Kafka概述
kafka是一个分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理领域。kafka采取了发布/订阅模式,消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受感兴趣的消息。
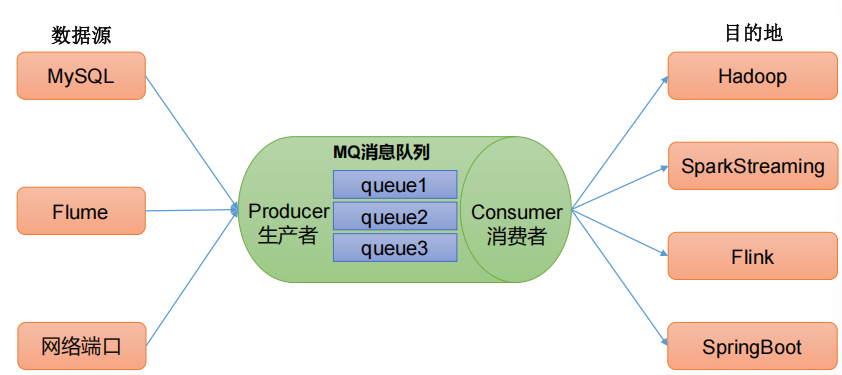
消息队列
-
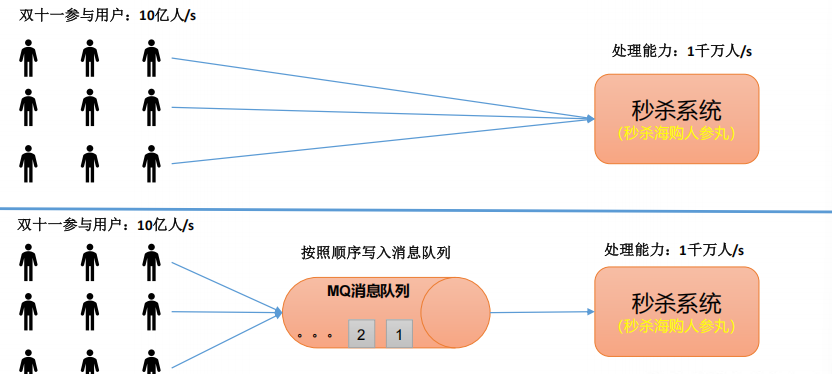
传统的消息队列的主要应用场景包括:缓存/削峰、解耦和异步通信。
-
缓冲/削峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
-
解耦:允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
-
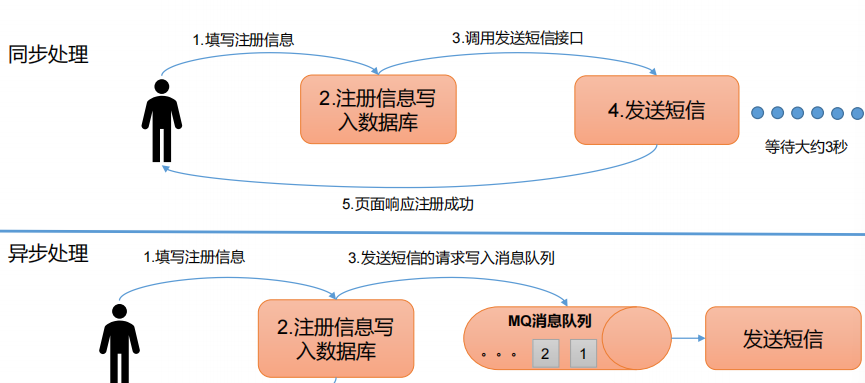
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
-
-
消息队列的两种模式
- 点对点模式:消费者主动拉取数据,消息收到后清除mq里的消息
- 发布/订阅模式:可以有多个topic主题;消费者消费数据之后,不删除数据;每个消费者相互独立,都可以消费到数据。
Kafka基础架构
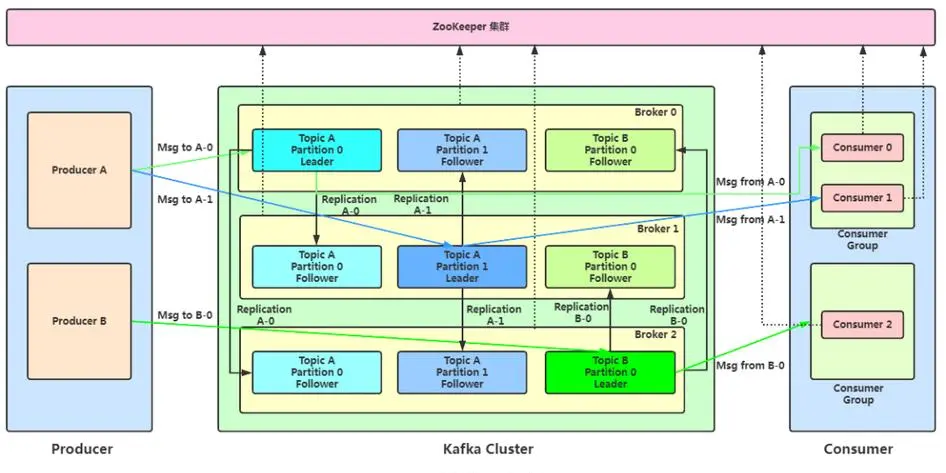
- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的"主",生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的"从",实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
- zk中记录谁是leader,kafka2.8之后也可以不配置zk。
Kafka的安装部署
笔者是采用k8s的方式在云服务器上部署kafka的,具体的安装步骤,大家可以参考这篇博客:https://blog.csdn.net/weixin_46619605/article/details/146170695,这里就不再叙述。
Kafka的命令行操作
主题命令行操作
-
查看操作主题命令参数
clikebin/kafka-topics.sh -
查看当前服务器中的所有topic
clikebin/kafka-topics.sh --bootstrap-server xx:xx --list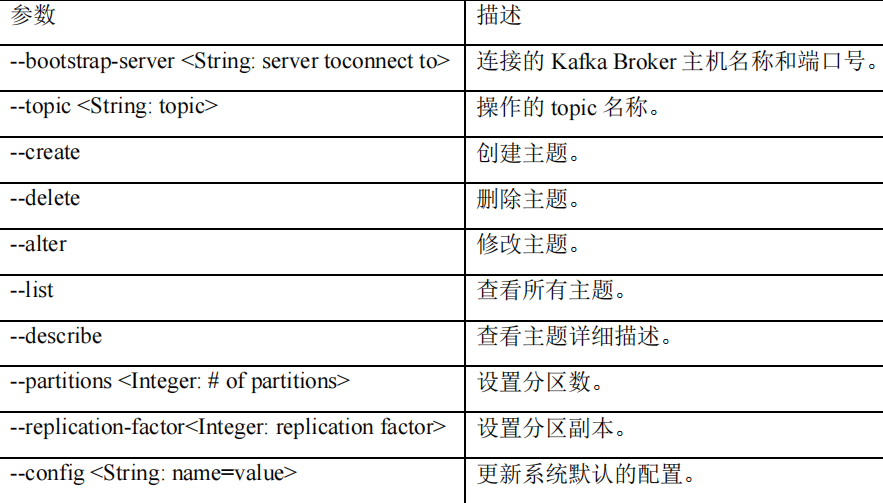
生产者命令行操作
-
查看操作生产者命令参数
clikebin/kafka-console-producer.sh
消费者命令行操作
-
查看操作消费者命令参数
clikebin/kafka-console-consumer.sh

生产者消息发送流程
- 发送原理
在消息发送的过程中,涉及到了两个线程------main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
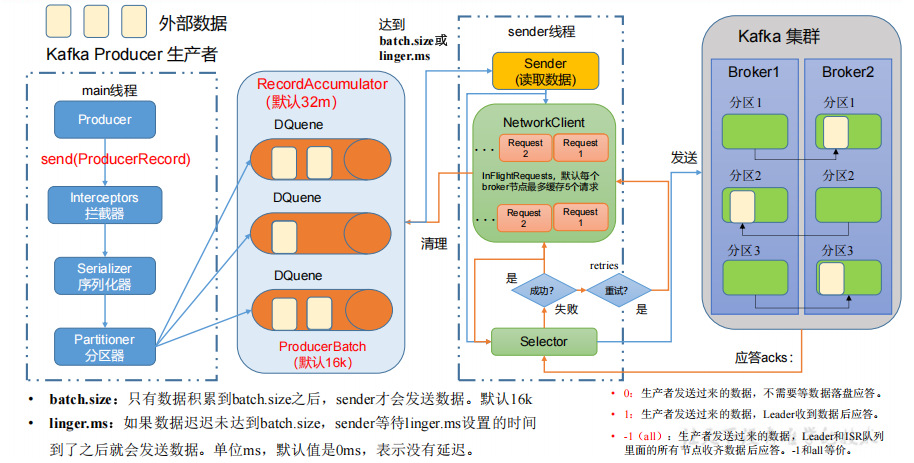
- 生产者分区
- 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
Kafka Broker总体工作流程
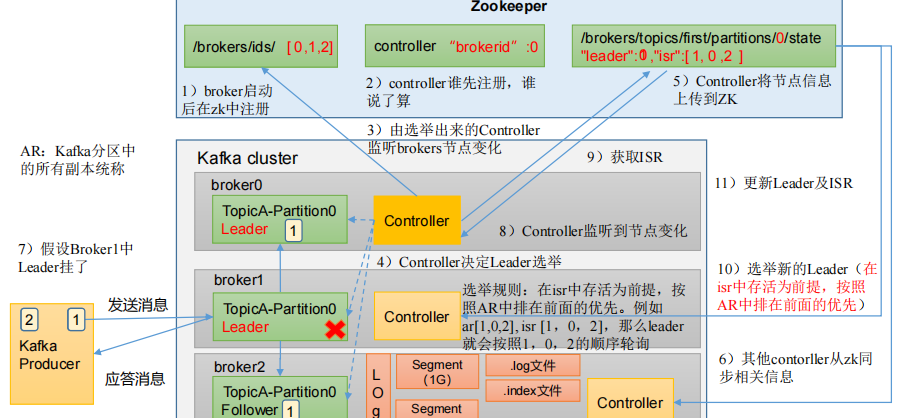
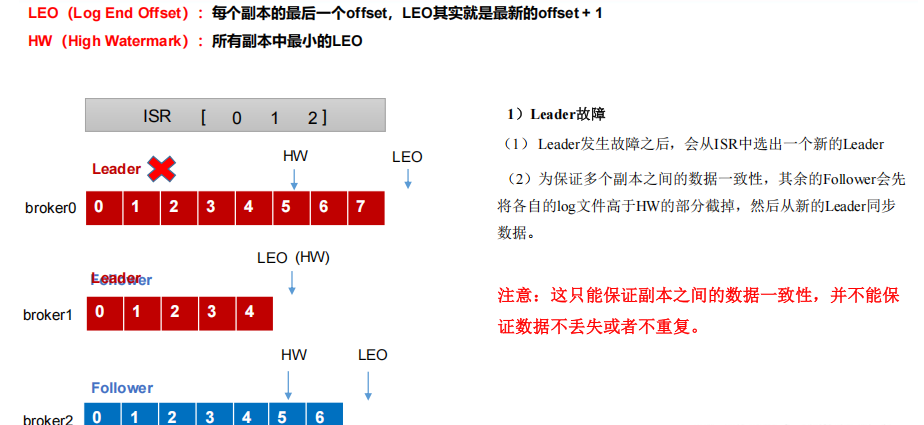
Kafka副本
- Kafka 副本作用:提高数据可靠性。
- Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
- Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。
- Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。

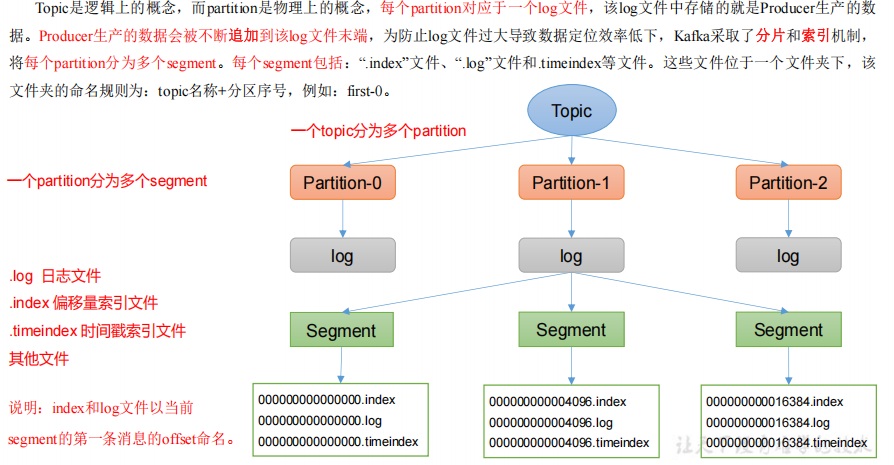
文件存储机制
文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
- log.retention.hours,最低优先级小时,默认 7 天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
Kafka中提供的日志清理策略有delete和compact。
- delete日志删除:将过期数据删除
log.cleanup.policy = delete 所有数据启用删除策略- 基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
- 基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。
log.retention.bytes,默认等于-1,表示无穷大。
- compact日志压缩:对于相同的key的不同value值,只保留最后一个版本。
高效读写数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。 - 页缓存+零拷贝技术
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
Kafka消费方式
- pull模式:consumer采用从broker中主动拉取数据。kafka采用这种方式。不足之处,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
- push模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率。
Kafka消费者工作流程
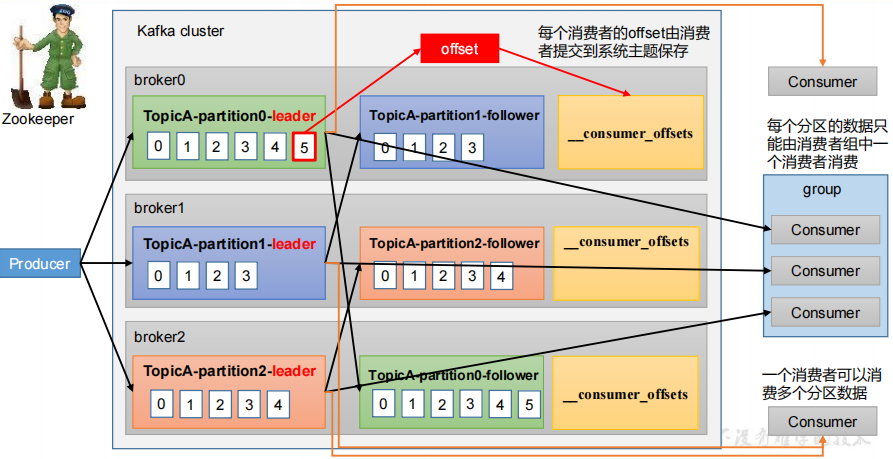
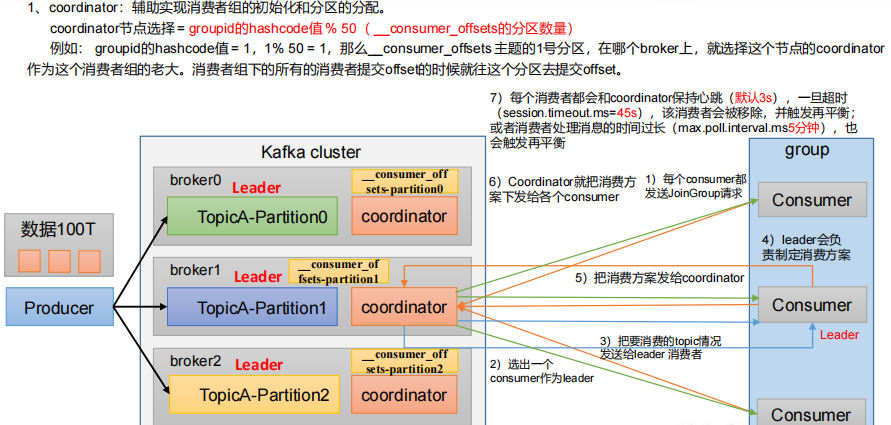
消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
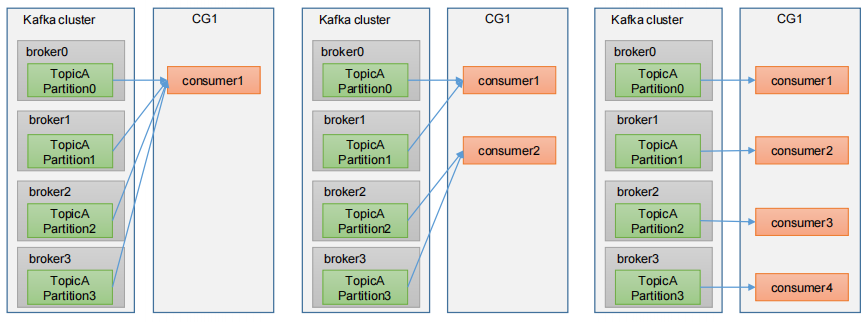
消费者组初始化流程
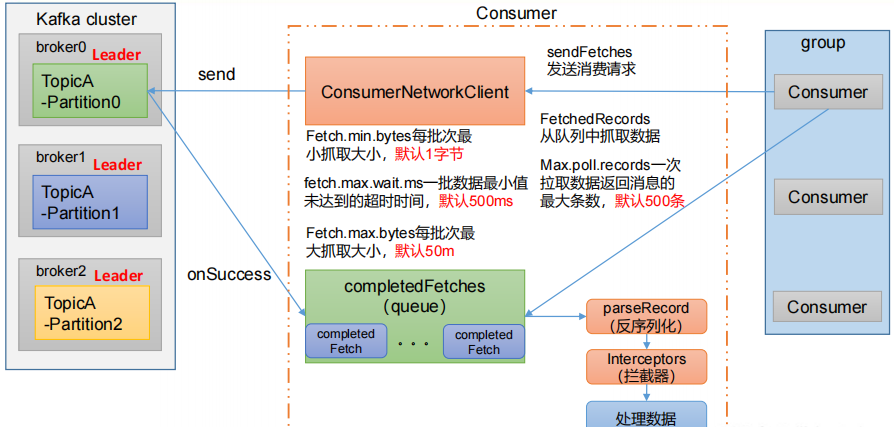
消费者详细消费流程
消费offset 位移
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据。
-
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
- enable.auto.commit:是否开启自动提交offset功能,默认是true
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
-
虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
指定Offset消费
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
- earliest:自动将偏移量重置为最早的偏移量,--from-beginning。
- latest(默认值):自动将偏移量重置为最新偏移量。
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
- 任意指定 offset 位移开始消费。
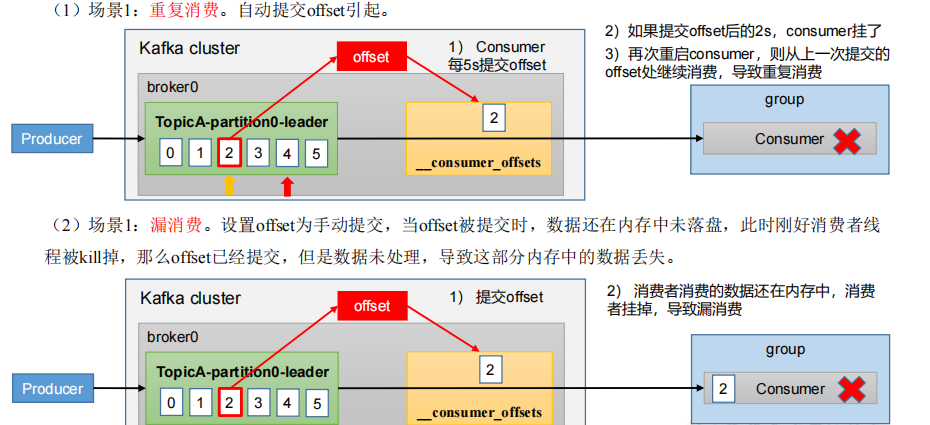
漏消费和重复消费
重复消费:已经消费了数据,但是 offset 没提交。
漏消费:先提交 offset 后消费,有可能会造成数据的漏消费。
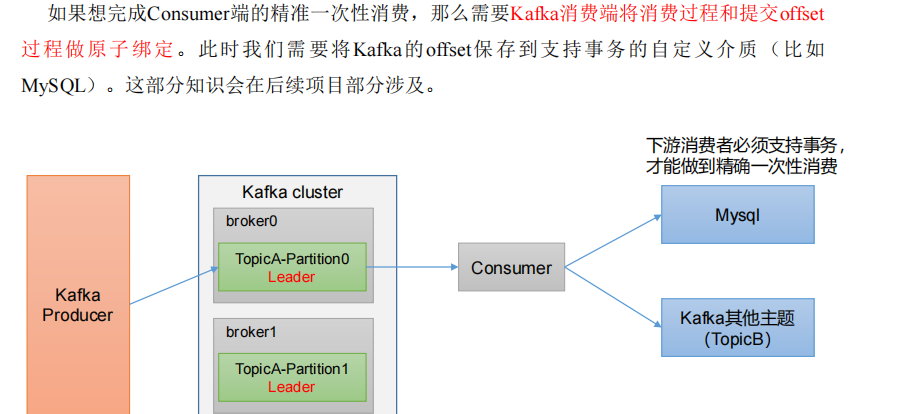
消费者事务
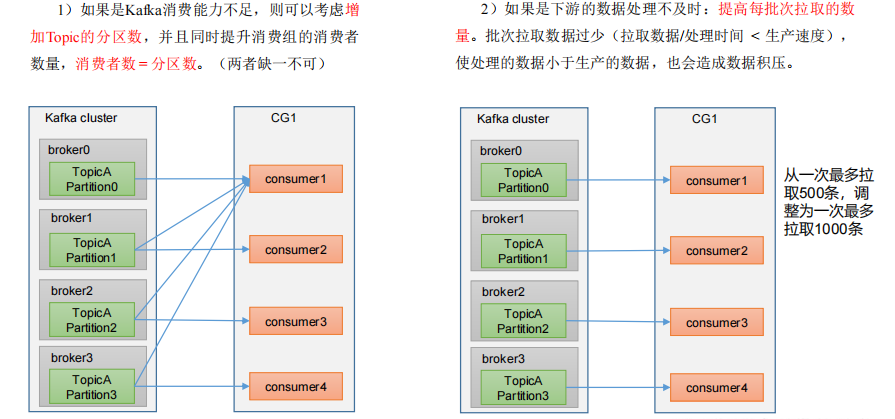
数据积压(消费者如何提高吞吐量)