关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
中文乱码是一个常见且令人头疼的问题,它通常发生在字符编码和解码方式不匹配的时候。本文将系统地讲解乱码的成因,并提供从简单到复杂的解决方案。
02 乱码的根源
编码与解码不匹配
计算机底层存储的是二进制(0和1)。编码(Encode) 是将字符(如"中")转换为二进制的过程,而解码(Decode) 则是将二进制转换回字符的过程。常见的编码格式有:
UTF-8: 目前互联网上的首选标准,兼容ASCII,一个中文字符通常占3个字节。GBK/GB2312: 中文Windows系统的默认编码,一个中文字符占2个字节。ISO-8859-1: 早期HTTP协议默认的编码标准,不支持中文,也是程序世界中最常见的编码,90%的中文乱码都是它引起的。
乱码的本质就是: 用编码A(如UTF-8)将文字转换为二进制,却用编码B(如GBK)去解码这些二进制。
03 常见场景及解决方案
3.1 网页浏览器中的乱码
表现: 网页上的中文变成一堆问号 ??? 或乱码符号 çˉè¯>>。
解决方法:
1、手动选择编码:需要借助浏览器的扩展插件,选择不同的编码,UTF-8是的首选。
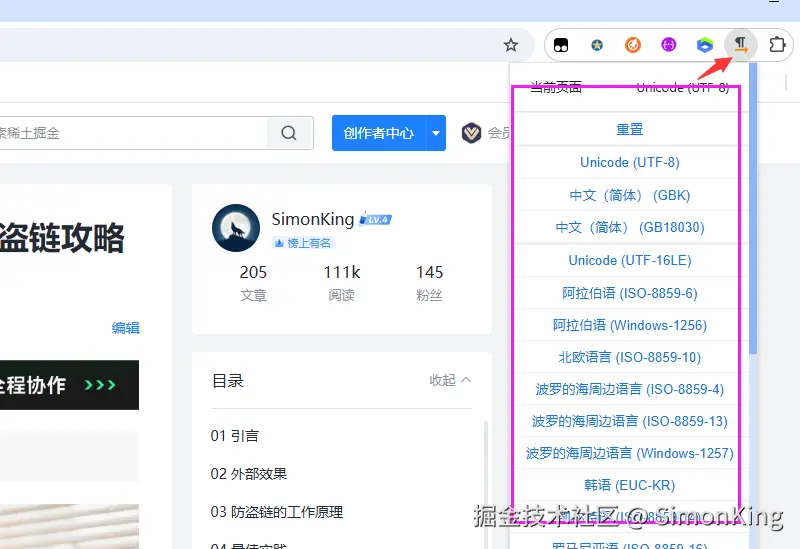
这里不得不提一下谷歌浏览器的这款插件,由于之前升级了谷歌浏览器的版本,导致该插件无法使用。因为此插件使用起来非常流畅,使用其他插件不习惯,就给插件的作者在Github上提了issue,没想到作者很快给了回复,并支持了最新版的谷歌浏览器。
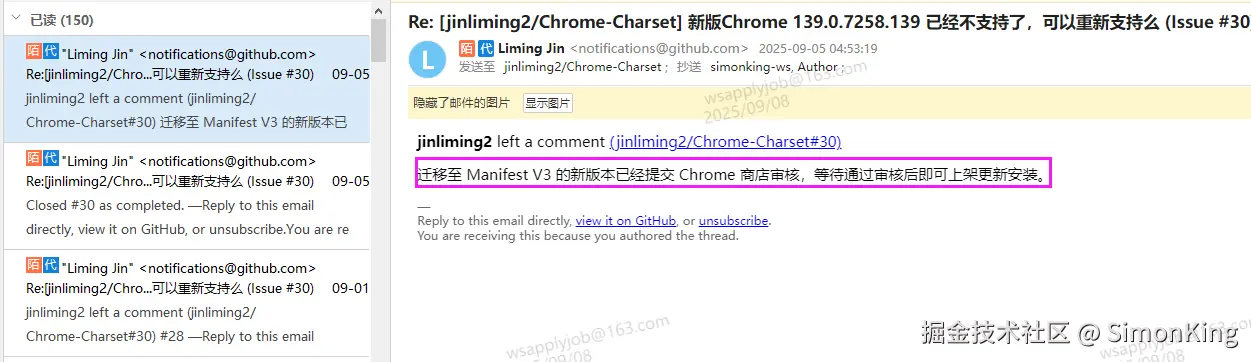
必须给作者点赞!!!
GitHub地址:github.com/jinliming2/...
2、源码层解决:网页开发者必须在HTML的 <head> 标签内明确声明字符集,<meta charset="UTF-8"> 这是最重要的做法,确保浏览器始终使用UTF-8解析。
3.2 编程中处理文件或网络请求
如:
HttpClient
这是最复杂的场景,下面以Java语言为例。
问题: 使用 EntityUtils.toString() 时未指定编码,它会使用默认的ISO-8859-1,导致中文乱码。
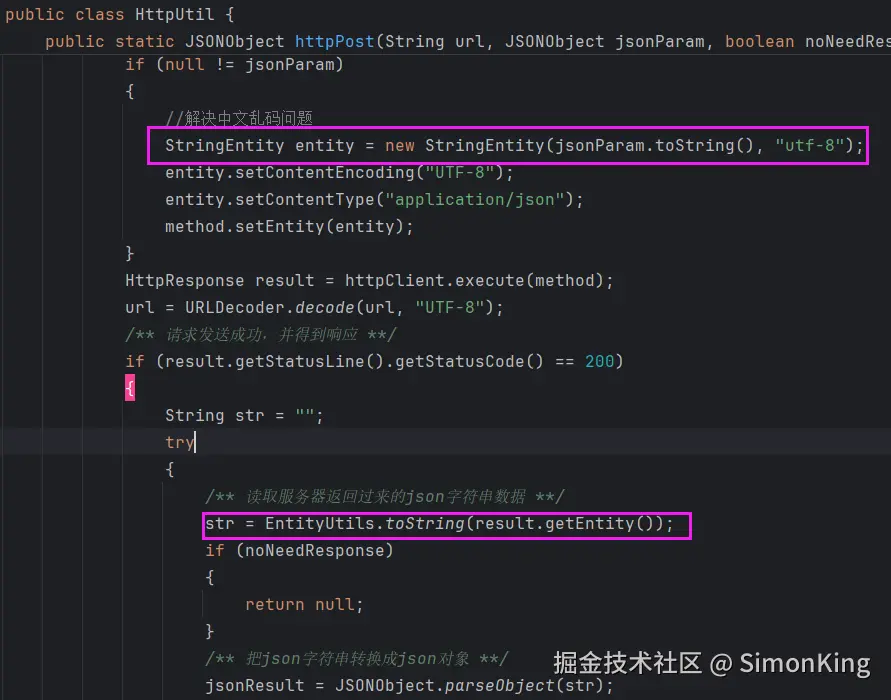
如图,在调用其他人封装的HttpClient方法时,大概扫了一眼,StringEntity都加了utf-8的编码,想着应该不会有问题。不出意外的话,就出意外了,调用第三方接口直接乱码,真实让人抓狂。
不得已,只能认真读代码,才发现EntityUtils.toString() 未指定编码,默认是ISO-8859-1,导致乱码,如下图。
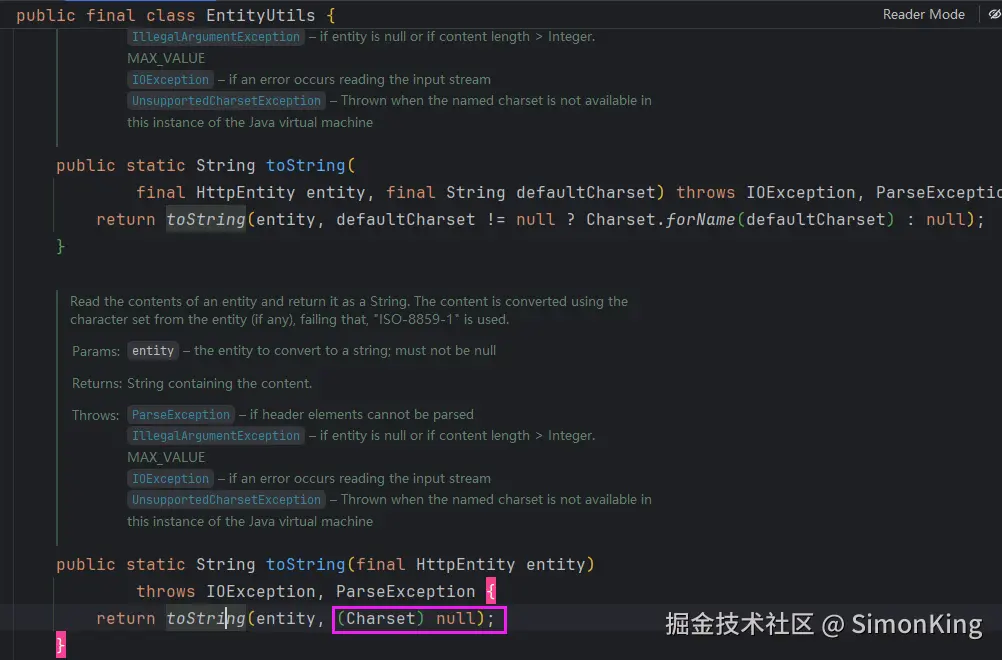
修改源代码,问题解决:
java
EntityUtils.toString(result.getEntity(), StandardCharsets.UTF_8)3.3 IDE或文本编辑器中的代码文件乱码
表现: 代码里的中文注释或字符串显示为乱码。
解决方法:
- 用IDE(如VSCode, IntelliJ IDEA)或高级文本编辑器(如Sublime Text, Notepad++)打开文件。
- 在右下角找到当前文件的编码显示(如
UTF-8、GBK)。 - 点击它,选择 "通过编码重新打开" (Reopen with Encoding),尝试不同的编码直到显示正常。
- 如果显示正常了,再次点击编码,选择 "随编码保存" (Save with Encoding),并统一保存为
UTF-8,这是现代项目的标准。
3.4 数据库乱码
表现: 从数据库读出的中文是乱码。
解决方法:
-
确保数据库、表、字段的字符集设置为统一的
UTF-8系列(如utf8mb4)。sql-- 创建数据库时指定 CREATE DATABASE mydb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -- 修改已有表的字符集 ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -
确保连接数据库时,在连接字符串(JDBC URL)中指定编码:
sqljdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8
04 小结
要系统地解决和避免中文乱码,请遵循以下原则:
- 统一编码 :在整个项目生命周期中强制使用
UTF-8。包括IDE设置、代码文件、数据库、HTTP通信等。 - 明确声明 : 在任何需要声明编码的地方都明确指定(如HTML的
<meta>标签、数据库建表语句、文件保存格式)。 - 谨慎转换 :在处理数据时,明确知道数据当前的编码和目标编码,使用可靠的工具库(如Java的
InputStreamReader)进行转换。 - 怀疑精神 : 不要完全信任外部系统(如某些老旧网站或
API)返回的编码声明,当其声明不可靠时,要有能力手动指定或通过分析字节模式来推断正确编码。
你遇到过中文乱码么?又是怎么解决的呢?