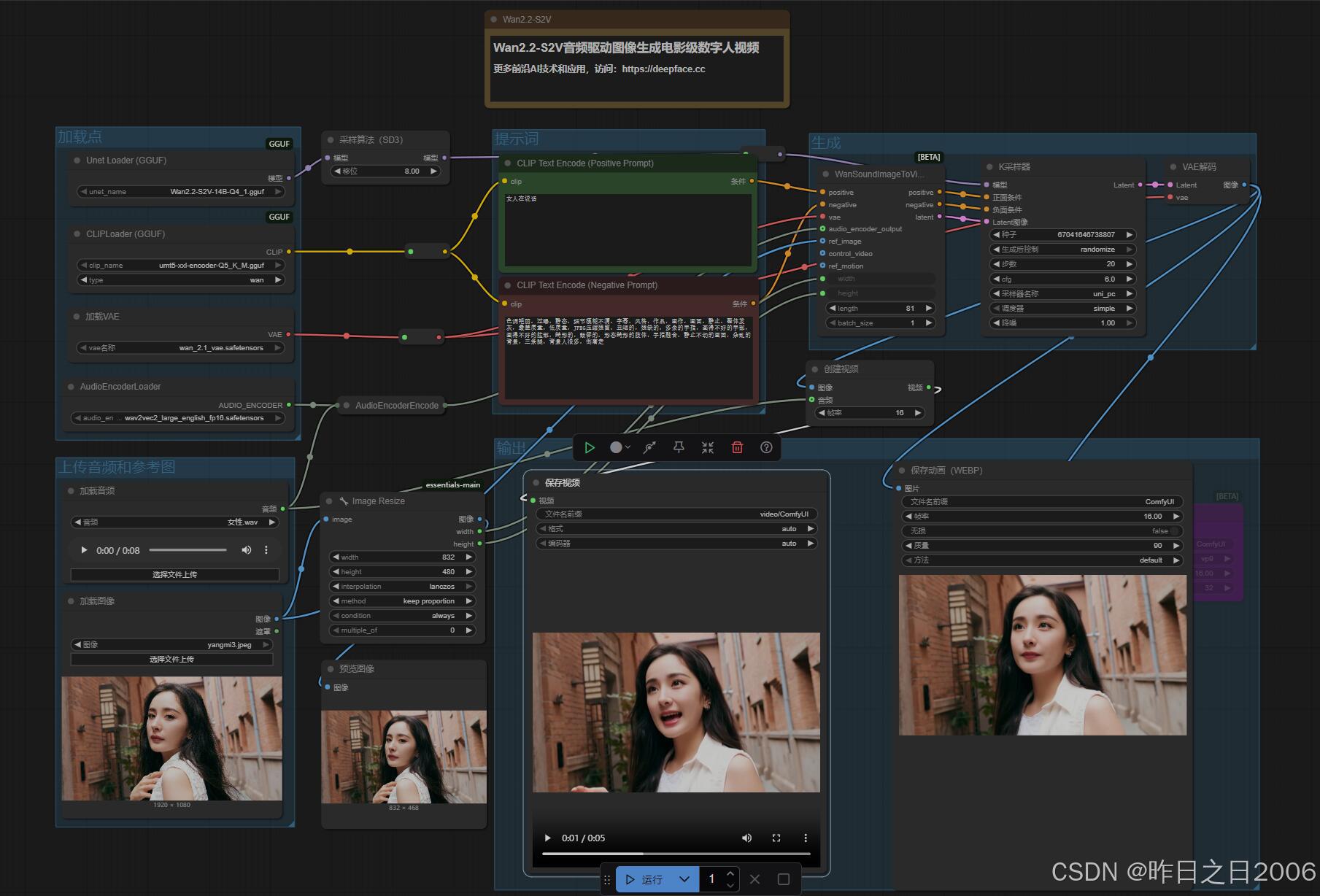
Wan2.2-S2V 是阿里云开源的一款多模态视频生成模型,该模型专为音频驱动的电影视频生成而设计,其核心功能是通过一张静态图片和一段音频,自动生成电影级质量的数字人视频。不仅在语音和歌唱的场景中表现出色,在满足对细腻的角色互动、逼真的身体动作和动态摄像工作的需求下,尤其对电影情境下视频生成显著增强了表现力和保真度。
主要特点
输入简单:只需一张图片(真人、卡通、动物等均可)和一段音频(如说话、唱歌),就能让图片"动起来"。
效果逼真:生成视频的口型与音频精准同步,面部表情自然,肢体动作流畅,甚至能模拟弹钢琴时手指的细节动作。
支持长视频:单次可生成分钟级时长的视频,远超同类模型的生成能力。
灵活控制:通过文本提示(Prompt)可调整视频内容,比如改变人物动作或背景。
音频驱动:结合全局运动控制和局部细节优化,确保口型、表情与音频高度匹配。
应用领域
数字人直播:快速生成虚拟主播,实现24小时不间断直播,降低人力成本。
影视制作:用于角色预演、动画短片生成,加速创作流程。
音乐视频:对于音乐视频来说,这个模型可以生成与音乐同步的人物表演视频,让音乐视频更加生动有趣。
广告创意:在广告制作中,Wan-S2V 可以用来快速生成各种创意视频,比如产品展示、品牌宣传等,提高广告的制作效率。
AI教育:将教材内容转化为生动讲解视频,提升学习体验。
虚拟偶像:为卡通或数字人形象赋予表演能力,如唱歌、跳舞等
使用教程: (建议N卡,显存12G起,支持50系显卡)
分别下载一键包主体和模型文件(ComfyUI文件夹),解压一键包主体后,将模型(ComfyUI文件夹)移动到一键包主体下即可。
双击启动,进入WebUI后,点击左侧的 工作流,选择Wan2.2-S2V-GGUF.json
上传图像和音频,调节生成时长(生成下的length,16帧为一秒,比如81帧,即生成5秒长度),输入提示词,最后点下方的运行即可。
2025年9月5日,更新最新V10模型,大家可以根据需要下载,然后在unet模型切换到V10。
下载地址:点此下载