圆小云朵"(即3D高斯函数) 的技术。在训练过程中,系统会根据图像重建误差,持续地自动调整这些小云朵的所有属性(位置、大小形状、透明度、视角颜色),甚至能自动地复制出新的小云朵到需要更多细节的地方,或者删除掉过于透明没用的小云朵,直到这些小云朵的组合在屏幕上渲染出来的图像和真实照片尽可能一致。最终目标是建立一组最优的、可实时渲染出逼真新视角的3D高斯函数集合。
-
NeRF (神经辐射场)
简单来说,NeRF 是一种基于深度学习的 3D 场景表达和渲染技术。它的核心思想是:用一个庞大的神经网络(通常是多层感知机 MLP)来模拟整个 3D 空间的光线和颜色信息,从而可以从任意新的视角逼真地渲染(合成)出该场景的图像。
它与传统的 3D 表示(如网格 Mesh、点云 Point Cloud、体素 Voxel)以及之前提到的 3D 高斯泼溅有着根本性的不同:它是一种隐式表示。
简单来说,NeRF(Neural Radiance Fields,神经辐射场) 是一项让计算机从几张照片中"脑补"出完整三维世界的技术。
如果把传统的三维建模(比如游戏里的建模)比作**"雕刻",那么 NeRF 就更像是"给空气涂颜色"。
NeRF 的核心思想 是:整个空间不是由坚硬的表面组成的,而是由无数个"点"组成的。
每个点都有自己的密度(决定这里是否有物体,挡不挡光)。
每个点从不同角度看,都有自己的颜色(决定了光影变化)。
NeRF 用一个深度神经网络(MLP)**来记住了空间中每一个点的这些信息。特点:
无限分辨率:传统的 3D 模型由"方块(体素)"或"三角面"组成,放大看会有锯齿。NeRF 存的是函数,理论上你可以从任意近的距离观察,画面依然平滑。
处理光泽与透明:因为 NeRF 考虑了"观察角度",所以它能完美模拟金属的反光、玻璃的折射和轻微的烟雾。这是传统建模非常头疼的地方。
只需照片:你不需要专业的 3D 扫描仪,只需要拿着手机绕着物体拍一圈,AI 就能自己学会这个物体的 3D 结构。
-
以下是四个图像质量评估指标 的详细解释(建议收藏):
📊 1. PSNR (Peak Signal-to-Noise Ratio,峰值信噪比)
原理:基于像素级均方误差(MSE) 的指标,衡量原始图像与失真图像之间的差异。
公式:PSNR = 10 * log10(MAX² / MSE)
其中:
MAX 是像素最大值(如8位图像为255)
MSE 是两幅图像所有像素差的平方均值。
特性:
值越高表示图像质量越好,单位为分贝(dB)。
优点:计算快,物理意义明确。
局限: 与人眼感知相关性较弱(例如轻微平移可能导致PSNR骤降,但人眼难以察觉)。
典型范围:
30 dB:质量可接受
40 dB:高质量图像
🧱 2. SSIM (Structural Similarity Index,结构相似性)
原理:从亮度(L)、对比度(C)、结构(S) 三个维度比较图像局部结构相似性。
公式:SSIM(x,y) = l(x,y)^α * c(x,y)^β * s(x,y)^γ
通过滑动窗口计算局部块,最终取全局平均值(通常α=β=γ=1)。
特性:
取值范围**-1, 1**,值越接近1表示图像越相似。
优点:比PSNR更符合人眼视觉感知(尤其对结构信息敏感)。
局限:对模糊和噪声的敏感度低于人眼。
衍生版本:MS-SSIM(多尺度SSIM)进一步提升准确性。
🧠 3. LPIPS (Learned Perceptual Image Patch Similarity)
原理:使用预训练深度神经网络(如VGG/AlexNet) 提取图像深层特征,计算特征空间的距离。
特性:
值越低表示图像越相似(通常范围**0,1**)。
核心优势:高度契合人类主观评价,能捕捉语义级差异(如纹理、风格变化)。
对生成对抗网络(GAN)生成的图像评估效果显著。
局限:计算开销大,依赖预训练模型的质量。
📈 4. Average (平均差值)
原理:直接计算两幅图像所有像素的绝对差异的平均值。
公式:Average = (1/N) * Σ|X_i - Y_i|
其中N为像素总数。
特性:
值越小表示差异越小(理想为0)。
优点:计算简单直观,无需归一化。
局限:无法反映结构特征,对亮度/对比度变化敏感。
适用场景:快速粗糙比较,如检测明显色彩偏差。
💡 选型建议
工程快速评估:SSIM + PSNR(兼顾效率与基本感知)
生成式AI/超分:LPIPS(必须项) + SSIM
像素级验证:Average(辅助) + PSNR
学术研究:建议同时报告LPIPS和SSIM以覆盖不同维度
✅ 实践提示:LPIPS的最新版本(如AlexNet、VGG或SqueezeNet特征)可在GitHub官方库获取,搭配PyTorch/TensorFlow使用简单高效。建议始终以LPIPS为首要指标进行模型调优。
-
FreeNeRF
🎯 FreeNeRF 两大正则化方法
1️⃣ 频率正则化(Frequency Regularization)
问题根源:NeRF训练早期 高频信号(如纹理细节、噪声) 引发优化不稳定,导致几何形状崩溃(形状失真或漂浮物)。
解决方案:
渐进式频带解封 ------ 训练初期封锁高频分量,逐步释放:# 伪代码:频率掩码应用 (训练步数t, 总步数T)
mask = 1.0 if freq <= (t/T)*max_freq else 0.0 # 线性解封高频
效果:
早期聚焦低频形状建模(粗糙几何)
后期释放高频提升细节(纹理、光照)
避免高频噪声主导优化方向
2️⃣ 遮挡正则化(Occlusion Regularization)
问题根源:视角依赖的表面遮挡歧义(同一位置在不同视角被遮挡程度不同)导致渲染浮点伪影。
解决方案:
几何熵损失(Geometry Entropy Loss):
计算每条光线上的权重分布熵:
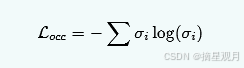
最小化熵 → 迫使权重分布尖锐化(避免半透明漂浮物)
效果:
抑制不合理的遮挡过渡区域
提升几何结构紧凑性
【三维重建2】TCPFormer以及NeRF相关SOTA方法
摘星观月2026-01-12 10:40
相关推荐
Georgeviewer4 小时前
商业落地评测|实体门店GEO优化性价比与服务体系深度复盘GuWenyue4 小时前
分不清AI Workflow与Agent?3个实战案例彻底讲透,做AI应用不再踩选型坑彩讯股份3006345 小时前
彩讯股份与心洲科技签署战略合作协议,共建企业级模型后训练能力迅易科技5 小时前
从场景验证到Agent上线:迅易 × WorkBuddy如何帮助企业建设AI能力?PNP Robotics5 小时前
多伦多大学机器人峰会|物理AI与具身智能落地新趋势GIR1235 小时前
官方出品 | 多通道土壤呼吸测量系统市场现状与十五五规划深度报告:行业分析+趋势预测全收录绿算技术5 小时前
绿算技术亮相第十八届HPC AI中国年会,擘画AI基础设施全栈协同新图景Litluecat6 小时前
2026年7月22日科技热点新闻To_OC6 小时前
别再傻傻分不清:Workflow 和 Agent 到底不是一回事触底反弹6 小时前
🔥 2026 大模型选择指南:别再只看 Benchmark 了,这些维度才是关键!