文章目录
-
[1. MySQL安装](#1. MySQL安装)
-
[2. 安装Hive集群](#2. 安装Hive集群)
-
[3. 使用Hive客户端](#3. 使用Hive客户端)
-
[4. 实战总结](#4. 实战总结)
-
本实战在VMware上搭建Hive集群,集成MySQL作为元数据存储,完成Hive环境配置、元数据初始化及HDFS仓库目录创建,实现Hive on Hadoop的SQL查询能力,为大数据分析提供数据仓库支持。
1. MySQL安装

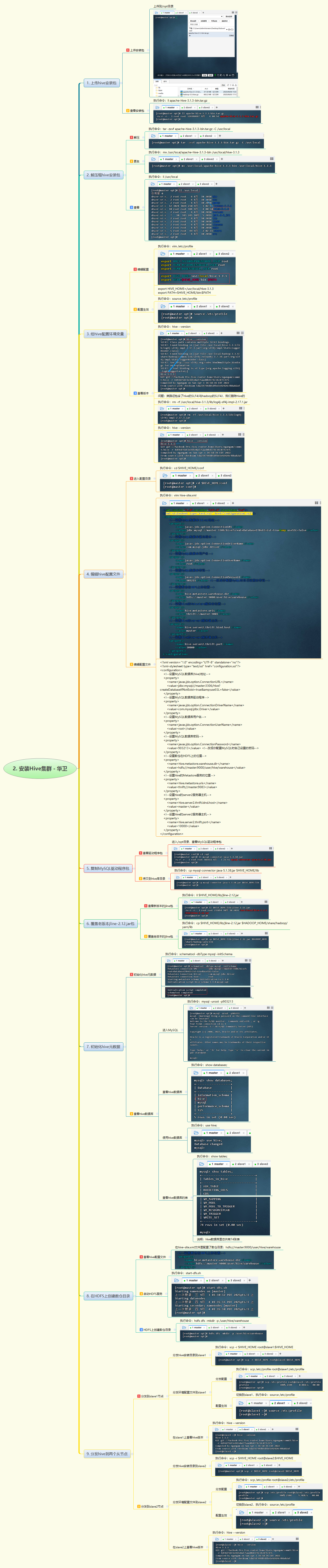
2. 安装Hive集群
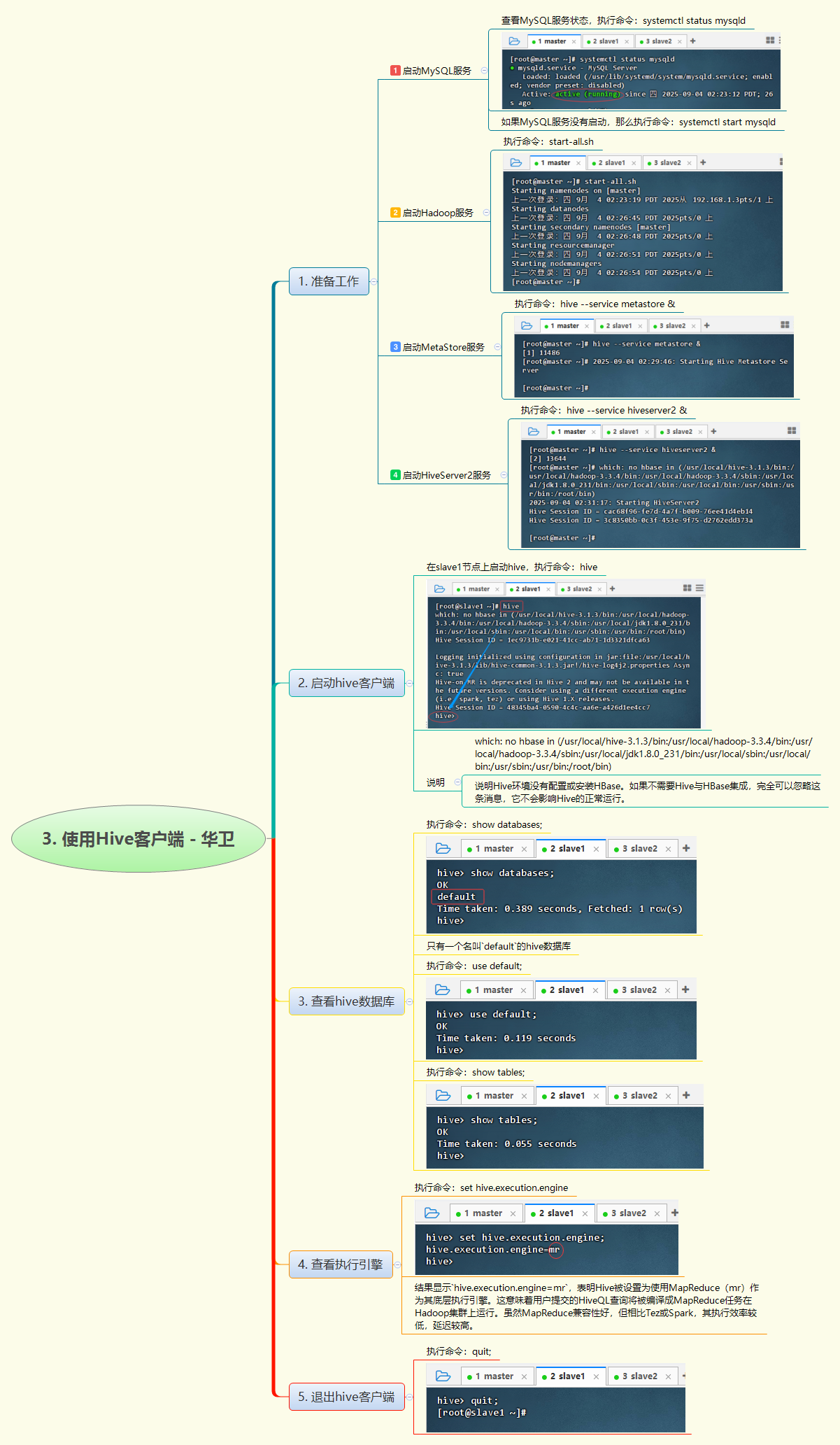
3. 使用Hive客户端
4. 实战总结
- 本次实战完成了在VMware虚拟机环境下Hive分布式数据仓库集群的搭建与配置。通过安装MySQL作为元数据存储,合理配置
hive-site.xml,解决Hadoop与Hive间的JAR包版本冲突(如guava、jline),并初始化元数据库,成功部署Hive Metastore和Hiveserver2服务。集群配置完成后,通过Hive客户端验证了数据库连接与基本操作,明确了Hive基于MapReduce的执行引擎机制。整个过程深入理解了Hive与Hadoop生态的集成原理,掌握了元数据管理、类路径冲突解决及服务部署的关键技能,为后续开展大数据分析与数仓建设奠定了坚实基础。