mindspore的Print算子有两种模式,一种是直接打屏,还有一种是数据落盘,保存到二进制文件中
默认打印在屏幕上。也可以保存在文件中,通过context设置print_file_path参数。
一旦设置,输出将保存在指定文件中。通过函数 mindspore.parse_print() 可以重新加载数据。
而且print_file_path只在Ascend上设置生效
1. 保存print的数据到文件中
关键的代码为:
ini
context.set_context(print_file_path=print_file)
python
from mindspore import nn
from mindspore.ops import operations as ops
from mindspore import Tensor
import numpy as np
from mindspore import context
from mindspore.train.serialization import parse_print
print_file = "kkkk.log"
context.set_context(print_file_path=print_file)
class PrintDemo(nn.Cell):
def __init__(self):
super(PrintDemo, self).__init__()
self.print = ops.Print()
def construct(self, x, y):
self.print('Print Tensor x and Tensor y:', x, y)
return x
x = Tensor(np.ones([2, 1]).astype(np.int32))
y = Tensor(np.ones([2, 2]).astype(np.int32))
net = PrintDemo()
result = net(x, y) 2. 通过parse_print接口,读取保存的数据
关键代码为:
ini
file = parse_print(print_file)
python
from mindspore import nn
from mindspore.ops import operations as ops
from mindspore import Tensor
import numpy as np
from mindspore import context
from mindspore.train.serialization import parse_print
print_file = "kkkk.log"
file = parse_print(print_file)
print("kkkk0", file[0])
print("kkkk1", file[1])
print("kkkk2", file[2]) 两个不能放在同一个文件中执行,若是放在一个文件中执行,读取的时候会报错,说没有数据
保存的文件是下面这样的:

可以从代码中看到,保存的有三个数据,一个字符串,两个Tensor
打印出来的保存数据形式为:
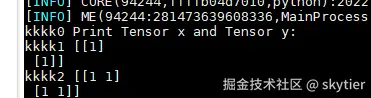
这种保存方式,可以在调试数据大的时候使用