摘要
好久未更新文章,最近生产环境遇到一个频繁FullGC问题,用这一篇文章记录下来。先剧透原因,总结一句话原因如下:
本文记录了一次因 Log4j2 配置、JVM 参数和应用依赖变更等多因素叠加导致的频繁 Full GC 线上故障。通过分析 GC 日志、内存 Dump 和源码,最终定位到是因引入 Servlet 依赖导致 Log4j2 线程缓存失效,进而引发大对象直接晋升老年代所致。本文详细记录了排查思路、根因分析及解决方案。
一、事情起因
某一天夜晚系统上线后,没过多久运维便找上门,系统存在Full GC告警,一分钟Full GC超过5次。(出现问题的系统使用Log4j2框架,对应版本2.31.8)
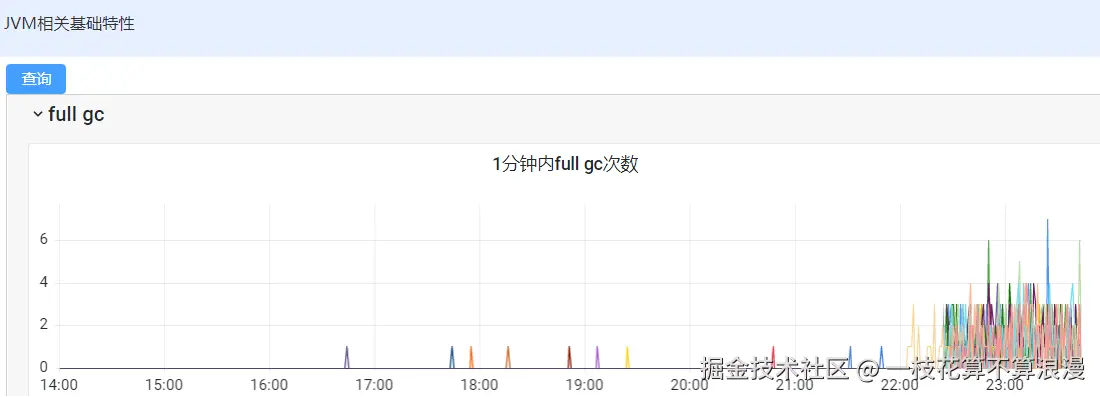
1、JVM监控看板
上线后Full GC频次立马上来了,可以确定Full GC和本次版本有关系。先回退版本,优先解决问题为主。同时找运维dump内存快照,方便后续分析问题。
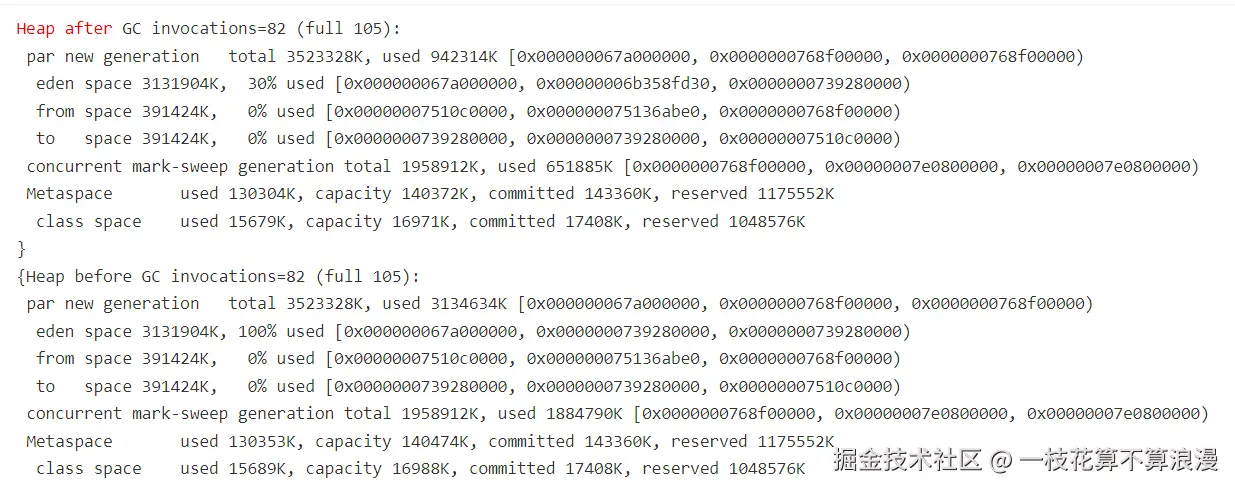
2、GC日志
GC日志显示很明显,通过GC日志可以粗略分析如下: Minor GC触发次数:82 Full GC触发次数:105次
- Minor GC频率高:新生代 GC 已触发 82 次,说明短期对象频繁创建。
- Full GC频率更高:Full GC 触发 105 次(> Minor GC次数),证明存在 内存分配严重失衡:
- 对象未能在新生代回收,被迫晋升到老年代
- 老年代快速填满(日志中GC前占用96.2%)
- 最终频繁触发Full GC(影响系统性能)。
交给AI分析下,以下表格比较直观:
| 内存区域 | GC前占用 | GC后占用 | 变化趋势 |
|---|---|---|---|
| 新生代 (Eden) | 100% (3.13GB已满) | 30% (约0.94GB) | ↓70% |
| 新生代 (Survivor区) | 0% (完全闲置) | 0% (持续闲置) | 失效状态 |
| 老年代 (CMS) | 96.2% (1.84GB/1.87GB) | 33.3% (0.65GB/1.87GB) | ↓63%,但残余仍过高 |
问题关键是,一次 Young GC 后老年代仍占用 0.65GB,说明有大量本应回收的对象常驻老年代,这是典型的内存泄漏或不当晋升的迹象。
二、问题排查
有了AI分析的加持,我们大致明白原因是系统中频繁创建大对象直接晋升到老年代 快速填满老年代进而触发Full GC。剩下的就是进行具体问题排查了。
问题排查的思路如下:
1、梳理本次系统上线内容
本次上线是将旧系统的dubbo依赖去除,然后引入公司内部xxx-rpc框架,本次并没有其他业务代码的修改。初步怀疑是公司内部xxx-rpc的问题,但是这个框架已经在其他项目都推广了,也没有反馈过此问题,所以通过代码改动回溯并没有定位到具体的问题。
2、内存快照Dump
出现问题之后就立马找运维dump了内存快照,这次再通过dump文件分析下问题:
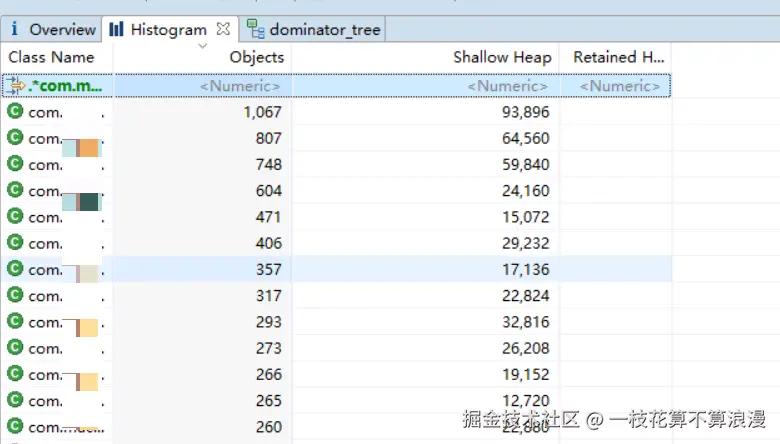
2.1 按照包名过滤
首先怀疑是我们系统代码导致的GC问题,按照系统包名进行过滤。按照Objects数量排序,这里查看数量级没有问题
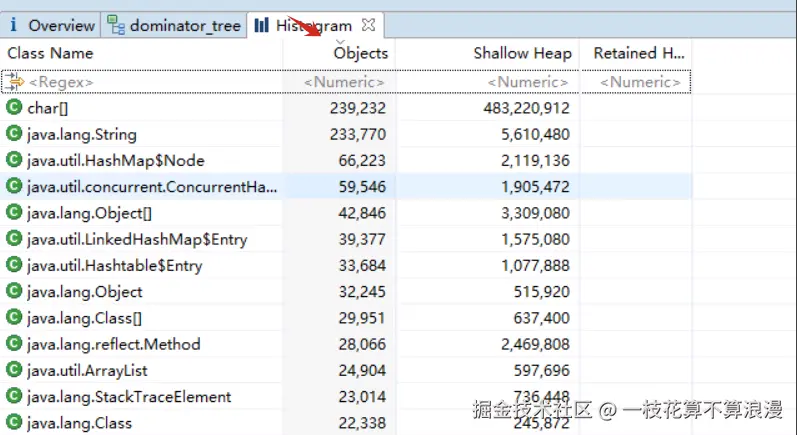
2.2 按照类数量排序
这里看到char数组和String数量最多,而且占用的内存也是最高的。这通常意味着问题与大量的字符串处理操作有关,例如日志、JSON 序列化/反序列化等 。看下char\[\]数组关联的引用:
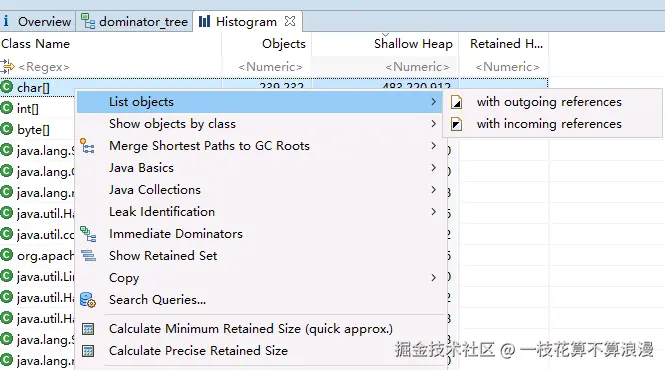
通过with incoming references查看引用列表:
看到这个图好像是发现问题了,Shallow Heap大小都是固定的值2MB+
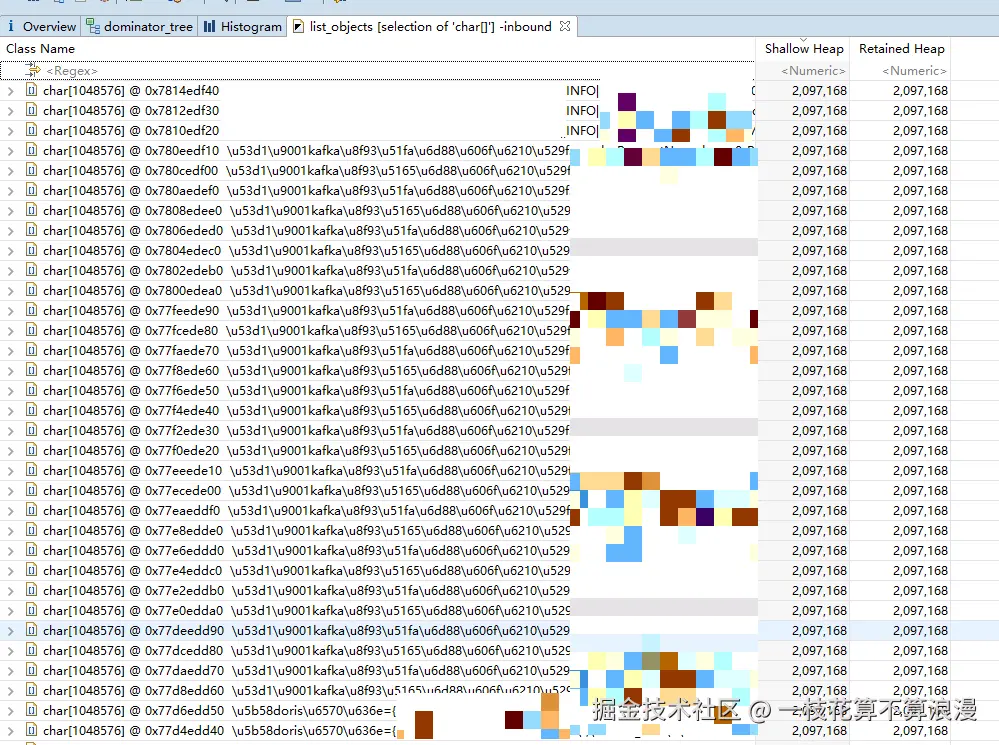
对象内容都是一些日志内容,而且查看日志内容也不大,为了达到预设的容量(1MB),会用一个默认值(空字符)来填充数组,这在内存快照中看到的就是大量\u0000。(StringBuilder 的机制)

这里可以想到可能是系统日志框架搞了鬼,每次打印日志时都生成一个2MB+的大对象,再看这个char的引用是一个StringBuilder。通过char数组的GC root也能够证明这一点。
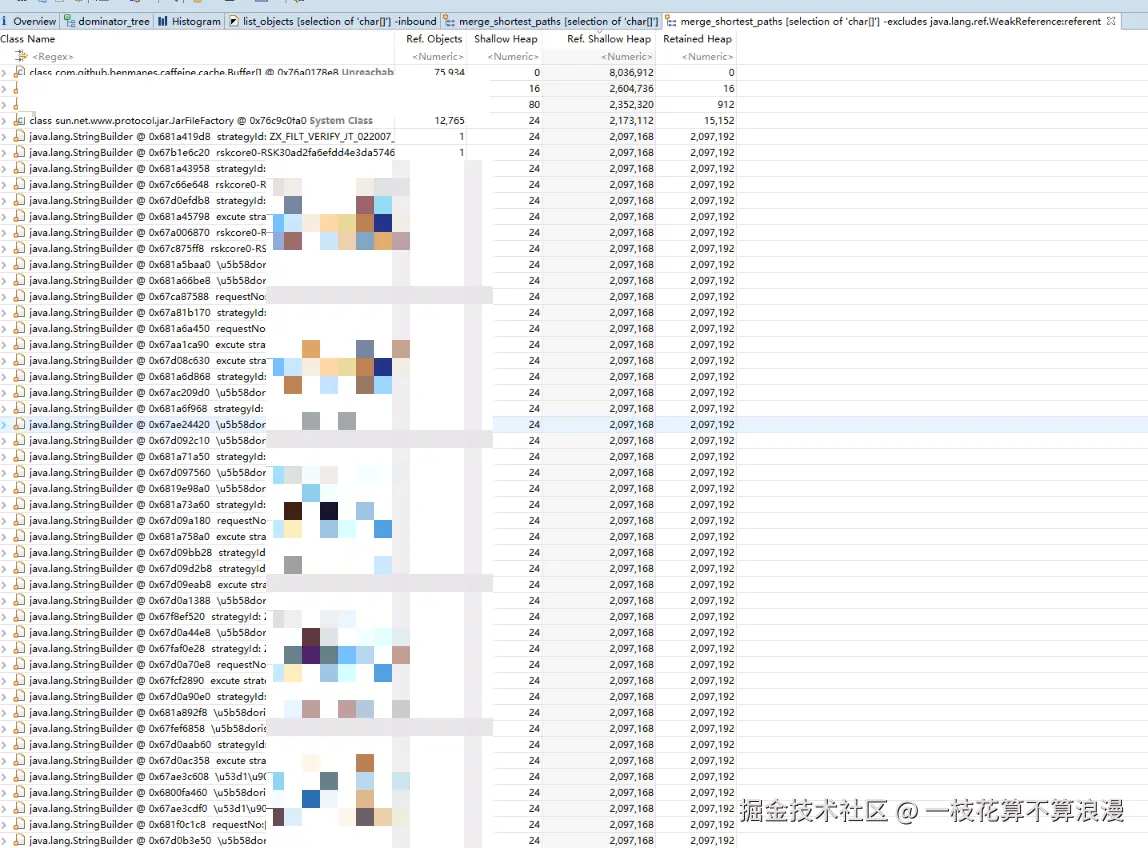
现在排查的大致方向明确了:
系统频繁Full GC的原因是使用的日志框架不停的创建StringBuilder(StringBuilder的底层就是用的char数组)导致。通过这个方向去代码中进一步排查。
3、查看系统JVM配置
系统JVM配置中有一个配置 -XX:PretenureSizeThreshold=2097152,含义是如果创建的对象大于2MB后就会直接进入老年代。结合上面的问题,会有大量的对象频繁分配到老年代,导致Full GC频发。

另外询问AI这个参数配置是否合理,得到回复:
- 重新评估 JVM 参数:慎重考虑 -XX:PretenureSizeThreshold=2097152 这个参数的必要性。这个参数非常激进,它改变了对象的正常晋升规则。对于绝大多数应用,尤其是大量存在临时大对象(如你的日志场景)的应用,移除这个参数让对象优先在新生代分配,可能是更好的选择。让 JVM 自己管理对象晋升通常更合理。
三、代码追踪
通过MAT工具已经定位到大致的方向了,剩下的就是要排查代码中对于Log的使用,查看是哪里的配置导致了问题。
1、Log框架
搜索系统中使用的log框架

系统通过lombok的注解@Log4j2来进行日志打印,那么就开始看下log4j2底层代码,通过代码进行直接搜索: 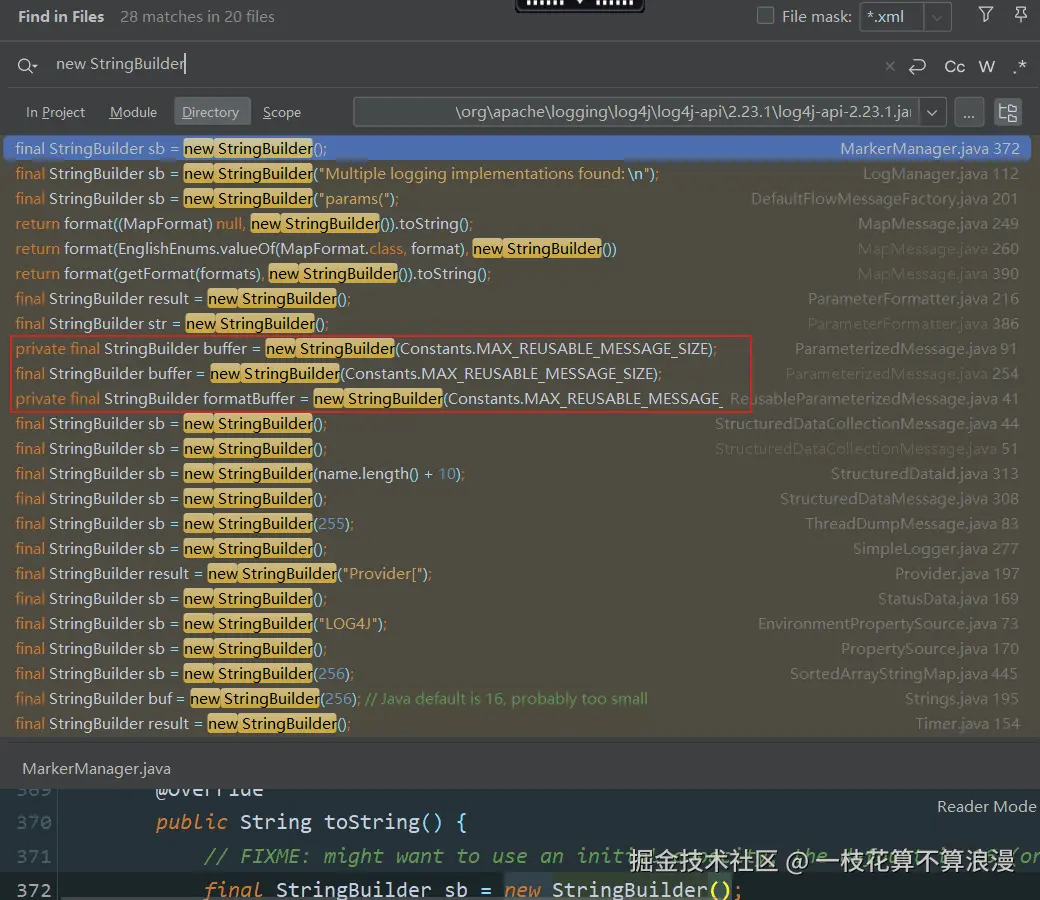
另外log4j-core 包下也做了类似搜索,只有这里有更多线索值得追溯,继续往后跟踪。
2、本地Debug溯源
直接可以本地启动Debug下,遇到有log.info即可进入到创建StringBuilder的地方:
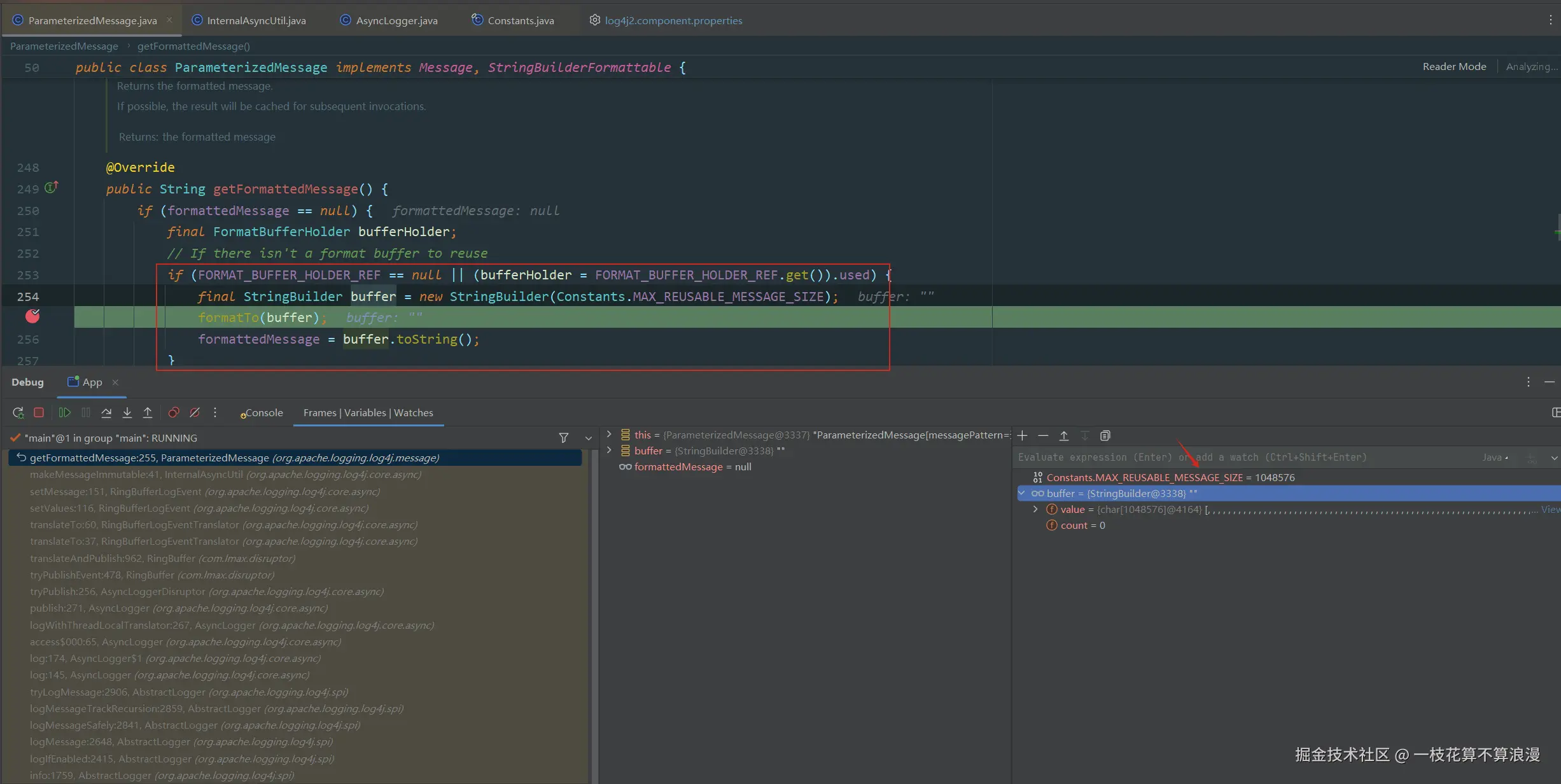
这里是每次打印log都会进入,然后执行new StringBuilder(MAX_REUSABLE_MESSAGE_SIZE),这里看到buffer都是用的空字符串进行占位,一个**char1048576**数组占用的空间计算如下:
1.数组长度:1048576=2^20=1MB(元素个数) 2.每个char占用:2字节(Java中char是16位) 3.数据分占用:1048576×2=2097152字节=2MB
如果再加上对象头的开销,实际占用是超过2097152的,再参考MAT中对象占用大小2097168,这似乎都对应上了。接着继续跟这个判断逻辑:
java
final ThreadLocal<FormatBufferHolder> FORMAT_BUFFER_HOLDER_REF
Constants.ENABLE_THREADLOCALS ? ThreadLocal.withInitial(FormatBufferHolder:new) : null;
public static final boolean ENABLE_THREADLOCALS
!IS_WEB_APP &PropertiesUtil.getProperties().getBooleanProperty("log4j2.enable.threadlocals", true);
public static final boolean IS_WEB_APP = Propertiesutil.getproperties().getBooleanProperty(
"1og4j2.is.webapp", iscLassAvailable("javax.servlet.Servlet") || isCLassAvailable("jakarta.servlet.Servlet"));可以看到这里log4j2.enable.threadlocals=false或者被判定isWebApp的话 都会使得FORMAT_BUFFER_HOLDER_REF为null,最终每次都会new StringBuilder()创建大对象:
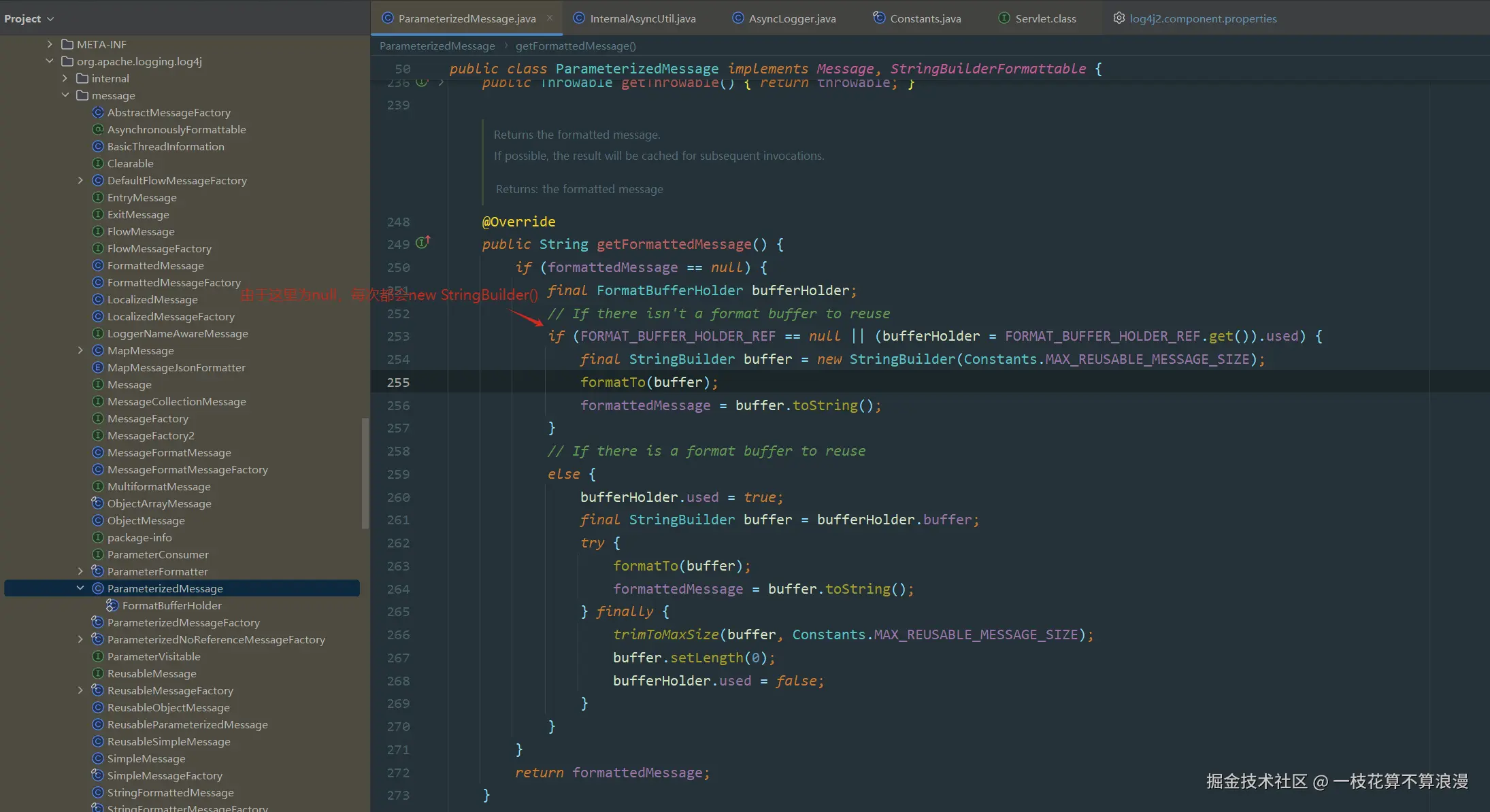
3、代码配置
继续跟着上面问题跟踪,查看系统配置。
1、系统MAX_REUSABLE_MESSAGE_SIZE为多少?
2、log4j2.enable.threadlocals配置为false或者系统被识别为webApp?
继续通过代码搜索:
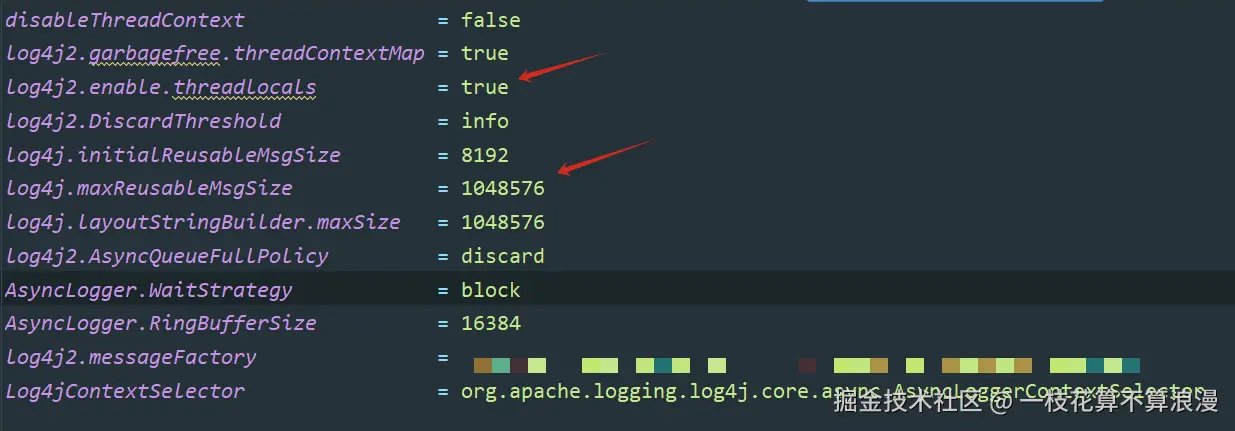
1、系统配置的MAX_REUSABLE_MESSAGE_SIZE为10048576(1MB) 2、log4j2.enable.threadlocals已经配置了true 3、系统被误识别为webApp应用,由于引入公司其他段对的包间接引入了tomcat包,引入了Servlet类,导致识别为webApp应用
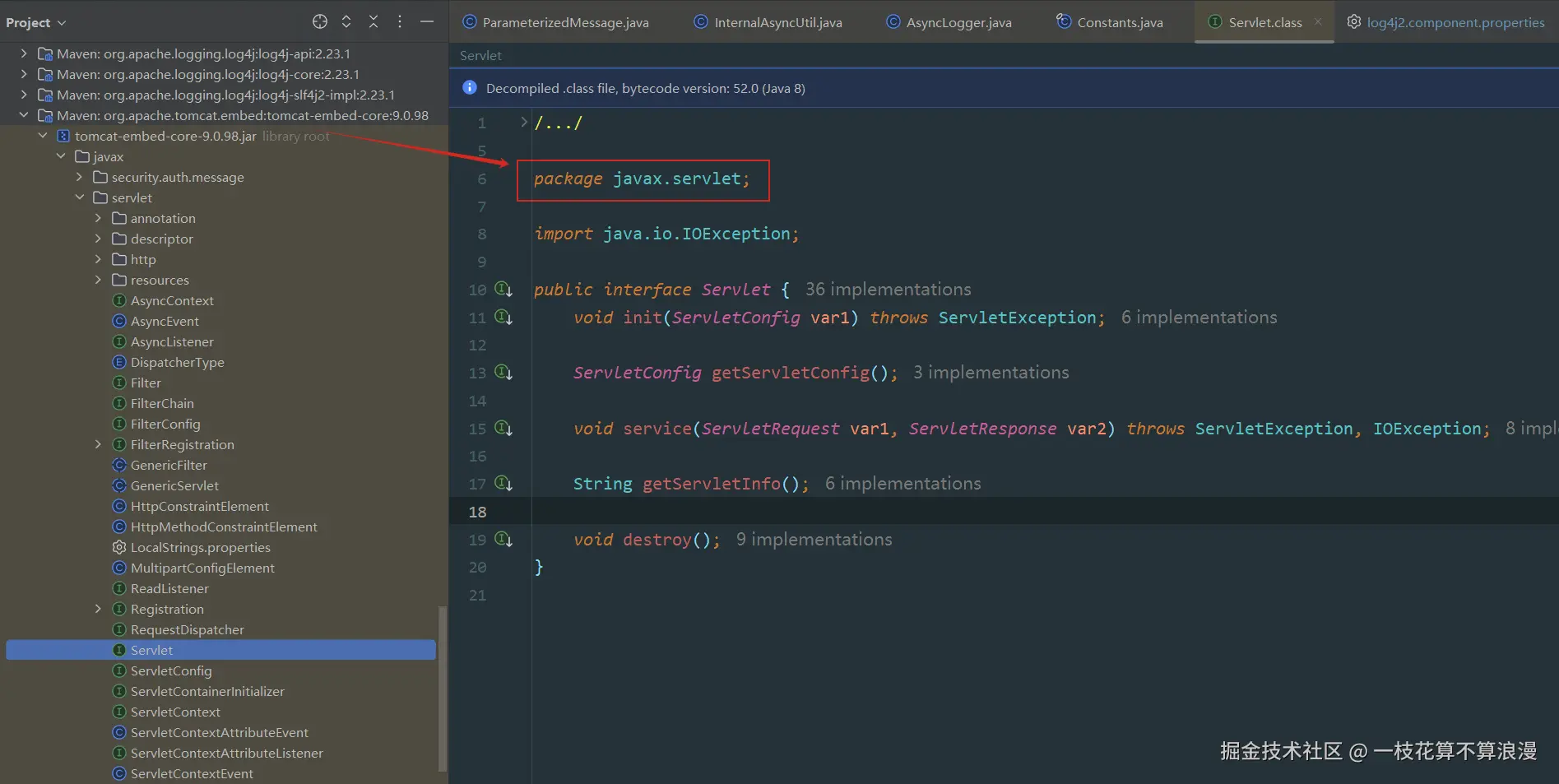

系统中引入了**==javax.servlet.Servlet==**类,所以被误识别为webApp应用,进而导致每次日志打印都会创建一个2MB的StringBuilder() 对象。
4、原理解释
这个问题的核心在于解释下面的代码的含义,以及log4j2.maxReusableMsgSize、log4j2.enable.threadlocals等配置的意义:
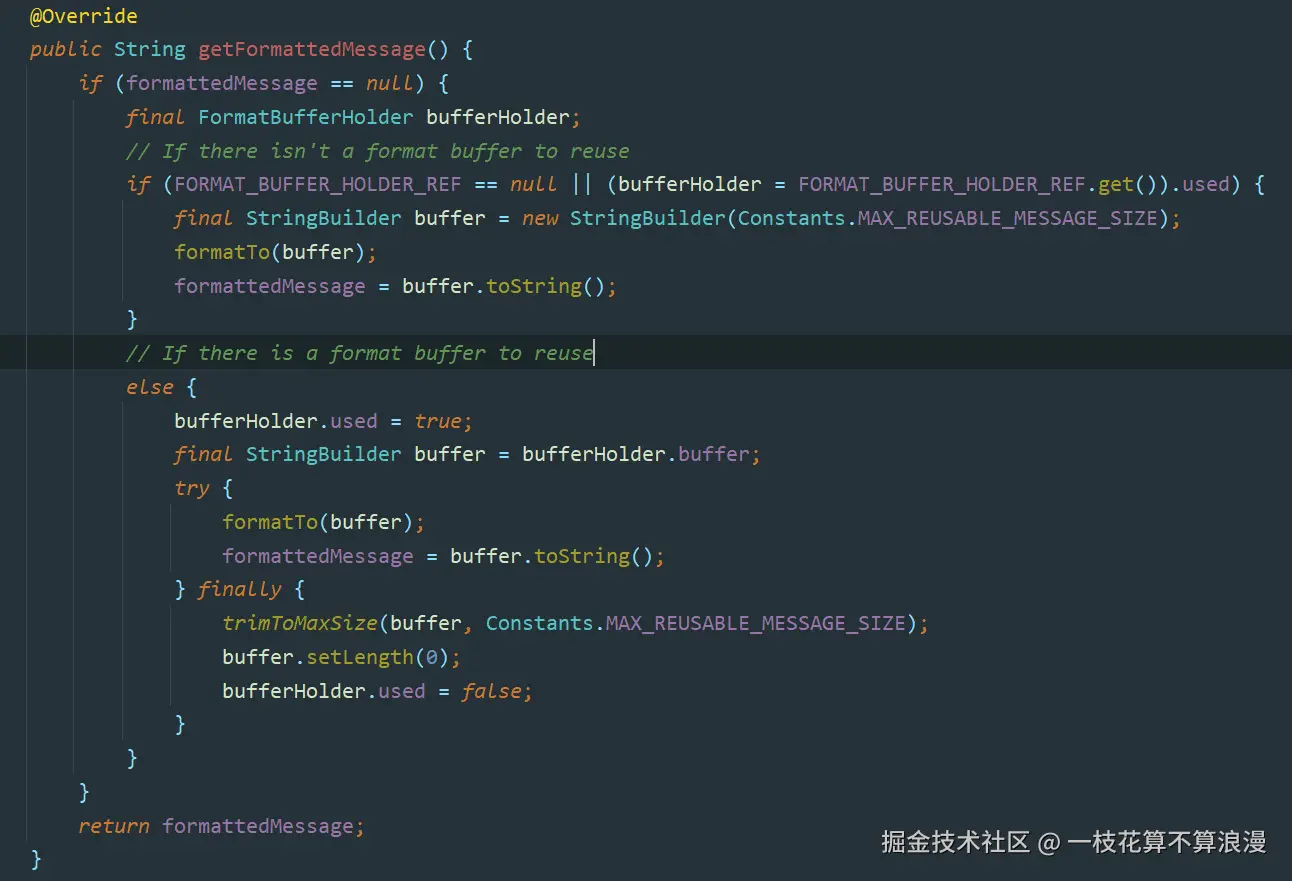
1、log4j2.enable.threadlocals=true时,在线程执行的周期内打印的日志都可以复用创建的StringBuilder缓冲区,它会随着线程的创建而创建,并在线程结束时被垃圾回收。这个缓冲区的核心目的是复用:通过线程本地变量(ThreadLocal)为每个线程分配一个固定的缓冲区,在每次日志格式化操作中重复使用它,从而避免频繁创建和销毁 StringBuilder 对象,避免了短期对象的创建,降低新生代的 GC 频率,减少垃圾回收(GC)压力。
2、log4j2.maxReusableMsgSize顾名思义这个配置即为缓冲区大小,定义了每个线程本地缓存中 StringBuilder 缓冲区的初始容量。
5、解决方式
解决方式很简单,修改log4j2配置即可。修改isWebApp为false,强制覆盖 isWebApp判断,并且减小缓存maxResuableMsggSize大小。

四、事后复盘
上面已经找到了问题的所在,但是还是有些问题没有得到明确的解释:
1、系统之前都跑的好好的,为何本次上线才导致这个问题出现?其他团队是否也遇到了类似问题?
这个问题几乎是身边同事、领导都在问的,问题的开始我也有同样的疑惑。(该问题仅限定于同样使用Log4j2框架的系统)
这里直接看我们系统正常系统和我们系统的一些差异对比,这里会更加直观,下面也有详细配置的差异:
| 配置项 | 正常系统(其他团队系统) | 故障系统(我们团队系统) | 后果 |
|---|---|---|---|
log4j2.maxReusableMsgSize |
默认 (0.5KB) | 显式配置为 1MB | 创建的对象大小不同 |
-XX:PretenureSizeThreshold |
默认 (0) | 显式配置为 2MB | 大对象分配策略不同 |
javax.servlet.Servlet 依赖 |
有(引入公司内部xxx-rpc框架导致) | 有(引入公司内部xxx-rpc框架导致) | 导致线程缓存失效 |
| 最终效果 | 小对象在新生代回收 | 大对象直击老年代 | 频繁 Full GC |
接着看下我们系统的一些具体配置:
1.1、log4j2配置不当
本次接入了公司内部xxx-rpc框架间接引入了Servlet类,导致log4j2框架将系统识别为webApp,导致log4j2.enable.threadlocals=true失效,其他系统也同样有此问题,但是其他系统并没有显示去配置log4j2一些属性,都是使用默认配置
maxReusableMsgSize默认值为0.5KB,其他系统即使每次都new StringBuilder()出来 也不会进入老年代中,不会产生Full GC问题

1.2、JVM参数配置不当
我们系统配置的-XX:PretenureSizeThreshold=2097152,也就是超过2MB的大对象直接分配到老年代。而其他系统并未配置此JVM参数,-XX:PretenureSizeThreshold 这个参数的默认值是 0。默认情况下所有对象都会首先尝试在新生代(Young Generation)进行分配,而不会仅仅因为对象大就直接进入老年代。
1.3、log4j2 2.23.1缓存顶格分配
该问题同1.1,默认缓存大小为0.5k,即使顶格分配也不会出现问题。上面查看log4j2 2.23.1版本的源码,每次都按照maxResuableMsgSize配置顶格创建对应的StringBuilder缓存。这个改动是从2.17.0版本之后修改的,我们再看下2.17.0版本源码的处理:
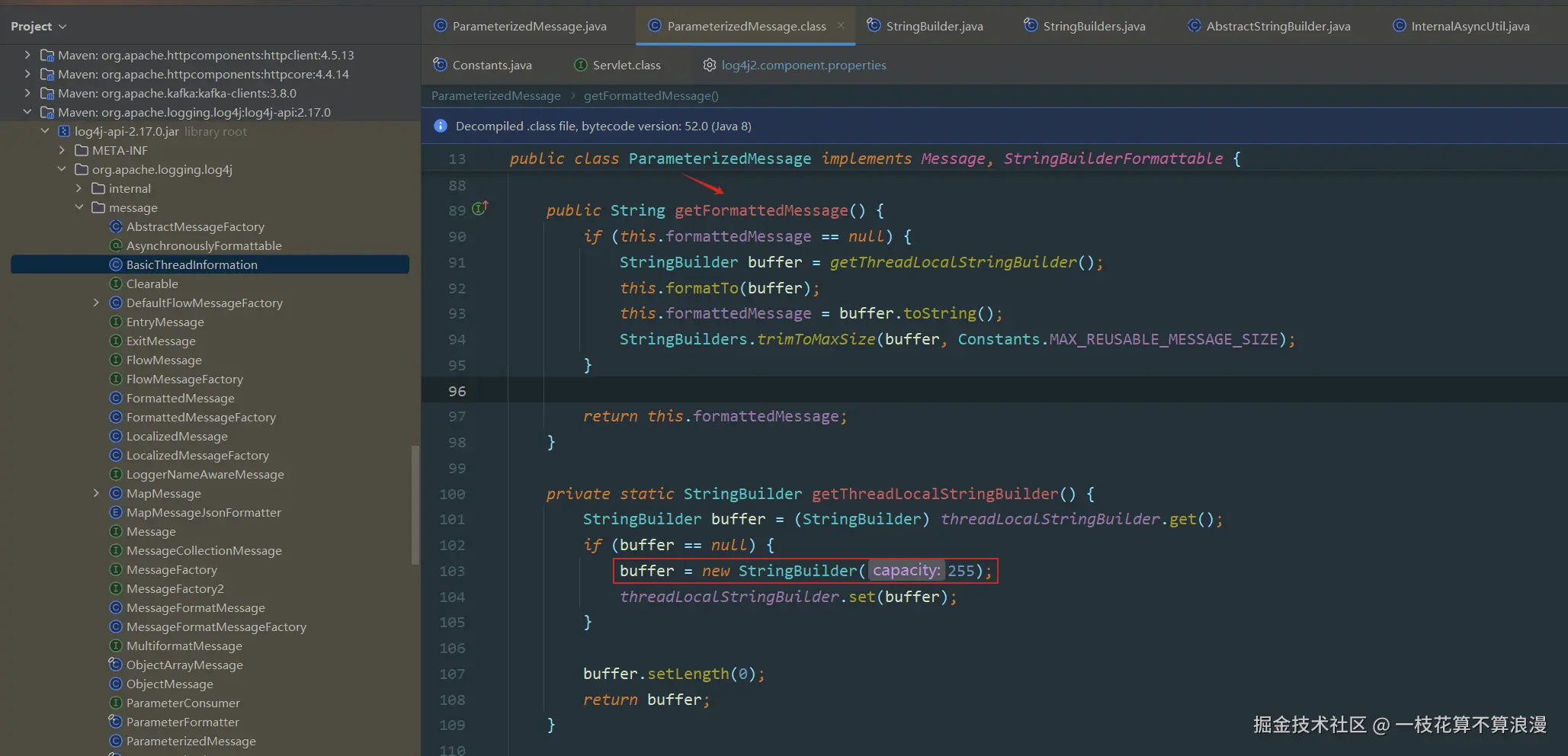
2.17.0版本初始创建255字节,然后按需扩容。再询问AI Log4j2框架后续版本这样改动的目的:
在对 Log4j2 不同版本间
MAX_REUSABLE_MESSAGE_SIZE处理方式的差异进行溯源和思考。从"按需创建"到"顶格分配"的变化,确实是 Log4j2 演进过程中一个值得探讨的设计抉择。🔍 版本行为对比
为了更清晰地展示提到的两个版本在处理上的差异,整理了以下表格:
特性 Log4j2 ~2.17.0 Log4j2 2.23.1 分配策略 初始创建较小(如 255 字节)的 StringBuilder"顶格分配" ,直接创建指定 MAX_REUSABLE_MESSAGE_SIZE大小的StringBuilder核心目标 节省单个线程的初始内存占用 追求极致的格式化性能,避免任何可能的中间扩容操作 性能表现 若日志消息超长,可能触发多次扩容和数组复制,带来额外的性能开销 绝大多数情况下一次分配,无需扩容,格式化操作更快 内存占用 初始内存占用较低,但遇到大消息时,扩容后可能最终占用与顶格分配相似的内存 每个线程初始内存占用即固定 ,与配置的 MAX_REUSABLE_MESSAGE_SIZE直接相关适用场景 对内存资源非常敏感,且日志消息长度普遍较短的环境 追求高性能日志记录,能够接受以固定内存换取性能,且日志消息长度多变的环境 💡 顶格分配的设计考量
Log4j2 团队在后续版本中选择"顶格分配"策略,并非一个缺陷,而是基于特定目标的权衡:
- 极致性能优先 :日志记录在许多应用中属于高频操作。"顶格分配" 最直接的好处是避免了
StringBuilder在后续格式化过程中因容量不足而进行的多次扩容。每次扩容都涉及申请新内存、复制旧数据、回收旧数组等一系列操作,这在高性能场景下是不可忽视的开销。预先分配足够大的空间,消除了这个不确定性。- 内存与性能的权衡 :这体现了软件设计中常见的 "以空间换时间" 的策略。开发者通过适当提高
MAX_REUSABLE_MESSAGE_SIZE,可以换取更稳定、更高效的日志记录性能。当然,这也要求开发者对自身系统的日志大小有一定的了解,并接受每个线程所需的内存开销会相应增加。- 预期内的内存占用 :顶格分配使得每个线程的日志缓冲区内存占用变得可预测 。对于一个配置了固定大小线程池的应用,可以相对准确地计算出 Log4j2 线程本地缓存所需的总内存(线程数 ×
MAX_REUSABLE_MESSAGE_SIZE× 2字节),方便进行资源规划。⚠️ 潜在的问题
- 初衷 :为了在高性能日志记录中避免反复扩容
StringBuilder(扩容涉及数组复制,成本高),直接分配一个足够大的缓冲区在性能上是最优的。- 副作用 :当这个机制因为
isWebApp误判而失效,线程本地缓存被禁用时,每次日志记录都"顶格分配"一个大缓冲区的行为就从性能优化变成了性能灾难和内存杀手。
1.4 Logback和Log4j2的对比
Spring Boot 默认使用的是 Logback日志框架,这里给出和Log4j2的对比:
- Logback :可以看作是 Log4j 1.x 的官方正统继承者和现代化改进版 。由同一作者(Ceki Gülcü)开发,旨在解决 Log4j 1.x 的诸多痛点,并原生支持 SLF4J。它的设计是渐进式的演进。
- Log4j 2 :这是 Apache 基金会的一个全新项目 ,受 Logback 思想的启发,但完全从头开始重写。它旨在吸收 Logback 的优点,同时解决其架构上的一些局限性,并引入更革命性的特性(如无垃圾日志记录)。它的设计是颠覆式的革新。
简单比喻:
- Log4j 1.x -> Logback:像是从 Windows XP 升级到了 Windows 7,系统更流畅、界面更美观、功能更强。
- Logback -> Log4j 2:像是从 Windows 系统切换到了 macOS,理念和底层架构都有了巨大的变化,旨在提供一种更极致的体验。
详细对比表:Logback vs. Log4j2
| 特性维度 | Logback | Log4j2 | 分析与解释 |
|---|---|---|---|
| 出身与作者 | Ceki Gülcü,作为 Log4j 1.x 的继任者 | Apache 基金会,受启发但完全重写 | Logback 是"正统",Log4j2 是"新贵"。 |
| 性能表现 | 优秀。比 Log4j 1.x 有显著提升。 | 极致 。尤其是在异步日志模式下,性能远超 Logback。 | 这是 Log4j2 的最大卖点 。其异步模式基于LMAX Disruptor(一个高性能的无锁环形队列库),极大减少了线程争用,在高并发场景下性能提升数个数量级。 |
| 异步日志 | 支持,通过 AsyncAppender。 |
支持,提供两种方式:AsyncAppender 和更高效的 AsyncLogger。 |
Logback 的 AsyncAppender 只是一个阻塞队列包装器,在队列满时可能阻塞应用线程。Log4j2 的 AsyncLogger 基于 Disruptor,是真正的无锁异步,吞吐量极高。 |
| 垃圾回收友好度 | 良好。 | 极佳 。支持 "无垃圾"(Garbage-Free) 或"低垃圾"模式。 | Log4j2 在记录日志时可重用对象(如 ThreadLocal 的 StringBuilder)和缓存,避免创建大量临时对象,从而极大减轻了 GC 压力,对于延迟敏感的应用程序至关重要。 |
| 配置方式 | XML 或 Groovy。支持条件处理 (<if>) 。 |
XML, JSON, YAML, Properties。功能更强大的条件配置和脚本支持。 | Log4j2 的配置更加灵活和强大,例如可以在配置中直接使用系统属性或环境变量进行复杂逻辑判断。 |
| 自动重载配置 | 支持,且可靠。 | 支持,且更可靠。 | 两者都支持在应用不重启的情况下重载配置文件,对于生产环境调试非常有用。 |
| 插件架构 | 有,但相对简单。 | 功能强大且易于扩展。 | Log4j2 的插件系统非常成熟,只需使用 @Plugin 注解即可轻松自定义 Appender、Layout 等组件。 |
| 社区与维护 | 稳定维护。但新特性迭代较慢。 | 非常活跃。Apache 顶级项目,持续迭代,修复迅速。 | Log4j2 的社区活跃度和发展势头明显优于 Logback。但之前的 Log4Shell 漏洞也提醒我们,新特性多也可能带来新的风险。 |
| 安全性 | 历史上较为稳定,未出现严重远程漏洞。 | 曾因 Log4Shell(CVE-2021-44228)漏洞而蒙上阴影。 | 这是一个重要的考量点。Log4Shell 之后,Log4j2 团队在安全方面投入了巨大精力,安全性已得到显著增强。 |
2、isWebApp的判断是Log4j2的Bug吗?为何webApp应用就不能共享线程缓存?
同样这个问题也是我们大家一直疑问的地方,log4j2框架是不是存在Bug,为何webApp就禁止线程内禁止使用共享的缓存?
这里直接问了AI:
log4j2对于WebApp的处理不是bug,而是有意设计的安全措施。原因如下:
- 在传统的Web容器(如Tomcat、Jetty)中,应用可能会被频繁重新部署,且线程会被重用。如果使用线程本地缓存(threadlocals),在重新部署时,线程本地对象可能无法被及时清理,从而持有旧类加载器的引用,导致内存泄漏(类加载器无法被垃圾回收)。
- 因此,log4j2在检测到Web应用时禁用线程本地缓存,以防止内存泄漏。这是一种保守但安全的策略。
- 问题在于,log4j2的检测机制基于类路径中是否存在
javax.servlet.Servlet类,这对于Spring Boot应用(使用嵌入式Servlet容器)可能产生误判。Spring Boot应用通常不会像传统Web容器那样频繁重新部署,因此禁用缓存可能是不必要的。
接着追问,对于SpringBoo应用包含嵌入式容器是否存在问题:
Spring Boot应用与 Log4j2 内存泄漏担忧
- 传统 Web 容器 vs Spring Boot 嵌入式容器 :
- 传统容器(Tomcat, WebSphere) :应用会频繁地热部署(Hot Deployment) 和 卸载(Undeploy) 。线程由容器管理,会在部署之间被复用 。如果Log4j2在这些线程的ThreadLocal里存了东西,当下一个应用部署后,旧应用的ClassLoader因为被ThreadLocal引用而无法被GC回收,就造成了ClassLoader泄漏,最终导致内存泄漏。
- Spring Boot 嵌入式容器 :您的应用和Tomcat服务器是同一个JVM进程,同一个ClassLoader 。应用的生命周期就是JVM的生命周期。通常不会存在"应用卸载但容器线程仍在"的情况。当您停止JVM时,一切都会被回收。
- 结论 : 在 Spring Boot 嵌入式容器 中,由Log4j2的ThreadLocal引起内存泄漏的风险极低 。因为不存在应用独立 reload 而线程池存活的场景。整个JVM同生共死,因此,在您的场景下,大胆地使用
-Dlog4j2.is.webapp=false来启用线程本地缓存是安全且正确的做法,无需过分担心内存泄漏问题。这个安全措施主要是为传统部署模式设计的,对于Spring Boot的嵌入式部署模式来说,它过于保守了。
因此,本次事故并非 Log4j2 的'Bug',而是其'高性能设计'与我们应用'特定配置'及'意外环境'(误判为 WebApp)相结合后产生的一个'副作用'。