1、首先包含头文件
#include "rknn_api.h"
#include <unistd.h>
#include <set>
#include <vector>
#include <math.h>
编译报错的处理办法,原因:包含了头文件rknn_api.h未找到头文件和库文件
1)首先在inc包含头文件的地方添加头文件rknn_api.h
2)将库文件libriknn_api.so放在文件夹libs/rv1126文件夹下;
再次编译正常。
3)再添加头文件
#include "file_utils.h"
#include "common_ai.h"
#include "image_utils.h" //
#include "image_drawing.h"
编译报错,原来ai文件夹下只有ai.cpp和makefile两个文件,添加的文件在ai文件夹下包括的文件如下:(蓝色文件为添加的文件)
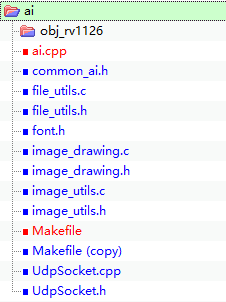
修改ai文件夹下的makefile内容:(红色为自己添加的内容,用的比较软件Beyond Compare)
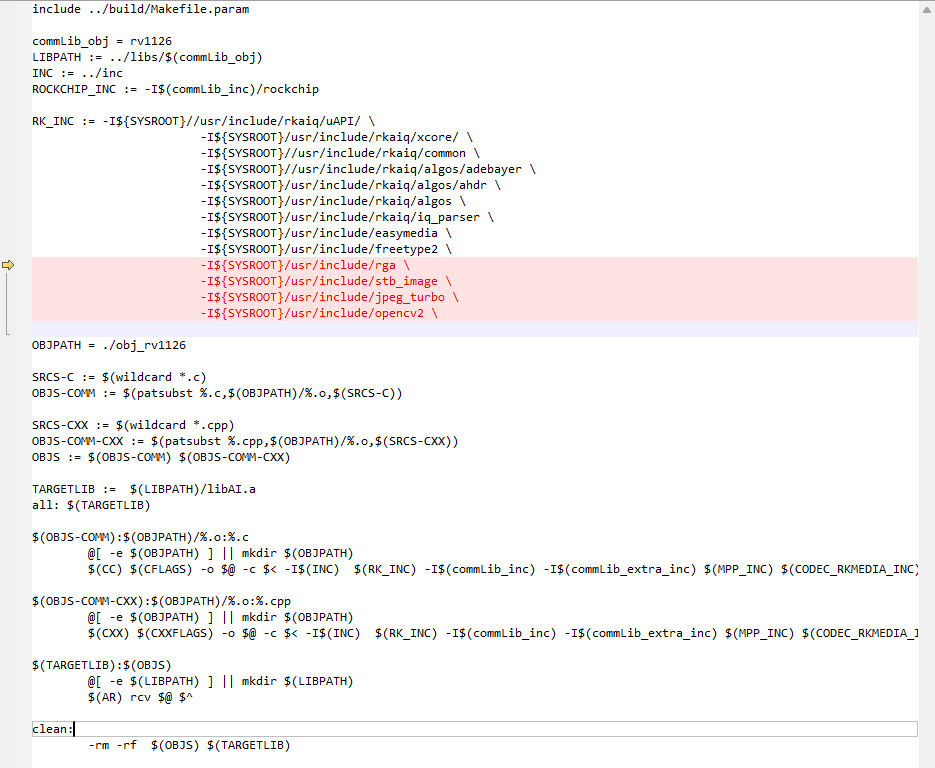
继续添加头文件
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>
#include "gpio.h" //For GPIO By Lzy 20250508
编译正常
4)添加OpenCV和UDP相关头文件如下
//For OpenCV and UDP
#include "core/core.hpp"
#include "highgui.hpp" //Added By Lzy 20240321
#include "opencv.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "UdpSocket.h"//Added By Lzy 20240429
在ai文件夹下编译正常在demo中编译报错如下:
undefined reference to `cv::String::deallocate()' collect2: error: ld returned 1 exit status
解决办法:修改demo文件下的makefile内容如下,再次编译OK。
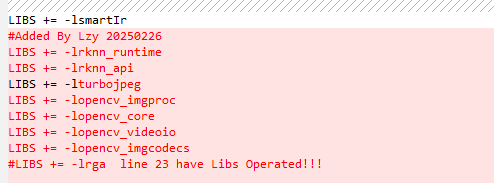
将生成的rv1126_ipc复制到板子所在的路径oem/usr/bin下执行报错如下:
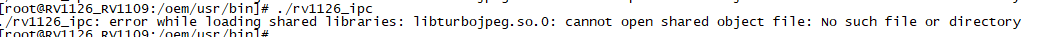
首先在先前的工程中将libturbojpeg.a放在当下的工程文件中的lib/rv1126文件夹下,并再次进行编译将rv1126重新部署在rv1126板子中,运行OK。
注意:libturbojpeg.a并不需要复制到板子中。会编译到程序中。
5)添加自定义变量及函数内容如下:
cpp
static void * ss_hd[MAX_STREAM_NUM] ; //截图句柄
//说明自启动程序需要绝对路经,用当前路径会启动失败。
//-----------------------------Added By Lzy Start ----------------------------------------
#define LABEL_NALE_TXT_PATH "/oem/usr/bin/coco_80_labels_list.txt" //"./coco_80_labels_list.txt"
const char *model_path = "/oem/usr/bin/yolov8.rknn"; //"./yolov8.rknn";
#define OBJ_CLASS_NUM 1 //80
#define OBJ_NAME_MAX_SIZE 64
#define OBJ_NUMB_MAX_SIZE 128
#define NMS_THRESH 0.45
#define BOX_THRESH 0.25
static char *labels[OBJ_CLASS_NUM]; //80 Classes Name
typedef struct {
rknn_context rknn_ctx;
rknn_input_output_num io_num;
rknn_tensor_attr* input_attrs;
rknn_tensor_attr* output_attrs;
int model_channel;
int model_width;
int model_height;
bool is_quant;
} rknn_app_context_t;
//For Yolov8 dectect results
typedef struct {
image_rect_t box;
float prop;
int cls_id;
} object_detect_result;
typedef struct {
int id;
int count;
object_detect_result results[OBJ_NUMB_MAX_SIZE];
} object_detect_result_list;
//Added For Inference using variable By Lzy 20250406
rknn_app_context_t rknn_app_ctx;
image_buffer_t src_image;
object_detect_result_list od_results;
char text[256];
bool bInitYolo=false;
class UdpSocket m_Udp; //Added By Lzy 20250429
char cUdpBuf[5];
struct CONFIG_INI
{
std::string strRtspCamera;
std::string strIpCamera;
std::string strIpMonitor;
unsigned int iPortMonitor;
};
inline static int clamp(float val, int min, int max) { return val > min ? (val < max ? val : max) : min; }
static char *readLine(FILE *fp, char *buffer, int *len)
{
int ch;
int i = 0;
size_t buff_len = 0;
buffer = (char *)malloc(buff_len + 1);
if (!buffer)
return NULL; // Out of memory
while ((ch = fgetc(fp)) != '\n' && ch != EOF)
{
buff_len++;
void *tmp = realloc(buffer, buff_len + 1);
if (tmp == NULL)
{
free(buffer);
return NULL; // Out of memory
}
buffer = (char *)tmp;
buffer[i] = (char)ch;
i++;
}
buffer[i] = '\0';
*len = buff_len;
// Detect end
if (ch == EOF && (i == 0 || ferror(fp)))
{
free(buffer);
return NULL;
}
return buffer;
}
static int readLines(const char *fileName, char *lines[], int max_line)
{
FILE *file = fopen(fileName, "r");
char *s;
int i = 0;
int n = 0;
if (file == NULL)
{
printf("Open %s fail!\n", fileName);
return -1;
}
while ((s = readLine(file, s, &n)) != NULL)
{
lines[i++] = s;
if (i >= max_line)
break;
}
fclose(file);
return i;
}
static int loadLabelName(const char *locationFilename, char *label[])
{
printf("load lable %s\n", locationFilename);
readLines(locationFilename, label, OBJ_CLASS_NUM);
return 0;
}
int init_post_process()
{
int ret = 0;
ret = loadLabelName(LABEL_NALE_TXT_PATH, labels);
if (ret < 0)
{
printf("Load %s failed!\n", LABEL_NALE_TXT_PATH);
return -1;
}
return 0;
}
static void dump_tensor_attr(rknn_tensor_attr *attr)
{
printf(" index=%d, name=%s, n_dims=%d, dims=[%d, %d, %d, %d], n_elems=%d, size=%d, fmt=%s, type=%s, qnt_type=%s, "
"zp=%d, scale=%f\n",
attr->index, attr->name, attr->n_dims, attr->dims[3], attr->dims[2], attr->dims[1], attr->dims[0],
attr->n_elems, attr->size, get_format_string(attr->fmt), get_type_string(attr->type),
get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}
int init_yolov8_model(const char *model_path, rknn_app_context_t *app_ctx)
{
int ret;
int model_len = 0;
char *model;
rknn_context ctx = 0;
// Load RKNN Model
model_len = read_data_from_file(model_path, &model);
if (model == NULL)
{
printf("load_model fail!\n");
return -1;
}
ret = rknn_init(&ctx, model, model_len, 0);
free(model);
if (ret < 0)
{
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
// Get Model Input Output Number
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
// Get Model Input Info
printf("input tensors:\n");
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
dump_tensor_attr(&(input_attrs[i]));
}
// Get Model Output Info
printf("output tensors:\n");
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
dump_tensor_attr(&(output_attrs[i]));
}
// Set to context
app_ctx->rknn_ctx = ctx;
// TODO
if (output_attrs[0].qnt_type == RKNN_TENSOR_QNT_AFFINE_ASYMMETRIC && output_attrs[0].type == RKNN_TENSOR_UINT8)
{
app_ctx->is_quant = true;
}
else
{
app_ctx->is_quant = false;
}
app_ctx->io_num = io_num;
app_ctx->input_attrs = (rknn_tensor_attr *)malloc(io_num.n_input * sizeof(rknn_tensor_attr));
memcpy(app_ctx->input_attrs, input_attrs, io_num.n_input * sizeof(rknn_tensor_attr));
app_ctx->output_attrs = (rknn_tensor_attr *)malloc(io_num.n_output * sizeof(rknn_tensor_attr));
memcpy(app_ctx->output_attrs, output_attrs, io_num.n_output * sizeof(rknn_tensor_attr));
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW)
{
printf("model is NCHW input fmt\n");
app_ctx->model_channel = input_attrs[0].dims[2];
app_ctx->model_height = input_attrs[0].dims[1];
app_ctx->model_width = input_attrs[0].dims[0];
}
else
{
printf("model is NHWC input fmt\n");
app_ctx->model_height = input_attrs[0].dims[2];
app_ctx->model_width = input_attrs[0].dims[1];
app_ctx->model_channel = input_attrs[0].dims[0];
}
printf("model input height=%d, width=%d, channel=%d\n",
app_ctx->model_height, app_ctx->model_width, app_ctx->model_channel);
return 0;
}
static float CalculateOverlap(float xmin0, float ymin0, float xmax0, float ymax0, float xmin1, float ymin1, float xmax1,
float ymax1)
{
float w = fmax(0.f, fmin(xmax0, xmax1) - fmax(xmin0, xmin1) + 1.0);
float h = fmax(0.f, fmin(ymax0, ymax1) - fmax(ymin0, ymin1) + 1.0);
float i = w * h;
float u = (xmax0 - xmin0 + 1.0) * (ymax0 - ymin0 + 1.0) + (xmax1 - xmin1 + 1.0) * (ymax1 - ymin1 + 1.0) - i;
return u <= 0.f ? 0.f : (i / u);
}
static int nms(int validCount, std::vector<float> &outputLocations, std::vector<int> classIds, std::vector<int> &order,
int filterId, float threshold)
{
for (int i = 0; i < validCount; ++i)
{
int n = order[i];
if (n == -1 || classIds[n] != filterId)
{
continue;
}
for (int j = i + 1; j < validCount; ++j)
{
int m = order[j];
if (m == -1 || classIds[m] != filterId)
{
continue;
}
float xmin0 = outputLocations[n * 4 + 0];
float ymin0 = outputLocations[n * 4 + 1];
float xmax0 = outputLocations[n * 4 + 0] + outputLocations[n * 4 + 2];
float ymax0 = outputLocations[n * 4 + 1] + outputLocations[n * 4 + 3];
float xmin1 = outputLocations[m * 4 + 0];
float ymin1 = outputLocations[m * 4 + 1];
float xmax1 = outputLocations[m * 4 + 0] + outputLocations[m * 4 + 2];
float ymax1 = outputLocations[m * 4 + 1] + outputLocations[m * 4 + 3];
float iou = CalculateOverlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1);
if (iou > threshold)
{
order[j] = -1;
}
}
}
return 0;
}
static int quick_sort_indice_inverse(std::vector<float> &input, int left, int right, std::vector<int> &indices)
{
float key;
int key_index;
int low = left;
int high = right;
if (left < right)
{
key_index = indices[left];
key = input[left];
while (low < high)
{
while (low < high && input[high] <= key)
{
high--;
}
input[low] = input[high];
indices[low] = indices[high];
while (low < high && input[low] >= key)
{
low++;
}
input[high] = input[low];
indices[high] = indices[low];
}
input[low] = key;
indices[low] = key_index;
quick_sort_indice_inverse(input, left, low - 1, indices);
quick_sort_indice_inverse(input, low + 1, right, indices);
}
return low;
}
inline static int32_t __clip(float val, float min, float max)
{
float f = val <= min ? min : (val >= max ? max : val);
return f;
}
static uint8_t qnt_f32_to_affine_u8(float f32, int32_t zp, float scale)
{
float dst_val = (f32 / scale) + zp;
uint8_t res = (uint8_t)__clip(dst_val, 0, 255);
return res;
}
static float deqnt_affine_u8_to_f32(uint8_t qnt, int32_t zp, float scale) { return ((float)qnt - (float)zp) * scale; }
static void compute_dfl(float* tensor, int dfl_len, float* box){
for (int b=0; b<4; b++){
float exp_t[dfl_len];
float exp_sum=0;
float acc_sum=0;
for (int i=0; i< dfl_len; i++){
exp_t[i] = exp(tensor[i+b*dfl_len]);
exp_sum += exp_t[i];
}
for (int i=0; i< dfl_len; i++){
acc_sum += exp_t[i]/exp_sum *i;
}
box[b] = acc_sum;
}
}
static int process_u8(uint8_t *box_tensor, int32_t box_zp, float box_scale,
uint8_t *score_tensor, int32_t score_zp, float score_scale,
uint8_t *score_sum_tensor, int32_t score_sum_zp, float score_sum_scale,
int grid_h, int grid_w, int stride, int dfl_len,
std::vector<float> &boxes,
std::vector<float> &objProbs,
std::vector<int> &classId,
float threshold)
{
int validCount = 0;
int grid_len = grid_h * grid_w;
uint8_t score_thres_u8 = qnt_f32_to_affine_u8(threshold, score_zp, score_scale);
uint8_t score_sum_thres_u8 = qnt_f32_to_affine_u8(threshold, score_sum_zp, score_sum_scale);
for (int i = 0; i < grid_h; i++)
{
for (int j = 0; j < grid_w; j++)
{
int offset = i * grid_w + j;
int max_class_id = -1;
// Use score sum to quickly filter
if (score_sum_tensor != nullptr)
{
if (score_sum_tensor[offset] < score_sum_thres_u8)
{
continue;
}
}
uint8_t max_score = -score_zp;
for (int c = 0; c < OBJ_CLASS_NUM; c++)
{
if ((score_tensor[offset] > score_thres_u8) && (score_tensor[offset] > max_score))
{
max_score = score_tensor[offset];
max_class_id = c;
}
offset += grid_len;
}
// compute box
if (max_score > score_thres_u8)
{
offset = i * grid_w + j;
float box[4];
float before_dfl[dfl_len * 4];
for (int k = 0; k < dfl_len * 4; k++)
{
before_dfl[k] = deqnt_affine_u8_to_f32(box_tensor[offset], box_zp, box_scale);
offset += grid_len;
}
compute_dfl(before_dfl, dfl_len, box);
float x1, y1, x2, y2, w, h;
x1 = (-box[0] + j + 0.5) * stride;
y1 = (-box[1] + i + 0.5) * stride;
x2 = (box[2] + j + 0.5) * stride;
y2 = (box[3] + i + 0.5) * stride;
w = x2 - x1;
h = y2 - y1;
boxes.push_back(x1);
boxes.push_back(y1);
boxes.push_back(w);
boxes.push_back(h);
objProbs.push_back(deqnt_affine_u8_to_f32(max_score, score_zp, score_scale));
classId.push_back(max_class_id);
validCount++;
}
}
}
return validCount;
}
int post_process(rknn_app_context_t *app_ctx, void *outputs, letterbox_t *letter_box, float conf_threshold, float nms_threshold, object_detect_result_list *od_results)
{
rknn_output *_outputs = (rknn_output *)outputs;
std::vector<float> filterBoxes;
std::vector<float> objProbs;
std::vector<int> classId;
int validCount = 0;
int stride = 0;
int grid_h = 0;
int grid_w = 0;
int model_in_w = app_ctx->model_width;
int model_in_h = app_ctx->model_height;
memset(od_results, 0, sizeof(object_detect_result_list));
// default 3 branch
int dfl_len = app_ctx->output_attrs[0].dims[2] / 4;
int output_per_branch = app_ctx->io_num.n_output / 3;
for (int i = 0; i < 3; i++)
{
void *score_sum = nullptr;
int32_t score_sum_zp = 0;
float score_sum_scale = 1.0;
if (output_per_branch == 3){
score_sum = _outputs[i*output_per_branch + 2].buf;
score_sum_zp = app_ctx->output_attrs[i*output_per_branch + 2].zp;
score_sum_scale = app_ctx->output_attrs[i*output_per_branch + 2].scale;
}
int box_idx = i*output_per_branch;
int score_idx = i*output_per_branch + 1;
grid_h = app_ctx->output_attrs[box_idx].dims[1];
grid_w = app_ctx->output_attrs[box_idx].dims[0];
stride = model_in_h / grid_h;
if (app_ctx->is_quant)
{
validCount += process_u8((uint8_t *)_outputs[box_idx].buf, app_ctx->output_attrs[box_idx].zp, app_ctx->output_attrs[box_idx].scale,
(uint8_t *)_outputs[score_idx].buf, app_ctx->output_attrs[score_idx].zp, app_ctx->output_attrs[score_idx].scale,
(uint8_t *)score_sum, score_sum_zp, score_sum_scale,
grid_h, grid_w, stride, dfl_len,
filterBoxes, objProbs, classId, conf_threshold);
}
else
{
/*
validCount += process_fp32((float *)_outputs[box_idx].buf, (float *)_outputs[score_idx].buf, (float *)score_sum,
grid_h, grid_w, stride, dfl_len,
filterBoxes, objProbs, classId, conf_threshold);
*/
}
}
// no object detect
if (validCount <= 0)
{
return 0;
}
std::vector<int> indexArray;
for (int i = 0; i < validCount; ++i)
{
indexArray.push_back(i);
}
quick_sort_indice_inverse(objProbs, 0, validCount - 1, indexArray);
std::set<int> class_set(std::begin(classId), std::end(classId));
for (auto c : class_set)
{
nms(validCount, filterBoxes, classId, indexArray, c, nms_threshold);
}
int last_count = 0;
od_results->count = 0;
/* box valid detect target */
for (int i = 0; i < validCount; ++i)
{
if (indexArray[i] == -1 || last_count >= OBJ_NUMB_MAX_SIZE)
{
continue;
}
int n = indexArray[i];
float x1 = filterBoxes[n * 4 + 0] - letter_box->x_pad;
float y1 = filterBoxes[n * 4 + 1] - letter_box->y_pad;
float x2 = x1 + filterBoxes[n * 4 + 2];
float y2 = y1 + filterBoxes[n * 4 + 3];
int id = classId[n];
float obj_conf = objProbs[i];
od_results->results[last_count].box.left = (int)(clamp(x1, 0, model_in_w) / letter_box->scale);
od_results->results[last_count].box.top = (int)(clamp(y1, 0, model_in_h) / letter_box->scale);
od_results->results[last_count].box.right = (int)(clamp(x2, 0, model_in_w) / letter_box->scale);
od_results->results[last_count].box.bottom = (int)(clamp(y2, 0, model_in_h) / letter_box->scale);
od_results->results[last_count].prop = obj_conf;
od_results->results[last_count].cls_id = id;
last_count++;
}
od_results->count = last_count;
return 0;
}
char *coco_cls_to_name(int cls_id)
{
if (cls_id >= OBJ_CLASS_NUM)
{
return "null";
}
if (labels[cls_id])
{
return labels[cls_id];
}
return "null";
}
void deinit_post_process()
{
for (int i = 0; i < OBJ_CLASS_NUM; i++)
{
if (labels[i] != nullptr)
{
free(labels[i]);
labels[i] = nullptr;
}
}
}
int release_yolov8_model(rknn_app_context_t *app_ctx)
{
if (app_ctx->input_attrs != NULL)
{
free(app_ctx->input_attrs);
app_ctx->input_attrs = NULL;
}
if (app_ctx->output_attrs != NULL)
{
free(app_ctx->output_attrs);
app_ctx->output_attrs = NULL;
}
if (app_ctx->rknn_ctx != 0)
{
rknn_destroy(app_ctx->rknn_ctx);
app_ctx->rknn_ctx = 0;
}
return 0;
}
int inference_yolov8_model(rknn_app_context_t *app_ctx, image_buffer_t *img, object_detect_result_list *od_results)
{
int ret;
image_buffer_t dst_img;
letterbox_t letter_box;
rknn_input inputs[app_ctx->io_num.n_input];
rknn_output outputs[app_ctx->io_num.n_output];
const float nms_threshold = NMS_THRESH; // Default NMS threshold
const float box_conf_threshold = BOX_THRESH; // Default box threshold
int bg_color = 114;
if ((!app_ctx) || !(img) || (!od_results))
{
return -1;
}
memset(od_results, 0x00, sizeof(*od_results));
memset(&letter_box, 0, sizeof(letterbox_t));
memset(&dst_img, 0, sizeof(image_buffer_t));
memset(inputs, 0, sizeof(inputs));
memset(outputs, 0, sizeof(outputs));
// Pre Process
dst_img.width = app_ctx->model_width;
dst_img.height = app_ctx->model_height;
dst_img.format = IMAGE_FORMAT_RGB888;
dst_img.size = get_image_size(&dst_img);
dst_img.virt_addr = (unsigned char *)malloc(dst_img.size);
if (dst_img.virt_addr == NULL)
{
printf("malloc buffer size:%d fail!\n", dst_img.size);
return -1;
}
// letterbox
ret = convert_image_with_letterbox(img, &dst_img, &letter_box, bg_color);
if (ret < 0)
{
printf("convert_image_with_letterbox fail! ret=%d\n", ret);
return -1;
}
// Set Input Data
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].size = app_ctx->model_width * app_ctx->model_height * app_ctx->model_channel;
inputs[0].buf = dst_img.virt_addr;
ret = rknn_inputs_set(app_ctx->rknn_ctx, app_ctx->io_num.n_input, inputs);
if (ret < 0)
{
printf("rknn_input_set fail! ret=%d\n", ret);
return -1;
}
// Run
printf("rknn_run\n");
ret = rknn_run(app_ctx->rknn_ctx, nullptr);
if (ret < 0)
{
printf("rknn_run fail! ret=%d\n", ret);
return -1;
}
// Get Output
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < app_ctx->io_num.n_output; i++)
{
outputs[i].index = i;
outputs[i].want_float = (!app_ctx->is_quant);
}
ret = rknn_outputs_get(app_ctx->rknn_ctx, app_ctx->io_num.n_output, outputs, NULL);
if (ret < 0)
{
printf("rknn_outputs_get fail! ret=%d\n", ret);
goto out;
}
// Post Process
post_process(app_ctx, outputs, &letter_box, box_conf_threshold, nms_threshold, od_results);
// Remeber to release rknn output
rknn_outputs_release(app_ctx->rknn_ctx, app_ctx->io_num.n_output, outputs);
out:
if (dst_img.virt_addr != NULL)
{
free(dst_img.virt_addr);
}
return ret;
}
//--For Main Function Test-----------------------------------
void RknnTest()
{
//const char *model_path = "./yolov8.rknn";
const char *image_path = "./bus.jpg";
const char *image_path_ex="./test.jpg";
int ret;
rknn_app_context_t rknn_app_ctx;
memset(&rknn_app_ctx, 0, sizeof(rknn_app_context_t));
init_post_process();
ret = init_yolov8_model(model_path, &rknn_app_ctx);
if (ret != 0)
{
printf("init_yolov8_model fail! ret=%d model_path=%s\n", ret, model_path);
goto out;
}
else
printf("init_yolov8_model YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY! ret=%d model_path=%s\n", ret, model_path);
image_buffer_t src_image;
memset(&src_image, 0, sizeof(image_buffer_t));
ret = read_image(image_path, &src_image);
if (ret != 0)
{
printf("read image fail! ret=%d image_path=%s\n", ret, image_path);
goto out;
}
else
printf("read image YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY! ret=%d image_path=%s\n", ret, image_path);
object_detect_result_list od_results;
ret = inference_yolov8_model(&rknn_app_ctx, &src_image, &od_results);
if (ret != 0)
{
printf("init_yolov8_model fail! ret=%d\n", ret);
goto out;
}
// 画框和概率
char text[256];
for (int i = 0; i < od_results.count; i++)
{
object_detect_result *det_result = &(od_results.results[i]);
printf("%s @ (%d %d %d %d) %.3f\n", coco_cls_to_name(det_result->cls_id),
det_result->box.left, det_result->box.top,
det_result->box.right, det_result->box.bottom,
det_result->prop);
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
draw_rectangle(&src_image, x1, y1, x2 - x1, y2 - y1, COLOR_BLUE, 3);
sprintf(text, "%s %.1f%%", coco_cls_to_name(det_result->cls_id), det_result->prop * 100);
draw_text(&src_image, text, x1, y1 - 20, COLOR_RED, 10);
}
write_image("out.png", &src_image);
#if 0 //For Test 1080P jpg Image
memset(&src_image, 0, sizeof(image_buffer_t));
ret = read_image(image_path_ex, &src_image);
if (ret != 0)
{
printf("read image fail! ret=%d image_path=%s\n", ret, image_path);
goto out;
}
else
printf("read image YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY! ret=%d image_path=%s\n", ret, image_path);
ret = inference_yolov8_model(&rknn_app_ctx, &src_image, &od_results);
if (ret != 0)
{
printf("init_yolov8_model fail! ret=%d\n", ret);
goto out;
}
// 画框和概率
for (int i = 0; i < od_results.count; i++)
{
object_detect_result *det_result = &(od_results.results[i]);
printf("%s @ (%d %d %d %d) %.3f\n", coco_cls_to_name(det_result->cls_id),
det_result->box.left, det_result->box.top,
det_result->box.right, det_result->box.bottom,
det_result->prop);
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
draw_rectangle(&src_image, x1, y1, x2 - x1, y2 - y1, COLOR_BLUE, 3);
sprintf(text, "%s %.1f%%", coco_cls_to_name(det_result->cls_id), det_result->prop * 100);
draw_text(&src_image, text, x1, y1 - 20, COLOR_RED, 10);
}
write_image("out_ex.png", &src_image);
#endif
out:
deinit_post_process();
ret = release_yolov8_model(&rknn_app_ctx);
if (ret != 0)
{
printf("release_yolov8_model fail! ret=%d\n", ret);
}
if (src_image.virt_addr != NULL)
{
free(src_image.virt_addr);
}
return ;
}
bool RknnInit()
{
int ret;
memset(&rknn_app_ctx, 0, sizeof(rknn_app_context_t));
init_post_process();
ret = init_yolov8_model(model_path, &rknn_app_ctx);
if (ret != 0)
{
printf("init_yolov8_model fail! ret=%d model_path=%s\n", ret, model_path);
goto out;
}
else
{
printf("init_yolov8_model YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY! ret=%d model_path=%s\n", ret, model_path);
return true;
}
out:
deinit_post_process();
ret = release_yolov8_model(&rknn_app_ctx);
if (ret != 0)
{
printf("release_yolov8_model fail! ret=%d\n", ret);
}
if (src_image.virt_addr != NULL)
{
free(src_image.virt_addr);
}
return -1;
}
int post_process_ex(rknn_app_context_t *app_ctx, void *outputs, float scale_w, float scale_h, float conf_threshold, float nms_threshold, object_detect_result_list *od_results) //For YoloV8
{
rknn_output *_outputs = (rknn_output *)outputs;
std::vector<float> filterBoxes;
std::vector<float> objProbs;
std::vector<int> classId;
int validCount = 0;
int stride = 0;
int grid_h = 0;
int grid_w = 0;
int model_in_w = app_ctx->model_width;
int model_in_h = app_ctx->model_height;
memset(od_results, 0, sizeof(object_detect_result_list));
#if 1//RKNPU1_SET //For RKNPU1
int dfl_len = app_ctx->output_attrs[0].dims[2] / 4;
#else //For RKNPU2
int dfl_len = app_ctx->output_attrs[0].dims[1] / 4;
#endif
int output_per_branch = app_ctx->io_num.n_output / 3;
for (int i = 0; i < 3; i++)
{
void *score_sum = nullptr;
int32_t score_sum_zp = 0;
float score_sum_scale = 1.0;
if (output_per_branch == 3)
{
score_sum = _outputs[i * output_per_branch + 2].buf;
score_sum_zp = app_ctx->output_attrs[i * output_per_branch + 2].zp;
score_sum_scale = app_ctx->output_attrs[i * output_per_branch + 2].scale;
}
int box_idx = i * output_per_branch;
int score_idx = i * output_per_branch + 1;
#if 1 //RKNPU1_SET //For RKNPU1
grid_h = app_ctx->output_attrs[box_idx].dims[1];
grid_w = app_ctx->output_attrs[box_idx].dims[0];
#else
grid_h = app_ctx->output_attrs[box_idx].dims[2];
grid_w = app_ctx->output_attrs[box_idx].dims[3];
#endif
stride = model_in_h / grid_h;
if (app_ctx->is_quant)
{
#if 1 //RKNPU1_SET //For RKNPU1
validCount += process_u8((uint8_t *)_outputs[box_idx].buf, app_ctx->output_attrs[box_idx].zp, app_ctx->output_attrs[box_idx].scale,
(uint8_t *)_outputs[score_idx].buf, app_ctx->output_attrs[score_idx].zp, app_ctx->output_attrs[score_idx].scale,
(uint8_t *)score_sum, score_sum_zp, score_sum_scale,
grid_h, grid_w, stride, dfl_len,
filterBoxes, objProbs, classId, conf_threshold);
#else
validCount += process_i8((int8_t *)_outputs[box_idx].buf, app_ctx->output_attrs[box_idx].zp, app_ctx->output_attrs[box_idx].scale,
(int8_t *)_outputs[score_idx].buf, app_ctx->output_attrs[score_idx].zp, app_ctx->output_attrs[score_idx].scale,
(int8_t *)score_sum, score_sum_zp, score_sum_scale,
grid_h, grid_w, stride, dfl_len,
filterBoxes, objProbs, classId, conf_threshold);
#endif
}
else
{
/*
validCount += process_fp32((float *)_outputs[box_idx].buf, (float *)_outputs[score_idx].buf, (float *)score_sum,
grid_h, grid_w, stride, dfl_len,
filterBoxes, objProbs, classId, conf_threshold);
*/
}
}
// no object detect
if (validCount <= 0)
{
return 0;
}
std::vector<int> indexArray;
for (int i = 0; i < validCount; ++i)
{
indexArray.push_back(i);
}
quick_sort_indice_inverse(objProbs, 0, validCount - 1, indexArray);
std::set<int> class_set(std::begin(classId), std::end(classId));
for (auto c : class_set)
{
nms(validCount, filterBoxes, classId, indexArray, c, nms_threshold);
}
int last_count = 0;
od_results->count = 0;
/* box valid detect target */
for (int i = 0; i < validCount; ++i)
{
if (indexArray[i] == -1 || last_count >= OBJ_NUMB_MAX_SIZE)
{
continue;
}
int n = indexArray[i];
if(1)//if (sSysCtrl.bDetect && m_Config.labelsFlag[classId[n]]) // Added the limit By Lzy
{ // Added
float x1 = filterBoxes[n * 4 + 0]; //- letter_box->x_pad;
float y1 = filterBoxes[n * 4 + 1]; //- letter_box->y_pad;
float x2 = x1 + filterBoxes[n * 4 + 2];
float y2 = y1 + filterBoxes[n * 4 + 3];
int id = classId[n];
float obj_conf = objProbs[i];
od_results->results[last_count].box.left = (int)(clamp(x1, 0, model_in_w) / scale_w); // letter_box->scale);
od_results->results[last_count].box.top = (int)(clamp(y1, 0, model_in_h) / scale_h); // letter_box->scale);
od_results->results[last_count].box.right = (int)(clamp(x2, 0, model_in_w) / scale_w); // letter_box->scale);
od_results->results[last_count].box.bottom = (int)(clamp(y2, 0, model_in_h) / scale_h); // letter_box->scale);
od_results->results[last_count].prop = obj_conf;
od_results->results[last_count].cls_id = id;
last_count++;
} // Added
}
od_results->count = last_count;
return 0;
}
int NpuRun(void *data, rknn_app_context_t *app_ctx, float scale_w, float scale_h, object_detect_result_list *od_results)
{
int ret;
rknn_input inputs[app_ctx->io_num.n_input];
rknn_output outputs[app_ctx->io_num.n_output];
const float nms_threshold = NMS_THRESH; // 默认的NMS阈值
const float box_conf_threshold = BOX_THRESH; // 默认的置信度阈值
int bg_color = 114;
memset(od_results, 0x00, sizeof(*od_results));
memset(inputs, 0, sizeof(inputs));
memset(outputs, 0, sizeof(outputs));
// Set Input Data
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].size = app_ctx->model_width * app_ctx->model_height * app_ctx->model_channel;
inputs[0].buf = (void *)data;
ret =rknn_inputs_set(app_ctx->rknn_ctx, app_ctx->io_num.n_input, inputs);
if (ret < 0)
{
printf("rknn_input_set fail! ret=%d\n", ret);
return -1;
}
ret = rknn_run(app_ctx->rknn_ctx, nullptr);
if (ret < 0)
{
printf("rknn_run fail! ret=%d\n", ret);
return -1;
}
// Get Output
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < app_ctx->io_num.n_output; i++)
{
outputs[i].index = i;
outputs[i].want_float = (!app_ctx->is_quant);
}
ret = rknn_outputs_get(app_ctx->rknn_ctx, app_ctx->io_num.n_output, outputs, NULL);
if (ret < 0)
{
printf("rknn_outputs_get fail! ret=%d\n", ret);
return -1;
}
// Post Process
post_process_ex(app_ctx, outputs, scale_w, scale_h, box_conf_threshold, nms_threshold, od_results);
// Remeber to release rknn output
rknn_outputs_release(app_ctx->rknn_ctx, app_ctx->io_num.n_output, outputs);
return 0;
}二、修改系统原有函数中的内容
1、在函数int comm_ai_init()中添加内容如下
cpp
if(RknnInit())
{
bInitYolo=true;
printf("Npu Init OK OK OK\n");
}
else
printf("Npu Init NG NG NG\n");2、在函数comm_ai_process(int stream_index, void *mb, void *puser)中添加内容如下
1)首先注释掉原函数中的模拟ai耗时语句,内容如下
cpp
//comm_ai_test(); //模拟ai 耗时
//printFps("AI frame",10000); 2)添加AI处理函数
cpp
if(bInitYolo)
{
cv::Mat origin_mat = cv::Mat::zeros(1080, 1920, CV_8UC3);
memcpy(origin_mat.data,rgb_buff[stream_index],1920*1080*3);
cv::resize(origin_mat,matResize,cv::Size(640,640),0,0,0);//Nearest
NpuRun(matResize.data, &rknn_app_ctx, 640 / 1920.0, 640 / 1080.0, &od_results);
}经验证测试代码需修改为:
cpp
if(bInitYolo)
{
cv::Mat origin_mat = cv::Mat::zeros(640, 640, CV_8UC3);
memcpy(origin_mat.data,rgb_buff[stream_index],640*640*3);//rgb_buff[stream_index] haved trans to 640*640
//cv::resize(origin_mat,matResize,cv::Size(640,640),0,0,0);//Nearest
NpuRun(origin_mat.data, &rknn_app_ctx, 640 / 1920.0, 640 / 1080.0, &od_results);
}对转换的图像进行保存测试语句如下
cpp
static bool bA=true;
if(bA)
{
cv::imwrite("./11.bmp",origin_mat);
cv::imwrite("./22.bmp",matResize);
bA=false;
}经测试原图如下:(说明图像保存的图像尺寸与获取的图像尺寸不一致),经代码走查,rgb_buff已经将图像缩放成640*640没必要再进行缩放了。问题得以解决。

3)为便于AI后处理需要,需对OSD进行重新编写