问题
在做通讯录、人员列表等功能时,经常会碰到按照中文拼音排序的问题。
我们在这里可以用一个简单的例子进行说明
先创建测试数据
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
INSERT INTO user (name) VALUES
('张三'),('李四'),('王五'),('赵六'),('钱七'),('孙八'),('周九'),('吴十');下面,我们希望查出数据,并且按照中文拼音顺序排序
很简单,这样就行了
sql
SELECT * FROM user ORDER BY name;可是,执行后却发现,结果似乎并不符合预期
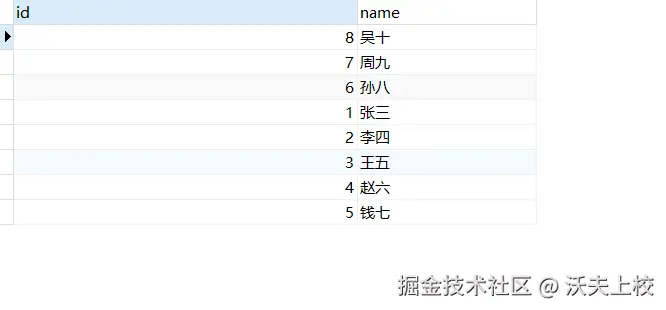
这其实是因为,MySQL 默认字符集排序:
utf8mb4_general_ciutf8mb4_unicode_ci
这些排序是 按 Unicode 编码点排序,而不是拼音顺序。
那么,我怎么实现中文拼音排序呢?
解决办法
方法一
默认字符集排序不支持,那我不用默认字符集不就行了,看我的
sql
SELECT * FROM user ORDER BY CONVERT(NAME USING gbk);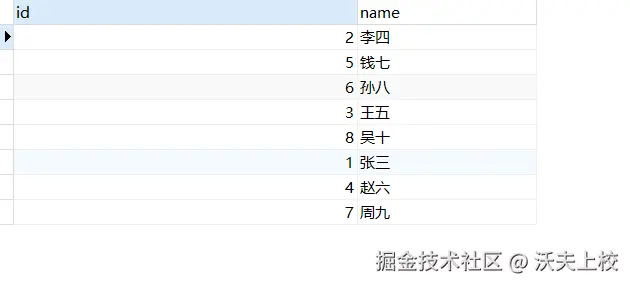
如果在 xml 里面使用,注意使用
CDATA包裹
xml
<select id="listUsers" resultType="User">
SELECT id, name
FROM user
ORDER BY <![CDATA[CONVERT(name USING gbk)]]>
</select>可行是可行,但是每次查询都要做编码转化,有没有更简单粗暴的方法?
方法二
有的兄弟,有的
我们可以跳过编码转化这一个步骤,添加一个冗余字段,在数据变更时写入拼音不就行了(空间换时间打法还是太强了)
我们先添加字段
sql
ALTER TABLE user
ADD COLUMN pinyin VARCHAR(100) AFTER name;再导入这样一个依赖
xml
<dependency>
<groupId>com.belerweb</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.1</version>
</dependency>再建立对应工具类
java
public class PinyinUtil {
/**
* @param chinaStr 中文字符串
* @return 中文字符串转拼音 其它字符不变
*/
public static String getPinyin(String chinaStr){
HanyuPinyinOutputFormat formart = new HanyuPinyinOutputFormat();
formart.setCaseType(HanyuPinyinCaseType.LOWERCASE);
formart.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
formart.setVCharType(HanyuPinyinVCharType.WITH_V);
char[] arrays = chinaStr.trim().toCharArray();
String result = "";
try {
for (int i=0;i<arrays.length;i++) {
char ti = arrays[i];
if(Character.toString(ti).matches("[\u4e00-\u9fa5]")){ //匹配是否是中文
String[] temp = PinyinHelper.toHanyuPinyinStringArray(ti,formart);
result += temp[0];
}else{
result += ti;
}
}
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
return result;
}
}PinyinUtil.getPinyin()会根据中文字符串 返回对应的拼音字符串
在涉及到数据变更(新增、修改、导入等场景)时,写入冗余字段就行
java
String pinyin = PinyinUtil.getPinyin(name);
user.setPinyin(pinyin);我们的测试数据表在经过处理后,就变成了这样
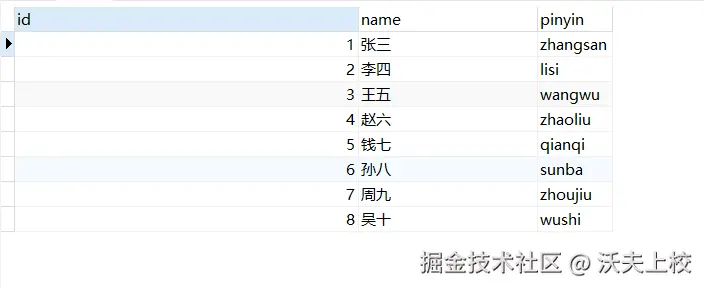
查询时,对冗余字段排序即可
sql
SELECT * FROM user ORDER BY pinyin;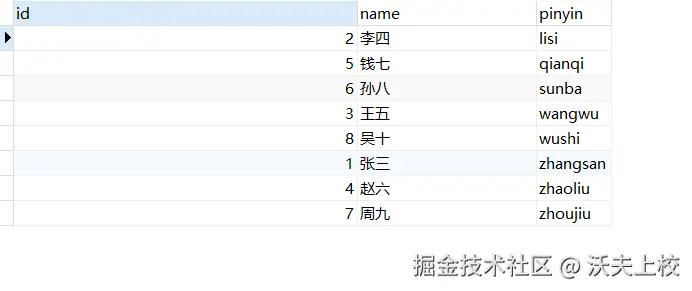
当数据量超过 几百万条以上 ,方法二的优势会明显
当然,方法一不用做多余操作,直接sql搞定,也是一个优点