当前,AI 应用正处于极速发展阶段,大语言模型(LLM)与检索增强生成(RAG)系统已成为构建智能问答、知识管理等高阶 AI 应用的核心引擎,被广泛应用于金融分析、学术研究、企业合规等多个领域。然而,许多团队在将 LLM 与 RAG 系统落地到实际项目时,却遭遇了明显的瓶颈:系统的实际表现与预期存在较大差距,无论是回答用户问题的准确性、内容相关性,还是整体响应效率,均难以满足业务需求。
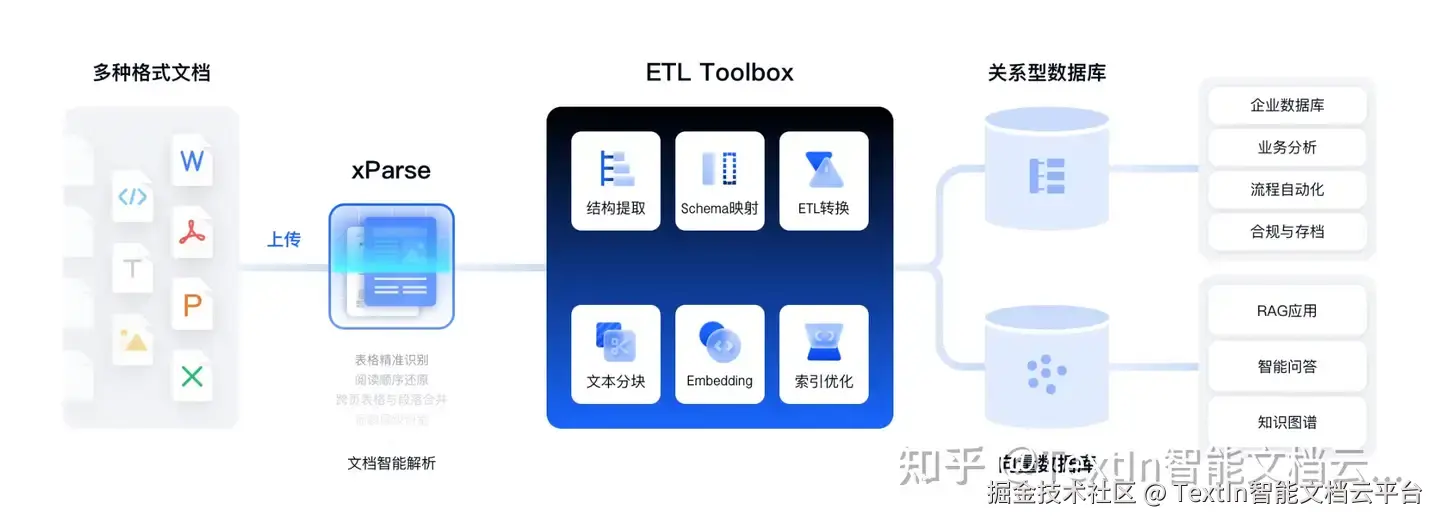
优质的文档解析并非简单提取文字,而是对文档内容进行深度理解与结构化重建------ 既要还原标题层级、段落顺序、表格结构等显性信息,也要捕捉元素间的语义关联(如图表与正文的对应关系、跨页内容的逻辑衔接),为后续 RAG 系统和 LLM 提供 "可理解" 的输入数据。
传统 OCR 工具的局限性恰好凸显了优质文档解析的重要性:传统 OCR 仅能机械提取图像上的文字,如同 "近视的搬运工",无法识别文档的内在 "蓝图"------ 标题层级关系混乱、段落被拆分得支离破碎、复杂表格像撕碎的拼图、跨页内容彻底断裂、图表沦为无注释的 "孤岛"。
当这种缺乏结构、语义断裂的数据直接输入 RAG 系统时,会引发一系列连锁问题:
- 检索效率低下:系统难以精准定位包含答案的关键片段,只能在海量文字碎片中 "大海捞针",耗时且低效;
- 答案准确性受损:上下文缺失或错位导致 LLM "理解偏差",生成跑题甚至错误的回答;
- 信息完整性打折:表格数据混乱、跨页信息断裂、图表意义不明,关键细节丢失,无法支撑完整的分析与决策。
由此可见,文档解析的质量直接锁定了 RAG 系统乃至整个 AI 应用效果的上限,而解决这一痛点,正是提升大模型处理长文档能力的核心突破口。
案例数据
TextIn xParse 智能文档解析引擎作为针对性解决方案,已在多个实际场景中验证了其对大模型处理长文档能力的提升作用:
| 案例类型 | 核心挑战 | 解析效果 |
| 密集少线表格识别 | 表格线条稀疏、数据密集,传统 OCR 易混淆单元格边界,导致数据错位 | 精准识别单元格边界,前端支持选中表格并在原图上显示模型预测的单元格,数据提取准确率达 98% 以上 |
| 跨页表格合并与页眉页脚识别 | 表格跨页断裂、页眉页脚与正文混淆,传统 OCR 无法关联跨页数据,易遗漏关键信息 | 自动合并跨页表格,完整保留数据连续性;精准区分页眉页脚与正文内容,避免无关信息干扰 RAG 检索 |
| 图表识别 | 图表数据肉眼读取困难,传统 OCR 仅能提取图表标题,无法获取图表内数值信息 | 通过精确测量给出图表内预估数值,关联图表标题与正文注释,帮助 LLM 挖掘图表背后的有效数据 |
| 标题层级识别 | 长文档(如论文、年报)标题层级多,传统 OCR 无法区分一级标题、二级标题等逻辑关系 | 基于语义提取段落 embedding 值,预测标题层级关系,构造清晰的文档树,提升 RAG 检索时的知识点定位效率 |
| 多栏版式还原 | 多栏布局文档(如学术论文、业务报告)阅读顺序复杂,传统 OCR 易按列乱序提取文字 | 理解文档元素排列逻辑,精准还原正确阅读顺序,确保上下文语义连贯,避免 LLM 因语序混乱产生理解偏差 |
| 弯折图片识别 | 手机拍摄、扫描的文档易出现页面弯折,传统 OCR 因图像变形导致文字提取错误 | 集成强大的图像处理能力,一键矫正弯折页面,排除图像质量干扰,文字提取准确率不受变形影响 |
核心能力
编辑
TextIn xParse 作为大模型友好型解析工具,通过多维度核心能力解决传统文档解析的痛点,为大模型处理长文档提供高质量数据输入:
(1)多格式文件全覆盖解析
支持 PDF、Word、Excel、PPT、图片等十余种格式的非结构化文件解析,无论是电子文档还是扫描件,均能快速转换为 Markdown 或 JSON 格式输出,同时保留精确的页面元素和坐标信息,满足不同场景下大模型对数据格式的需求。
(2)全类型元素精准识别
可识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各类文档元素,还支持印章、二维码、条形码等子类型识别,确保无关键元素遗漏,为 LLM 推理、训练提供完整的输入数据,助力数据清洗和文档问答任务。
(3)复杂表格深度处理能力
具备行业领先的表格识别技术,可轻松解决合并单元格、跨页表格、无线表格、密集表格等传统解析工具难以应对的难题,完整保留表格结构与数据关联,避免因表格解析错误导致 LLM 生成错误结论。
(4)文档语义结构还原
- 阅读顺序还原:理解多栏布局、图文混排等复杂版式,还原文档正确阅读顺序,确保上下文语义连贯;
- 标题层级构建:自研文档树引擎,基于语义预测标题层级关系,构造文档树结构,提升 RAG 检索的召回效果和精准度。
(5)扫描内容自适应处理
能良好处理各类图片与扫描文档,包括手机照片、截屏、弯折页面等质量不佳的内容,通过图像处理技术矫正图像变形、去除噪声,确保文字与元素识别的准确性,打破 "优质解析依赖高清文档" 的限制。
(6)多语言支持
覆盖简体中文、繁体中文、英文、数字、西欧主流语言、东欧主流语言等共 50 + 种语言,满足跨国企业、学术研究等多语言场景下的文档解析需求,避免因语言限制导致的知识遗漏。
(7)图像处理能力
针对文档常见的水印、页面弯曲、模糊等问题,提供一键解决方案:自动去除水印、矫正弯曲页面、增强模糊图像,排除图像质量对解析效果的干扰,确保数据提取的稳定性。
(8)开发者友好的集成体验
提供清晰的 API 文档和灵活的集成方式,包括 MCP Server、Coze、Dify 插件,同时支持 FastGPT、CherryStudio、Cursor 等主流平台,降低开发者集成门槛,可快速适配知识库、RAG、Agent 或其他自定义 AI 工作流程。
独特价值
TextIn xParse 的核心价值,在于打破了 "非结构化文档" 与 "大模型理解" 之间的壁垒,其独特性体现在三个层面:
(1)从 "文字提取" 到 "语义重建" 的升级
区别于传统 OCR "只搬文字不懂结构" 的局限,TextIn xParse 以 "机器和 LLM 真正理解" 为目标,通过结构化重建让文档数据具备 "语义属性"------ 不仅提取文字,更还原逻辑关系(如标题与正文的从属、图表与注释的关联、跨页内容的衔接),为后续 RAG 分块策略、高效向量检索以及 LLM 精准生成提供 "高质量燃料"。
(2)全场景适配的实用性
TextIn xParse 的能力覆盖金融、学术、企业、教育、医疗、法律等多个领域的核心场景:
- 金融领域:解析年报、研报,支撑财务对比与合规审查;
- 学术领域:重建论文结构,助力知识图谱构建;
- 医疗领域:结构化病历数据,辅助临床决策;
- 法律领域:提取条款层级,赋能合规风险预警。
其适配性不仅体现在格式与元素识别,更在于对不同行业文档 "业务逻辑" 的理解,确保解析结果贴合实际需求。
(3)为 AI 应用效果提供 "底层保障"
文档解析是大模型处理长文档的 "第一步",也是最关键的一步。TextIn xParse 通过提升输入数据的 "质量",从源头解决 RAG 检索低效、LLM 回答偏差、信息遗漏等问题,帮助 AI 应用突破效果上限 ------ 无论是知识库构建、智能问答,还是 Agent 自动化流程,均能基于结构化数据实现更精准、更高效的输出,最终降低 AI 应用落地成本,提升业务价值。