论文阅读:VGGT: Visual Geometry Grounded Transformer
今天介绍一篇 CVPR 2025 的 best paper,这篇文章是牛津大学的 VGG 团队的工作,主要围绕着 3D 视觉中的各种任务,这篇文章提出了一种多任务统一的架构,实现一次输入,同时预测多个任务,包括相机参数,点图,深度图以及相机轨迹。
Abstract
我们提出了 VGGT,这是一种前馈神经网络,能够从一个、几个或数百个场景视图中直接推断出场景的所有关键 3D 属性,包括相机参数、点图、深度图和 3D 点轨迹。在 3D 计算机视觉领域,模型通常受限于单一任务并针对其进行专门优化,而该方法则是这一领域的一项进步。它还具备简单高效的特点,重建图像的时间不到一秒,且性能仍优于那些需要借助视觉几何优化技术进行后处理的替代方案。该网络在多项 3D 任务中均取得了最先进的成果,包括相机参数估计、多视图深度估计、密集点云重建以及 3D 点跟踪。我们还表明,将预训练的 VGGT 用作特征骨干网络,能显著提升下游任务的性能,例如非刚性点跟踪和前馈新视图合成。

- 图 1 VGGT 是一个大型前馈 Transformer,其 3D 归纳偏差极少,训练所用数据为大量带 3D 标注的数据集。该模型可接收多达数百张图像,能在不到一秒的时间内一次性为所有图像预测出相机参数、点图、深度图和点轨迹,且在无需进一步处理的情况下,性能往往优于基于优化的同类方法。
Introduction
我们研究的问题是:利用前馈神经网络对一组图像所捕捉场景的 3D 属性进行估计。传统上,3D 重建采用视觉几何方法,借助如光束平差法(Bundle Adjustment, BA)33 等迭代优化技术。机器学习在其中常发挥重要的补充作用,用于解决仅靠几何无法完成的任务,例如特征匹配和单目深度预测。两者的融合日益紧密,如今像 VGGSfM 83 这类最先进的运动恢复结构(Structure-from-Motion, SfM)方法,通过可微分 BA 将机器学习与视觉几何进行端到端结合。即便如此,视觉几何在 3D 重建中仍占据主导地位,这无疑增加了重建过程的复杂性与计算成本。
随着神经网络的性能愈发强大,我们不禁提出疑问:3D 任务是否终于可以由神经网络直接完成,从而几乎完全避开几何后处理步骤?诸如 DUSt3R 87 及其改进版本 MASt3R 43 等近期研究成果已在这一方向上展现出了良好前景,但这些网络一次仅能处理两张图像,且若要重建更多图像,仍需依赖后处理步骤对成对重建结果进行融合。
在本文中,我们朝着进一步迈向消除 3D 几何后处理优化需求的目标。为此,我们提出了视觉几何基础 Transformer(VGGT)------ 一种前馈神经网络,能够从一个、几个乃至数百个场景输入视图中完成 3D 重建。VGGT 可预测全套 3D 属性,包括相机参数、深度图、点图和 3D 点轨迹。它通过单次前向传播在数秒内即可完成这一过程。值得注意的是,即便不进行进一步处理,其性能也常常优于基于优化的替代方案。这与 DUSt3R、MASt3R 或 VGGSfM 形成了显著差异,后三者仍需要代价高昂的迭代后优化才能获得可用结果。
我们还表明,无需为 3D 重建专门设计特定网络。相反,VGGT 基于一个相当标准的大型 Transformer 79 构建,除了在逐帧注意力与全局注意力之间交替进行外,不存在特定的 3D 或其他归纳偏差,但其在大量带有 3D 标注的公开数据集上完成了训练。因此,VGGT 的构建模式与自然语言处理和计算机视觉领域的大型模型一致,例如 GPT 系列 1, 18, 101、CLIP 56、DINO 6, 53 以及 Stable Diffusion 22。这些模型已成为通用的骨干网络,通过微调便能解决新的特定任务。同样,我们发现 VGGT 计算得到的特征能显著提升下游任务的性能,如动态视频中的点跟踪以及新视图合成。
近期已有不少大型 3D 神经网络的实例,包括 DepthAnything 97、MoGe 86 以及 LRM 34 等。但这些模型仅聚焦于单一 3D 任务,例如单目深度估计或新视图合成。与之不同的是,VGGT 采用共享骨干网络,同步预测所有目标 3D 量。我们证明,尽管可能存在冗余信息,但通过学习预测这些相互关联的 3D 属性,整体精度反而得到了提升。同时我们发现,在推理阶段,可通过单独预测的深度图和相机参数推导得到点图,相较于直接使用专门的点图头,这种方式能获得更高的精度。
综上,我们的贡献如下:
- 提出了 VGGT------ 一种大型前馈 Transformer。给定一个、几个乃至数百张场景图像,它能在数秒内预测出场景的所有关键 3D 属性,包括相机内参和外参、点图、深度图以及 3D 点轨迹。
- 证实了 VGGT 的预测结果可直接使用,其性能极具竞争力,且通常优于采用慢速后处理优化技术的最先进方法。
- 研究实验发现,当进一步与 BA 后处理相结合时,VGGT 在各方面均能取得最先进的结果 ------ 即便与专注于部分 3D 任务的方法相比亦是如此,且往往能显著提升结果质量。
Method
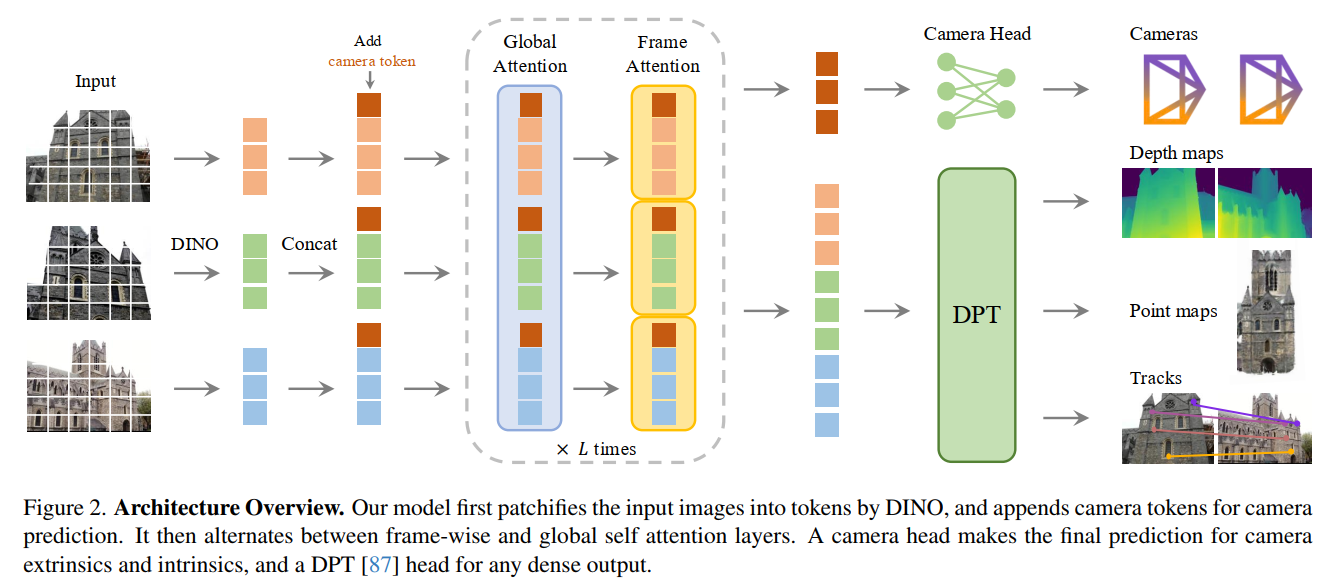
- 图 2 架构概述:我们的模型首先通过 DINO 将输入图像分割为tokens,并附加相机tokens以用于相机参数预测。随后,模型交替使用逐帧自注意力层和全局自注意力层。相机头负责最终预测相机外参和内参,而 DPT 头 87 则用于生成各类密集输出。
Problem definition and notation
输入为观测同一 3D 场景的 N 张 RGB 图像序列(Ii)i=1N(I_i)_{i=1}^N(Ii)i=1N,其中每张图像Ii∈R3×H×WI_i \in \mathbb{R}^{3 \times H \times W}Ii∈R3×H×W。VGGT 的 Transformer 是一个函数,它将该序列映射到对应的 3D 标注集,每帧对应一组标注:
f((Ii)i=1N)=(gi,Di,Pi,Ti)i=1N(1) f\left((I_i){i=1}^N\right) = (g_i, D_i, P_i, T_i){i=1}^N \tag{1} f((Ii)i=1N)=(gi,Di,Pi,Ti)i=1N(1)
因此,该 Transformer 将每张图像IiI_iIi映射至其相机参数gi∈R9g_i \in \mathbb{R}^9gi∈R9(内参和外参)、深度图Di∈RH×WD_i \in \mathbb{R}^{H \times W}Di∈RH×W、点图Pi∈R3×H×WP_i \in \mathbb{R}^{3 \times H \times W}Pi∈R3×H×W,以及一个C维特征网格 Ti∈RC×H×WT_i \in \mathbb{R}^{C \times H \times W}Ti∈RC×H×W 用于表示点的轨迹。
对于 相机参数 gig_igi,我们采用文献 83 中的参数化方式,令g=q,t,fg = q, t, fg=q,t,f,其中包含旋转四元数q∈R4q \in \mathbb{R}^4q∈R4、平移向量t∈R3t \in \mathbb{R}^3t∈R3以及视场角f∈R2f \in \mathbb{R}^2f∈R2,三者依次拼接构成 ggg。我们假设相机的主点位于图像中心,这在运动恢复结构(SfM)框架中是常见设定 63, 83。
我们将图像 IiI_iIi 的定义域记为 I(Ii)={1,...,H}×{1,...,W}I(I_i) = \{1, \ldots, H\} \times \{1, \ldots, W\}I(Ii)={1,...,H}×{1,...,W},即像素位置的集合。深度图 DiD_iDi 将每个像素位置 y∈I(Ii)y \in I(I_i)y∈I(Ii) 与从第 iii 个相机观测到的对应深度值 Di(y)∈R+D_i(y) \in \mathbb{R}^+Di(y)∈R+ 相关联。同样地,点图 PiP_iPi 将每个像素与对应的 3D 场景点 Pi(y)∈R3P_i(y) \in \mathbb{R}^3Pi(y)∈R3 相关联。重要的是,与 DUSt3R 87 中类似,点图具有视点不变性,即 3D 点 Pi(y)P_i(y)Pi(y) 是在第一个相机 g1g_1g1 的坐标系中定义的,我们将该坐标系作为世界参考坐标系。
最后,针对关键点 跟踪任务,我们采用 "跟踪任意点" 的方法(如 15, 39 所述)。具体而言,给定查询图像 IqI_qIq 中的一个固定查询图像点 yqy_qyq,网络会输出一条轨迹 T⋆(yq)=(yi)i=1NT^\star(y_q) = (y_i)_{i=1}^NT⋆(yq)=(yi)i=1N,该轨迹由所有图像 IiI_iIi 中对应的 2D 点 yi∈R2y_i \in \mathbb{R}^2yi∈R2 构成。
需要注意的是,上述 Transformer 函数 fff 并不直接输出轨迹,而是输出用于跟踪的特征 Ti∈RC×H×WT_i \in \mathbb{R}^{C \times H \times W}Ti∈RC×H×W。跟踪任务由一个独立模块完成(详见第 3.3 节),该模块实现函数T((yj)j=1M,(Ti)i=1N)=((y^j,i)i=1N)j=1MT\left((y_j){j=1}^M, (T_i){i=1}^N\right) = \left((\hat{y}{j,i}){i=1}^N\right)_{j=1}^MT((yj)j=1M,(Ti)i=1N)=((y^j,i)i=1N)j=1M。它接收查询点 yqy_qyq 以及 Transformer 函数 fff 输出的密集跟踪特征 TiT_iTi,进而计算出轨迹。Transformer 网络 fff 与跟踪模块 TTT 通过端到端的方式联合训练。
预测顺序:输入序列中图像的顺序是任意的,但需将第一张图像选定为参考帧。网络架构在设计上,除第一帧外,对其余所有帧均具有排列等变性。
过度完整预测 :值得注意的是,VGGT 所预测的所有量并非都是独立的。例如,正如 DUSt3R 87 所展示的那样,相机参数 ggg 可从具有不变性的点图 PPP 中推断得出 ------ 比如通过求解 nnn 点透视(Perspective-n-Point, PnP)问题 23, 42。此外,深度图也可由点图和相机参数推导得出。然而,正如我们在第 4.5 节中所展示的,即便这些量之间存在闭式关系,在训练阶段让 VGGT 明确预测上述所有量,仍能带来显著的性能提升。同时,在推理阶段观察到,将独立估计的深度图与相机参数相结合,相较于直接使用专门的点图分支,能生成更精确的 3D 点。
Feature Backbone
借鉴 3D 深度学习领域的近期研究成果 36, 87, 90,我们设计了一种架构简洁且 3D 归纳偏差极少的模型,让模型从大量带 3D 标注的数据中自主学习。具体而言,我们将模型 fff 实现为一个大型 Transformer 79。为此,首先通过 DINO 53 将每张输入图像 III 分割为一组包含 KKK 个 tokens 的集合 tI∈RK×Ct_I \in \mathbb{R}^{K \times C}tI∈RK×C。随后,来自所有帧的图像tokens组合集(即tI=∪i=1N{tIi}t_I = \cup_{i=1}^N \{t_{I_i}\}tI=∪i=1N{tIi})将通过主网络结构进行处理,该过程会交替使用逐帧自注意力层和全局自注意力层。
交替注意力机制 :我们对标准 Transformer 设计稍作调整,引入了交替注意力(Alternating-Attention, AA)机制,使 Transformer 能够以交替方式聚焦于单帧内部和全局范围。具体而言,逐帧自注意力单独关注每个帧内的 tokens tIkt_{I_k}tIk,而全局自注意力则联合关注所有帧的 tokens tIt_ItI。这在整合不同图像信息与标准化单张图像内 tokens 激活值之间取得了平衡。默认情况下,我们采用 24 层(L=24L=24L=24)全局和逐帧注意力层。我们的实验证明这种交替注意力架构能带来显著的性能提升。需要注意的是,我们的架构未使用任何交叉注意力层。
Prediction heads
下面我们将阐述函数 fff 如何预测相机参数、深度图、点图和点轨迹。首先,对于每张输入图像IiI_iIi,我们在其对应的图像 tokens tIit_{I_i}tIi基础上,增加一个额外的相机tokens tig∈R1×C′t_{i}^{g} \in \mathbb{R}^{1 \times C'}tig∈R1×C′ 和四个配准tokens 10 tiR∈R4×C′t_{i}^{R} \in \mathbb{R}^{4 \times C'}tiR∈R4×C′。随后,将 (tiI,tig,tiR)i=1N(t_{i}^{I}, t_{i}^{g}, t_{i}^{R}){i=1}^N(tiI,tig,tiR)i=1N的拼接结果输入交替注意力(AA)Transformer,得到输出tokens (t^Ii,t^gi,t^Ri)i=1N(\hat{t}{I_i}, \hat{t}{g_i}, \hat{t}{R_i}){i=1}^N(t^Ii,t^gi,t^Ri)i=1N。这里,第一帧的相机 tokens 和配准 tokens(t1g:=tˉgt{1}^{g} := \bar{t}^{g}t1g:=tˉg,t1R:=tˉRt_{1}^{R} := \bar{t}^{R}t1R:=tˉR)被设置为一组独特的可学习tokens tˉg\bar{t}^{g}tˉg、tˉR\bar{t}^{R}tˉR,而其他所有帧的相机 tokens 和配准 tokens 则为另一组可学习tokens,二者并不相同。这一设计使模型能够区分第一帧与其他帧,并在第一个相机的坐标系中表示 3D 预测结果。需要注意的是,经过优化的相机 tokens 和配准 tokens 现在具有帧特异性,这是因为我们的交替注意力 Transformer 包含逐帧自注意力层,使得 Transformer 能够将相机 tokens 和配准 tokens 与同一图像的对应tokens进行匹配。按照常规做法,输出的配准 tokens t^iR\hat{t}{i}^{R}t^iR 会被丢弃,而 t^iI\hat{t}{i}^{I}t^iI 和 t^ig\hat{t}_{i}^{g}t^ig 则用于预测任务。
坐标系 :如上所述,我们在第一个相机 g1g_1g1 的坐标系中预测相机参数、点图和深度图。因此,为第一个相机输出的相机外参被设为单位矩阵,即第一个旋转四元数 q1=0,0,0,1q_1 = 0, 0, 0, 1q1=0,0,0,1,第一个平移向量 t1=0,0,0t_1 = 0, 0, 0t1=0,0,0。需注意的是,特殊的相机 tokens 和配准 tokens t1g:=tˉgt_{1}^{g} := \bar{t}^gt1g:=tˉg、t1R:=tˉRt_{1}^{R} := \bar{t}^Rt1R:=tˉR 使 Transformer 能够识别出第一个相机。
相机参数预测 :相机参数(g^i)i=1N(\hat{g}i){i=1}^N(g^i)i=1N 是通过四个额外的自注意力层处理输出的相机 tokens (t^gi)i=1N(\hat{t}{g_i}){i=1}^N(t^gi)i=1N,再经由一个线性层得到的。这构成了用于预测相机内参和外参的相机头。
密集预测 :输出的图像 tokens t^Ii\hat{t}{I_i}t^Ii 用于预测密集输出,即深度图DiD_iDi、点图 PiP_iPi 和跟踪特征 TiT_iTi。更具体地说,首先通过 DPT 层 57 将 t^Ii\hat{t}{I_i}t^Ii 转换为密集特征图 Fi∈RC×H×WF_i \in \mathbb{R}^{C \times H \times W}Fi∈RC×H×W。然后,通过一个 3×3 卷积层将每个 FiF_iFi 映射到对应的深度图 DiD_iDi 和点图 PiP_iPi。此外,DPT 头还输出密集特征 Ti∈RC×H×WT_i \in \mathbb{R}^{C \times H \times W}Ti∈RC×H×W,作为跟踪头的输入。我们还分别为每个深度图和点图预测了随机不确定性 40, 51 ΣiD∈R+H×W\Sigma_i^{D} \in \mathbb{R}^{H \times W}+ΣiD∈R+H×W 和 ΣiP∈R+H×W\Sigma_i^{P} \in \mathbb{R}^{H \times W}+ΣiP∈R+H×W。这些不确定性图用于损失函数中,并且在训练后,与模型对预测结果的置信度成比例。
跟踪任务 :为实现跟踪模块 TTT,我们采用了 CoTracker2 架构 39,该架构以密集跟踪特征 TiT_iTi 作为输入。具体而言,给定查询图像 IqI_qIq 中的查询点 yjy_jyj(训练期间,我们始终设 q=1q=1q=1,但理论上任何其他图像都可作为查询图像),跟踪头 TTT 会预测所有图像 IiI_iIi 中与 yjy_jyj 对应同一 3D 点的 2D 点集 T((yj)j=1M,(Ti)i=1N)=((y^j,i)i=1N)j=1MT\left((y_j){j=1}^M, (T_i){i=1}^N\right) = \left((\hat{y}{j,i}){i=1}^N\right){j=1}^MT((yj)j=1M,(Ti)i=1N)=((y^j,i)i=1N)j=1M。为实现这一目标,首先在查询点 yjy_jyj 处对查询图像的特征图TqT_qTq 进行双线性采样,以获取该点的特征。随后,将此特征与所有其他特征图 TiT_iTi(i≠qi \neq qi=q)进行关联,得到一组关联图。这些关联图经自注意力层处理后,即可预测出与 yjy_jyj 对应的最终 2D 点 y^i\hat{y}{i}y^i。需要注意的是,与 VGGSfM 83 类似,我们的跟踪器不依赖输入帧的时间顺序,因此可应用于任意输入图像集,而非仅局限于视频。
Training
训练损失 :我们使用多任务损失对 VGGT 模型 fff 进行端到端训练:
L=Lcamera+Ldepth+Lpmap+λLtrack(2) \mathcal{L} = \mathcal{L}{\text{camera}} + \mathcal{L}{\text{depth}} + \mathcal{L}{\text{pmap}} + \lambda\mathcal{L}{\text{track}} \tag{2} L=Lcamera+Ldepth+Lpmap+λLtrack(2)
我们发现相机损失(Lcamera\mathcal{L}{\text{camera}}Lcamera)、深度损失(Ldepth\mathcal{L}{\text{depth}}Ldepth)和点图损失(Lpmap\mathcal{L}{\text{pmap}}Lpmap)的数值范围相近,无需相互加权。跟踪损失 Ltrack\mathcal{L}{\text{track}}Ltrack 通过系数 λ=0.05\lambda = 0.05λ=0.05 进行权重下调。下面依次介绍每个损失项:
-
相机损失 Lcamera\mathcal{L}_{\text{camera}}Lcamera 用于监督相机参数 g^\hat{g}g^:
Lcamera=∑i=1N∥g^i−gi∥ϵ\mathcal{L}{\text{camera}} = \sum{i=1}^N \|\hat{g}i - g_i\|\epsilonLcamera=i=1∑N∥g^i−gi∥ϵ
其中使用 Huber 损失∣⋅∣ϵ|\cdot|_\epsilon∣⋅∣ϵ 来衡量预测相机参数 g^i\hat{g}_ig^i与真值gig_igi之间的差异。
-
深度损失 Ldepth\mathcal{L}_{\text{depth}}Ldepth 借鉴了 DUSt3R 129 的做法,采用随机不确定性损失 59, 75,通过预测的不确定性图 Σ^iD\hat{\Sigma}i^{D}Σ^iD 对预测深度 D^i\hat{D}iD^i 与真值深度 DiD_iDi 之间的差异进行加权。与 DUSt3R 不同的是,我们还加入了一个基于梯度的项(在单目深度估计中被广泛使用)。因此,深度损失为:
Ldepth=∑i=1N∥Σ^iD⊙(D^i−Di)∥+∥Σ^iD⊙(∇D^i−∇Di)∥−αlogΣ^iD\mathcal{L}{\text{depth}} = \sum{i=1}^N \|\hat{\Sigma}_i^{D} \odot (\hat{D}_i - D_i)\| + \|\hat{\Sigma}_i^{D} \odot (\nabla\hat{D}_i - \nabla D_i)\| - \alpha\log\hat{\Sigma}_i^{D}Ldepth=i=1∑N∥Σ^iD⊙(D^i−Di)∥+∥Σ^iD⊙(∇D^i−∇Di)∥−αlogΣ^iD其中 ⊙\odot⊙ 表示通道广播的元素级乘积。
-
点图损失的定义与之类似,但使用点图不确定性 Σ^iP\hat{\Sigma}_i^{P}Σ^iP:
Lpmap=∑i=1N∥Σ^iP⊙(P^i−Pi)∥+∥Σ^iP⊙(∇P^i−∇Pi)∥−αlogΣ^iP\mathcal{L}{\text{pmap}} = \sum{i=1}^N \|\hat{\Sigma}_i^{P} \odot (\hat{P}_i - P_i)\| + \|\hat{\Sigma}_i^{P} \odot (\nabla\hat{P}_i - \nabla P_i)\| - \alpha\log\hat{\Sigma}_i^{P}Lpmap=i=1∑N∥Σ^iP⊙(P^i−Pi)∥+∥Σ^iP⊙(∇P^i−∇Pi)∥−αlogΣ^iP
-
最后,跟踪损失定义为
Ltrack=∑j=1M∑i=1N∥y^j,i−yj,i∥\mathcal{L}{\text{track}} = \sum{j=1}^M \sum_{i=1}^N \|\hat{y}{j,i} - y{j,i}\| Ltrack=j=1∑Mi=1∑N∥y^j,i−yj,i∥
其中,外层求和遍历查询图像 IqI_qIq 中所有真值查询点 yjy_jyj,yj,iy_{j,i}yj,i 是 yjy_jyj 在图像 IiI_iIi 中的真值对应点,y^j,i\hat{y}{j,i}y^j,i 是通过跟踪模块 T((yj)j=1M,(Ti)i=1N)T\left((y_j){j=1}^M, (T_i)_{i=1}^N\right)T((yj)j=1M,(Ti)i=1N) 得到的对应预测点。此外,借鉴 CoTracker2 57 的做法,我们还应用了可见性损失(二元交叉熵),用于估计一个点在给定帧中是否可见。
真值坐标归一化 :若对场景进行缩放或更改其全局参考系,场景的图像并不会受到任何影响,这意味着此类变换后的结果均属于 3D 重建的合理结果。为消除这种歧义,我们通过对数据进行归一化来确定一个标准形式,并让 Transformer 输出这一特定形式的结果。我们借鉴了 129 的做法:首先,将所有量都转换到第一个相机 g1g_1g1 的坐标系下进行表示;然后,计算点图 PPP 中所有 3D 点到原点的平均欧氏距离,并以此缩放尺度对相机平移向量 ttt、点图 PPP 和深度图 DDD 进行归一化。重要的是,与 129 不同的是,我们不对 Transformer 输出的预测结果进行此类归一化操作;相反,我们让模型从训练数据中自主学习我们所设定的归一化规则。
实现细节 :默认情况下,我们分别采用 24 层(L=24L=24L=24)全局注意力层和逐帧注意力层。该模型总计包含约 12 亿个参数。我们通过 AdamW 优化器对训练损失(公式 2)进行优化,以训练模型,共训练 16 万次迭代。学习率调度采用余弦调度策略,峰值学习率设为 0.0002,热身迭代次数为 8000 次。对于每个批次,我们从随机选取的训练场景中随机采样 2-24 帧。输入帧、深度图和点图均调整为最大维度为 518 像素的尺寸,宽高比随机设定在 0.33 到 1.0 之间。我们还会对帧随机应用颜色抖动、高斯模糊和灰度增强处理。训练在 64 块 A100 GPU 上进行,耗时 9 天。为保证训练稳定性,我们采用梯度范数裁剪策略,阈值设为 1.0。同时,我们借助 bfloat16 精度和梯度检查点技术,以提升 GPU 内存利用率和计算效率。
训练数据:该模型的训练采用了大量且多样的数据集集合,包括:Co3Dv2 88、BlendMVS 146、DL3DV 69、MegaDepth 64、Kubric 41、WildRGB 135、ScanNet 18、HyperSim 89、Mapillary 71、Habitat 107、Replica 104、MVS-Synth 50、PointOdyssey 159、Virtual KITTI 7、Aria Synthetic Environments 82、Aria Digital Twin 82,以及一个与 Objaverse 20 类似的、由艺术家创作资产构成的合成数据集。这些数据集涵盖多种领域,包括室内和室外环境,且包含合成场景与真实世界场景。这些数据集的 3D 标注来源于多个渠道,例如直接的传感器采集、合成引擎或运动恢复结构(SfM)技术 95。我们所采用的数据集组合在规模和多样性上与 MASt3R 30 所使用的数据集大致相当。
Formal Definitions
相机外参是相对于世界参考系定义的,而我们将世界参考系设定为第一个相机的坐标系。为此,我们引入两个函数:第一个函数 γ(g,p)=p′\gamma(g,p) = p'γ(g,p)=p′,其作用是将 ggg 所编码的刚性变换应用于世界参考系中的点 ppp,从而得到相机参考系中对应的点 p′p'p′;第二个函数 π(g,p)=y\pi(g,p) = yπ(g,p)=y 则进一步执行透视投影,将 3D 点 ppp 映射为 2D 图像点 yyy。我们还通过 πD(g,p)=d∈R+\pi_D(g,p) = d \in \mathbb{R}^+πD(g,p)=d∈R+ 来表示从相机 ggg 观测到的点的深度。我们将场景建模为一组正则曲面 Si⊂R3S_i \subset \mathbb{R}^3Si⊂R3 的集合。由于场景可能随时间变化 151,我们将其设定为第 iii 张输入图像的函数。像素位置 y∈I(Ii)y \in I(I_i)y∈I(Ii) 处的深度定义为场景中所有投影到 yyy 的 3D 点 ppp 的最小深度,即 Di(y)=min{πD(gi,p):p∈Si∧π(gi,p)=y}D_i(y) = \min\{\pi_D(g_i,p) : p \in S_i \land \pi(g_i,p) = y\}Di(y)=min{πD(gi,p):p∈Si∧π(gi,p)=y}。像素位置 yyy 处的点则由 Pi(y)=γ(g,p)P_i(y) = \gamma(g,p)Pi(y)=γ(g,p) 给出,其中 p∈Sip \in S_ip∈Si 是满足上述最小化条件的 3D 点,即 p∈Si∧π(gi,p)=y∧πD(gi,p)=Di(y)p \in S_i \land \pi(g_i,p) = y \land \pi_D(g_i,p) = D_i(y)p∈Si∧π(gi,p)=y∧πD(gi,p)=Di(y)。
Implementation Details
架构:如主论文所述,VGGT 由 24 个注意力块组成,每个块配备一个逐帧自注意力层和一个全局自注意力层。借鉴 DINOv2 78 中使用的 ViT-L 模型,每个注意力层的特征维度设为 1024,并采用 16 个注意力头。我们使用 PyTorch 的官方注意力层实现(即 torch.nn.MultiheadAttention),并启用闪现注意力(flash attention)。为稳定训练,每个注意力层还采用了 QKNorm 48 和 LayerScale 115,其中 LayerScale 的初始值设为 0.01。在图像 tokenization 方面,我们使用 DINOv2 78 并添加位置嵌入。与 143 相同,我们将第 4、11、17 和 23 个块的 token 输入到 DPT 87 中进行上采样。
训练过程:构建训练批次时,我们首先随机选择一个训练数据集(每个数据集的权重不同但大致相近,如 129 所述),然后从该数据集中随机采样一个场景(均匀采样)。训练阶段,每个场景选择 2 至 24 帧,同时保证每个批次内的总帧数恒定为 48 帧。训练使用各数据集各自的训练集,排除帧数量少于 24 帧的训练序列。RGB 帧、深度图和点图首先进行等比缩放,使较长边为 518 像素。然后,对较短边(围绕主点)进行裁剪,裁剪后尺寸在 168 至 518 像素之间,且为 14 像素 patch 大小的倍数。值得一提的是,我们对同一场景内的每帧独立应用强色彩增强,以提升模型对不同光照条件的鲁棒性。真值轨迹的构建遵循 33, 105, 125 的方法:将深度图反投影为 3D 点,再将点重投影到目标帧,保留重投影深度与目标深度图匹配的对应关系。批次采样时,排除与查询帧相似度低的帧。在极少数无有效对应关系的情况下,会忽略跟踪损失。
