知识蒸馏(KD)详解一:认识一下BERT 模型
1 什么是BERT
简单来说,BERT其实就是一个预训练模型,是一个文本特征提取器。它的核心思想:
第一,就是在一个很大的预料库上进行预训练,得到语言的表征的一个预训练模型;
第二,下游在接一个具体任务的一些层,如文本分类、情感识别、问答等,和这个预训练模型进行一起微调训练,进而实现具体的任务。
论文参考:https://arxiv.org/pdf/1810.04805
2 模型
2.1 结构
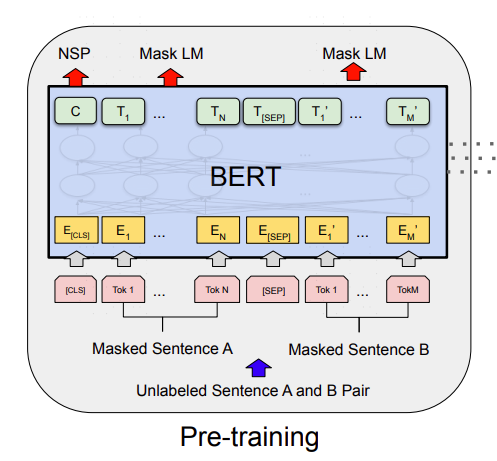
模型分为以下几个部分:
- 输入 CLS Masked SentenceA SEP Masked Sentence B SEP 对应的token ids
如:"CLS my dog is cute SEP he likes play MASK SEP",其中MASK 是被隐藏掉的词,用于训练预测。
转换为对应的token ids : 101, 2026, 3899, 2003, 10140, 102, 2002, 7777, 2377, 103, 102,其中CLS是101,MASK是103,SEP是102
-
Embeddings 部分
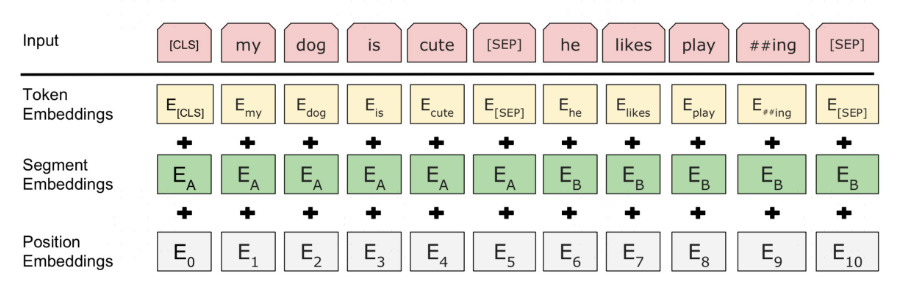
Token Embeddings :对应的是将30522个词所对应的id转为768维度的向量,如"my" 的id 是 2026,就变成一个768的向量
Segment Embeddings:来分割句子A和B,前一个句子A所有token 是0,后一个句子B所有token 是1,前一个句子包含CLS,结果就是0,0,0,0,0,0,1,1,1,1,1,然后embeddings 成768维向量
Position Embeddings:位置编码,最大512个token输入,输出维度也是768维度,具体位置编码可查看transformer 结构中的实现。
最终的embeddings 就是将三者相加起来。
- 骨干网络:Bidirectional Transformers 也就是 Transformer Encoder
堆叠的N层transformer encoder,论文作者给出了两种不同参数的模型
在这里插入图片描述

可以看到我们上面例子768维度的embeddings就是论文中提到的一种输入输出维度,输出维度(batch, SeqLen, 768)
- 下游任务:NSP + Mask LM
要想得到一个预训练模型,必须是骨干网络+下游任务。论文中的预训练模型就是由NSP + Mask LM下游任务得到的。
NSP: Linear(in_features=768, out_features=2, bias=True) ,将骨骼网络输出对应CLS位置的向量转为一个2维的向量,来分类判断句子B是否句子A下句的概率,标签1是,0不是。
Mask LM: (predictions): BertLMPredictionHead(
(transform): BertPredictionHeadTransform(
(dense): Linear(in_features=768, out_features=768, bias=True)
(transform_act_fn): GELUActivation()
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(decoder): Linear(in_features=768, out_features=30522, bias=True)
)
除了CLS对应的输出向量外,其他token 对应的骨干网络输出向量经过以上层,得到30522个词对应的概率。
然后对NSP和Mask LM 输出向量进行softmax 并argmax 找到概率最大的位置,即是输出token ids
最终输出可写为如模型结构图中所示:

2.2 训练
我们要知道我们拿bert 是干什么的,目的是用来做特征提取的预训练,在结合自己的任务做微调训练,因此自然分为两部分:Pre-Train,Fine-Tuning
-
Pre-Train
前面已经说过,论文是拿NSP+MLM 预测头来预训练模型,这种形式标签可自动生成,不需要额外标注。
NPS: NSP 的具体做法是,其中,50% 的概率将语义连贯的两个连续句子作为训练文本(同一篇文章连续两句话),另外 50% 的概率将完全随机抽取两个句子作为训练文本。如下实例:连续句对:CLS你人呢?SEP一整天都没看到你了。SEP label:1
随机句对:CLS今天晚上吃烤鱼。SEP地球是圆的。SEP label:0
预测的C 概率最大的位置对应即对应的label,1表示后面句子B是前面句子A的下一句,否则不是。
MLM: 针对样本,每一个token都有15%的概率被选为mask,而对于每一个mask:80%的概率是MASK,10%是原词,10%是其他词,而标签始终是原词。以此来构造mask。
- Fine-Tuning
在Pre-Train 基础得到的不带预测头的骨干网络,在加上新的任务的预测头来进行微调训练。也就是基于BERT的预训练骨干网络和权重来构建新的训练任务。
2.3 损失
- MLM(Masked Language Modeling)损失
-
设一句输入长度为 SS,词表大小 ∣V∣|V|∣V∣。从非特殊符号位置里随机抽出 15% 作为掩码集合 M\mathcal{M}M(80/10/10 只影响输入端替换 ,标签始终是原词)。
-
对每个被选中位置i∈Mi \in \mathcal{M}i∈M:
-
模型给出词表 logits:zi∈R∣V∣{z}_i \in \mathbb{R}^{|V|}zi∈R∣V∣
-
该位置的真实 token id:yi∈{0,...,∣V∣−1}y_i \in \{0,\dots,|V|-1\}yi∈{0,...,∣V∣−1}
-
单点交叉熵:CEi=−logsoftmax(zi)yi{CE}_i = -\log \mathrm{softmax}(\mathbf{z}i){y_i}CEi=−logsoftmax(zi)yi
-
-
MLM 总损失(常用平均):
LMLM=1∣M∣∑i∈MCEi{L}{\text{MLM}} = \frac{1}{|\mathcal{M}|}\sum{i\in \mathcal{M}} \mathrm{CE}_iLMLM=∣M∣1i∈M∑CEi
其他位置(未被选择)不计入损失。PyTorch 里通常把这些位置的 label 设为 -100 ,配合
ignore_index=-100。
- NSP(Next Sentence Prediction)损失
-
输入是句对 A;B,标签 yNSP∈{0,1}y_{\text{NSP}}\in\{0,1\}yNSP∈{0,1}(1=IsNext , 0=NotNext)。
-
用
[CLS]的(pooler 后)向量接一个线性层得到二类 logits:r∈R2{r}\in\mathbb{R}^{2}r∈R2。 -
NSP 损失(二分类交叉熵):
LNSP=−logsoftmax(r) yNSP{L}{\text{NSP}} = -\log \mathrm{softmax}(\mathbf{r}){\,y_{\text{NSP}}}LNSP=−logsoftmax(r)yNSP
- 联合目标(原始 BERT)
L=LMLM+LNSP{L} = \mathcal{L}{\text{MLM}} + \mathcal{L}{\text{NSP}}L=LMLM+LNSP
论文中不额外加权;实现里通常直接相加(同量级)。
3 如何使用BERT
https://huggingface.co/docs/transformers/model_doc/bert
https://huggingface.co/google-bert/bert-base-uncased
huggingface中提供了很多bert 模型和使用方法,而我们将使用论文中提到的骨骼网络+NSP+MLM的模型结构来测试。
code:
python
from transformers import AutoTokenizer, BertForPreTraining
import torch
device = "cuda:0" # cup
# 手动步骤实现(更深入了解过程)
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = BertForPreTraining.from_pretrained(model_name).eval().to(device) # .cuda()
print(model)
# 待分析的句子
textA = "my dog is cute"
textB = "he likes play [MASK]"
# 返回包含 'input_ids', 'token_type_ids', 'attention_mask' 的字典
inputs = tokenizer(textA, textB, return_tensors="pt", truncation=True).to(device) # .cuda()
# 转换成tokens 查看
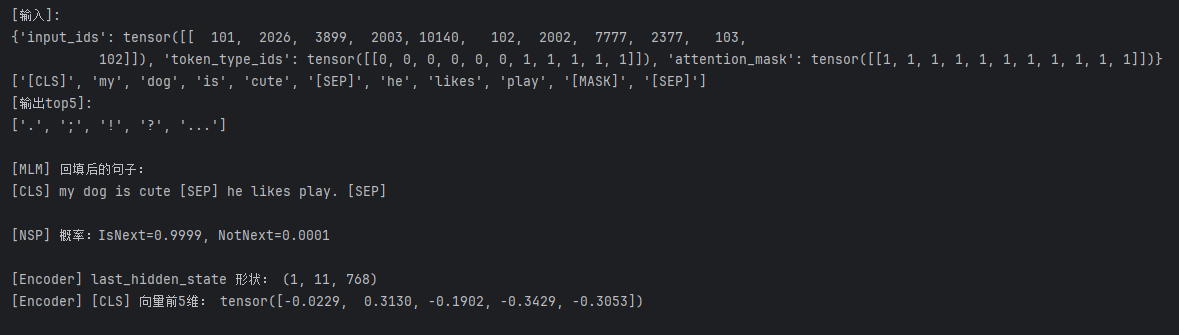
in_toks = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
print("[输入]:")
print(inputs)
print(in_toks)
# 将输入传递给模型,得到输出
with torch.no_grad(): # 推理时不需要计算梯度
outputs = model(**inputs, output_hidden_states=True)
# MLM 输出
mlm_logits = outputs.prediction_logits #(1, 11, 30522)
mask_pos = (inputs["input_ids"][0] == tokenizer.mask_token_id).nonzero(as_tuple=True)[0] # 找到mask的位置 9mask_pos = mask_pos[0].item()
mask_probs = torch.softmax(mlm_logits[0, mask_pos], dim=-1) # 计算 mask 概率
# top-5 预测
mask_top5_tok_ids = torch.topk(mask_probs, k=5, dim=-1).indices # 取概率前5位置ids
mask_top5_toks = tokenizer.convert_ids_to_tokens(mask_top5_tok_ids.cpu().tolist())
print("[输出top5]:")# 转换成tokens
print(mask_top5_toks)
# 用top1 回填原句子
filled_ids = inputs["input_ids"][0].clone()
filled_ids[mask_pos] = mask_top5_tok_ids[0].item()
filled = tokenizer.decode(filled_ids)
print("\n[MLM] 回填后的句子:")
print(filled)
# nsp 输出
nsp_logits = outputs.seq_relationship_logits
nsp_probs = torch.softmax(nsp_logits, dim=-1)
print(f"\n[NSP] 概率:IsNext={nsp_probs[0,0].item():.4f}, NotNext={ nsp_probs[0, 1].item():.4f}")
# 骨干网络输出
last_hidden = outputs.hidden_states[-1]
print("\n[Encoder] last_hidden_state 形状:", tuple(last_hidden.shape))
print("[Encoder] [CLS] 向量前5维:", last_hidden[0, 0, :5])
print()
inputs_ids就是2.1中提到的输入tokens ids
token_type_ids 就是2.1中提到的用于Segment Embeddings 的ids
attention_mask 是针对于改句子是否有padding,padding的位置为0,因为训练时整个batch,要求等长,末尾需要补充padding
结果: