🔗从BERT到T5:为什么说T5是NLP的"大一统者"?
"翻译、分类、问答、摘要......能不能用一个模型搞定?"
Google 的 T5(Text-to-Text Transfer Transformer) 给出了肯定答案。
在上一篇文章中,我们介绍了以 BERT 为代表的 Encoder-Only 模型,它们擅长"理解语言",但在"生成语言"上力不从心。
而今天要讲的 T5 ,则融合了 Encoder + Decoder 的完整 Transformer 架构,并提出一个颠覆性的理念:
🌟 所有 NLP 任务,都可以统一为"文本到文本"的转换问题。
这不仅是架构的升级,更是一次范式的革命。
🧩 一、为什么需要 Encoder-Decoder 架构?
在讲 T5 之前,我们先回顾一下三种主流架构的"分工":
| 架构 | 代表模型 | 擅长任务 | 局限 |
|---|---|---|---|
| Encoder-Only | BERT | 文本理解(分类、NER) | 无法生成文本 |
| Decoder-Only | GPT | 文本生成(写作、对话) | 无法双向理解 |
| Encoder-Decoder | T5 | 理解 + 生成 | 结构更复杂 |
- BERT 只能"读",不能"写";
- GPT 只能"写",且是单向"从左到右"地写;
- 而 T5,既能"读"又能"写",真正实现了"理解后生成"。
✅ 类比:
- BERT 是"阅读理解专家"
- GPT 是"小说作家"
- T5 是"既能读题又能答题的全能考生"
🚀 二、T5 是谁?一句话介绍
T5(Text-to-Text Transfer Transformer) 是 Google 在 2019 年提出的预训练模型,其核心思想是:
🎯 把所有 NLP 任务,都变成"输入一段文本,输出一段文本"的形式。
无论是分类、翻译、摘要,还是问答、纠错,统统都用"文本 → 文本"的方式处理。
这让 T5 成为了 NLP 领域第一个真正意义上的 "任务统一者"。
🏗 三、模型架构:Encoder + Decoder 的完整体
T5 采用了标准的 Transformer Encoder-Decoder 架构,但做了多项优化。
python
Input Text → Tokenizer → Encoder → Decoder → Output TextT5详细架构如下:
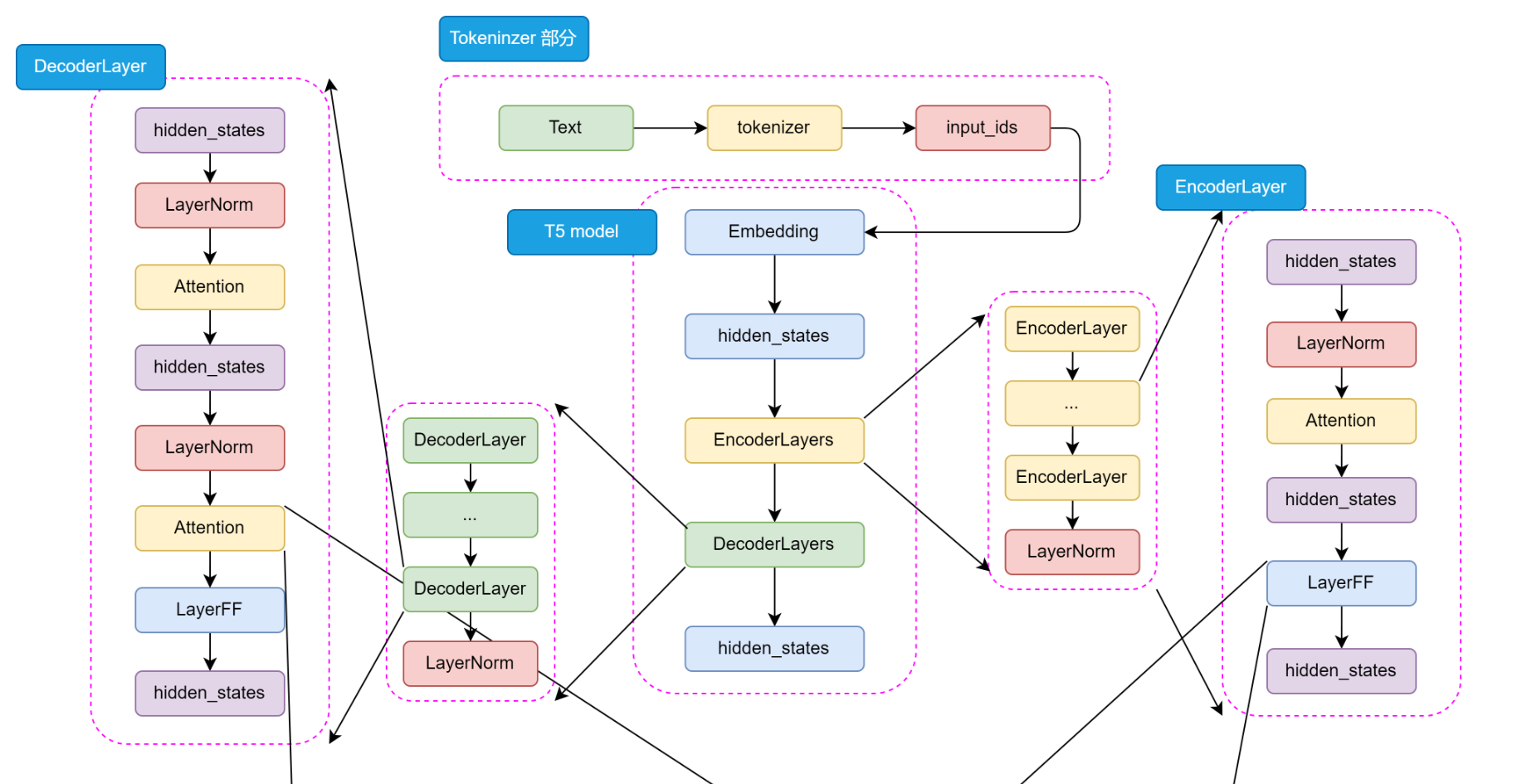
📌 1. Encoder(编码器)
- 负责"理解"输入文本
- 使用 多层 Self-Attention 提取语义
- 输出:输入文本的深层语义表示
📌 2. Decoder(解码器)
- 负责"生成"输出文本
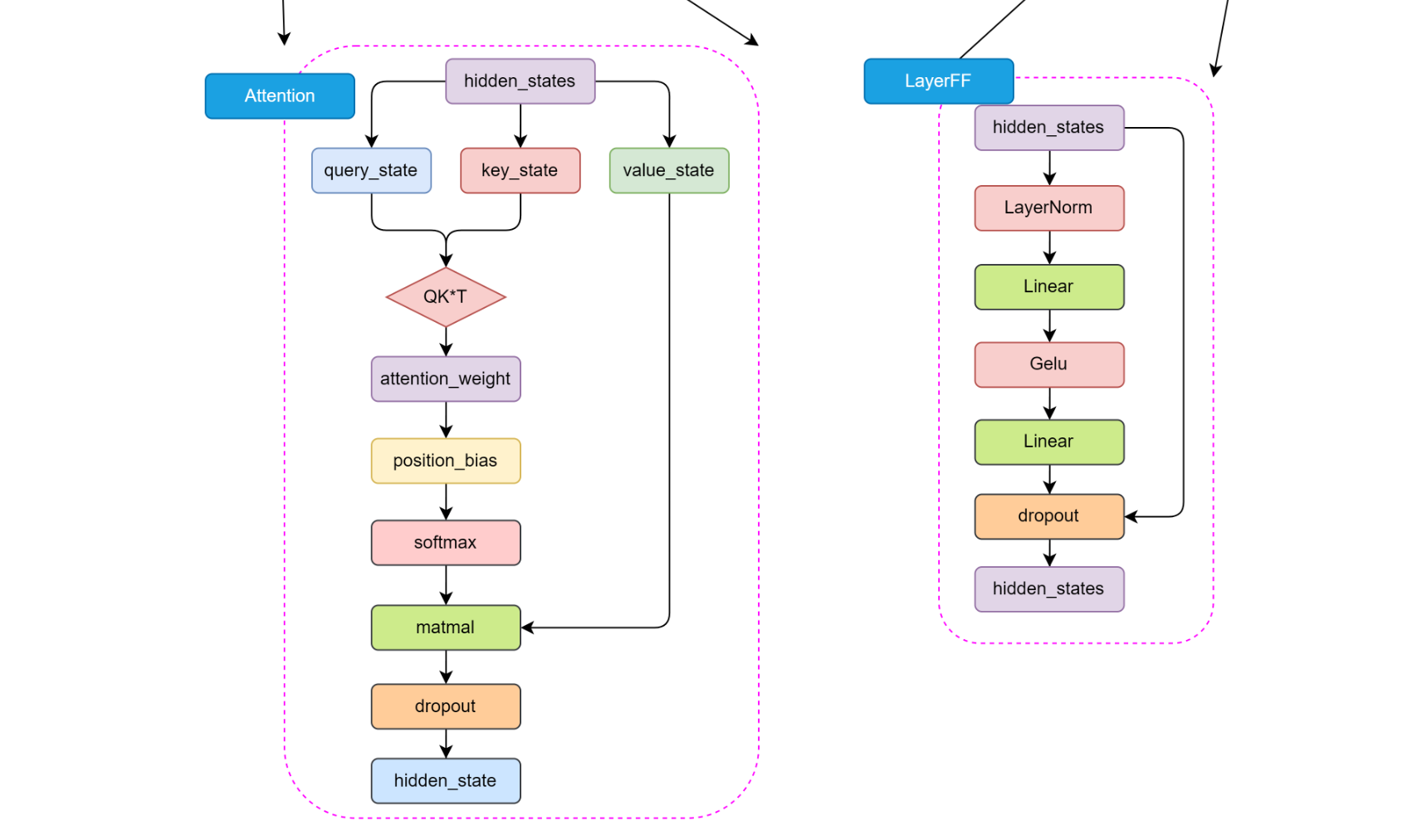
- 包含:
- Masked Self-Attention:防止"偷看未来"
- Encoder-Decoder Attention:将 Encoder 的理解结果作为"知识库"来参考
- 前馈网络 + RMSNorm
🔍 RMSNorm 是什么?
T5 用 RMSNorm (Root Mean Square Layer Normalization)替代了传统的 LayerNorm。
它只对激活值的均方根进行归一化,参数更少,训练更稳定,尤其适合大模型。
数学公式:
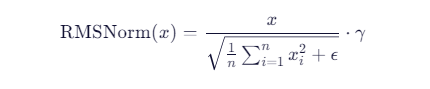
其中 γ 是可学习的缩放参数,ϵ 是防止除零的小常数。
📌 3. Tokenizer:使用 SentencePiece
T5 使用 SentencePiece + BPE 算法进行分词,词表大小为 32K,支持多语言。
✅ 优势:无需依赖空格,能处理中文、日文等无空格语言。
🎯 四、预训练任务:MLM 的升级版
T5 的预训练任务本质上是 MLM(掩码语言模型),但形式更灵活。
✅ 具体做法:
- 在输入文本中随机遮蔽 15% 的 token
- 将被遮蔽的 token 片段拼接成"目标序列"
- 训练模型:输入完整文本(带遮蔽符),输出被遮蔽的内容
📌 例如:
- 输入:
The [MASK] jumps over the [MASK].- 输出:
cat dog
这种任务也被称为 "填空式生成",既训练了理解能力,也训练了生成能力。
📊 预训练数据:C4 数据集
T5 使用了 C4(Colossal Clean Crawled Corpus) ,一个从 Common Crawl 中清洗出的 750GB 英文文本,包含:
- 维基百科
- 新闻文章
- 书籍
- 网页内容
数据经过严格清洗:去广告、去重复、去低质量文本。
✅ 规模:远超 BERT 的 13GB,为模型提供了更丰富的语言知识。
🌍 五、核心思想:NLP 大一统(Text-to-Text)
这是 T5 最革命性的创新!
❓ 传统做法 vs T5 做法
| 任务 | 传统做法 | T5 做法 |
|---|---|---|
| 情感分类 | 输入句子,输出标签 positive/negative |
输入:classify: I love this movie,输出:positive |
| 机器翻译 | 输入英文,输出法文 | 输入:translate English to French: How are you?,输出:Comment ça va? |
| 文本摘要 | 输入长文,输出摘要 | 输入:summarize: ...,输出:short summary |
| 问答系统 | 输入问题+段落,输出答案 | 输入:question: Who is the president? context: ...,输出:Joe Biden |
✅ 统一格式 :
[任务前缀]: [输入]→[输出]
🧠 大一统的三大优势
| 优势 | 说明 |
|---|---|
| 1. 模型统一 | 一个模型处理所有任务,无需为每个任务设计不同结构 |
| 2. 训练统一 | 所有任务都用"文本生成"方式训练,代码和流程完全一致 |
| 3. 微调灵活 | 下游任务只需改输入前缀,无需修改模型结构 |
💡 类比:
以前每个任务都要"定制APP",
现在只需要一个"超级APP",换一下"输入指令"就能切换功能。
📈 六、T5 的版本与性能
Google 发布了多个版本的 T5:
| 版本 | 参数量 | 性能 |
|---|---|---|
| T5-Small | 60M | 快速实验 |
| T5-Base | 220M | 平衡选择 |
| T5-Large | 770M | 强大性能 |
| T5-3B | 3B | 接近 GPT-2 |
| T5-11B | 11B | 当时最大模型之一 |
🏆 在 GLUE、SuperGLUE、SQuAD 等多个榜单上,T5-large 和 T5-11B 都取得了 SOTA 成绩。
🔍 七、T5 的启示:NLP 的未来方向
T5 的成功告诉我们:
-
任务形式比模型结构更重要
统一输入输出格式,极大提升了模型的通用性。
-
预训练数据的质量和规模至关重要
C4 的清洗策略为后续大模型数据处理提供了范本。
-
生成式建模范式更具扩展性
即使是分类任务,也可以用"生成标签"的方式处理,为 LLM 时代铺平道路。
🆚 八、T5 vs BERT vs GPT:三巨头对比
| 特性 | BERT | GPT | T5 |
|---|---|---|---|
| 架构 | Encoder-Only | Decoder-Only | Encoder-Decoder |
| 任务形式 | 分类/标注 | 生成 | 文本到文本 |
| 预训练任务 | MLM + NSP | LM | MLM(生成式) |
| 是否统一任务 | ❌ | ❌ | ✅ |
| 能否生成文本 | ❌ | ✅ | ✅ |
| 能否双向理解 | ✅ | ❌ | ✅ |
✅ T5 = BERT 的理解力 + GPT 的生成力 + 任务统一性
📣 结语:T5 是 LLM 时代的"先驱者"
虽然如今 GPT 系列大红大紫,但 T5 的思想影响深远:
- 它证明了:一个模型可以通吃所有 NLP 任务
- 它启发了:后续的 FLAN-T5、UL2 等模型,进一步强化"指令微调"和"多任务学习"
- 它预示了:LLM 的本质,就是"文本到文本"的超级转换器
🔁 所以,要理解现代大模型,你必须读懂 T5。
📚 参考资料:
- 《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
- T5 GitHub: https://github.com/google-research/text-to-text-transfer-transformer
- C4 数据集: https://www.tensorflow.org/datasets/catalog/c4
- GitHub - datawhalechina/happy-llm: 📚 从零开始的大语言模型原理与实践教程