目录
[① 优势](#① 优势)
[② 应用场景](#② 应用场景)
[4、随机森林算法 -- 代码实现](#4、随机森林算法 – 代码实现)
[① AdaBoost 算法推导](#① AdaBoost 算法推导)
[② 构建流程(权重更新计算)](#② 构建流程(权重更新计算))
一、集成学习思想
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(弱学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
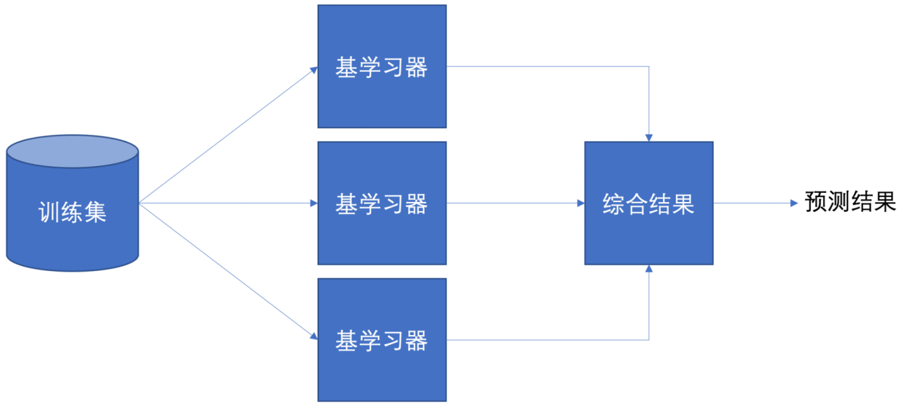
Bagging:随机森林
Boosting:Adaboost、GBDT、XGBoost、LightGBM
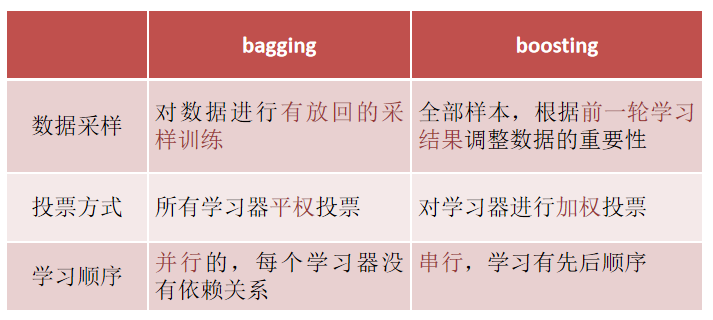
1、bagging集成思想
有**放回的抽样(bootstrap抽样)**产生不同的训练集,从而训练不同的学习器
通过平权投票、多数表决的方式决定预测结果
弱学习器可以并行训练
2、boosting集成思想
每一个训练器重点关注前一个训练器不足的地方进行训练
通过加权投票的方式,得出预测结果
串行的训练方式
3、Bagging&Boosting对比
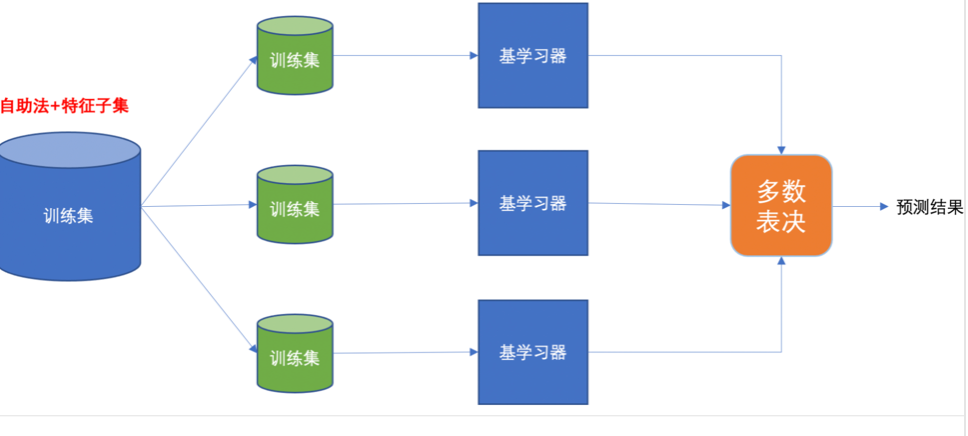
二、随机森林算法
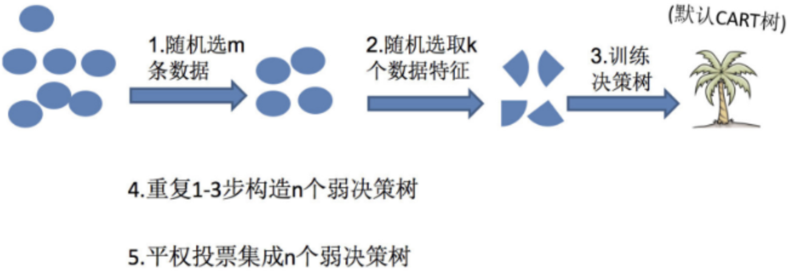
随机森林是基于 Bagging 思想实现的一种集成学习算法,采用决策树模型作为每一个弱学习器。
1、流程
①训练
有放回的产生训练样本
随机挑选 n 个特征(n 小于总特征数量)
②预测
平权投票,多数表决输出预测结果
2、疑点解答
①为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
②为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
3、优势及应用场景
① 优势
高准确性与鲁棒性 :通过集成多棵树的预测,降低了方差,通常能获得比单棵决策树更高的准确性,并对噪声数据和缺失值不敏感
抗过拟合能力 :Bootstrap抽样和随机特征选择引入了随机性,有效降低了模型过拟合的风险
评估特征重要性 :能够提供特征重要性的估计,帮助理解哪些特征对预测结果贡献最大
并行化训练:每棵决策树的构建是独立的,因此算法易于并行化,提高了训练效率
处理高维数据:能够处理特征数量多的数据集,并在特征选择方面表现出色
② 应用场景
分类问题:如医疗诊断(疾病预测)、金融风控(欺诈检测、信用评分)、图像分类等
回归问题 :如房价预测、销售额预测、股票价格预测等
特征选择 :通过分析特征重要性,进行特征筛选
异常检测 :如信用卡欺诈识别、网络入侵检测等
4、随机森林算法 -- 代码实现
① 导包
python
from sklearn.ensemble import RandomForestClassifier # 随机森林分类算法
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.model_selection import GridSearchCV # 网格搜索交叉验证
import pandas as pd② 数据导入及数据预处理
(本文中是基于泰坦尼克号数据,也可自己寻找其他数据进行训练)
python
df = pd.read_csv('train.csv')
# df. info()
# 数据预处理
x = df[['Pclass', 'Sex', 'Age', 'Fare','SibSp']].copy()
y = df['Survived']
x['Age'] = x['Age'].fillna(x['Age'].mean()) # 填充年龄(平均值)
x = pd.get_dummies(x) # 独热编码, 将分类变量转换为数字
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=28, shuffle=True)③ 模型训练
python
# 随机森林
es2 = RandomForestClassifier(n_estimators=100, max_depth = None) # 默认100个弱学习器
es2.fit(x_train, y_train)
y_pre2 = es2.predict(x_test)
print("随机森林的模型准确率:", es2.score(x_test, y_test))
# 随机森林 ------ 网格搜索
es3 = RandomForestClassifier()
param_grid = {
'n_estimators': [100, 25, 30, 40, 150],
'max_depth': [5, 10, 15, 20, 9, 30], # 树深度, 越深越复杂
}
es3_grid = GridSearchCV(es3, param_grid, cv=4)
es3_grid.fit(x_train, y_train)
y_pre3 = es3_grid.predict(x_test)
print("随机森林(网格搜索)的模型准确率:", es3_grid.score(x_test, y_test))
print("最佳参数为:", es3_grid.best_params_)超参数设置


三、Adaboost算法
Adaptive Boosting(自适应提升)基于 Boosting思想 实现的一种集成学习算法,核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。
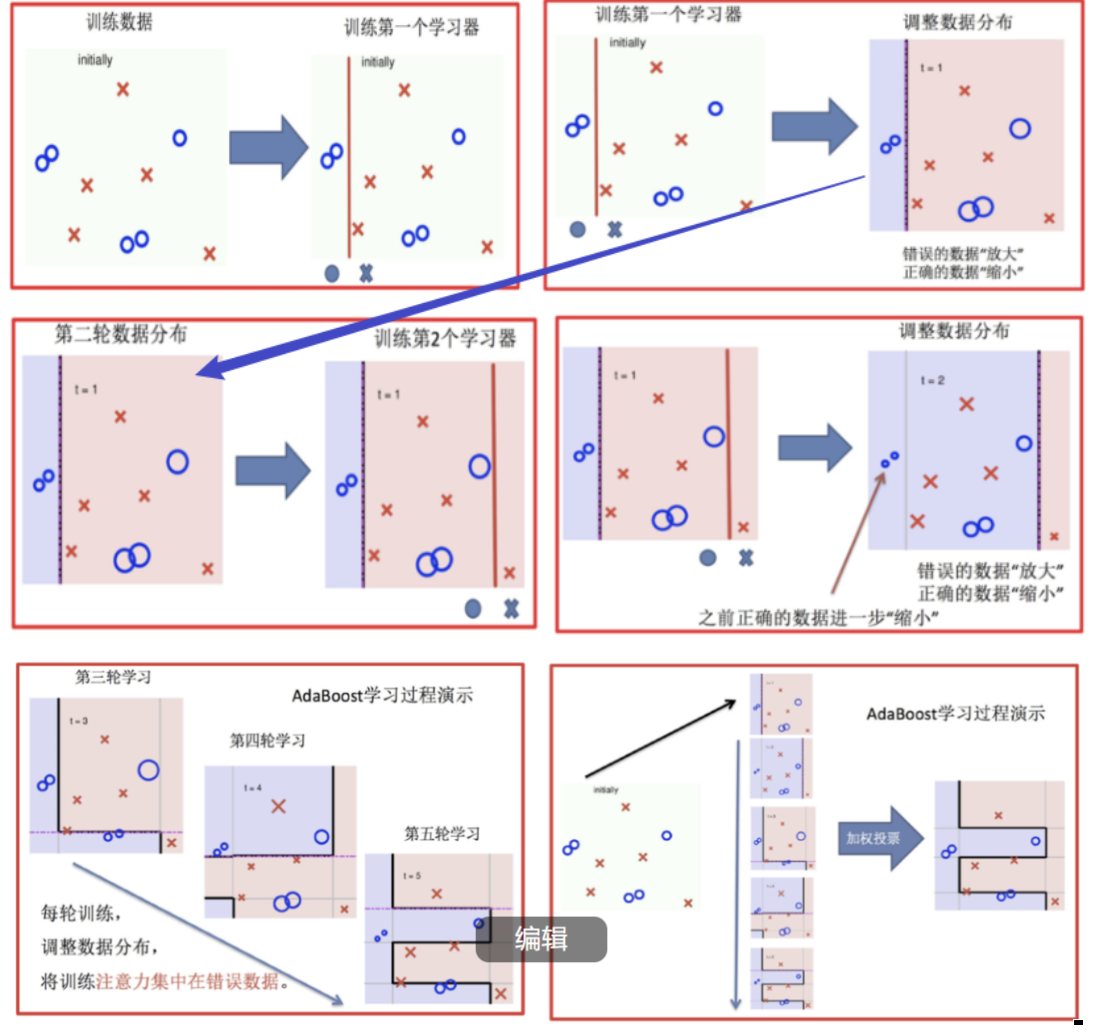
AdaBoost 的核心在于顺序地训练一系列弱分类器 (如深度很浅的决策树,又称"决策树桩"),并根据每一轮的分类结果自适应地调整训练样本的权重 ,使得后续的弱分类器能更关注那些之前被错误分类的样本。最后,将所有弱分类器的预测结果进行加权投票 (分类问题)或加权平均(回归问题)得到最终输出,权重则取决于每个弱分类器自身的准确率。
1、优缺点

2、应用场景

3、构建过程
① AdaBoost 算法推导

② 构建流程(权重更新计算)
1、构建第1个弱分类器
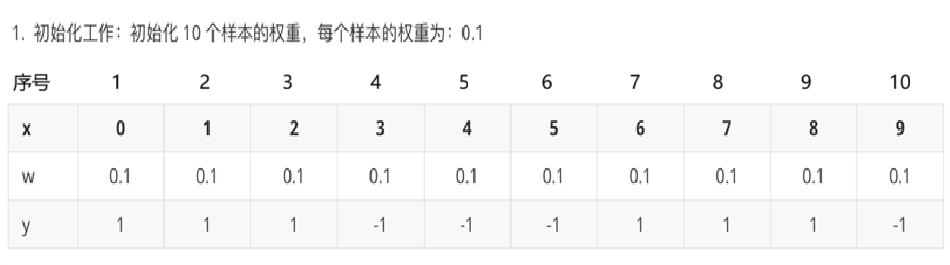
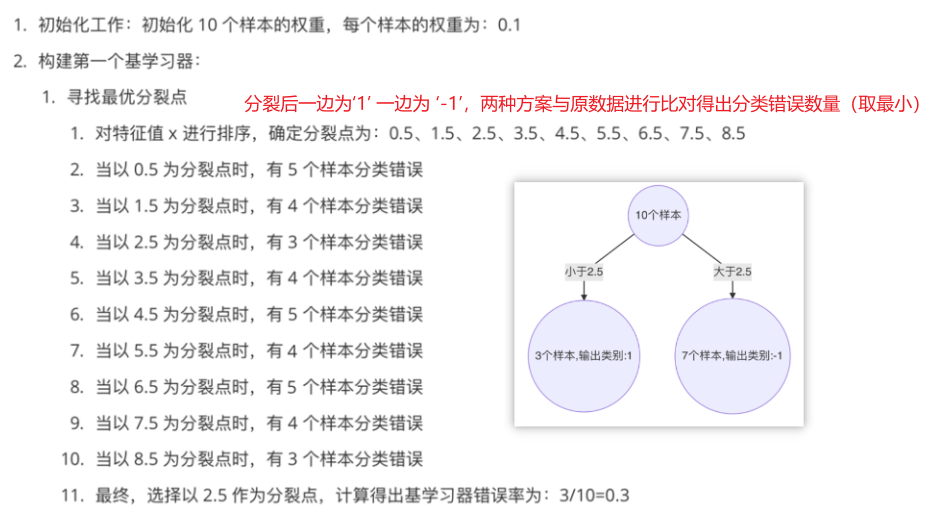
由此的为0.3,计算模型权重


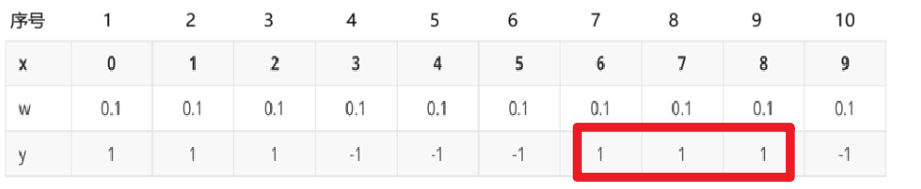
2、更新构建 第2个弱学习器的权重

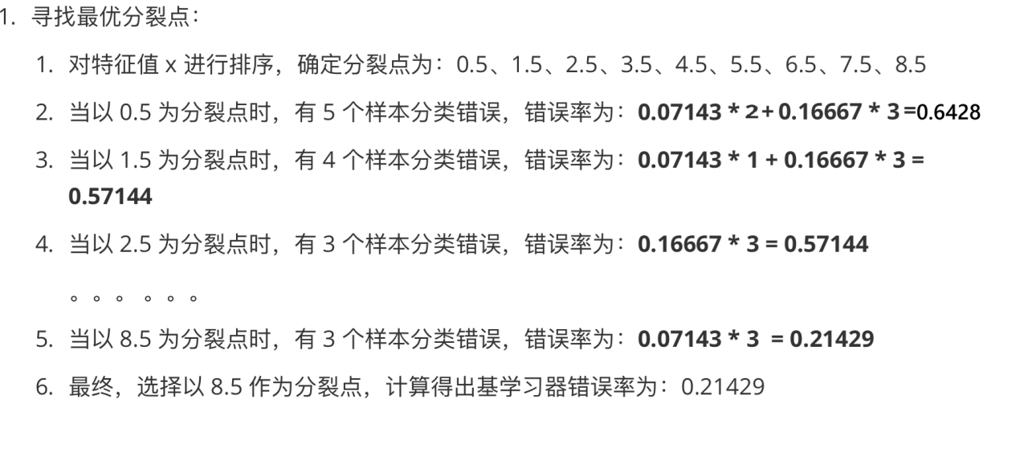
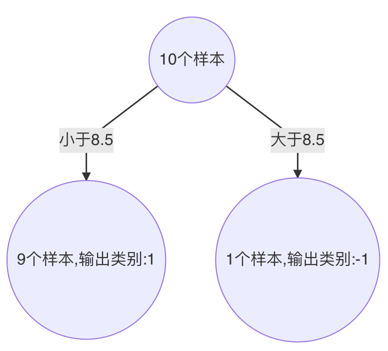


3、构建第三个弱学习器
以此类推,得到  ,得到最终的学习器为:
,得到最终的学习器为:
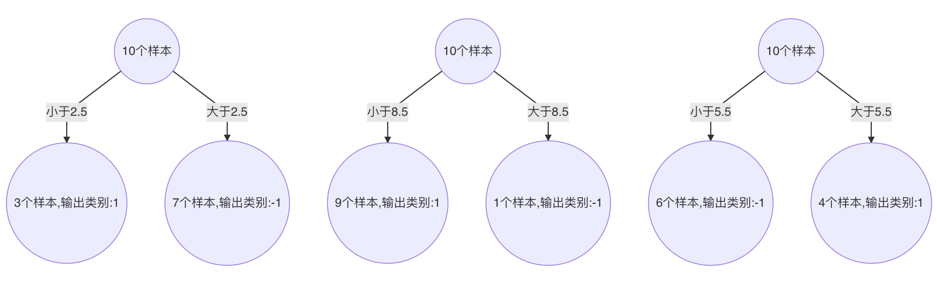
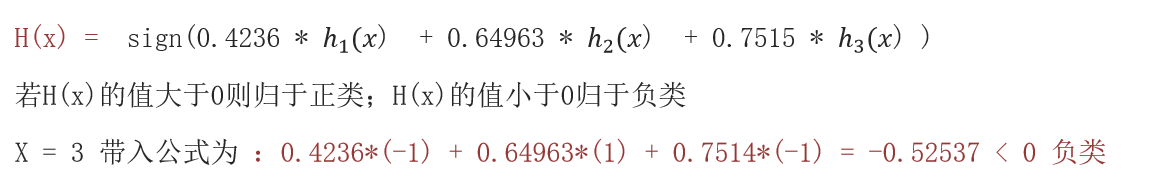
4、总结
- 初始化数据权重,来训练第1个弱学习器。找最小的错误率计算模型权重,再更新模数据权重。
- 根据更新的数据集权重,来训练第2个弱学习器,再找最小的错误率计算模型权重,再更新模数据权重。
- 依次重复第2步,训练n个弱学习器。组合起来进行预测。结果大于0为正类、结果小于0为负类
四、算法对比
