摘要
我阅读了普林斯顿大学和谷歌大脑研究人员的《REACT:在语言模型中协同推理和行动》。该论文发表在 ICLR 2023 上,讨论了一种 LLM 提示方法,该方法帮助 LLM 在需要推理和行动的复杂环境中表现良好。
人类可以轻松地将以任务为导向的行动与口头推理结合起来。行动和推理之间的这种协同作用使人类能够快速学习新任务,并针对看不见的情况做出稳健的决策。
一、目前存在的问题:
诸如"思维链"之类的提示方法是黑匣子,这意味着模型使用内部表示来生成思想,而不是使用外部世界。这可能导致幻觉,正如本文后面所见。
预训练模型以前曾用于在交互式环境中进行规划和行动。他们将多模态观察结果转换为文本,并使用语言模型生成作(WebGPT、作为零样本规划器的语言模型、保持冷静和探索)。确实会出现一些问题。这些预训练模型尚未利用语言模型来执行抽象推理。他们缺乏工作记忆,这对于长期任务很重要。最后,他们缺乏对复杂环境的探索。
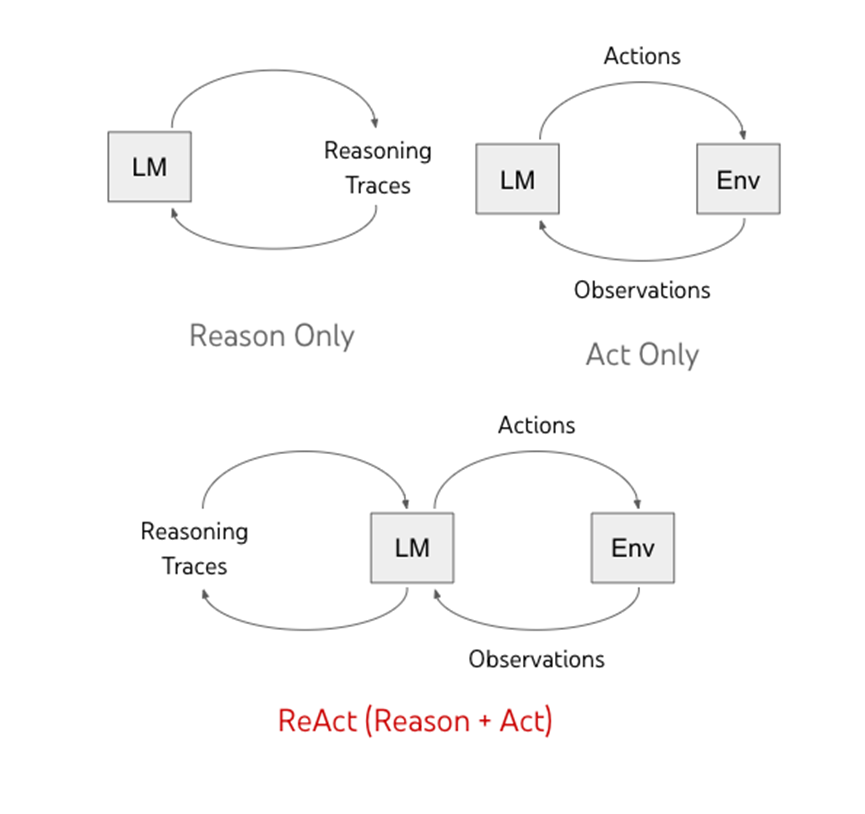
二、提出的解决方案:ReAcT(推理 + 行动)
ReAcT 提示 LLM 生成与任务相关的口头推理跟踪和作,以便模型显示高级推理。ReAcT 为行动(行动的理由)以及与环境交互以检索推理的附加信息(行动到理由)创建高级计划。该论文对以下内容进行了测试:
• 问答(HotputQA 数据集)
• 事实验证(FEVER数据集)
• 基于文本的游戏(ALFWorld)
• 网页导航(Webshop)

三、技术实现:
在每个时间步长 t 上,代理都会收到一个 O o_t ∈观察。代理执行 B a_t ∈作,其中 B = A ∪ L。
• A:与外部环境相互作用的行动空间。
• L:用于推理思想的语言空间。
代理根据策略行事( π(a_t | c_t) ):
• c_t = (o_1, a_1, ... , o_t-1, a_t-1) 是时间 t 的上下文。
• a_t要么是推理,要么是行动。
该策略使用冻结的 LLM(论文中的 PaLM)来实现。LLM 会提示一些人工注释的上下文演示。然后模型将生成下一个自回归的标记,无论是想法还是行动。
行动a_t∈A 会在上下文中引起新的 o_t+1,而思想 (a_t∈L) 则不会。
优势:
• 直观且易于设计的 ReAcT 提示。
• 通用和灵活
• 健壮,可以很好地推广到新任务。
四、实验设计与结果
1、在 ReAcT 上测试的任务:知识密集型推理任务:
• 使用HotPotQA和FEVER数据集。
作者设计了一个具有 3 个功能的维基百科 API:
• searchunity:返回前 5 个 wiki 页面或 5 个类似的 wiki 页面。
• lookupstring:返回包含字符串的页面中的下一个句子。
• finishanswer:使用答案完成当前任务。
• 目的是模拟人类如何与维基百科互动。
对于少量学习,他们从 HotPotQA 中获取了 6 个示例,从 FEVER 中获取了 3 个示例,每个示例包含多个动作观察步骤。
消融部分:
用于通过删除某些组件来针对 ReAcT 进行计算的基线模型。
• 标准提示:基本提示(无思想、无行动、无观察)。
• 思维链:删除动作和观察,只保留推理。CoT-SC:生成 21 种不同的推理路径并进行多数投票,这有利于减少幻觉。
• 仅行动提示 (ACT):在删除想法的同时保留行动和观察。
当 ReAcT 未能在给定步骤内返回时,使用 CoT-SC。如果来自 n 个 CoT-SC 样品的大多数答案出现少于 n/2 次,则再次使用 ReAcT,这表明存在一定的不确定性。
结果:
• ReAcT 的表现始终优于 ACT。
• 幻觉是 CoT 的一个问题。
• 通过搜索检索知识对于 ReAcT 来说很重要。
• ReAcT + CoT-SC 在微调方面表现最佳。
2 在 ReAcT 上测试的任务:决策任务:
用于决策任务的数据集:ALFWorld 和 Webshop。
ALFWorld:模拟基于文本的家务。
• 一个任务实例最多可以有 50 个不同的家庭位置,这会导致 50 个步骤。
• 作者从训练数据中随机选择了 3 个任务,并包括稀疏的思想(关键推理步骤)来指导智能体。他们通过要求智能体分解目标、跟踪子目标完成情况、确定下一个子目标和常识性推理来做到这一点。
• 3 个随机任务作为少量示例,以便代理可以推广到新情况。
结果:
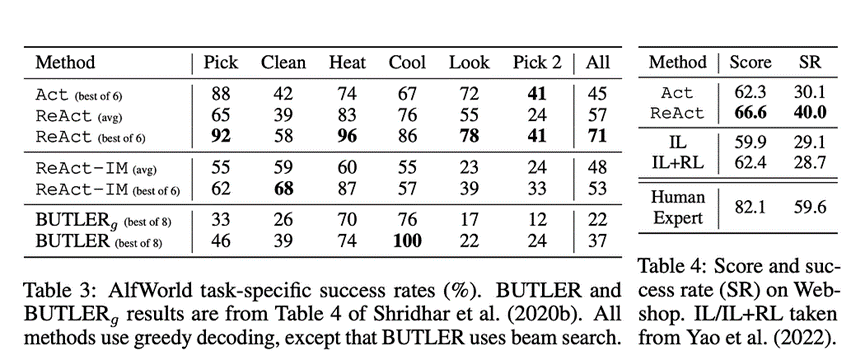
• 使用 ReAcT 提示的最佳跟踪导致 71% 的成功率,最差的跟踪导致 48% 的成功率。
• ReAcT 的表现优于 ACT(47%)和 BUTLER(37%)
• ACT 无法分解复杂的目标,而 ReAcT 则使用思考和推理。