模型介绍
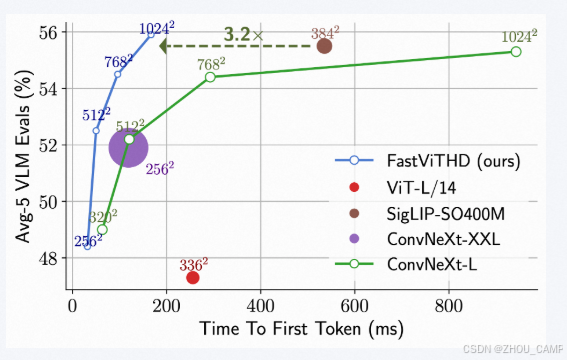
FastVLM(Fast Vision-Language Model)是苹果团队于2025年在CVPR会议上提出的高效视觉语言模型 ,专为移动设备(如iPhone、iPad、Mac)优化,核心创新在于通过全新设计的 FastViTHD混合视觉编码器 解决了传统视觉语言模型(VLM)在高分辨率图像处理中的"编码延迟高、视觉token冗余"等痛点,实现了速度与性能的双重突破。
FastViTHD 采用"卷积神经网络(CNN)+ Transformer"的混合架构,兼顾局部特征提取与全局建模能力,通过三大设计大幅降低计算复杂度:
- 动态分辨率调整:基于特征图信息熵动态分配计算资源,对图像关键区域(如文字、物体)分配高分辨率,背景区域低分辨率,在ImageNet-1K上减少47%计算量;
- 层级 token 压缩:将传统VLM的1536个视觉token压缩至576个(减少62.5%),大幅降低语言模型的处理负担;
- 轻量卷积嵌入:用轻量卷积层(仅增加0.3%参数)替代传统ViT的patch embedding,更快提取局部特征。
模型性能
FastVLM在"首token生成时间(TTFT)"和"模型轻量化"上表现突出:
- 速度对比 :
- 最小变体(FastVLM-0.5B)的TTFT比LLaVA-OneVision-0.5B快85倍 ,比Cambrian-1-8B(基于Qwen2-7B)快7.9倍;
- 在1152×1152高分辨率图像上,整体性能媲美竞品,但视觉编码器体积小3.4倍。
- 硬件适配 :
- 针对苹果A18芯片和M2/M4处理器优化矩阵运算,支持CoreML集成,在iPad Pro M2上实现60 FPS连续对话;
- 动态INT8量化后内存占用减少40%,保持98%精度,0.5B模型的App仅占1.8GB内存。
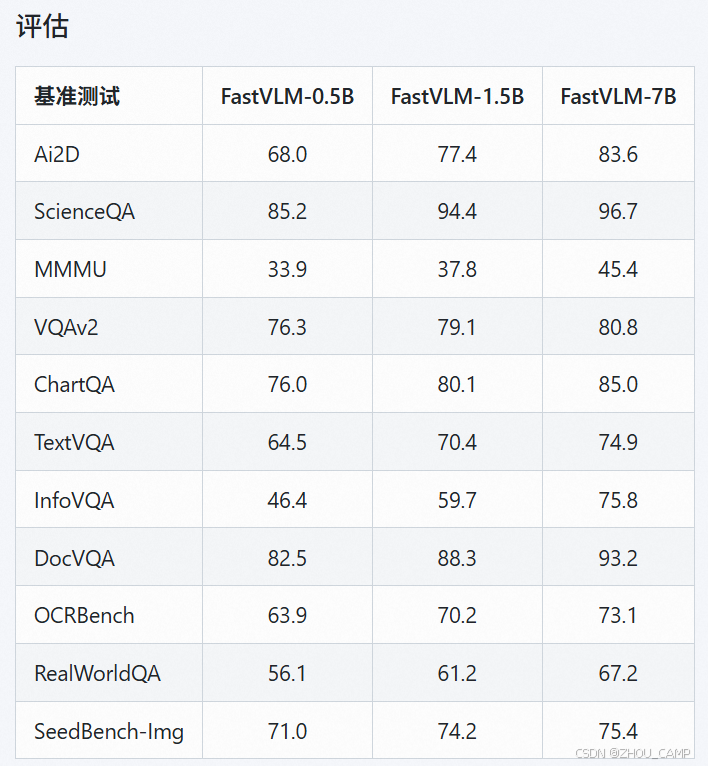
模型加载
python
import torch
from PIL import Image
from modelscope import AutoTokenizer, AutoModelForCausalLM
MID = "apple/FastVLM-0.5B"
IMAGE_TOKEN_INDEX = -200 # what the model code looks for
# Load
tok = AutoTokenizer.from_pretrained(MID, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MID,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True,
)模型配置
python
tok Qwen2TokenizerFast(name_or_path='/home/six/.cache/modelscope/hub/models/apple/FastVLM-0___5B', vocab_size=151643, model_max_length=8192, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'eos_token': '<|im_end|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>']}, clean_up_tokenization_spaces=False, added_tokens_decoder={
151643: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151644: AddedToken("<|im_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151645: AddedToken("<|im_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
python
model.configLlavaConfig {
"architectures": [
"LlavaQwen2ForCausalLM"
],
"attention_dropout": 0.0,
"auto_map": {
"AutoConfig": "llava_qwen.LlavaConfig",
"AutoModelForCausalLM": "llava_qwen.LlavaQwen2ForCausalLM"
},
"bos_token_id": 151643,
"dtype": "float16",
"eos_token_id": 151645,
"freeze_mm_mlp_adapter": false,
"hidden_act": "silu",
"hidden_size": 896,
"image_aspect_ratio": "pad",
"image_grid_pinpoints": null,
"initializer_range": 0.02,
"intermediate_size": 4864,
"layer_types": [
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention"
],
"max_position_embeddings": 32768,
"max_window_layers": 24,
"mm_hidden_size": 3072,
"mm_patch_merge_type": "flat",
"mm_projector_lr": null,
"mm_projector_type": "mlp2x_gelu",
"mm_use_im_patch_token": false,
"mm_use_im_start_end": false,
"mm_vision_select_feature": "patch",
"mm_vision_select_layer": -2,
"mm_vision_tower": "mobileclip_l_1024",
"model_type": "llava_qwen2",
"num_attention_heads": 14,
"num_hidden_layers": 24,
"num_key_value_heads": 2,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000.0,
"sliding_window": null,
"tie_word_embeddings": true,
"tokenizer_model_max_length": 8192,
"tokenizer_padding_side": "right",
"transformers_version": "4.56.0",
"tune_mm_mlp_adapter": false,
"unfreeze_mm_vision_tower": true,
"use_cache": true,
"use_mm_proj": true,
"use_sliding_window": false,
"vocab_size": 151936
}模型结构
python
modelLlavaQwen2ForCausalLM(
(model): LlavaQwen2Model(
(embed_tokens): Embedding(151936, 896)
(layers): ModuleList(
(0-23): 24 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=896, out_features=896, bias=True)
(k_proj): Linear(in_features=896, out_features=128, bias=True)
(v_proj): Linear(in_features=896, out_features=128, bias=True)
(o_proj): Linear(in_features=896, out_features=896, bias=False)
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=896, out_features=4864, bias=False)
(up_proj): Linear(in_features=896, out_features=4864, bias=False)
(down_proj): Linear(in_features=4864, out_features=896, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((896,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
(vision_tower): MobileCLIPVisionTower(
(vision_tower): MCi(
(model): FastViT(
(patch_embed): Sequential(
(0): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(3, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(1): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96)
)
(2): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
)
)
(network): ModuleList(
(0): Sequential(
(0-1): RepMixerBlock(
(token_mixer): RepMixer(
(reparam_conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)
(convffn): ConvFFN(
(conv): Sequential(
(conv): Conv2d(96, 96, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act): GELU(approximate='none')
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
)
)
(1): PatchEmbed(
(proj): Sequential(
(0): ReparamLargeKernelConv(
(activation): GELU(approximate='none')
(se): Identity()
(lkb_reparam): Conv2d(96, 192, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), groups=96)
)
(1): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(2): Sequential(
(0-11): RepMixerBlock(
(token_mixer): RepMixer(
(reparam_conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(convffn): ConvFFN(
(conv): Sequential(
(conv): Conv2d(192, 192, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=192, bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act): GELU(approximate='none')
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
)
)
(3): PatchEmbed(
(proj): Sequential(
(0): ReparamLargeKernelConv(
(activation): GELU(approximate='none')
(se): Identity()
(lkb_reparam): Conv2d(192, 384, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), groups=192)
)
(1): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(4): Sequential(
(0-23): RepMixerBlock(
(token_mixer): RepMixer(
(reparam_conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)
(convffn): ConvFFN(
(conv): Sequential(
(conv): Conv2d(384, 384, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=384, bias=False)
(bn): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Conv2d(384, 1536, kernel_size=(1, 1), stride=(1, 1))
(act): GELU(approximate='none')
(fc2): Conv2d(1536, 384, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
)
(5): PatchEmbed(
(proj): Sequential(
(0): ReparamLargeKernelConv(
(activation): GELU(approximate='none')
(se): Identity()
(lkb_reparam): Conv2d(384, 768, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), groups=384)
)
(1): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(768, 768, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(6): RepCPE(
(reparam_conv): Conv2d(768, 768, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=768)
)
(7): Sequential(
(0-3): AttentionBlock(
(norm): LayerNormChannel()
(token_mixer): MHSA(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(convffn): ConvFFN(
(conv): Sequential(
(conv): Conv2d(768, 768, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=768, bias=False)
(bn): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Conv2d(768, 3072, kernel_size=(1, 1), stride=(1, 1))
(act): GELU(approximate='none')
(fc2): Conv2d(3072, 768, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
)
(8): PatchEmbed(
(proj): Sequential(
(0): ReparamLargeKernelConv(
(activation): GELU(approximate='none')
(se): Identity()
(lkb_reparam): Conv2d(768, 1536, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), groups=768)
)
(1): MobileOneBlock(
(se): Identity()
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(1536, 1536, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(9): RepCPE(
(reparam_conv): Conv2d(1536, 1536, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=1536)
)
(10): Sequential(
(0-1): AttentionBlock(
(norm): LayerNormChannel()
(token_mixer): MHSA(
(qkv): Linear(in_features=1536, out_features=4608, bias=False)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1536, out_features=1536, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(convffn): ConvFFN(
(conv): Sequential(
(conv): Conv2d(1536, 1536, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=1536, bias=False)
(bn): BatchNorm2d(1536, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Conv2d(1536, 6144, kernel_size=(1, 1), stride=(1, 1))
(act): GELU(approximate='none')
(fc2): Conv2d(6144, 1536, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
)
)
(conv_exp): MobileOneBlock(
(se): SEBlock(
(reduce): Conv2d(3072, 192, kernel_size=(1, 1), stride=(1, 1))
(expand): Conv2d(192, 3072, kernel_size=(1, 1), stride=(1, 1))
)
(activation): GELU(approximate='none')
(reparam_conv): Conv2d(1536, 3072, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1536)
)
(head): GlobalPool2D()
)
)
)
(mm_projector): Sequential(
(0): Linear(in_features=3072, out_features=896, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=896, out_features=896, bias=True)
)
)
(lm_head): Linear(in_features=896, out_features=151936, bias=False)
)模型调用

python
# Build chat -> render to string (not tokens) so we can place <image> exactly
messages = [
{"role": "user", "content": "<image>\nDescribe this image in detail."}
]
rendered = tok.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
pre, post = rendered.split("<image>", 1)
# Tokenize the text *around* the image token (no extra specials!)
pre_ids = tok(pre, return_tensors="pt", add_special_tokens=False).input_ids
post_ids = tok(post, return_tensors="pt", add_special_tokens=False).input_ids
# Splice in the IMAGE token id (-200) at the placeholder position
img_tok = torch.tensor([[IMAGE_TOKEN_INDEX]], dtype=pre_ids.dtype)
input_ids = torch.cat([pre_ids, img_tok, post_ids], dim=1).to(model.device)
attention_mask = torch.ones_like(input_ids, device=model.device)
# Preprocess image via the model's own processor
img = Image.open("image.png").convert("RGB")
px = model.get_vision_tower().image_processor(images=img, return_tensors="pt")["pixel_values"]
px = px.to(model.device, dtype=model.dtype)
# Generate
with torch.no_grad():
out = model.generate(
inputs=input_ids,
attention_mask=attention_mask,
images=px,
max_new_tokens=1024,
)
print(tok.decode(out[0], skip_special_tokens=True))### Image Description
The image is a photograph of handwritten notes. It is formatted in a columnar, portrait mode. The notes are written in a somewhat cursive and formal style with regular spacing between lines. The content of the notes is not followed by a specific topic or question, but rather appears to be a detailed narrative or reflection.
#### Breakdown of the Content:
1. **Title or Notation**:
- The first line reads "Remind the both part of realistic history and interpret...". The precise context or terms suggest it might be a summary or introduction to a theoretical discussion, possibly related to historical real-world interpretations or an analytical piece on it.
2. **Paragraph Structure**:
- The text proceeds sequentially down the page, which looks like a detailed narrative or argument. Each paragraph begins with a header, followed by an initial statement or heading.
3. **Content Analysis**:
- **First Paragraph:**
- There appears to be an initial statement emphasizing the comparison between realism, perhaps discussing historical periods such as "the dark" and the "internet buying and Internet buying of things". Parts of the heading might indicate a topic related to real-world analysis or comparison.
- **Second Paragraph:**
- The language becomes more descriptive, discussing the growth of "internet buying and Internet buying of things". Timeframes, statistical data, and percentages hint at a trend or progression being discussed, which indicates it could be a case study or comparative study.
- **Third Paragraph:**
- This part of the document mentions "four years," suggesting it is about a four-year period of observation or change within the context it refers to.
- **Final Paragraph:**
- It concludes with a concise conclusion or observation, indicating that the results of the previous analysis provided are valid or noteworthy.
### Knowledge Integration:
1. **Historical Realism**: Historically, realism is a philosophical approach that posits that we have all knowledge and the nature of reality. This perspective often frames history as an objective recounting of past events without subjective interpretation. Reputations and perceptions have naturally developed over time, often evolving in different ways due to various influences.
2. **Internet Buying of Things**: The term "internet buying of things" suggests a reference to purchasing trends using computer systems, which are pivotal in today's digital economy. The reference to "2019" could be indicating a specific year's perspective, possibly within a historical context for analysis.
### Chain of Thought:
Given the structured format and the reference to "four years," it is plausible that the notes might be part of an analytical and reflective discussion, perhaps comparing old historical realist perspectives of the same historical period with contemporary digital trends, such as internet buying practices.
This comprehensive description should enable a pure text model to effectively parse and answer questions related to the content or structure of the handwritten notes captured in the image.
---
### Analysis
The handwritten notes appear to be an analytical and reflective piece addressing historical realist interpretations and predictions in the context of online buying behaviors. The notes discuss the comparative development of historical realist views about historical periods and their evolution over time. They reference significant dates and percentages, likely from 2019. The notes conclude by noting that there is a direct comparison with current trends, specifically regarding "internet buying" as noted in the 2019 context. The narrative suggests a methodical approach, reflective of a theoretical or analytical examination of past and present trends, possibly using historical realist techniques to contextualize contemporary practices.
The text you provided can be directly converted into a markdown table for better clarity and readability:
| Column | Content |
|---------|-----------|
| 1 | Remind the both part of realistic history and interpret...
| 2 | A comparison between historical periods such as "the dark" and the "internet buying and Internet buying of things".
| 3 | Timeframes of statistical data showing 2019.
| 4 | An example of a year with an increase of 24.5%.
| 5 | An increase of 233 with the year 2023 and a trend of 4303 of years.
| 6 | An additional detail suggesting the possibility of an observer's friends change.
| 7 | Likely a conclusion that the results of previous analysis of realist are valid.
The markdown format simplifies the content and makes it formatted for further reading and