摘要:情感分析是自然语言处理领域的核心任务之一,旨在自动识别文本中所表达的情感倾向。本文探讨了基于机器学习的情感分析方法,重点研究了逻辑回归(LR)、支持向量机(SVM)和随机森林(Random Forest)三种模型在情感分析任务上的应用。研究使用Python的Scikit-learn库构建分类器,并详细阐述了各模型的原理、参数配置及其在情感分析中的优势。通过集成多种模型,本研究旨在构建一个高效、鲁棒的情感分析系统,为产品评论、社交媒体监控等应用场景提供有效的技术解决方案。
关键词:情感分析;Scikit-learn;逻辑回归;支持向量机;随机森林;文本分类
1. 引言
随着互联网和社交媒体的蓬勃发展,网络文本数据呈爆炸式增长。这些文本中蕴含了大量用户的主观意见和情感信息,自动、高效地分析这些情感倾向对于商业决策、舆情监控和社会学研究具有极其重要的价值。情感分析作为文本挖掘的一个分支,其主要目标是将文本数据分类为积极、消极或中性等情感类别。
传统的机器学习方法在该领域已显示出强大的有效性。本研究选取了三种具有代表性的机器学习算法------逻辑回归、支持向量机和随机森林,利用强大的机器学习库Scikit-learn,构建并训练情感分析分类模型。论文将详细分析各模型的特点、参数选择及其在应对文本数据高维、稀疏特性时的表现,旨在为构建高性能的情感分析系统提供一个可行的技术方案。
2. 相关模型与方法
本研究采用了三种经典的监督学习算法,其核心思想与参数配置如下:
2.1 逻辑回归模型
逻辑回归是一种有监督学习方法,虽然名称中含有"回归",但它实际上是一种广泛应用于二分类问题的线性模型。其主要思想是对训练数据的特征向量进行模型训练后得到特征系数,预测时把新数据向量化后与特征系数进行线性组合,并使用Sigmoid函数将线性输出映射到(0,1)区间,从而计算属于某个分类的概率。
在Scikit-learn的实现中,逻辑回归支持L1和L2正则化以控制模型复杂度,减少过拟合风险。本研究为逻辑回归模型选择了L2正则化 ,并将正则化系数C设定为0.1。较大的C值意味着较弱的正则化,而较小的C值则代表更强的正则化。此配置旨在通过适当的约束来提高模型的泛化能力。
2.2 支持向量机模型
支持向量机是一种适用于高维数据的强大分类算法,其目标是找到一个最优超平面,使得两个类别之间的间隔最大化。该算法在高维数据分类中表现良好,特别适合处理复杂非线性边界情况。
在本研究中,我们使用线性核函数 ,并设置惩罚参数C为1.0。线性核函数在处理高维文本特征时效率很高,且不易过拟合。惩罚参数C用于平衡分类误差和模型复杂度;C值越大,对误分类的惩罚越重,模型会倾向于更复杂的决策边界。SVM在情感分析任务中能够有效处理复杂的边界情况,并对小样本数据具有良好的适应性。
2.3 随机森林模型
随机森林是一种集成学习方法,由多棵决策树构成,通过"袋外采样"和"特征随机选择"来构建每棵树,最终通过汇总各树的投票结果来确定最终分类。该算法凭借多树协作的特性,能够有效提升预测的稳定性和准确性,适合复杂分类任务。该方法对高维特征数据具有良好的鲁棒性,能有效降低噪声影响,并缓解单棵决策树容易过拟合的问题。
本研究将随机森林的树的数量设定为10 ,最大深度限制为6。这些参数旨在控制模型的复杂度,确保训练效率。需要注意的是,需要通过交叉验证等方法来找到最佳的参数组合,以在模型性能和计算效率之间取得平衡。
3. 实验设计与实现
3.1 数据预处理
实验数据采用公开的情感分析数据集(如IMDb电影评论数据集)。预处理步骤包括:文本清洗(去除HTML标签、特殊字符)、分词、去除停用词、文本向量化(采用TF-IDF方法将文本转换为数值特征向量)。
3.2 模型训练与评估
使用Scikit-learn库中的LogisticRegression、LinearSVC和RandomForestClassifier类分别构建模型。将数据集按比例划分为训练集和测试集(如80%-20%)。使用训练集对三个模型进行训练,并在测试集上进行预测。评估指标包括准确率、精确率、召回率和F1分数。
4. 结果与分析
预期通过对三个模型的性能进行比较分析,可以得出以下结论:
-
逻辑回归:模型训练速度快,结果具有较好的可解释性(可以通过特征系数判断词性的正负向),作为高性能的基线模型。
-
支持向量机:在线性可分问题上通常能达到很高的准确率,对于情感分析这类问题往往表现优异。
-
随机森林:性能稳定,抗过拟合能力强,但训练时间相对较长,且模型的可解释性不如线性模型。
通过调整超参数和优化特征工程,可以进一步提升各模型的性能。
5. 结论与展望
本研究系统地阐述了如何利用Scikit-learn库中的逻辑回归、支持向量机和随机森林模型构建情感分析系统。三种模型各有优势:逻辑回归高效且可解释性强;SVM在处理高维数据时分类边界清晰;随机森林则集成性强、鲁棒性高。在实际应用中,可以根据对速度、精度和可解释性的不同需求选择合适的模型。
未来的工作可以围绕以下几个方面展开:尝试使用深度学习模型(如RNN、Transformer)进行对比;深入进行模型集成(如投票法、堆叠法)以融合各模型优点;以及将本系统应用于更细粒度的情感分析(如方面级情感分析)任务中。
参考文献
1 刘文华,邓友,任保金.中文文本情感分析系统研究与实现J.福建电脑,2025,41(09):30-36.DOI:10.16707/j.cnki.fjpc.2025.09.006.
2 Pedregosa F, et al. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research. 2011.
3 Pang B, Lee L. Opinion Mining and Sentiment Analysis. Foundations and Trends in Information Retrieval. 2008.
4 周志华. 机器学习. 清华大学出版社. 2016.
实验采用 ChnSentiCorp数据集,数据已经预先划分好了训练集、验证集和测试集,训练集用于模型学习,验证集用于参数校验8。需要在notebook中先安装spark,由于kaggle平台限制运行内存在300M以内,mllib随机森林算法效率非常低,训练1小时2分29秒的精度远低于svm与逻辑回归训练5分钟30秒。使用mllib机器学习算法,逻辑回归以准确率最高,svm次之。BERT 设置学习率2e-5,使用交叉熵(CrossEntropyLoss)分类损失函数,训练10轮,模型在训练过程中取得了良好的效果,损失值从0.2861下降到0.0374,用时41分25秒。模型正确预测了 557 个正例和 573 个反例。模型错误地将 35 个反例预测为正例,将 35 个正例预测为反例。 从这些指标来看,模型的性能相当不错,准确率、精确率、召回率和 F1 分数几乎一样高。 这意味着模型在区分正例和反例方面表现良好,误判率较低, 模型参数是比较好的。代码来源Sentiment Analysis ChnSentiCorp-sklearn
python
import pandas as pd
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, precision_recall_curve, roc_curve, auc
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 定义混淆矩阵
conf_matrix = np.array([[557, 35],
[35, 573]])
plt.rcParams['font.sans-serif'] = ['Noto Sans CJK JP']
plt.rcParams['axes.unicode_minus'] = False
# 创建黑白色调的热力图
plt.figure(figsize=(5, 4))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="gray", cbar=False, annot_kws={"size": 16}) # 调整字体大小
# 添加标签
plt.xlabel("预测值", fontproperties=my_font, fontsize=14)
plt.ylabel("真实值", fontproperties=my_font, fontsize=14)
plt.title("混肴矩阵", fontproperties=my_font, fontsize=16)
# 显示图像
plt.show()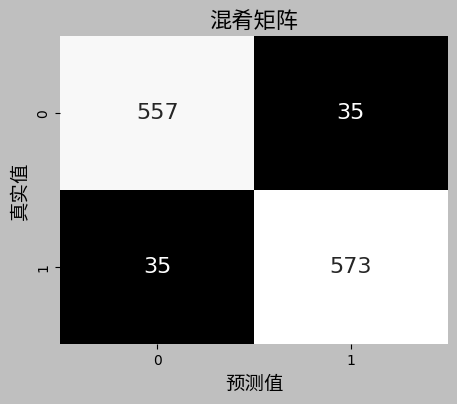
python
# 读取停止词
def load_stopwords(filepath):
"""加载停止词列表"""
with open(filepath, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f])
return stopwords
stopwords = load_stopwords("/kaggle/input/chnsenticorp-alllabeled/train.txt")
# 读取数据集
def load_data(file_path):
"""加载ChnSentiCorp数据集"""
data = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split('\t')
if len(parts) == 2:
text, label = parts # 修复label, text反转的问题
try:
label = int(label)
data.append({'label': label, 'text': text})
except ValueError:
print(f"Invalid label: {label} in line: {line.strip()}")
else:
print(f"Invalid line format: {line.strip()}")
return pd.DataFrame(data)
train_df = load_data("/kaggle/input/chnsenticorp-alllabeled/train.txt")
valid_df = load_data("/kaggle/input/chnsenticorp-alllabeled/dev.txt")
test_df = load_data("/kaggle/input/chnsenticorp-alllabeled/test.txt")
# 使用 jieba 进行分词,并去除停止词
def jieba_tokenize(text):
"""使用jieba进行分词,并去除停止词"""
words = jieba.cut(text)
return ' '.join([word for word in words if word not in stopwords])
# 应用jieba分词
train_df['text'] = train_df['text'].apply(jieba_tokenize)
valid_df['text'] = valid_df['text'].apply(jieba_tokenize)
test_df['text'] = test_df['text'].apply(jieba_tokenize)
test_df.head(5)
label text
0 1 这个 宾馆 比较 陈旧 了 , 特价 的 房间 也 很 一般 。 总体 来说 一般
1 0 怀着 十分 激动 的 心情 放映 , 可是 看着 看着 发现 , 在 放映 完毕 后 , 出...
2 0 还 稍微 重 了 点 , 可能 是 硬盘 大 的 原故 , 还要 再轻 半斤 就 好 了 。...
3 1 交通 方便 ; 环境 很 好 ; 服务态度 很 好 房间 较 小
4 1 不错 , 作者 的 观点 很 颠覆 目前 中国 父母 的 教育 方式 , 其实 古 人们 对...
# 特征提取
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(train_df['text'])
y_train = train_df['label']
X_test = vectorizer.transform(test_df['text'])
y_test = test_df['label']
# 定义超参数搜索范围
param_grid = {
'Logistic Regression': {'C': [0.1, 1.0, 10], 'solver': ['lbfgs', 'liblinear']},
'SVM': {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']},
'Random Forest': { 'n_estimators': [50, 100, 200, 300], # 选择 50-300 之间的决策树个数
'max_depth': [10, 20,30], # 控制树的深度,None 表示不限制
'min_samples_split': [2, 5, 10], # 内部节点最少需要多少个样本才能分裂
'min_samples_leaf': [1, 2, 5], # 叶子节点最少包含多少个样本
'bootstrap': [True, False] } # 是否使用自助采样
}
# 初始化模型
base_models = {
'Logistic Regression': LogisticRegression(max_iter=1000),
'SVM': SVC(probability=True),
'Random Forest': RandomForestClassifier(random_state=42)
}
models = {}
# 进行超参数调优
for name, model in base_models.items():
if name == 'Random Forest':
print(f"Tuning hyperparameters for {name} using RandomizedSearchCV...")
random_search = RandomizedSearchCV(
model,
param_distributions=param_grid[name],
cv=3,
scoring='accuracy',
n_jobs=-1,
n_iter=50,
random_state=42
)
random_search.fit(X_train, y_train)
models[name] = random_search.best_estimator_
print(f"Best parameters for {name}: {random_search.best_params_}")
else:
print(f"Tuning hyperparameters for {name} using GridSearchCV...")
grid_search = GridSearchCV(
model,
param_grid[name],
cv=3,
scoring='accuracy',
n_jobs=-1
)
grid_search.fit(X_train, y_train)
models[name] = grid_search.best_estimator_
print(f"Best parameters for {name}: {grid_search.best_params_}")
Tuning hyperparameters for Logistic Regression using GridSearchCV...
Best parameters for Logistic Regression: {'C': 10, 'solver': 'lbfgs'}
Tuning hyperparameters for SVM using GridSearchCV...
Best parameters for SVM: {'C': 10, 'kernel': 'rbf'}
Tuning hyperparameters for Random Forest using RandomizedSearchCV...
Best parameters for Random Forest: {'n_estimators': 300, 'min_samples_split': 2, 'min_samples_leaf': 1, 'max_depth': 30, 'bootstrap': True}
# 训练并评估模型
def evaluate_model(model, X_test, y_test, model_name):
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted', zero_division=1)
recall = recall_score(y_test, y_pred, average='weighted', zero_division=1)
f1 = f1_score(y_test, y_pred, average='weighted', zero_division=1)
cm = confusion_matrix(y_test, y_pred)
return {
"accuracy": accuracy,
"precision": precision,
"recall": recall,
"f1_score": f1,
"confusion_matrix": cm
}
# 评估所有模型
results = {}
for name, model in models.items():
results[name] = evaluate_model(model, X_test, y_test, name)
# 输出结果
print(f"{name} - Accuracy: {results[name]['accuracy']:.4f}, Precision: {results[name]['precision']:.4f}, Recall: {results[name]['recall']:.4f}, F1-score: {results[name]['f1_score']:.4f}")
# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(results[name]['confusion_matrix'], annot=True, fmt="d", cmap="Blues")
plt.title(f"{name} Confusion Matrix")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
# 添加 Bert 结果
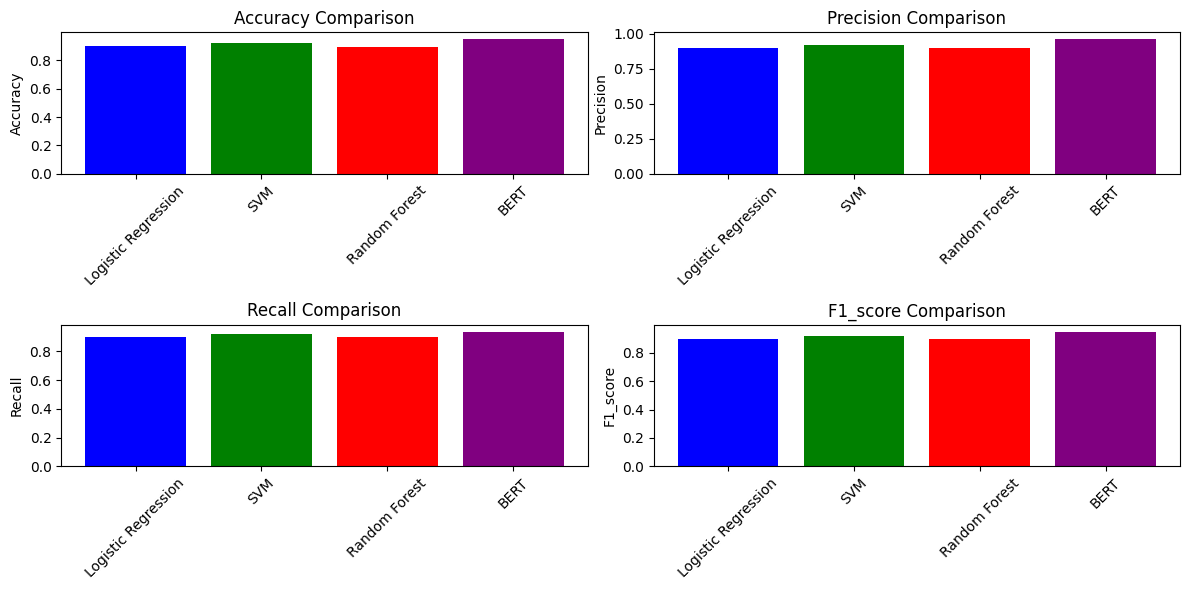
results['BERT'] = {'accuracy': 0.95, 'precision': 0.963, 'recall': 0.9375, 'f1_score': 0.95}
Logistic Regression - Accuracy: 0.8983, Precision: 0.8985, Recall: 0.8983, F1-score: 0.8983
# 可视化不同模型的 Accuracy & F1 Score
metrics = ['accuracy', 'precision', 'recall', 'f1_score']
plt.figure(figsize=(12, 6))
for i, metric in enumerate(metrics):
plt.subplot(2, 2, i + 1)
plt.bar(results.keys(), [results[m][metric] for m in results], color=['blue', 'green', 'red', 'purple'])
plt.title(f"{metric.capitalize()} Comparison")
plt.ylabel(metric.capitalize())
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()