为什么搜索总是不懂你的心?
你是不是也有这种经历?在电商平台上搜索"轻薄笔记本",系统却推荐你"笔记本纸"。
这就像你对暗恋对象说:"我喜欢听你说话",结果对方回答:"哦,我也喜欢听歌"。两个人说的都是中文,却完全不在一个频道上。
或者更惨的是,你问智能客服:"我的订单什么时候能到?",它回答:"您好,欢迎选购更多商品!"这就像你问朋友:"我看起来胖了吗?"朋友回答:"今天天气真好!"------经典的鸡同鸭讲。
为什么会这样?因为传统搜索只会"看字面",不会"懂含义"。
但是等等...如果电脑能像人类一样理解语言的含义呢?这就是今天我们要聊的主角------「嵌入模型」和「向量化技术」。
没听说过?没关系!想学RAG(检索增强生成)技术,却不了解这两个概念,就像想做厨师却不知道刀该怎么用。你可能做出食物,但绝不会是美食!
向量化:把人类语言翻译成机器的"星际语"
人类语言vs机器语言:一场跨物种的沟通
你有没有想过,为什么你能秒懂"我肚子饿了"这句话,而电脑却需要把它变成一串数字才能处理?
就像这样:0.2, -0.1, 0.8, ..., 0.3
没错,这串看似随机的数字,在机器眼中就是"我肚子饿了"这句话的"灵魂"。这个神奇的转换过程,就叫做"「向量化」"。

图1:文本向量化的魔法转换过程
这就像把一首诗翻译成了外星人的语言。看起来是乱码,但只要知道翻译规则,就能完美传递原意。
为什么普通搜索像"脸盲",而向量搜索像"识人精"?
传统的关键词搜索就像一个严重"脸盲"的人:
「脸盲者」 :"嘿,你是张三吗?" 「路人」 :"不,我是李四。" 「脸盲者」:"但你也姓'李'啊,那你一定是李三!"
荒谬吧?但这就是关键词搜索的逻辑------只认字面,不认人。
而向量搜索则像是社交达人,不仅认识你,还知道你的喜好、习惯和说话方式。它不是看你"长什么样"(字面),而是理解你"是什么样的人"(语义)。
比如"苹果"这个词:
- "我想吃个新鲜的苹果" → 向量会靠近水果、食物
- "我想买个新款苹果手机" → 向量会靠近电子产品、科技
同一个词,不同的向量。这就像双胞胎虽然长得一样,但一个可能是医生,一个可能是歌手,完全不同的"人设"。
向量化与嵌入模型:完美灵魂伴侣的奇妙关系
揭秘天作之合的神奇伴侣
如果你一直弄不清"向量化"和"嵌入模型"的关系,别担心,你不是一个人!
让我给你一个绝对通俗的解释:
- 「向量化」:是把文字变成数字的**「过程」**(就像"烹饪")
- 「嵌入模型」:是执行这个过程的**「工具」**(就像"厨师")
太抽象?那我们来点更生活化的:
向量化就像是把食材变成美食的过程,而嵌入模型就是厨师。不同的厨师(嵌入模型)有不同的烹饪风格和专长,做出来的菜(向量)自然也有差别。
有的厨师擅长川菜(某些嵌入模型更擅长处理中文),有的擅长法餐(某些模型更适合学术文本)。选择什么样的厨师,取决于你想吃什么菜!
嵌入模型:文本世界的"心灵捕手"
嵌入模型到底是什么神奇生物?它其实就是一个经过海量文本训练的AI,能够理解词语之间微妙的语义关系。
「嵌入模型的工作三步法」:
- 「学习阶段」:模型疯狂"阅读"全网文章(想象一个书呆子连续读了10年的书)
- 「编码阶段」:当我们输入文本时,它根据"阅读经验"将其转换为数字向量
- 「应用阶段」:用这些向量计算相似度,找到真正相关的内容

图2:嵌入模型的幕后工作流程
优秀的嵌入模型能够做到:
- 理解同义词("电影"和"电影院"不是一回事)
- 分辨一词多义("苹果"是水果还是手机要看上下文)
- 理解语境差异("这真好吃"和"这真难吃"虽然只差一个字,但意思完全相反)
嵌入模型选手大乱斗:谁才是真正的王者?
嵌入模型市场鱼龙混杂,该怎么选?想象一下你在挑选智能手机:
「OpenAI的Embedding API」:就像最新款的iPhone Pro Max。功能强大,体验顺滑,就是...有点小贵。支持100多种语言,是商用RAG系统的"网红"选择。
使用它就像叫专车一样,服务好,但价格也不菲:
图3:使用OpenAI的API时你的钱包变化
一个简单API调用就能获得高质量向量,但每月账单可能让你惊叹:"我就是问了几个问题啊?"
「中文嵌入模型」:国货之光闪亮登场!
如果你主要处理中文内容,那**「text2vec」和「BGE」**(BAAI General Embedding)模型就像是专门为你打造的家乡菜。它们对中文的理解就像北京人对胡同的熟悉,拐弯抹角也不会迷路。
而且,BGE还能处理中英文混合的"中式英语",就像那些在国际学校长大的孩子,中英文随意切换。最重要的是,这些模型通常可以私有部署,没有API调用费用,适合"穷开发"。
如何选择嵌入模型?
选择嵌入模型就像选择约会对象,需要考虑以下几点:
- 「语言匹配度」:TA懂你说的语言吗?(主要处理什么语言内容)
- 「理解深度」:TA能理解你的冷笑话吗?(语义理解的精确度)
- 「经济实力」:你的钱包能养得起TA吗?(使用成本)
- 「反应速度」:TA回消息快吗?(推理速度)
- 「隐私要求」:你们需要多私密的空间?(是否需要私有部署)
记住,没有最好的嵌入模型,只有最适合你需求的那个。就像没有最好的交通工具,只有最适合当前出行需求的那一种。
向量数据库:向量的"快闪社交俱乐部"
为什么普通数据库搞不定向量?
想象一个场景:你有100万个向量,每个向量有1536个维度(就是1536个数字),你需要在0.1秒内找出与某个向量最相似的前10个。
用传统方式?那就像在装满沙子的海滩上找10颗特定的沙粒,而且不能用筛子,只能一粒粒比较!别说0.1秒,0.1年都悬...
向量数据库就是为解决这个问题而生的特种部队,它使用特殊索引算法(如HNSW、IVF),可以在眨眼间完成看似不可能的任务。
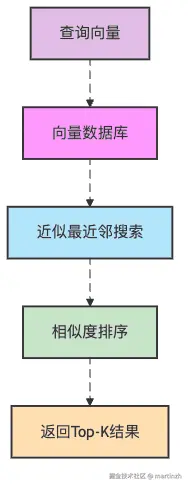
图4:向量数据库的闪电搜索魔法
Chroma:新手友好的"入门款"
Chroma是向量数据库界的"米其林三轮车"------结构简单,操作容易,初学者秒上手。它直接作为Python库集成到项目中,不需要额外的服务器或复杂配置。
ini
# 你没看错,创建向量数据库真的只需要这几行代码
import chromadb
# 创建客户端
client = chromadb.Client()
# 创建集合(想象成一个向量的专属文件夹)
collection = client.create_collection("my_collection")
# 添加文档向量(放入文档和对应的向量)
collection.add(
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 1.2]], # 向量
documents=["这是第一个文档", "这是第二个文档"], # 原文本
ids=["id1", "id2"] # 唯一ID
)
# 查询相似文档(找相似的内容)
results = collection.query(
query_embeddings=[1.1, 2.3, 3.2], # 查询向量
n_results=2 # 要找几个
)看!这么简单!比做一碗泡面还简单(泡面至少要等3分钟)。
Chroma就像是那种"麻雀虽小五脏俱全"的工具,麻雀大小,也能唱出好歌。它非常适合入门学习和中小型项目。当然,如果你要处理亿级数据,可能就需要考虑更专业的向量数据库了。
但对于大多数RAG应用场景,特别是个人项目和中小型应用,Chroma就像家用轿车,足够把你从A点送到B点了。
从"假聪明"到"真聪明":向量化改造计划
智能客服小明的华丽转身
小明是某电商平台的智能客服,让我们看看他的进化史:
「小明1.0版」(关键词匹配):
「用户」 :我的订单显示已发货,但我还没收到,怎么办?
「小明1.0」:关于"订单"的问题,您可以点击"我的订单"查询状态。关于"发货"的问题,一般发货后1-3天送达。关于"收到"的问题...
(用户已崩溃)
「小明2.0版」(向量搜索升级):
「用户」 :我的包裹还在路上吗?都过了三天了。
「小明2.0」:您好,我看到您最近有一个订单#123456,已于3天前发出。根据物流信息,包裹在昨晚到达了您所在城市的配送中心,预计今天下午送达。您可以通过物流单号XXXXXXX查看实时位置。需要我帮您催一下快递员吗?
看出区别了吗?
小明1.0就像只会按图索骥的机器人,而小明2.0则理解了问题背后的意图。这就是向量化的魔力------它让AI有了"理解"的能力。
实战案例:打造智能电商客服
让我们一起来看一个实际案例,如何用向量化技术打造一个智能电商客服。不要担心,我会用最简单的方式解释。
步骤1:收集知识库
首先,我们需要收集电商平台的各种信息:商品描述、FAQ、退换货政策等。这就像给AI准备"教科书"。
步骤2:切碎知识(文档分割)
接着,我们把长文档切成小段落。为什么?因为太长的文档不容易精准匹配,就像你问"如何退货",不需要返回整个"用户服务条款"。
步骤3:向量化(请出嵌入模型)
然后,用嵌入模型把这些文本段落转换成向量。这相当于给每段文本生成了一个"数学指纹",独一无二,便于比对。
步骤4:存入向量数据库
将这些向量和原文本一起存入Chroma向量数据库,建立索引,随时待命。
步骤5:查询处理
当用户问问题时:
- 用同一个嵌入模型将问题也转换为向量
- 在向量数据库中搜索最相似的文本段落(相似的向量)
- 将找到的相关文本作为上下文,让大语言模型生成回答
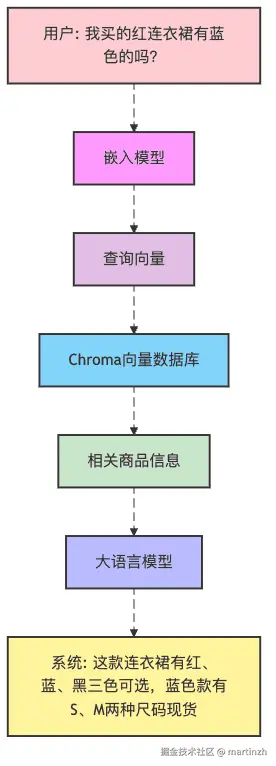
图5:智能客服系统的魔法流程
效果震撼对比
「传统搜索」:
- 用户:"有没有类似这条裙子但是蓝色的款式?"
- 系统:"对不起,我不理解您的问题,请告诉我具体商品编号。"
「向量搜索」:
- 用户:"有没有类似这条裙子但是蓝色的款式?"
- 系统:"您好!这款V领连衣裙确实有蓝色款式。蓝色款式比红色款多了蕾丝边设计,目前S码和M码有现货,L码需要预订。要查看蓝色款式的图片吗?"
差别就像是跟机器人对话,和跟一个真正懂你的店员对话的区别!
结语:向量化与嵌入模型,RAG系统的灵魂伴侣
向量化和嵌入模型就像RAG系统的灵魂伴侣,缺一不可:
- **「向量化」**是目标------将人类语言转换为机器可理解的数学表示
- **「嵌入模型」**是实现这一目标的工具------决定了向量质量的好坏
它们的关系就像一辆车:向量化是你想去的方向,嵌入模型是发动机,决定了你能跑多快、多稳。没有方向,有再好的发动机也是原地打转;没有发动机,知道方向也只能望路兴叹。
在实际应用中,向量质量的好坏直接决定了RAG系统的智商高低。选择合适的嵌入模型和向量数据库,就像选择称手的厨具,是做出美味AI应用的关键。
下次当你使用各种"智能"服务时,别忘了在背后默默工作的向量化技术和嵌入模型。它们就像数字世界的翻译官,帮助机器理解我们人类复杂的语言和微妙的情感。
记住:在RAG的世界里,没有向量化和嵌入模型,就没有真正的"智能"!