一、DSL查询
DSL查询就是以JSON格式来定义查询条件。类似于:

DSL查询可以分为两大类:
-
叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
-
复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
在查询以后,还可以对查询的结果做处理,包括:
- 排序:按照1个或多个字段值做排序
- 分页:根据from和size做分页,类似MySQL
- 高亮:对搜索结果中的关键字添加特殊样式,使其更加醒目
- 聚合:对搜索结果做数据统计以形成报表
1、快速入门
基于DSL的查询语法如下:
java
GET /{索引库名}/_search
{
"query": {
"查询类型": {
"查询条件":"条件值"
// .. 查询条件
}
}
}使用match_all查询所有:
#查询所有
GET /items/_search
{
"query": {
"match_all": {}
}
}2、叶子查询
叶子查询还可以进一步细分,常见的有:
-
全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
-
match_query -
multi_match_query
-
-
精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
-
ids -
term -
range
-
-
地理(geo)坐标查询 **:**用于搜索地理位置,搜索方式很多,例如:
-
geo_bounding_box:按矩形搜索 -
geo_distance:按点和半径搜索
-
全文检索查询
match查询:全文检索查询中的一种,会对用户输入的内容分词,然后去倒排索引库检索,语法:
GET /{索引库名}/_search
{
"query": {
"match": {
"字段名": "搜索条件"
}
}
}multi_match:与match查询类似,只不过允许同时查询多个字段,语法:
GET /{索引库名}/_search
{
"query": {
"multi_match": {
"query": "搜索条件",
"fields": ["字段1", "字段2"]
}
}
}示例:
java
#match查询
GET /items/_search
{
"query": {
"match": {
"name": "小米"
}
}
}
#multi_match查询
GET /items/_search
{
"query": {
"multi_match": {
"query": "脱脂牛奶", #要查询的内容
"fields": ["name"] #查询的字段(可以写多个)
}
}
}精确查询
term查询语法:
java
GET /{索引库名}/_search
{
"query": {
"term": {
"字段名": "搜索条件"
}
}
}
}range查询语法:
java
GET /{索引库名}/_search
{
"query": {
"range": {
"字段名": {
"gte": {最小值},
"lte": {最大值}
}
}
}
}range是范围查询,对于范围筛选的关键字有:
-
gte:大于等于 -
gt:大于 -
lte:小于等于 -
lt:小于
示例:
java
#term查询
GET /items/_search
{
"query": {
"term": {
"category":{
"value": "牛奶"
}
}
}
}
#term查询
GET /items/_search
{
"query": {
"term": {
"category":"牛奶" //key value形式也可以
}
}
}
}
#range查询
GET /items/_search
{
"query": {
"range": {
"price": {
"gte": 500000,
"lte": 600000
}
}
}
}
#ids查询
GET /items/_search
{
"query": {
"ids":{
"values": ["613360","613359"]
}
}
}3、复合查询
复合查询大致可以分为两类:
-
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如:
- bool
-
第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
-
function_score
-
dis_max
-
布尔查询
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
-
must:必须匹配每个子查询,类似"与"
-
should:选择性匹配子查询,类似"或"
-
must_not:必须不匹配,不参与算分,类似"非"
-
filter:必须匹配,不参与算分
bool查询语法:
java
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"should": [
{"term": {"brand": { "value": "vivo" }}},
{"term": {"brand": { "value": "小米" }}}
],
"must_not": [
{"range": {"price": {"gte": 2500}}}
],
"filter": [
{"range": {"price": {"lte": 1000}}}
]
}
}
}示例:
java
#复合查询 搜索智能手机,但是品牌必须是华为,价格必须是900-1599
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "智能手机"}},
{"term": {"brand": {"value": "华为"}}},
{"range": {"price": {"gte": 90000,"lte": 159900}}}
]
}
}
}4、排序和分页
排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
语法说明:
java
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"排序字段": "排序方式asc和desc"
}
}
]
}示例:
java
#排序查询 按销量的降序排列,如果相同则按照价格升序
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"sold": "desc"
},
{
"price": "asc"
}
]
}分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
-
from:从第几个文档开始 -
size:总共查询几个文档
语法说明:
java
GET /items/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 每页文档数量,默认10
"sort": [
{
"price": {
"order": "desc"
}
}
]
}示例:
java
#排序及分页查询 查询销量前十的,销量一样按价格升序
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"sold": "desc"
},
{
"price": "asc"
}
],
"from": 1,
"size": 3
}深度分页问题
针对深度分页,elasticsearch提供了解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
您的比喻:传统方法(找年级50-60名)
命令:校长说:"给我找出全年级第50到60名的同学。"
执行过程(低效):
每个班的班主任(分片 )都必须先把自己班前60名 的同学找出来,送到教务处(协调节点)。
教务处主任收到所有班级送来的"前60名"名单(每个班送来的名单长度都是
from + size = 60)。教务处主任然后把所有班级送来的好几百个学生放在一起,重新进行全年级大排名,排出前60名。
最后,他从这个全年级前60名的总名单里,扔掉前49名,把剩下的第50到60名这10个学生报给校长。
问题:校长只要10个人,却让所有班主任和教务处主任忙活了半天,处理了数百个学生的数据,其中绝大部分(前49名)的工作成果都被丢弃了。如果要找第1000-1010名,这个工作量会大到荒谬。
Search After 的解决方法:利用"锚点"
Search After 的思路完全不同,它不关心绝对的"第50名",它只关心"下一个是谁"。
前提:我们必须有一个全年级统一的、稳定的排名标准(比如"总成绩"为主,"学号"为辅,确保没有并列)。
步骤一:拿到第一批名单(年级前10名)
校长第一次说:"先给我全年级前10名的名单,并且告诉我第10名同学的成绩和学号。"
教务处很快完成了这个任务(因为每个班只需要报前10名,工作量很小)。校长拿到了名单,并且记录了一个关键信息【锚点】:第10名同学的王五,总成绩是588分,学号是20230010。
步骤二:拿到下一批名单(第11-20名)
校长现在想要下一批。他不会说"给我第11到20名",而是这样说:
- "请从【王五同学(588分,学号20230010)】之后开始,再给我接下来的10名同学。"
教务处主任接到这个指令后,工作变得非常简单:
他告诉各个班主任:"不要再报从第一名开始的人了!你们只需要看看自己班里,有没有总分低于588分,或者总分等于588分但学号比20230010大的同学,把这些人里的前10名报上来就行。"
各个班报上来的人自然都是排在王五后面的。教务处很快就能合并出紧接着的10个人(第11-20名)。
校长同样记录下第20名同学的信息作为新的【锚点】。
步骤三:以此类推,找到目标(第50-60名)
校长只需要重复步骤二 4次(每次拿10个),他手上的【锚点】就从【第10名】变成了【第20名】->【第30名】->【第40名】->最终,他拿到了第50-60名的名单。
他从未要求过教务处进行一次"全年级前60名"的巨大排序工作。
Search After 的核心优势:
绝不浪费 :每一次查询,每个班级(分片)都只做最小范围的必要工作------只寻找排在某个明确锚点之后的人。完全避免了"先找出一大堆,再扔掉绝大部分"的愚蠢行为。
效率恒定 :无论是取第1-10名,还是第1001-1010名,每次的工作量和速度几乎是一样的,因为它只是"从锚点X之后找10个人",而不是"先找到前1010个人再扔掉1000个"。
解决深度分页:正是因为这个特性,它完美地解决了"深度分页"这个让传统方法崩溃的难题。
所以,总结一下:
传统分页:是"先全部排序,再截取中间一段"。(您的比喻极其准确)
Search After :是"记住你现在的位置,然后告诉我紧接着的下一个是谁"。这是一种顺序访问,就像用书签看书一样,高效且优雅。
它通过改变问题的范式,从根本上解决了集群资源的浪费问题。
5、高亮显示
高亮显示:就是在搜索结果中把搜索关键字突出显示。
语法说明:
java
GET /{索引库名}/_search
{
"query": {
"match": {
"搜索字段": "搜索关键字"
}
},
"highlight": {
"fields": {
"高亮字段名称": {
"pre_tags": "<em>", //高亮的前置标签
"post_tags": "</em>" //高亮的后置标签
}
}
}
}示例:
java
#高亮显示
GET /items/_search
{
"query": {
"match": {
"name": "脱脂牛奶"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>"
, "post_tags": "</em>"
}
}
}
}二、RestClient查询
1、快速入门
match_all查询为例,其DSL和JavaAPI的对比如图:
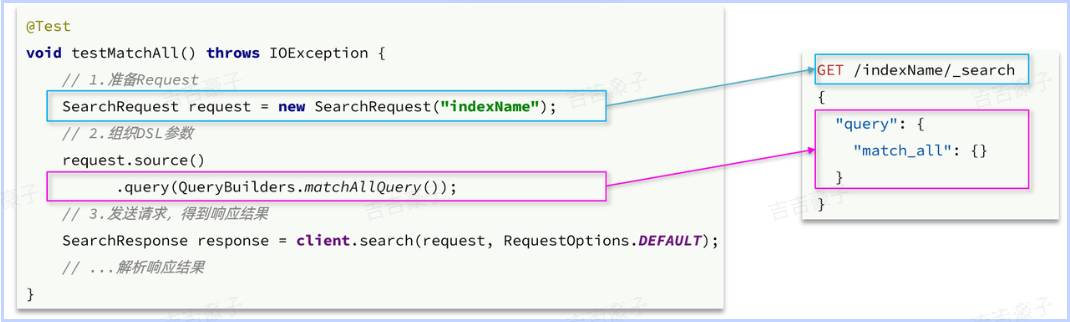
解析SearchResponse的代码就是在解析这个JSON结果,对比如下:
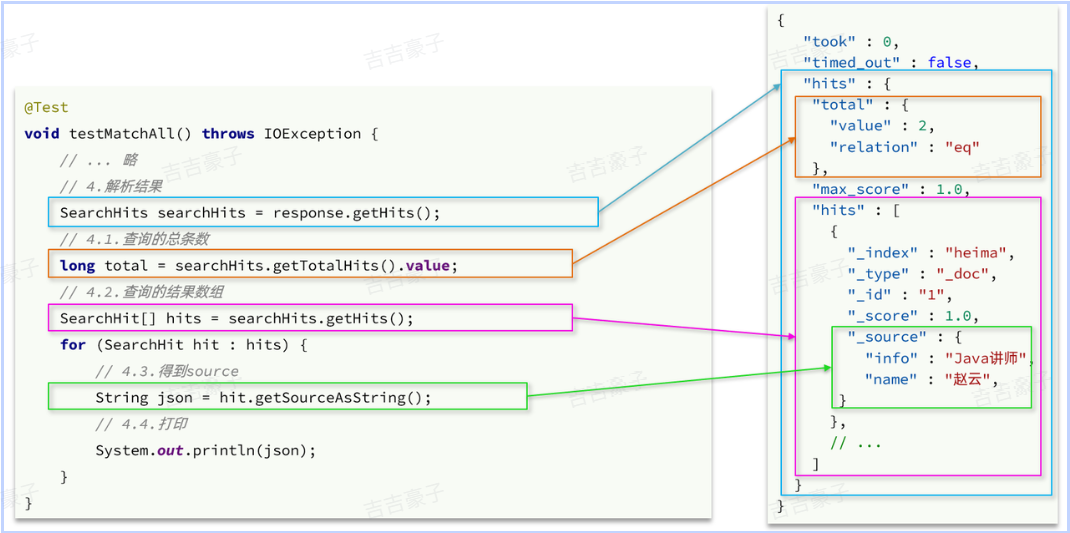
完整示例:
java
@Test
void testMatchAll() throws IOException {
// 1、创建request对象
SearchRequest request = new SearchRequest("items");
// 2、配置request参数
request.source()
.query(QueryBuilders.matchAllQuery());
// 3、发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("response:" + response);
// 4、解析结果
SearchHits searchHits = response.getHits();
// 4.1、总条数
long total = searchHits.getTotalHits().value;
System.out.println("total:" + total);
// 4.2、 命中的数据
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//获取source结果
String json = hit.getSourceAsString();
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("doc:"+doc);
}
}2、构建查询条件


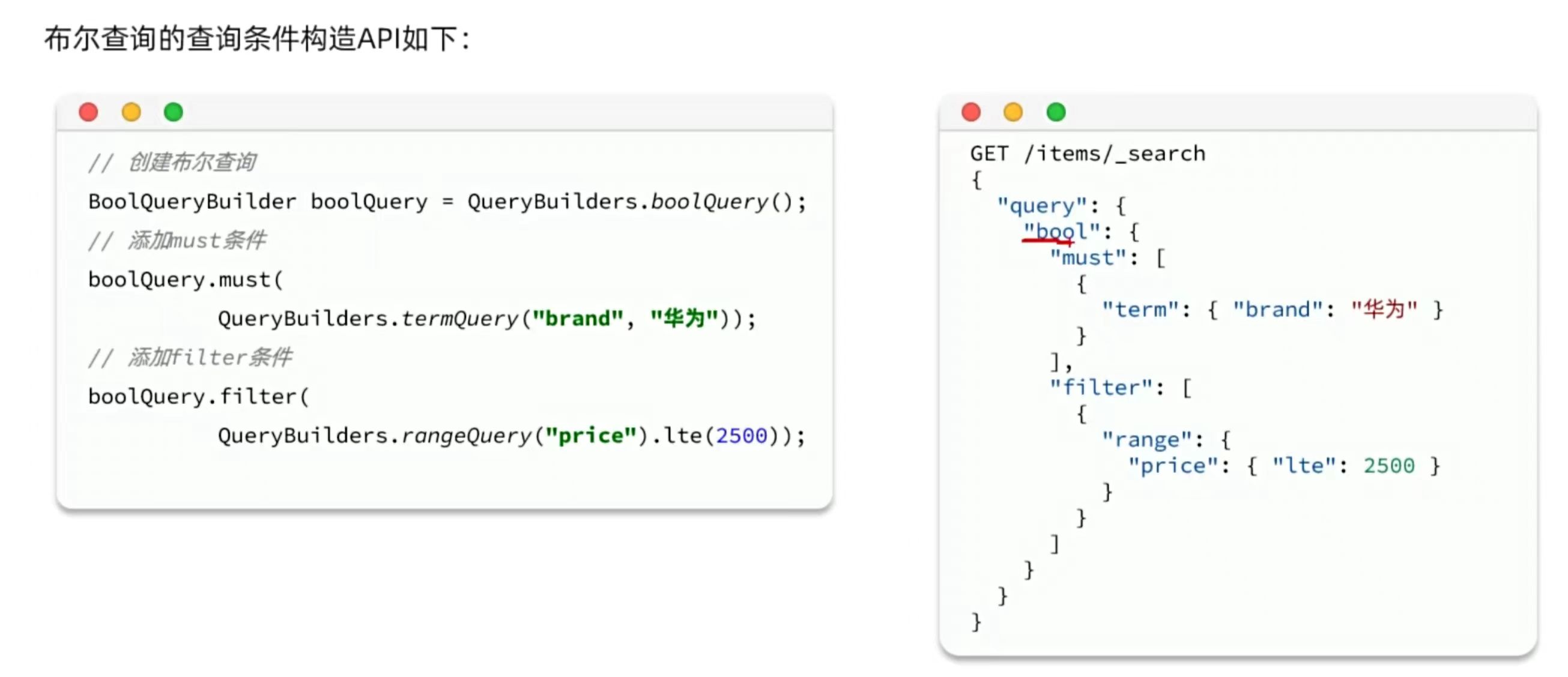
查询关键词为脱脂牛奶,品牌为德亚,价格低于300的商品
java
@Test
void testSearch () throws IOException {
// 1、创建request对象
SearchRequest request = new SearchRequest("items");
// 2、配置request参数
request.source().query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name","脱脂牛奶"))
.filter(QueryBuilders.termQuery("brand","德亚"))
.filter(QueryBuilders.rangeQuery("price").lt(30000))
);
// 3、发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("response:" + response);
// 4、结果解析
parseResponseResult(response);3、排序和分页
与query类似,排序和分页参数都是基于request.source()来设置的:
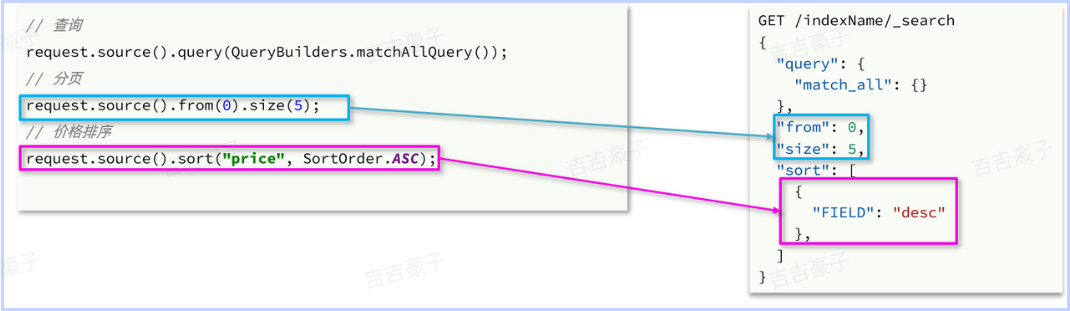
示例:
java
@Test
void testSortAndPage() throws IOException {
// 0、模拟前端传递的分页参数
int pageNo = 1 , pageSize = 5;
// 1、创建request对象
SearchRequest request = new SearchRequest("items");
// 2、配置request参数
//query条件
request.source().query(QueryBuilders.matchAllQuery());
//分页
request.source().from(pageNo - 1).size(pageSize);
//排序
request.source()
.sort("sold", SortOrder.DESC)
.sort("price",SortOrder.ASC);
// 3、发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("response:" + response);
// 4、结果解析
parseResponseResult(response);
}4、高亮显示
高亮条件构造,其DSL和JavaAPI的对比如图:

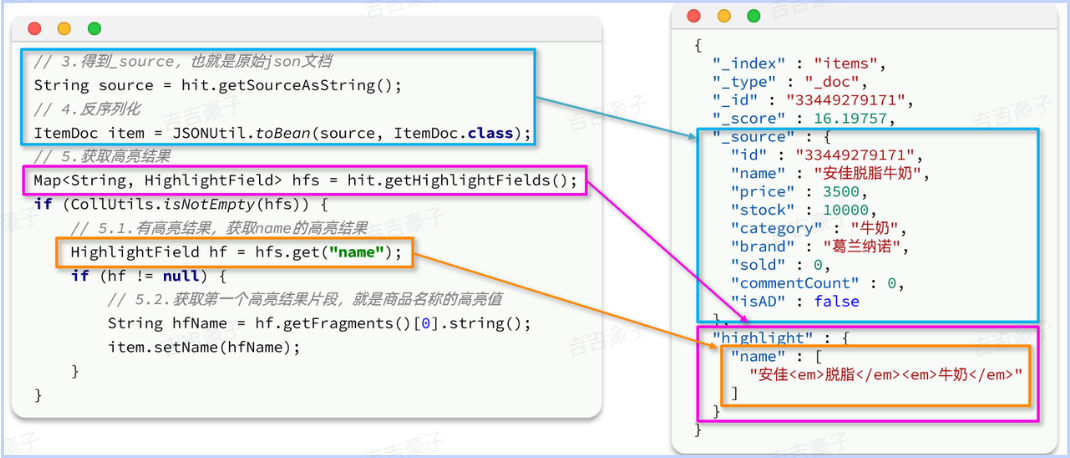
再来看结果解析,文档解析的部分不变,主要是高亮内容需要单独解析出来,其DSL和JavaAPI的对比如图:
示例:
java
@Test
void testHighlight() throws IOException {
// 1、创建request对象
SearchRequest request = new SearchRequest("items");
// 2、配置request参数
//query条件
request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));
//高亮条件
request.source().highlighter(SearchSourceBuilder.highlight().field("name"));
// 3、发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("response:" + response);
// 4、结果解析
parseResponseResult(response);
}
private static void parseResponseResult(SearchResponse response) {
// 4、解析结果
SearchHits searchHits = response.getHits();
// 4.1、总条数
long total = searchHits.getTotalHits().value;
System.out.println("total:" + total);
// 4.2、 命中的数据
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//获取source结果
String json = hit.getSourceAsString();
//转为ItemDoc
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
//处理高亮
Map<String, HighlightField> hfs = hit.getHighlightFields();
if(hfs != null && !hfs.isEmpty()){
//根据高亮字段名获取高亮结果
HighlightField hf = hfs.get("name");
//获取高亮结果,覆盖非高亮结果
String string = hf.getFragments()[0].toString();
doc.setName(string);
}
System.out.println("doc:" + doc);
}
}三、数据聚合
聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
-
桶(
Bucket**)**聚合:用来对文档做分组-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组 -
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(
Metric**)**聚合:用以计算一些值,比如:最大值、最小值、平均值等-
Avg:求平均值 -
Max:求最大值 -
Min:求最小值 -
Stats:同时求max、min、avg、sum等
-
-
管道(
pipeline**)**聚合:其它聚合的结果为基础做进一步运算

示例:
java
#聚合
GET /items/_search
{
"size": 0,
"aggs": {
"cate_agg": {
"terms": {
"field": "category",
"size":5
}
},
"brand_agg":{
"terms": {
"field": "brand",
"size":10
}
}
}
}
#带条件的聚合
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
},
{
"range": {
"price": {
"gte": 300000
}
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}除了对数据分组以外,我们还可以对每个Bucket内的数据进一步做数据计算和统计。
如:我想知道手机有哪些品牌,每个品牌价格的最大值、最小值、平均值。
java
#Metric聚合
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 10
},
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
}
}四、RestClient聚合
可以看到在DSL中,aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用request.source()方法来设置。
不过聚合条件的要利用AggregationBuilders这个工具类来构造。DSL与JavaAPI的语法对比如下:
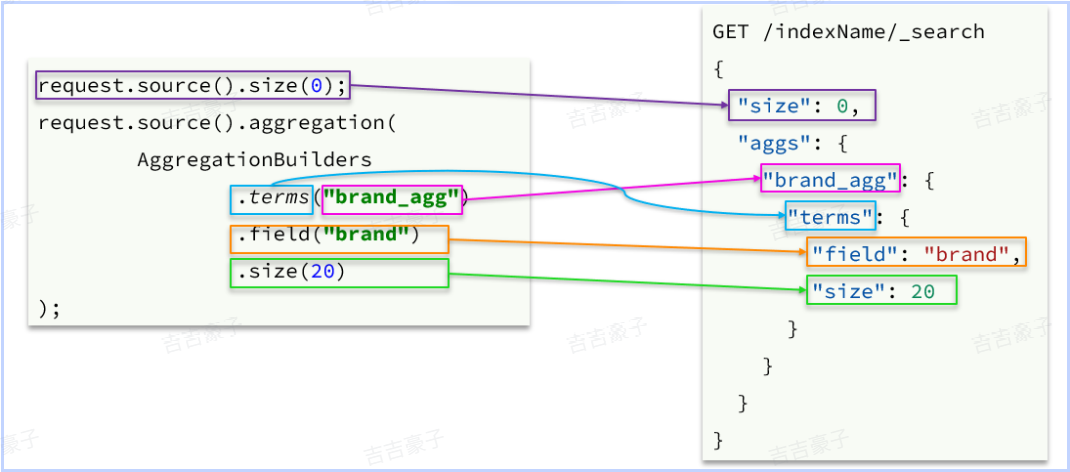
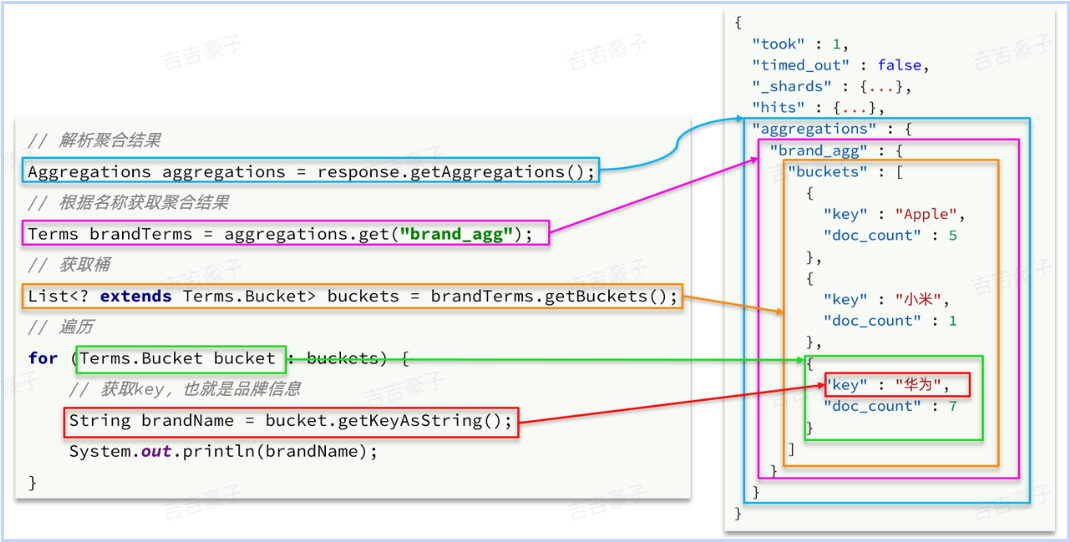
解析语法如下:
示例:
java
@Test
void testAgg() throws IOException {
// 1、创建request对象
SearchRequest request = new SearchRequest("items");
// 2、配置request参数
//分页
request.source().size(0);
//聚合条件
String brandAggName = "brandAgg";
request.source().aggregation(
AggregationBuilders.terms(brandAggName).field("brand").size(10)
);
// 3、发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4、结果解析
Aggregations aggregations = response.getAggregations();
// 根据聚合名称获取对应的聚合
Terms brandTerms = aggregations.get(brandAggName);
// 获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历获取每一个bucket
for (Terms.Bucket bucket : buckets) {
System.out.println("brand!!!!!!!!:"+bucket.getKeyAsString());
System.out.println("count!!!!!!!!:"+bucket.getDocCount());
}
}