写在文章开头
在现代多核处理器系统中,数据的一致性和访问效率是确保高性能计算的关键因素之一。随着技术的发展和应用需求的增长,传统的单核处理架构已经无法满足日益复杂的计算任务要求。因此,多核乃至多处理器系统的出现成为必然趋势。然而,在这样的并行计算环境中,如何保证各个核心之间的数据同步与一致成为了新的挑战。
缓存一致性问题是多核系统中最为核心的问题之一。当多个处理器核心共享同一块内存区域时,每个核心都可能拥有该内存区域的副本。如果一个核心修改了其缓存中的数据,其他核心必须能够及时感知这一变化,以保持数据的一致性。为了解决这个问题,各种缓存一致性协议应运而生。
本文将从最基本的总线嗅探技术入手,逐步深入探讨几种主流的缓存一致性协议,特别是MESI协议。我们将详细介绍这些协议的工作原理、优缺点以及对系统性能的影响。希望通过本文的讲解,读者能够对缓存一致性问题有一个全面的理解,并掌握解决这一问题的有效方法。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:github.com/shark-ctrl/...
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 "加群" 即可和笔者和笔者的朋友们进行深入交流。
详解CPU体系结构和数据读写机制
CPU Cache Line是什么
每个CPU都会有自己的二级缓存,其中一级缓存分为数据缓存 和指令缓存 ,这些缓存的数据都是从内存中读取的,而且每次都会加载一个cache line,而CPU Cache Line的物理结构大体如下图所示:
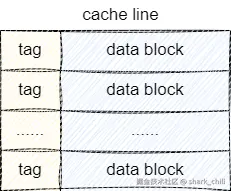
关于cache line的大小可以使用命令键入如下指令进行查看:
getconf LEVEL1_DCACHE_LINESIZE或者:
bash
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size以笔者的服务器为例,可以看到对应的输出结果为64:

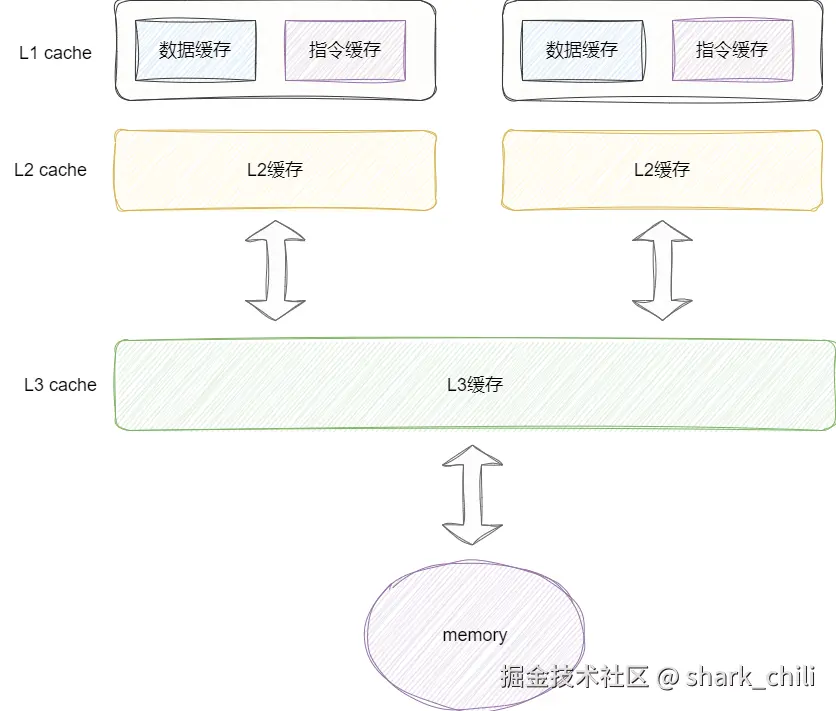
同时对应的我们给出CPU缓存与内存的体系结构图,其中按照数值减小访问速度越快,不同CPU核心都有独立的L1和L2缓存,而L3缓存则是共享缓冲区,与物理内存空间直接打交道:
如果开发者能够很好的使用缓存技术,那么程序的性能就会很高,具体可以参照笔者之前写的这篇文章
计算机组成原理-基于计组CPU的基础知识进行代码调优:blog.csdn.net/shark_chili...
CPU Cache和内存同步技术
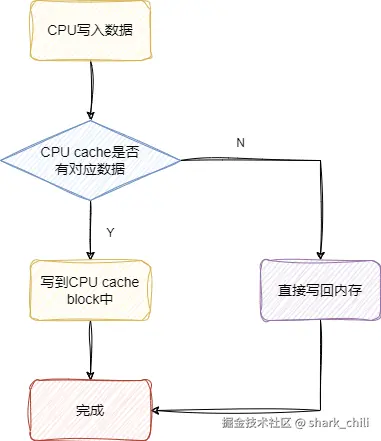
写直达(Write Through)技术
写直达技术解决cache和内存同步问题的方式很简单,例如CPU1要操作变量i,先看看cache中有没有变量i,若有则直接操作cache中的值,然后立刻写回内存。 若变量i不在cache中,那么CPU就回去内存中加载这个变量到cache中进行操作,然后立刻写回内存中。 这样做的好处就是实现简单,缺点也很明显,因为每次都要将修改的数据立刻写回内存,这其中的写入开销对于需要高速运转的CPU是一种灾难:
回写技术(Write Back)
Write Back即一种延迟写技术,为了避免上一种操作频繁写入内存的资源开销而提出的一种方案,它的工作原理是将数据加载到CPU cache并修改但并不立即写入内存,仅仅是将数据标记为dirty,由此减少写入内存的次数。如果没有发生缓存置换,这些数据就不会被写入内存中。
举个例子,CPU cache加载data1到缓存中,并进行数次修改操作,随后cpu cache发生data10不在缓存中需要从内存中加载,又因为cpu cache空间不足,此时触发缓存置换算法便将最近最少使用且是dirty的数据写到内存中,并将data10加载到cpu cache里:
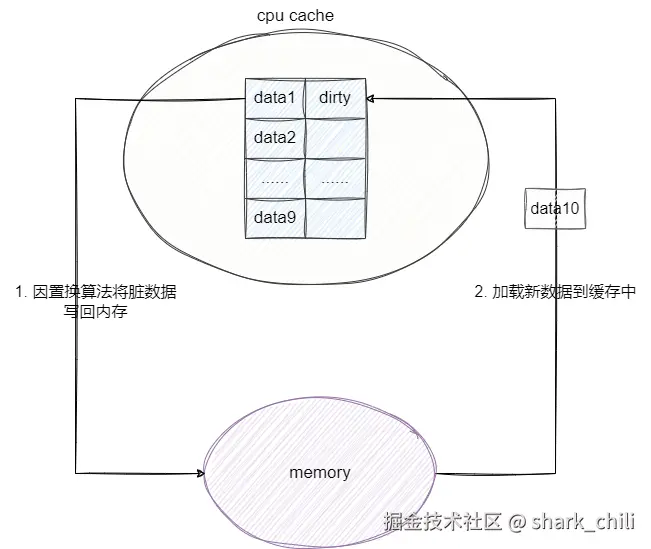
可以看出这种写法如果出现在毫秒级的断电场景可能存在数据丢失问题,又因为延迟写的原因,对应的数据加载在读未命中的情况下存在两次操作:
- 将需要置换的数据写入内存。
- 将需要加载的数据拉到
cpu cache。
这里我们也补充一下几种比较常见的缓存置换算法:
- 最优置换算法(OPT):理论上最优的算法,选择永远不再使用的页面进行淘汰
- 最近最少使用(LRU,Least Recently Used):根据页面使用的时间顺序,淘汰最长时间未被使用的页面
- 先进先出(FIFO,First In First Out):按照页面进入缓存的先后顺序进行淘汰
- 最不经常使用(LFU,Least Frequently Used):根据页面使用频率进行淘汰
在实际的CPU缓存中,通常采用近似LRU的算法来实现缓存置换。
详解CPU缓存一致性问题
多核心缓存修改问题
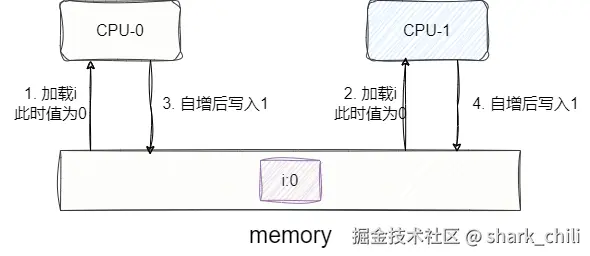
当一台计算机由多核CPU构成的时候,每个CPU都从内存里加载相同的变量i(初值为0)进行累加操作,我们试想这种情况:
CPU-0加载内存变量i值为0。CPU-0自增为1准备写回内存。CPU-1加载内存变量i值为0。CPU-1自增为1准备写回内存。
两次自增操作后,变量i的最终结果是1而不是期望的2,这就是经典的缓存一致性问题:
而解决这个问题我们只要攻破以下两点问题即可:
- 写传播问题 :即当前
Cache中修改的值要让其他CPU知道 - 事务串行化 :例如
CPU1先将变量i改为100,CPU2再将基于当前变量i的值乘2。我们必须保证变量i先加100,再乘2。
总线嗅探(Bus Snooping)
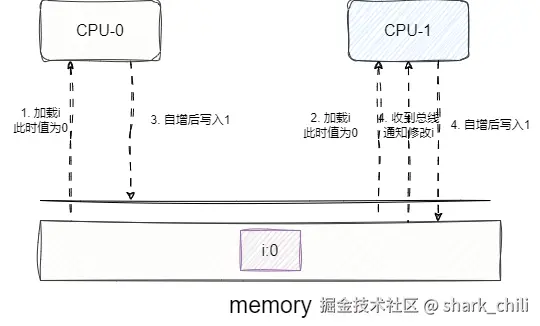
总线嗅探是解决写传播问题的解决方案。举个例子,当CPU1更新Cache中变量i的值时,就会通过总线通知其他核心变量i已被修改,当其他CPU发现自己Cache中也有这个值的时候就会将自己缓存中的该值标记为无效或更新为最新值。
这种方式缺点很明显,CPU必须无时不刻监听总线上的变化,而且出现变化的数据自己还不一定有,这样的作法增加了总线的压力:
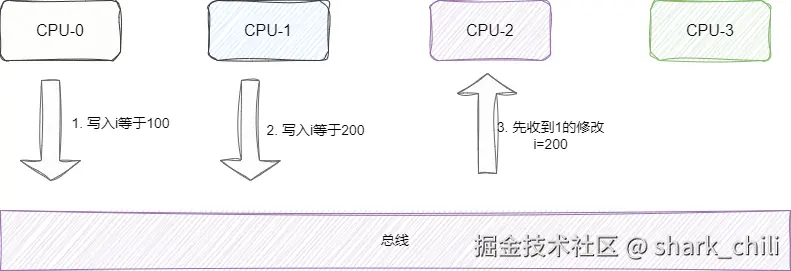
而且也不能保证事务串行化,如下图,CPU-0加载了变量并修改了值通知其他CPU这个值有变化了。 而CPU-1也修改了同一个变量的值,按照正常的逻辑CPU-2、CPU-3应该先收到CPU-0的通知将变量改为100,再收到CPU-1的通知将变量改为200。
但是由于网络延迟等原因,CPU-3可能先收到CPU-1的通知先改为200再收到CPU-0的通知改为100,这就导致了数据不一致的问题,即事务串行化失败:
MESI协议如何解决上述问题
MESI是总线嗅探的改良版,它很好地解决了总线的带宽压力,以及很好地解决了数据一致性问题。 在介绍MESI之前,我们必须了解以下MESI的四种状态:
M(Modified,已修改):CPU当前L1 cache中某个变量的数据被修改了,且这个数据在其他核心中都没有副本,数据与内存不一致。E(Exclusive,独占):CPU将数据加载到自己的L1 cache时,其他核心的cache中并没有这个数据,所以CPU将这个数据加载到自己的cache时标记为E,数据与内存一致。S(Shared,共享):说明CPU在加载这个数据时,其他CPU已经加载过这个数据了,这时CPU就会从其他CPU或内存中拿到这个数据并加载到L1 cache中,并且所有拥有这个值的CPU都会将cache中的这个值标记为S,数据与内存一致。I(Invalidated,已失效):当CPU修改了L1 cache中的变量时,发现这个值是S即共享的数据,那么就需要通知其他核心这个数据被改了,其他CPU都需要将cache中的这个值标为I,后面要操作时,必须重新从内存或其他核心获取最新的数据再进行操作。
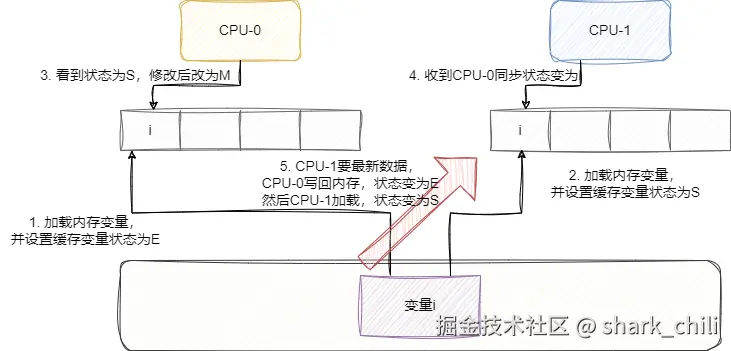
好了介绍完这几个状态之后,我们不妨用一个例子过一下这个流程:
CPU-0要加载变量i,发现变量i不在cache中,于是去内存中加载数据,此时通过总线发个消息给其他核心,其他核心的cache中并没有这条数据,所以这个变量在CPU-0的cache中的状态为E(独占)。CPU-1也加载这个数据了,在总线上发了个消息,发现CPU-0有这个数据且并没有修改或者失效的标志,于是它们一起将这个变量i状态设置为S(共享)。CPU-0要修改变量i值了,发消息给其他核心,其他核心收到消息将自己的变量i设置为I(无效),CPU-0改完后将数据设置为M(已修改)。CPU-0又要修改变量i的值了,而且看到变量i的状态为M(已修改),说明这个值是最新的数据,所以不发消息给其他核心了,直接更新即可。CPU-1要加载变量i,发现状态为I,于是CPU-0将值写回内存,此时状态变为E,然后CPU-1读取这个值,大家状态都变为S共享。CPU-0要加载新的变量x了,而且变量x要使用的cache空间正是变量i的,所以CPU-0将值写回内存中,这时候内存和最新数据同步了。
为了更清晰地理解MESI协议的状态转换,我们可以用下图来表示四种状态之间的转换关系:
MESI状态转换图
在这个状态转换图中:
- 读操作可能导致状态从I转为S或E
- 写操作可能导致状态从E或S转为M
- 来自其他核心的读操作可能导致状态从E转为S
- 来自其他核心的写操作可能导致状态从S或E转为I
小结
自此,我们从多核CPU体系结构所引发缓存一致性问题为入手,再从总线嗅探到MESI协议深度讲解了缓存一致性问题的解决方案。
MESI协议作为现代多核处理器中广泛采用的缓存一致性协议,对软件开发也有重要影响。例如,在Java中,volatile关键字的实现就依赖于CPU的缓存一致性机制。当一个变量被声明为volatile时,JVM会确保每次读取都从主内存中获取最新值,每次写入都立即刷新到主内存,这与MESI协议中的状态转换密切相关。
需要注意的是,虽然MESI协议解决了缓存一致性问题,但它也会带来一定的性能开销。频繁的缓存状态转换和总线通信会消耗系统资源,特别是在高并发场景下。因此,在实际编程中,我们需要在数据一致性和性能之间找到平衡点。
希望本文对理解CPU缓存一致性问题有所帮助。
我是 sharkchili ,CSDN Java 领域博客专家 ,mini-redis 的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:github.com/shark-ctrl/...
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 "加群" 即可和笔者和笔者的朋友们进行深入交流。
参考
一小时,完全搞懂 cpu 缓存一致性 :zhuanlan.zhihu.com/p/651732241
全知乎最详细的并发研究之CPU缓存一致性协议(MESI)有这一篇就够了!:zhuanlan.zhihu.com/p/467782159
本文使用 markdown.com.cn 排版