前言
即梦发布了 4.0,浏览了下发布的内容,有点吃惊。
当时 3.0 发布时,我分享了一篇文章《即梦3.0:真正可用的AI生图 - 掘金》,当时感觉算是"真正可用的AI生图"了。
等我体验完 4.0,我感觉已经不仅仅是吃惊了,AI 生成好像已经接近"随心所欲"了。
今天就给大家看下我的实测结果。
模型亮点
先看下官方提出的模型亮点:
- 精准指令编辑: 不需要学习专业术语,只需要通过大白话描述即可实现图片修改,这不相当于一个 PS 高手随时待命吗?
- 高度特征保持: 之前多图生成,总会存在各个图之间角色不一致的问题,这次尝试了,效果挺不错的。
- 深度意图理解: 这一点真的炸裂,"即梦4.0"拥有了很强的逻辑推理能力,可以识别图片中的逻辑内容,再进行进一步的生成操作。
- 多图输入输出: 之前只能上传一个底图进行操作,现在支持多图上传,可以融合,可以参考,大大提升了 AI 使用的场景和灵活性。
- 超高速超高清: 这个就属于"基操"了,不快不清的话,"即梦"也不会发展到现在了。
实测效果
理论方面我们已经了解了,下面针对每一个亮点,我们找个场景实际体验下。
精准指令编辑
顺手找了"即梦"的活动海报,我们通过自然语言要求更换文字。
原图

指令
请将大标题更换为"开学快乐",小标题改为"欢迎2025年新生"注意:提示词中并没有明确要求明确的目标文字,而是通过"大标题"这种概念指定的。
结果
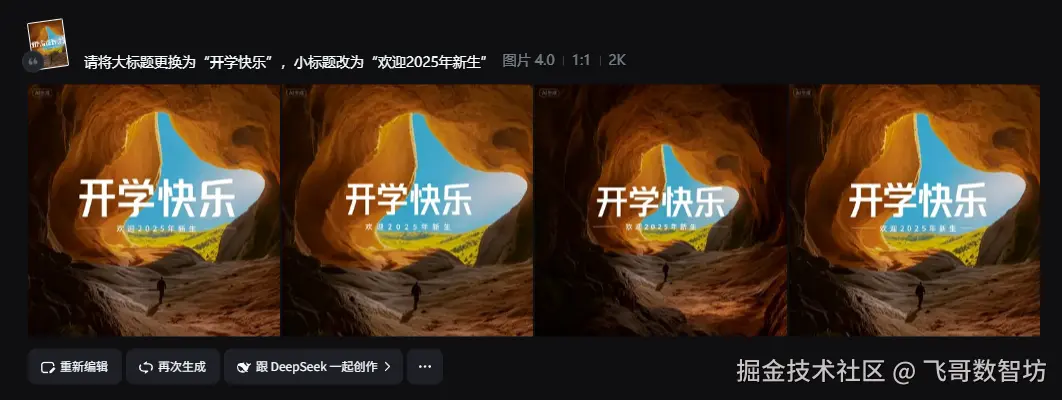
效果

高度特征保持
我们直接使用我自己搓的一个手工机器人,生成一个九宫格表情,看看角色一致性保持的如何。
原图

指令
请基于图片生成一个九宫格表情包结果
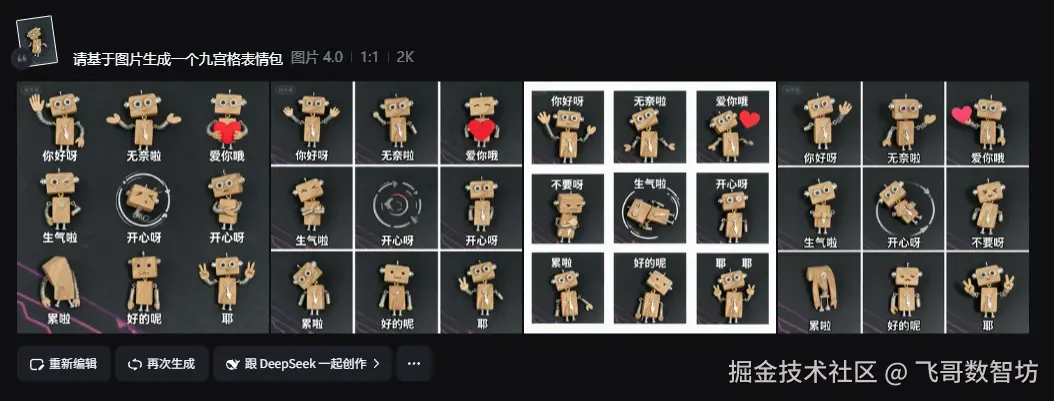
效果

其中,"开心呀"引用了"开心到转圈圈"的梗,"累啦"那个的弯腰幅度,真是打工人的真实写照了,如果是超我们这侧弯曲就更好了。
深度意图理解
官方示例中最打动我的就是一个时间更改的例子,AI 需要识别时间这个主体,然后理解意图中的时间概念,然后更改图中的时间。
原图
指令
帮我把时间往前调整1小时5分钟结果

效果
我还故意设置了一个分钟不够减的测试用例,它竟然借位成功了。
只有一个字,牛!
多图输入输出
这个虽然不太惊艳,但使用场景真的广泛,不在受限于底图的数量。
原图

指令
将图1和图2机器人合进一张画面结果

效果
这一场景下,不知道是我的图片特殊还是怎么滴,4 个结果中只有一张图是比较符合原角色的,其余 3 张都有不同程度的变化。
比如,"被动长高"。

超高速超高清
生成速度方面比前一阵确实快了点,高清的话,一直都挺清晰的,只能算保持吧。
结语
"即梦4.0" 的试用过程中,我已经不止一次的惊呼"太牛了"。
意图理解、角色一致、逻辑推理、多图融合,关键生图效果既快又清晰,这设计师的活快被包圆了。
也许 PS 暂时还会存在,但地位有点危险呀!
今天就到这里,我要找点更加真实的场景再去试试,回头再给大家分享哈~