目录
Advantages and disadvantages
从架构以及设计可以得出结论,Durid不支持ACID事务,基于时间戳列和维度列去查询,所以适合基于时间做分组和学列的查询操作。
Advantages优势:
实时数据摄取与查询
支持秒级数据摄取和近实时查询,适合对数据时效性要求高的场景。
高性能查询
采用列式存储、索引机制(如 bitmap、时间索引等)和多级缓存,查询速度非常快,尤其适合聚合类查询。
水平扩展性强
架构支持分布式部署,节点可按需扩展,适合处理 PB 级数据。
灵活的数据分片与分区策略
支持按时间、维度等进行分片,有助于提高查询效率。
内置 Rollup 和预聚合机制
可以在摄取阶段进行数据压缩和预聚合,减少存储和加快查询。
支持多种数据源
如 Kafka、HDFS、S3、MySQL、PostgreSQL 等,方便集成。
InAdvantages劣势:
不适合复杂事务处理
Druid 是为分析而设计,不支持 ACID 事务,不适合 OLTP(在线事务处理)场景。
数据更新困难 不支持实时更新:虽然支持流式插入,但不支持实时更新或删除,适合追加型数据而非频繁变更的数据。
扩展和运维复杂
架构组件较多(如 MiddleManager、Historical、Broker 等),部署和运维复杂,需要手动调优,且依赖本地 SSD,存储成本较高。
存储成本可能较高
尽管支持压缩,但在高并发和高可用配置下,资源消耗仍然较大。
对 JOIN 支持有限
Druid 原生不支持复杂的 JOIN 操作,适合以 denormalized(扁平化)数据为主。
查询引擎性能瓶颈基于 Java,缺乏 SIMD 优化,相比 ClickHouse、StarRocks 等新一代 OLAP 引擎性能略逊。
scenario
适合的场景
- 实时用户行为分析:如点击流、A/B 测试、用户活跃度分析。
- 数字广告分析:广告曝光、点击率、转化率等实时指标。
- 网络流量监控:网络流日志分析,检测异常流量。
- 应用性能监控:API 延迟、系统指标实时监控。
- IoT 数据分析:设备指标、传感器数据的实时聚合和可视化。
- 交互式 BI 应用:需要高并发、低延迟的用户自助分析场景。
不适合的场景
- 需要复杂事务或 ACID 保证的场景:如金融核心系统。
- 频繁更新或删除数据的场景:Druid 更适合追加型数据。
- 需要复杂多表 JOIN 的分析:如高度关系型的数据模型。
- 低实时性要求的批处理分析:如传统离线数仓任务,Hive/Spark 更合适。
- 对成本敏感且数据量极大:Druid 对 SSD 和集群资源要求高,运维成本较高。
Architecture
Druid 具有分布式架构,旨在云友好且易于作。您可以独立配置和扩展服务,以获得集群作的最大灵活性。此设计包括增强的容错能力:一个组件的中断不会立即影响其他组件。
下图显示了构成 Druid 架构的服务、它们在服务器之间的典型排列,以及查询和数据如何流经此架构。
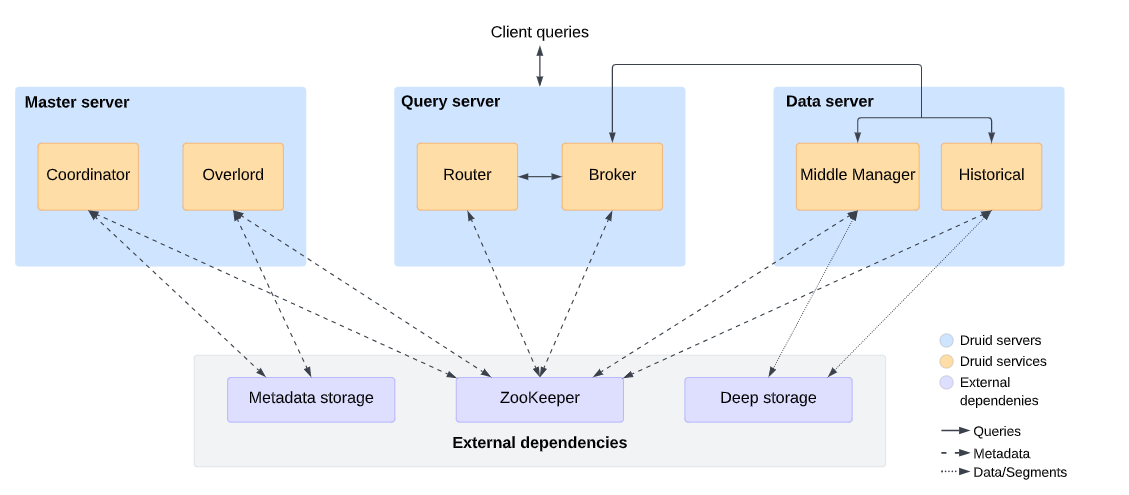
Durid Service
Druid has several types of services:
-
Coordinator 管理数据在集群中的可用性以及部分均匀.
-
Overlord 控制分配数据ingestion的workloads.
-
Broker 处理来自外部客户端的查询.
-
Router 路由请求致 Brokers, Coordinators, and Overlords.
-
Historical 存储可查询的数据.
-
Middle Manager and Peon ingest data.
-
Indexer 作为 Middle Manager + Peon task 执行系统的可选项.
可以在service中看到这些服务。
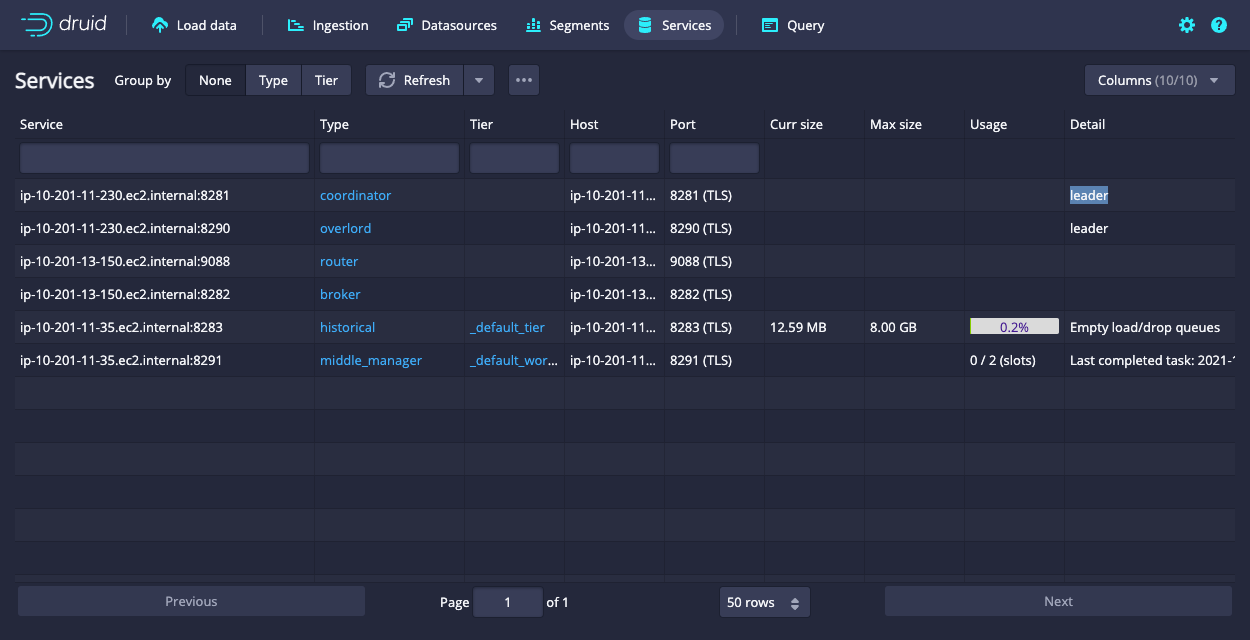
Durid Server
Master Server
A Master server manages data ingestion and availability. It is responsible for starting new ingestion jobs and coordinating availability of data on the Data server.Master servers divide operations between Coordinator and Overlordservices.
Query Server
A Query server provides the endpoints that users and client applications interact with, routing queries to Data servers or other Query servers (and optionally proxied Master server requests).Query servers divide operations between Broker and Routerservices.
DataServer
A Data server executes ingestion jobs and stores queryable data.
Data servers divide operations between Historical and Middle Manager services.
Index Service(optional)
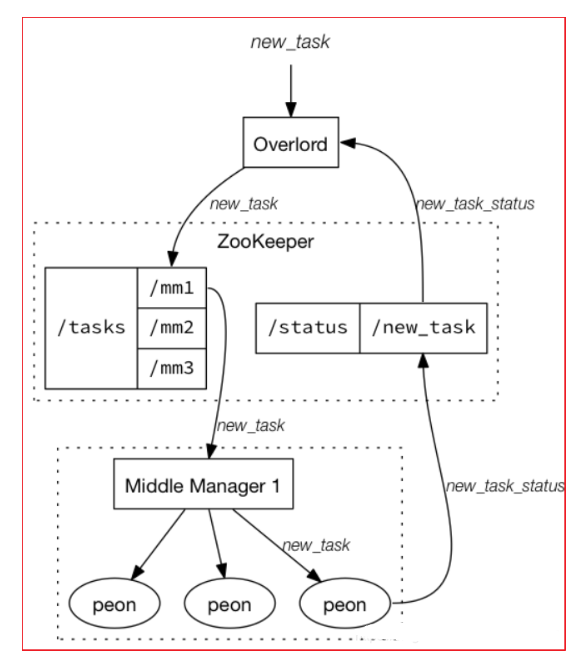
索引服务是数据摄入创建和销毁Segment的重要方式
Druid提供一组支持索引服务(Indexing Service)的组件,即Overlord和MiddleManager节点
索引服务采用的是主从架构,Overlord为主节点,MiddleManager是从节点
索引服务架构图如下图所示:
- 索引服务由三部分组件组成:
- Overlord组件
- 分配任务给MiddleManager
- MiddleManager组件
- 用于管理Peon的
- Peon(劳工)组件
- 用于执行任务
Durid 数据存储
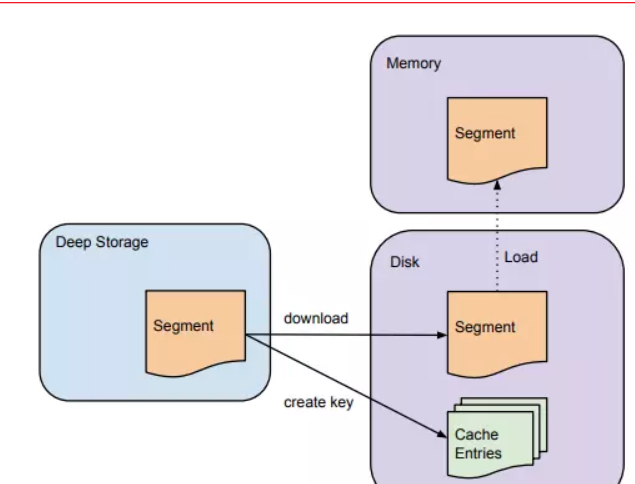
Historical节点负责管理历史Segment
Historical节点通过Zookeeper监听指定的路径来发现是否有新的Segment需要加载
Historical节点收到有新的Segment时候,就会检测本地cache和磁盘,查看是否有该Segment信息。如果没有Historical节点会从Zookeeper中拉取该Segment相关的信息,然后进行下载,Historical节点收到有新的Segment时候,就会检测本地cache和磁盘,查看是否有该Segment信息。 如果没有Historical节点会从Zookeeper中拉取该Segment相关的信息,然后进行下载。
- Druid中的数据存储在被称为DataSource中,DataSource类似RDMS中的table
- 每个DataSource按照时间划分,每个时间范围称为一个chunk((比如按天分区,则一个chunk为一天))
- 在chunk中数据由被分为一个或多个segment
- segment是数据实际存储结构,Datasource、Chunk只是一个逻辑概念
- 每个segment都是一个单独的文件,通常包含几百万行数据
- segment是按照时间组织成的chunk,所以在按照时间查询数据时,效率非常高
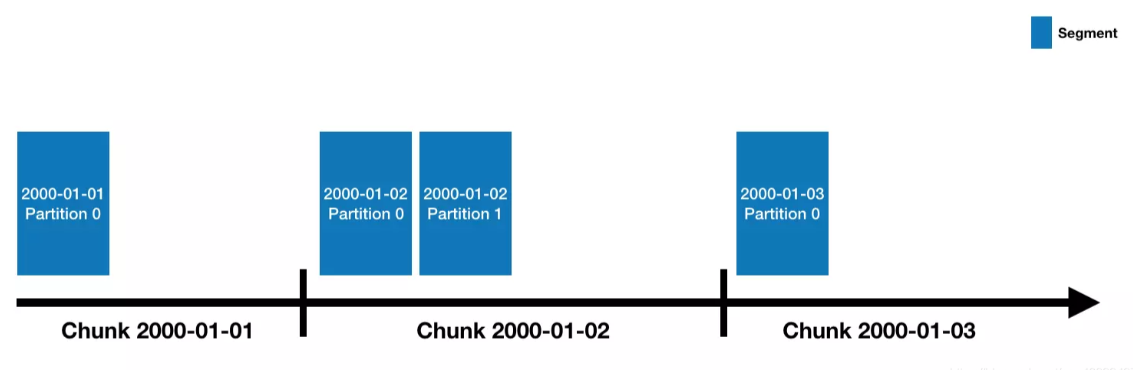
Data Partition
Druid处理的是事件数据,每条数据都会带有一个时间戳,可以使用时间进行分区
上图指定了分区粒度为为天,那么每天的数据都会被单独存储和查询
Segment
- Segment是数据存储、复制、均衡和计算的基本单元
- Segment具备不可变性,一个Segment一旦创建完成后(MiddleManager节点发布后)就无法被修改
- 只能通过生成一个新的Segment来代替旧版本的Segment
Segment内部存储结构
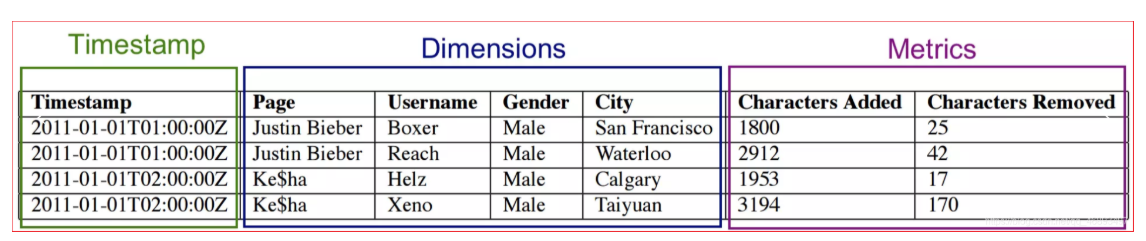
时间戳列和指标列
Druid采用LZ4压缩每列的整数或浮点数
收到查询请求后,会拉出所需的行数据(对于不需要的列不会拉出来),并且对其进行解压缩
维度列
维度列需要支持filter和group by
Druid使用了字典编码(Dictionary Encoding)和位图索引(Bitmap Index)来存储每个维度列
每个维度列需要三个数据结构
需要一个字典数据结构,将维度值映射成一个整数ID
使用上面的字典编码,将该列所有维度值放在一个列表中
对于列中不同的值,使用bitmap数据结构标识哪些行包含这些值。
Druid针对维度列之所以使用这三个数据结构,是因为:
使用字典将字符串映射成整数ID,可以紧凑的表示维度数据
使用Bitmap位图索引可以执行快速过滤操作
找到符合条件的行号,以减少读取的数据量
Bitmap可以快速执行AND和OR操作