一、身份证号码识别案例介绍(基于 OpenCV 与 Python)
身份证号码识别是计算机视觉领域中证件信息提取的典型应用,广泛用于身份验证、信息录入自动化等场景。本案例基于 Python 的 OpenCV 库实现身份证号码的定位与识别,主要流程包括图像预处理、号码区域定位、字符分割和字符识别四个核心步骤。
技术栈
- 编程语言:Python 3.x
- 核心库 :
- OpenCV(
cv2):用于图像处理、轮廓检测、形态学操作等 - NumPy:用于数值计算和数组处理
- (可选)Tesseract OCR:用于字符识别(需配合
pytesseract库)
- OpenCV(
实现流程
-
图像预处理
- 读取身份证图像并转为灰度图,减少颜色通道干扰
- 进行阈值分割(如 OTSU 算法),将图像转为黑白二值图
- 应用高斯模糊去除噪声,使用形态学操作(腐蚀 / 膨胀)增强字符边缘
-
号码区域定位
- 利用轮廓检测(
findContours)识别图像中的矩形区域 - 根据身份证号码的固定位置特征(底部 18 位数字)和宽高比例筛选目标区域
- 提取定位到的号码区域并进行角度校正(若图像存在倾斜)
- 利用轮廓检测(
-
字符分割
- 对号码区域进行垂直投影分析,确定每个字符的边界
- 按顺序分割出 18 个独立字符(包含数字和最后一位可能的字母 X)
- 统一字符尺寸并标准化(如转为 28×28 像素),便于后续识别
-
字符识别
- 方法一(传统 OCR):使用 Tesseract OCR 直接识别分割后的字符
- 方法二(机器学习):训练简单的 CNN 模型或使用预训练模型对字符分类
- 输出识别结果并校验(如验证 18 位身份证号码的校验位合法性)
二、数据准备
sfz.jpg

sfzh.png
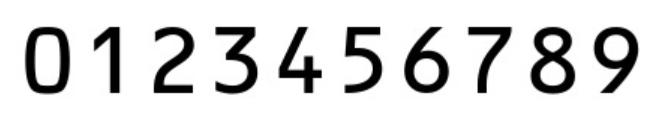
三、代码详解
1. 导入库和基础函数定义
python
import cv2
# 绘图展示函数
def cv_show(name, image):
cv2.imshow(name, image) # 显示图像,第一个参数是窗口名称,第二个是图像数据
cv2.waitKey(0) # 等待用户按键,0表示无限等待cv2是 OpenCV 库的 Python 接口,用于图像处理cv_show函数封装了显示图像的功能,简化了重复调用的代码量
python
def sort_contours(cnts, method='left-to-right'):
reverse = False
i = 0
# 判断是否需要反转排序结果
if method == "right-to-left" or method == 'bottom-to-top':
reverse = True
# 确定排序依据的坐标 (x或y)
if method == 'top-to-bottom' or method == 'bottom-to-top':
i = 1 # 按y坐标排序
# 计算每个轮廓的边界框
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
# 将轮廓和边界框配对并排序
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], # 按指定坐标排序
reverse=reverse))
return cnts, boundingBoxes- 这个函数用于对轮廓进行排序,支持四种排序方式:从左到右、从右到左、从上到下、从下到上
- 排序基于轮廓的边界框坐标,通过
boundingRect获取每个轮廓的最小外接矩形 - 使用
sorted函数和自定义的排序键实现按指定方向排序
2. 模板图像中的数字定位处理
# 读取模板图像
img = cv2.imread("sfzh.png")
cv_show('img', img) # 显示原始模板图像
# 转为灰度图
gray = cv2.imread("sfzh.png", 0)
# 阈值处理:将灰度图转为二值图,使用反阈值化(THRESH_BINARY_INV)
# 大于150的像素设为0,小于等于150的设为255
ref = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)[1]
cv_show('ref', ref) # 显示处理后的二值图- 这部分代码处理模板图像(包含 0-9 数字的图像)
- 首先读取图像并显示,然后转为灰度图(简化图像处理)
- 阈值处理将图像转为黑白二值图,反阈值化使得数字变为白色,背景变为黑色

python
# 查找轮廓
# cv2.findContours()接受二值图,返回三个值:图像、轮廓列表、层次结构
_, refCnts, hierarchy = cv2.findContours(ref, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在原始图像上绘制轮廓,-1表示绘制所有轮廓,颜色为绿色(0,255,0),线宽2
cv2.drawContours(img, refCnts, -1, (0, 255, 0), 2)
cv_show('img', img) # 显示带有轮廓的图像cv2.findContours用于检测图像中的轮廓cv2.RETR_EXTERNAL只检测外轮廓cv2.CHAIN_APPROX_SIMPLE只保留轮廓的终点坐标,简化轮廓信息
- 绘制轮廓是为了可视化检测结果,确认是否正确识别了所有数字的轮廓

python
# 按从左到右的顺序对轮廓排序
refCnts = sort_contours(refCnts, method='left-to-right')[0]
# 存储模板中每个数字对应的像素值
digits = {}
# 遍历每个轮廓
for (i, c) in enumerate(refCnts):
# 获取轮廓的边界框坐标
(x, y, w, h) = cv2.boundingRect(c)
# 提取数字区域,适当扩大边界(-2和+2)以确保包含完整数字
roi = ref[y - 2:y + h + 2, x - 2:x + w + 2]
# 调整大小为统一尺寸(57,88),便于后续模板匹配
roi = cv2.resize(roi, (57, 88))
# 按位取反:将黑白反转,使数字变为黑色,背景变为白色
roi = cv2.bitwise_not(roi)
cv_show('roi', roi) # 显示每个提取的数字
# 存储到字典中,i为键,对应的数字图像为值
digits[i] = roi
# 关闭所有打开的窗口
cv2.destroyAllWindows()- 对轮廓进行排序是为了确保数字顺序正确(0-9 的顺序)
- 对于每个轮廓,提取其对应的数字区域(ROI - Region of Interest)
- 统一调整所有数字的大小,是为了后续模板匹配时尺寸一致
- 按位取反操作是为了统一图像的黑白模式,便于匹配
- 最终将所有数字模板存储在字典中,供后续识别使用
3. 身份证号识别
python
# 读取身份证图像
img = cv2.imread('sfz.jpg')
imgg = img.copy() # 创建副本用于后续绘制结果
cv_show('img', img) # 显示原始身份证图像
# 转为灰度图
gray = cv2.imread('sfz.jpg', 0)
cv_show('gray', gray) # 显示灰度图
# 阈值处理,将灰度图转为二值图
ref = cv2.threshold(gray, 120, 255, cv2.THRESH_BINARY_INV)[1]
cv_show('ref', ref) # 显示处理后的二值图- 这部分开始处理实际的身份证图像
- 同样先读取图像,转为灰度图,再进行阈值处理得到二值图
- 这里使用的阈值 (120) 与模板处理时不同,因为身份证图像和模板图像的亮度可能不同

python
# 查找身份证图像中的轮廓
_, refCnts, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制所有轮廓并显示
a = cv2.drawContours(img.copy(), refCnts, -1, (0, 255, 0), 2)
cv_show('img', a)- 同样使用
findContours检测轮廓,但这里检测的是身份证图像中的所有外轮廓 - 绘制轮廓是为了查看哪些区域被识别为轮廓,帮助确定后续筛选条件
python
# 存储数字区域的位置信息
locs = []
# 遍历每个轮廓
for (i, c) in enumerate(refCnts):
# 获取轮廓的边界框
(x, y, w, h) = cv2.boundingRect(c)
# 根据位置筛选出身份证号码区域
# 这里的数值(330<y<360和x>220)是根据特定身份证图像的数字位置设置的
if (330 < y < 360) and x > 220:
locs.append((x, y, w, h)) # 符合条件的区域加入列表
# 按x坐标排序,确保数字顺序正确(从左到右)
locs = sorted(locs, key=lambda x: x[0])- 这是关键的筛选步骤,通过轮廓的位置坐标来识别身份证号码所在区域
- 条件
(330 < y < 360) and x > 220是根据特定身份证图像中号码的大致位置设定的- 实际应用中可能需要根据不同的身份证图像调整这些数值
- 对筛选出的区域按 x 坐标排序,保证数字的顺序正确
python
import numpy as np # 导入numpy库用于数值计算
output = [] # 存储识别结果
# 遍历每个数字区域
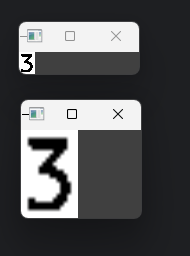
for (i, (gX, gY, gW, gH)) in enumerate(locs):
# 提取数字区域,适当扩大边界
group = gray[gY - 2:gY + gH + 2, gX - 2:gX + gW + 2]
# cv_show('group', group) # 显示提取的数字区域
# 预处理:自适应阈值处理,自动确定最佳阈值
group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group) # 显示处理后的数字区域
# 调整大小,与模板尺寸一致(57,88)
roi = cv2.resize(group, (57, 88))
cv_show('roi', roi) # 显示调整后的数字区域- 对于每个筛选出的数字区域,进行提取和预处理
- 使用
THRESH_OTSU方法让 OpenCV 自动计算最佳阈值,适应不同的光照条件 - 调整数字区域大小,使其与之前准备的模板尺寸一致,以便进行匹配
python
'''-------使用模板匹配,计算匹配得分-----------'''
scores = []
# 在模板中计算每一个数字的匹配得分
for (digit, digitROI) in digits.items():
# 模板匹配,使用cv2.TM_CCOEFF方法
result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result) # 获取最大匹配值
scores.append(score) # 存储得分
# 找到得分最高的模板对应的数字
jieguo = str(np.argmax(scores))
output.append(jieguo) # 添加到结果列表- 这是识别的核心步骤,使用模板匹配来识别数字
cv2.matchTemplate将待识别的数字与每个模板数字进行比较,返回匹配得分cv2.TM_CCOEFF是一种匹配方法,值越大表示匹配度越高- 通过
np.argmax找到得分最高的模板,其对应的键就是识别出的数字
python
# 在图像上绘制矩形框和识别结果
cv2.rectangle(imgg, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
# 在图像上添加识别出的数字文本
cv2.putText(imgg, jieguo, (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)- 可视化识别结果,在每个数字周围绘制红色矩形框
- 使用
cv2.putText在数字上方显示识别出的结果 - 参数分别为:图像、文本、位置、字体、大小、颜色、线宽
python
# 打印最终识别结果
print("Card ID #: {}".format("".join(output)))
# 显示最终结果图像
cv2.imshow("Image", imgg)
cv2.waitKey(0) # 等待用户按键
cv2.destroyAllWindows() # 关闭所有窗口- 将识别结果拼接成字符串并打印
- 显示最终的识别结果图像,包含所有数字的框选和识别结果
- 最后清理资源,关闭所有窗口
