本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
如何给Spring AI下定义呢?
在我看来,Spring AI和AI的关系,就像Spring Boot和Spring的关系一样,旨在简化包含AI功能的应用程序开发,避免不必要的复杂性。
据说,Spring AI是从著名的Python LangChain中汲取的灵感,就是为了让生成式AI应用不仅仅面向Python开发者,使Java这个伟大的语言再次伟大!
通过Spring AI,可以更行之有效地解决企业数据、API与AI模型集成的根本挑战。
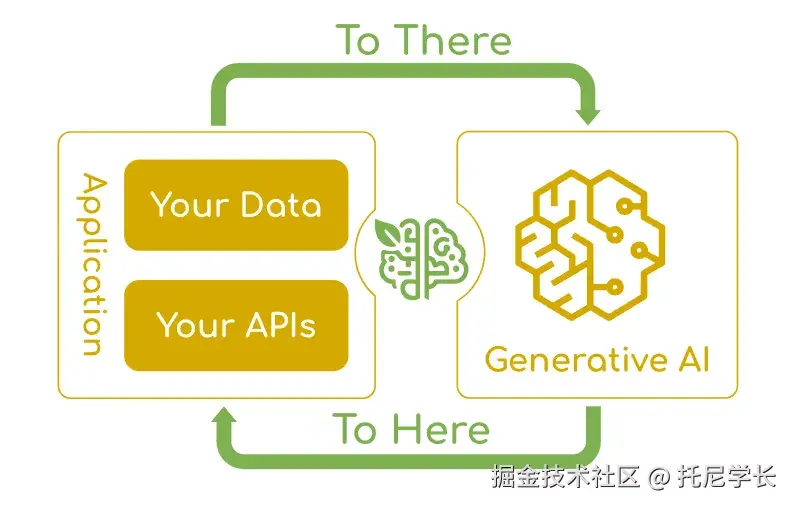
Spring AI 提供了一些抽象层,这些具有多种实现方式的抽象层是开发AI应用程序的基础,能够以最少的代码改动实现组件的轻松替换。
接下来我们看下Spring AI都具备哪些特性和能力。
1、主流模型支持
按照官网的说法,目前Spring AI支持所有主流的AI大模型提供商,包括:Anthropic、OpenAI、微软、亚马逊、谷歌和Ollama等。其所支持的模型类型有:
- 聊天补全(Chat Completion)
- 嵌入(Embedding)
- 文本生成图像(Text to Image)
- 音频转录(Audio Transcription)
- 文本转语音(Text to Speech)
- 内容审核(Moderation)
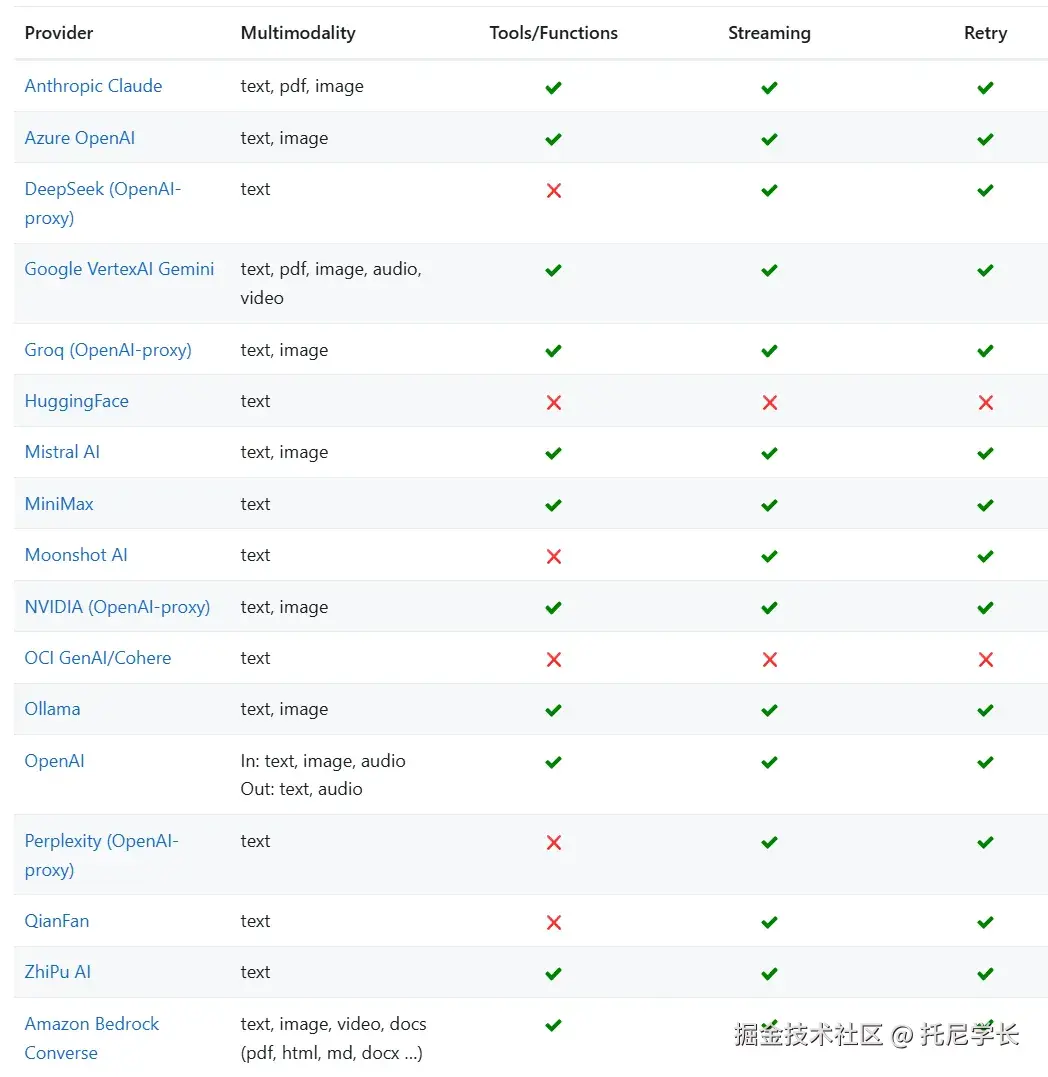
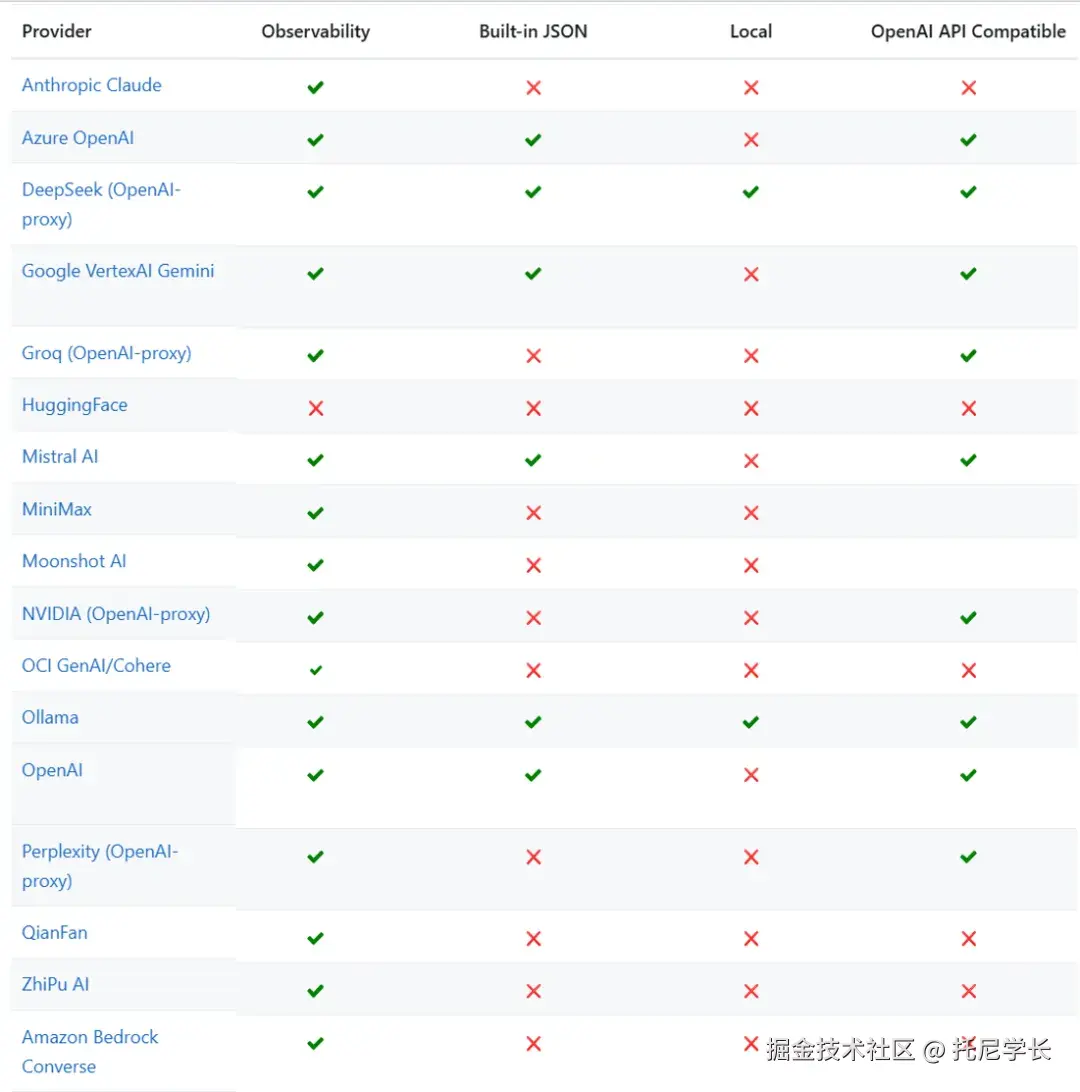
Spring AI支持这么多的大模型,并根据项目的实际需要在各个大模型间进行秒级切换,这对研发效率的提升是非常有帮助的。我们就以对话机器人为例,来看下代码的具体实现。
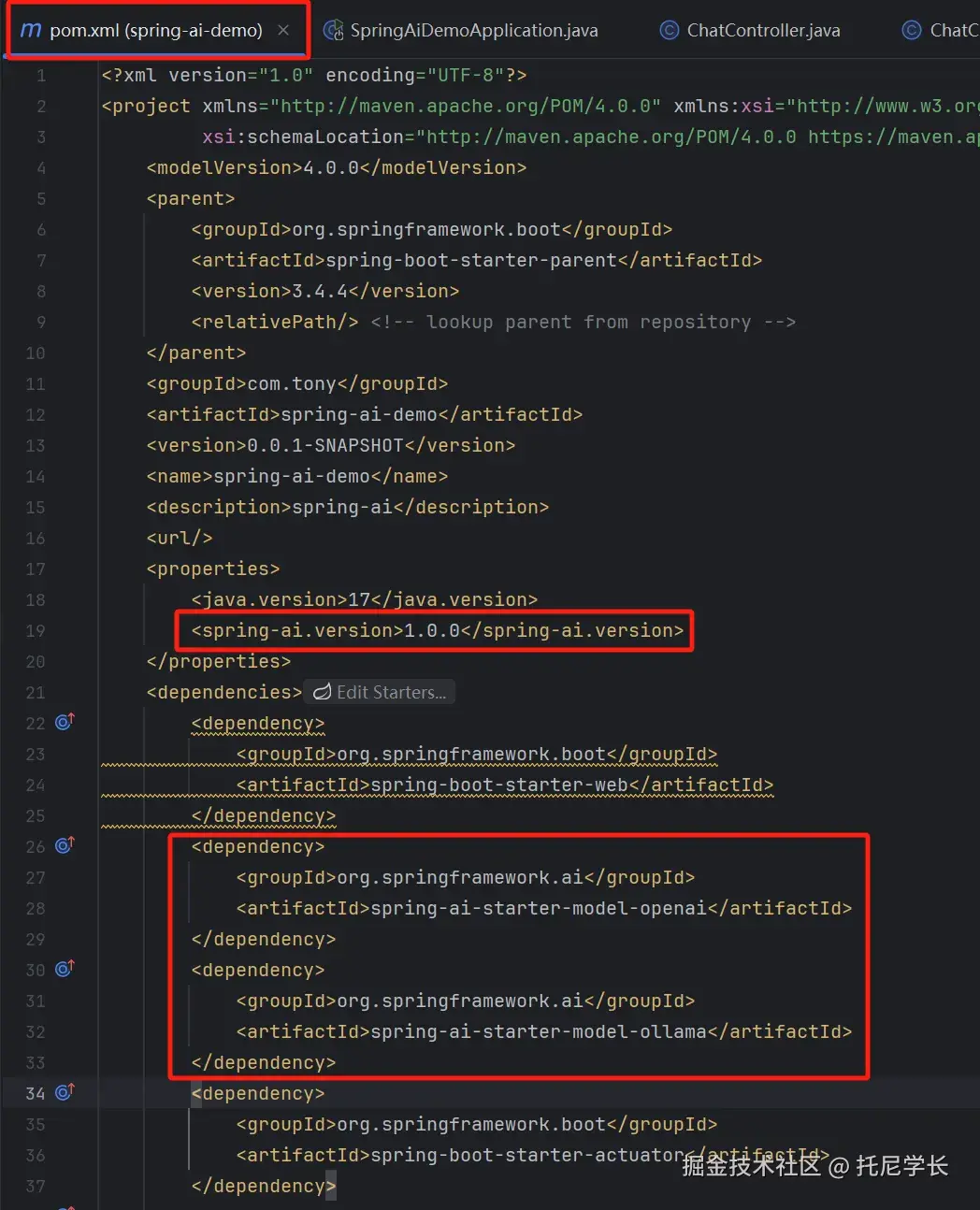
配置类及配置文件
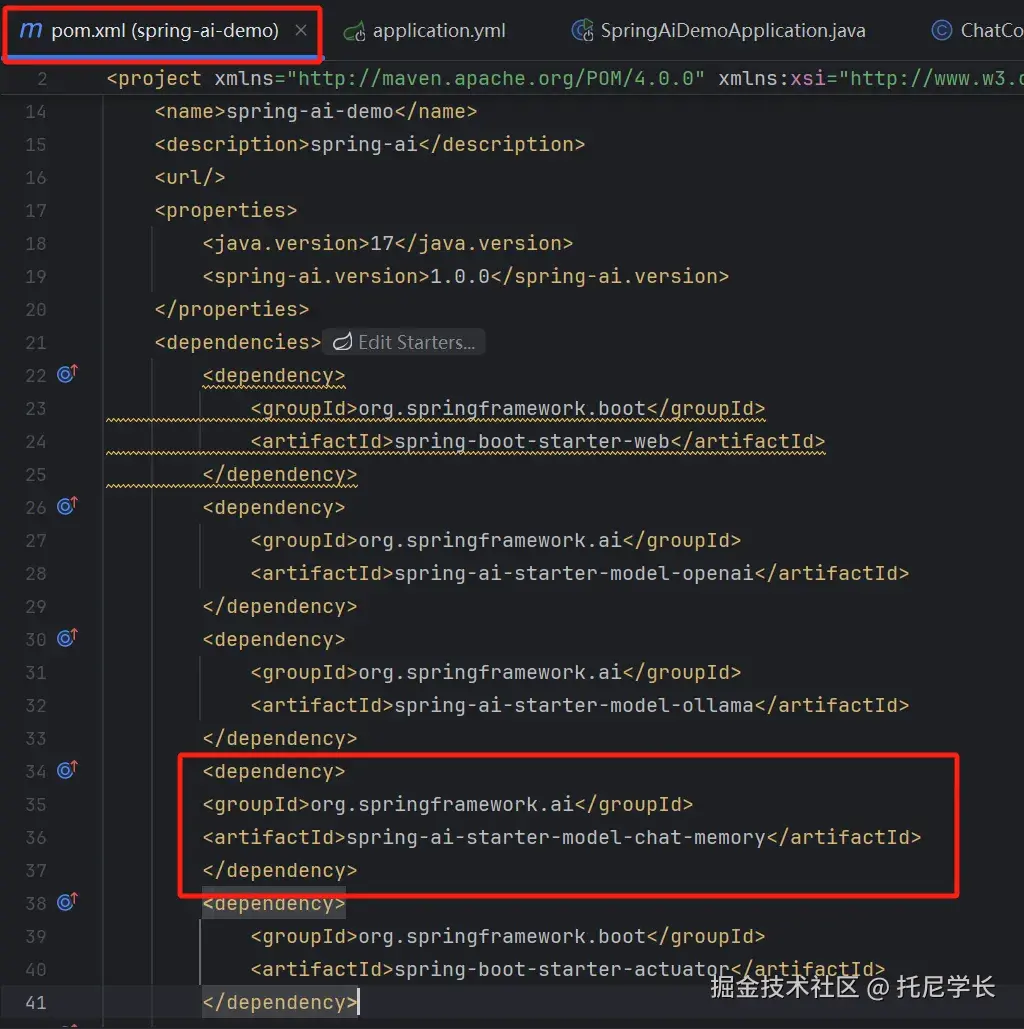
我们在这里选择Spring AI的1.0版本,并引入openai和ollama来实现大模型间的动态切换。这里特别需要注意的是,不要用Spring AI的太高版本,我之前用的1.1.0-M7版本,里面各种maven依赖jar包不能下载。
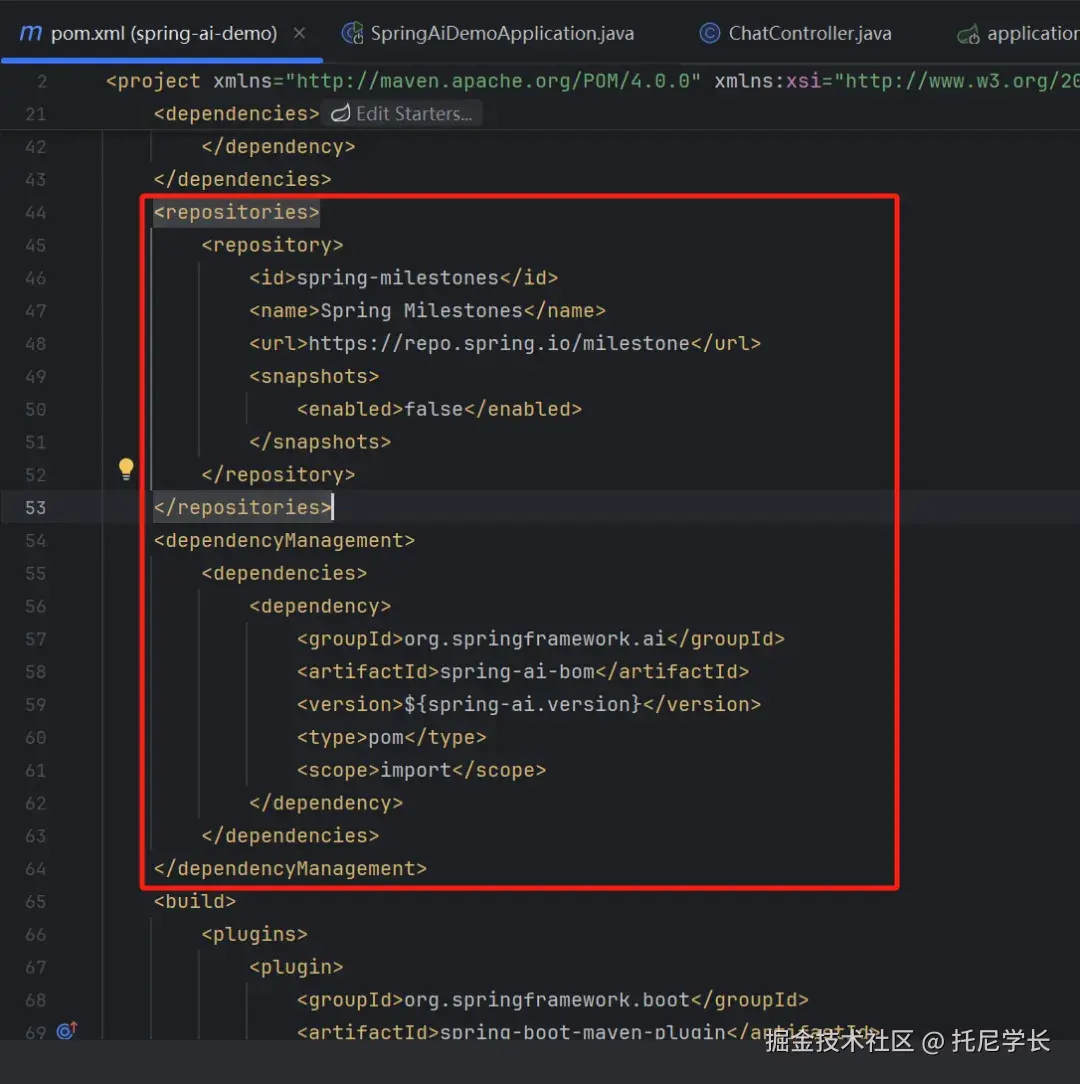

Controller类
实现具体的大模型调用。

启动类
访问结果

我们在跑通上面的代码后,就算完成了Spring AI的Hello World。
2、会话记忆
会话记忆(Conversational Memory)是Spring AI中非常好用的一个特性,可以使系统在对话过程中具有主动记录、理解和利用上下文信息的能力。
其核心目标是让AI能够像人类一样进行连贯、有逻辑的多轮交互,而非孤立地处理每一条用户输入。
我们继续在刚才的代码中进行实现。
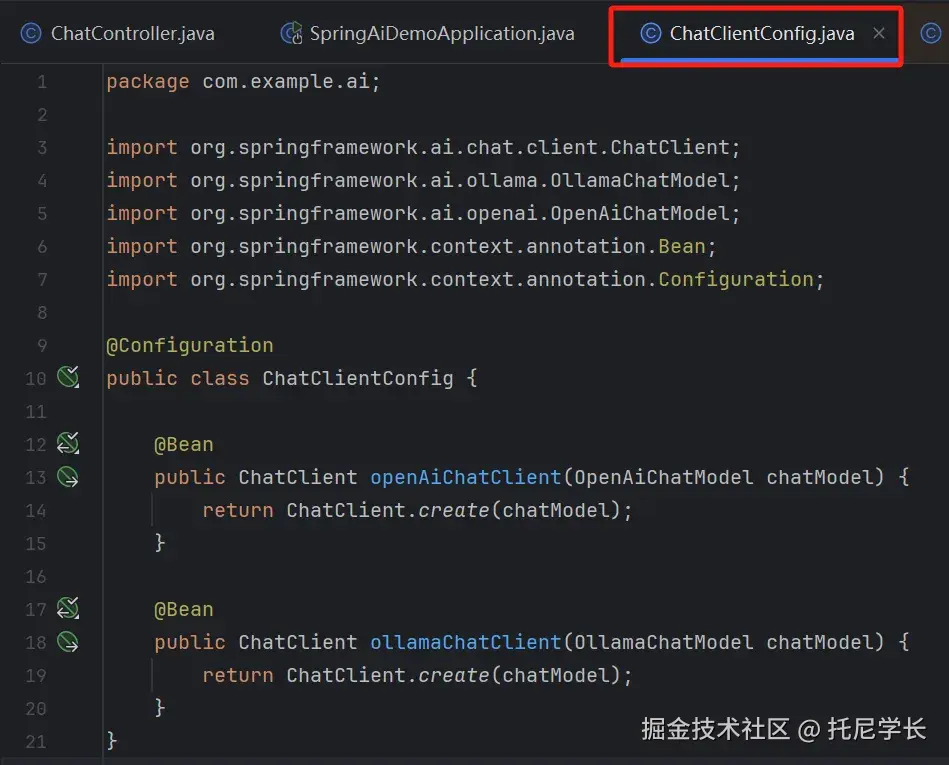
配置类及配置文件在这里需要引入会话记忆的依赖,默认以内存的方式进行存储实现。
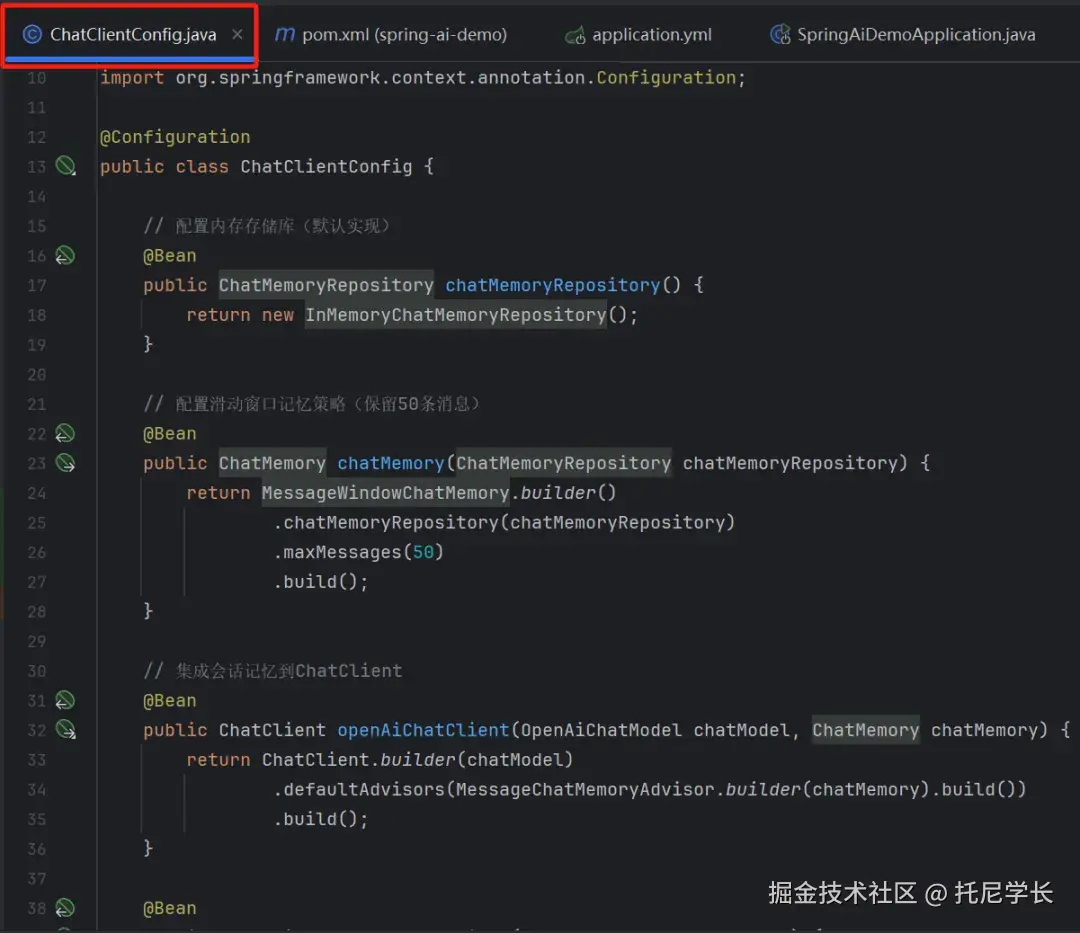
Controller类
新增了一个completionMemory方法进行实验,这里需要新增一个conversationId(会话ID),用于会话串联并记忆。
访问结果
1、我们首先输入问题"托尼学长是谁",并把会话ID设置为1。

2、接下来,我们输入问题"我刚才输入的是什么",会话ID还是设置为1。
果然,大模型进行了正确的解答,证明我们的会话记忆功能跑通了。

3、然后我们再做一次实验,输入的问题还是"我刚才输入的是什么",但把会话ID设置为2。从返回结果上来看,当会话ID变更之后,就无法实现会话记忆了。

除了内存之外,Spring AI还提供了MySQL、PostgreSQL、Cassandra、Neo4j等方式进行存储,我们可以根据业务特性进行灵活选择。
3、提示词工程
在Spring AI中,提示词工程(Prompt Engineering)是连接人类意图与 AI 模型的核心桥梁,简单说就是通过精心设计输入给 AI 的指令(提示),让模型更精准地输出符合预期的结果。
做个比较形象的比喻,相当于把广东人说的粤语,转化为全国人民都通俗易懂的普通话。
提示工程的目标包括:
-
明确任务意图(问答、总结、生成代码)
-
控制输出格式(JSON、表格、列表)
-
减少幻觉(模型生成错误信息)
-
适配特定领域(医疗、法律、金融等)
我们继续通过代码实现一个简单的Demo。
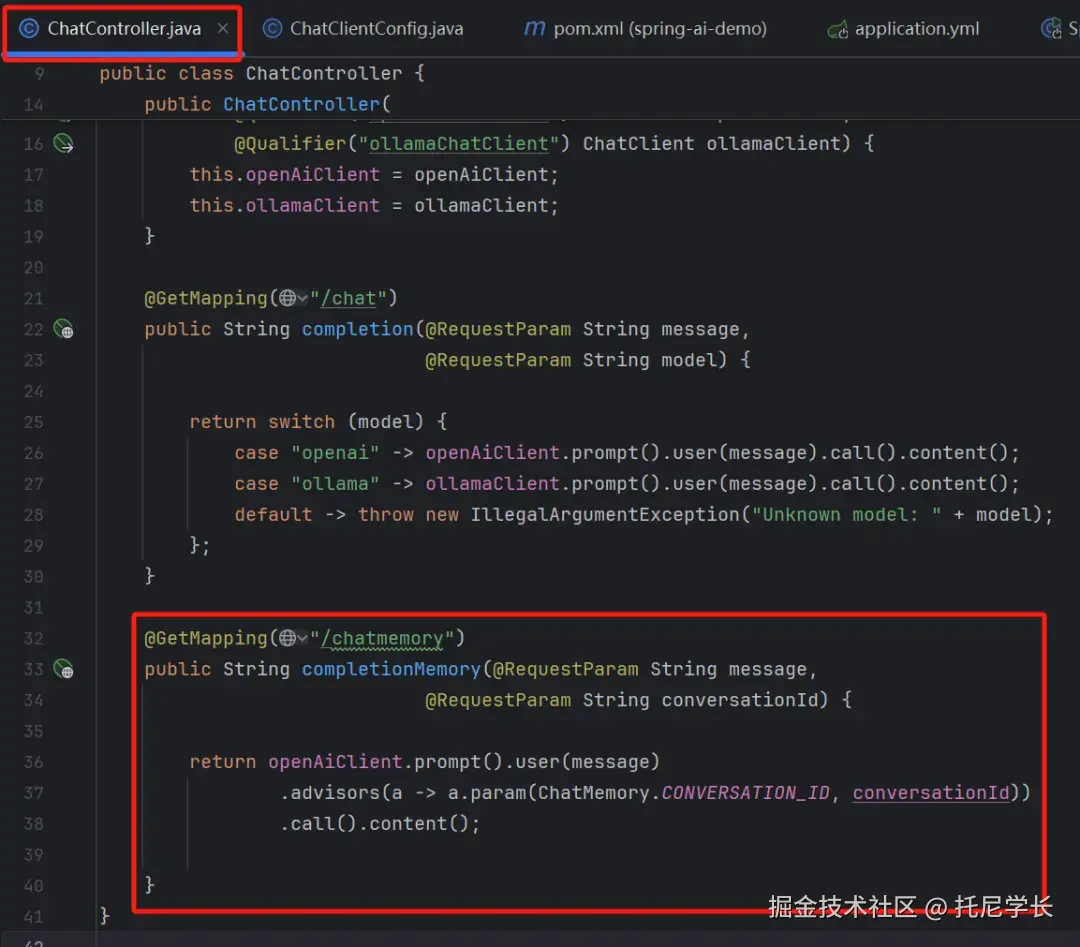
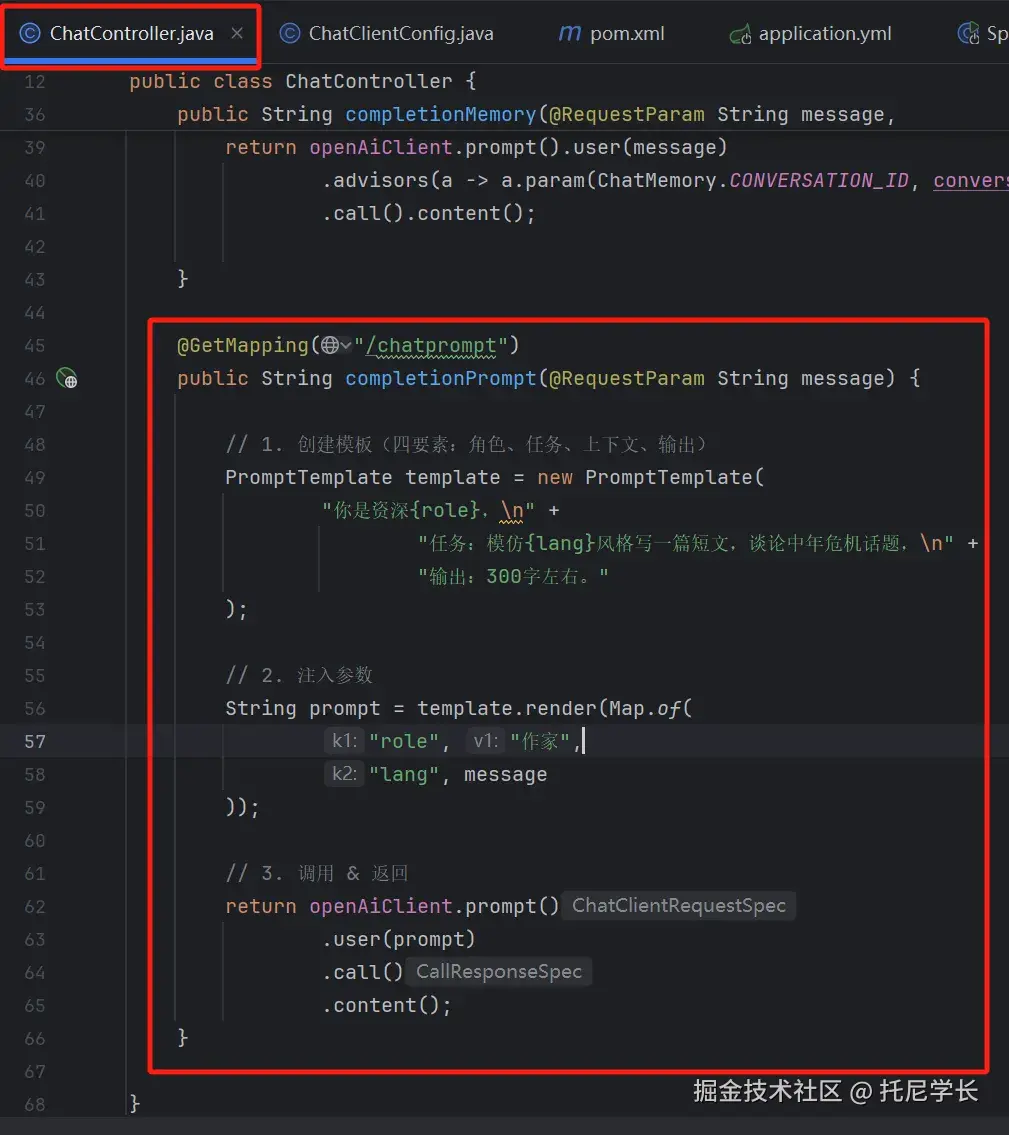
Controller类
新增了一个completionPrompt方法进行实验,该方法中共有三个步骤。
1、先创建一个提示词模板,需要满足四要素:角色、任务、上下文和输出。
2、注入可变的参数。
3、调用大模型并返回结果。
访问结果
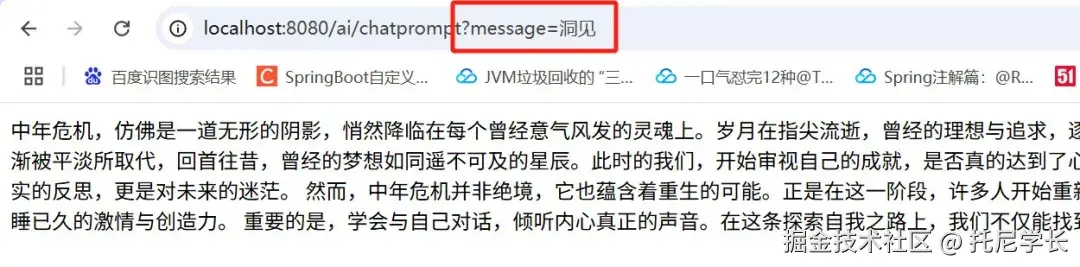
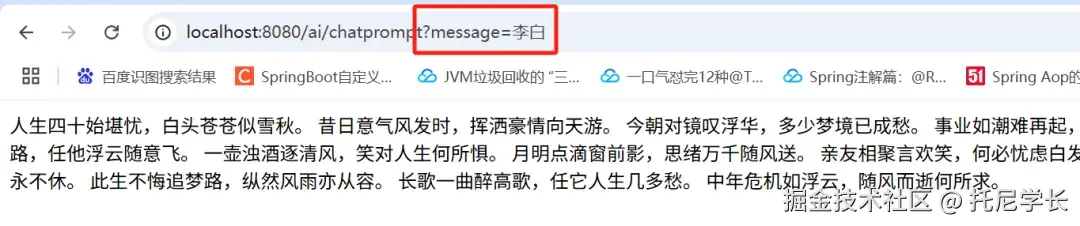
1、我们首先输入参数为"洞见",返回结果是一篇现代文。
2、接下来我们输入的参数为"李白",返回结果变成了一篇文言文。
结语
本篇文章我们先介绍到这里,后续我们会继续介绍Spring AI的RAG、多模态、MCP、向量存储等相关内容。btw:本文中的上述代码均已跑通,过程中由于版本问题踩了很多坑,耽误了很多时间,有需要的同学可以私我领取工程文件。