这几天逛淘股吧,发现好些牛人说低价股的春天要来了😂
那到底是真春天还是假春天,今天花姐就从量化角度 帮大家扒一扒,用数据告诉你低价股现在到底行不行。
一、分析动机
我们想知道:A股市场上,是高价股表现更好,还是低价股更占优势?
如果低价股表现更强,我们的策略可以适当加仓;反之,则需要关注高价股的避险属性。
二、分析步骤
1、历史行情数据下载
首先我们通过xtquant+miniQMT把历史行情下载到本地feather文件,行情文件包括code date open high low close preClose volume amount列。
python
from xtquant import xtdata
import pandas as pd
import tqdm
import os
def down_load_sector():
'''
下载行业板块数据
'''
# 用这个方法代替xtdata.download_sector_data(),解决xtdata.download_sector_data()卡死的问题
client = xtdata.get_client()
client.down_all_sector_data()
def get_stock_pool():
'''
获取股票池,返回全部A股的代码和对应的股票名称
'''
ret =[]
stocks = xtdata.get_stock_list_in_sector("沪深A股")
stocks_bj = xtdata.get_stock_list_in_sector("BJ")
info_list = xtdata.get_instrument_detail_list(stocks)
for stock in stocks:
name = info_list[stock]['InstrumentName']
ret.append({"code":stock,"name":name})
info_list_bj = xtdata.get_instrument_detail_list(stocks_bj)
for stock in stocks_bj:
name = info_list_bj[stock]['InstrumentName']
ret.append({"code":stock,"name":name})
df = pd.DataFrame(ret)
df = df.sort_values(by="code")
df.to_csv("沪深京A股股票池.csv",index=False)
return df
def download_his(perid='1d',incrementally=True,is_batches=False):
pool = pd.read_csv("沪深京A股股票池.csv")
print(f"开始下载股票历史{perid}:数据总计 {len(pool)}个股票")
if is_batches:
step = 300
# 分批下载数据 500个股票一组
total_batches = (len(pool) + step - 1) // step
for idx in tqdm.trange(total_batches, desc=f"正在下载 {perid} 数据", unit="batch"):
i = idx * step
batch = pool.iloc[i:i + step]
xtdata.download_history_data2(batch['code'].tolist(), period=perid,start_time='',end_time='', incrementally=incrementally)
else:
for code in tqdm.tqdm(pool['code'], desc=f"正在下载 {perid} 数据", unit="stock"):
xtdata.download_history_data(code, period=perid,start_time='',end_time='', incrementally=incrementally)
print(f"股票历史{perid}下载完成")
def data_to_feather(period='1d',start_time='19900101'):
'''
将数据转换为feather格式
'''
print(f"开始转换{period}数据为feather格式")
pool = pd.read_csv("沪深京A股股票池.csv")
data_dir = os.path.join("data", f"{period}")
if not os.path.exists(data_dir):
os.makedirs(data_dir)
for code in tqdm.tqdm(pool['code'], desc="导出数据为feather格式"):
file_path = os.path.join(data_dir,f"{code}.feather")
data = xtdata.get_local_data([],stock_list=[code],period=period,start_time=start_time,count=-1,dividend_type="front_ratio")
df = data[code]
df['code'] = code
if 'd' in period:
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d')
if 'm' in period:
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d%H%M%S')
df['date'] = df.index
df = df[['code','date', 'open', 'high', 'low', 'close','preClose', 'volume', 'amount']]
df = calc_limit_up_down(df,code)
df.to_feather(file_path)
print(f"{period}数据转换为feather格式完成")
def calc_limit_up_down(df: pd.DataFrame, code: str, close_col: str = 'preClose') -> pd.DataFrame:
"""
根据 preClose 列计算涨跌停价,并返回带 limitUp/limitDown 列的新 DataFrame
:param df: 含有 preClose 列的 DataFrame
:param code: 股票代码(用来判断涨跌幅限制)
:param close_col: 收盘价列名,默认是 'preClose'
:return: 新增 limitUp、limitDown 列的 DataFrame
"""
# 判断涨跌幅限制
if code[:2] in ['60','00']:
limit_ratio = 0.1
elif code[:2] in ['30','68','69']:
limit_ratio = 0.2
else: # 北交所(8、4、9 开头)
limit_ratio = 0.3
# 涨停价
def calc_limit_up(price: float) -> float:
return round(price * (1 + limit_ratio), 2)
# 跌停价
def calc_limit_down(price: float) -> float:
return round(price * (1 - limit_ratio), 2)
df = df.copy()
df['limitUp'] = df[close_col].apply(calc_limit_up)
df['limitDown'] = df[close_col].apply(calc_limit_down)
return df
if __name__ == "__main__":
down_load_sector()
get_stock_pool()
download_his(perid='1d',incrementally=True)
data_to_feather(period='1d',start_time='20240101')2、把行情读取到内存
通过简单的循环我们将需要的数据读取到内存中
python
def load_data():
'''
读取数据
'''
period = '1d'
data_dir = os.path.join("data", f"{period}")
pool = pd.read_csv("沪深京A股股票池.csv")
all_data = []
for code in tqdm.tqdm(pool['code'], desc="读取数据"):
file_path = os.path.join(data_dir,f"{code}.feather")
if os.path.exists(file_path):
df = pd.read_feather(file_path)
all_data.append(df)
all_data_df = pd.concat(all_data, ignore_index=True)
return all_data_df3、按价格分组
这里根据某日的价格把股票按照价格分成10组,1组表示价格最低的股票,10组表示价格最高的股票
python
def grouy_data(df, date, price_col='close'):
"""
根据股票date日期的收盘价把股票分成10组
"""
df = df.copy()
# 确保按日期升序排列
df = df[df['date']==date].copy()
# 分10组
df['group'] = pd.qcut(df[price_col], 10, labels=False) + 1
return df这里用到了一个qcut方法,它会把数据分成指定的数量 q个区间,每个区间内的数据数量尽量相等(数量均分,而不是值均分!)。比如你有 100 个股票的收盘价,pd.qcut(..., 10) 就是 分成10组,每组大约 10 个股票(如果数据量能整除的话)。
4、数据统计
统计每个分组从n日开始到最新收盘价平均涨幅情况
python
def avg_return_by_group(all_data_df, grouy_data, begin_date):
"""
计算每组的平均收益率
"""
all_data_df = all_data_df.copy()
grouy_data = grouy_data.copy()
# 把分组信息(group)带回整个数据集
all_data_df = all_data_df.merge(grouy_data[['code', 'group']], on='code', how='inner')
all_data_df = all_data_df.sort_values(['code', 'date'])
# 计算每日收益率
all_data_df['ret'] = all_data_df.groupby('code')['close'].pct_change()
# 从 begin_date 开始,每组的平均收益
df_filtered = all_data_df[all_data_df['date'] >= begin_date]
avg_ret = (
df_filtered.groupby(['date', 'group'])['ret']
.mean()
.reset_index()
)
# 转换成累计收益曲线
avg_ret['cum_ret'] = (
avg_ret.groupby('group')['ret']
.cumsum()
)
return avg_ret把收益绘制出来方便对比
python
def draw_avg_return(avg_ret,begin_date):
"""
绘制每组的平均收益率曲线
"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(10,6))
for g, data in avg_ret.groupby('group'):
plt.plot(data['date'], data['cum_ret']*100, label=f'第{g}组') # 乘以100转换为百分比
plt.legend()
plt.title(f'各分组累计平均收益率走势(自{begin_date}起)')
plt.xlabel('日期')
plt.ylabel('累计平均收益率')
plt.show()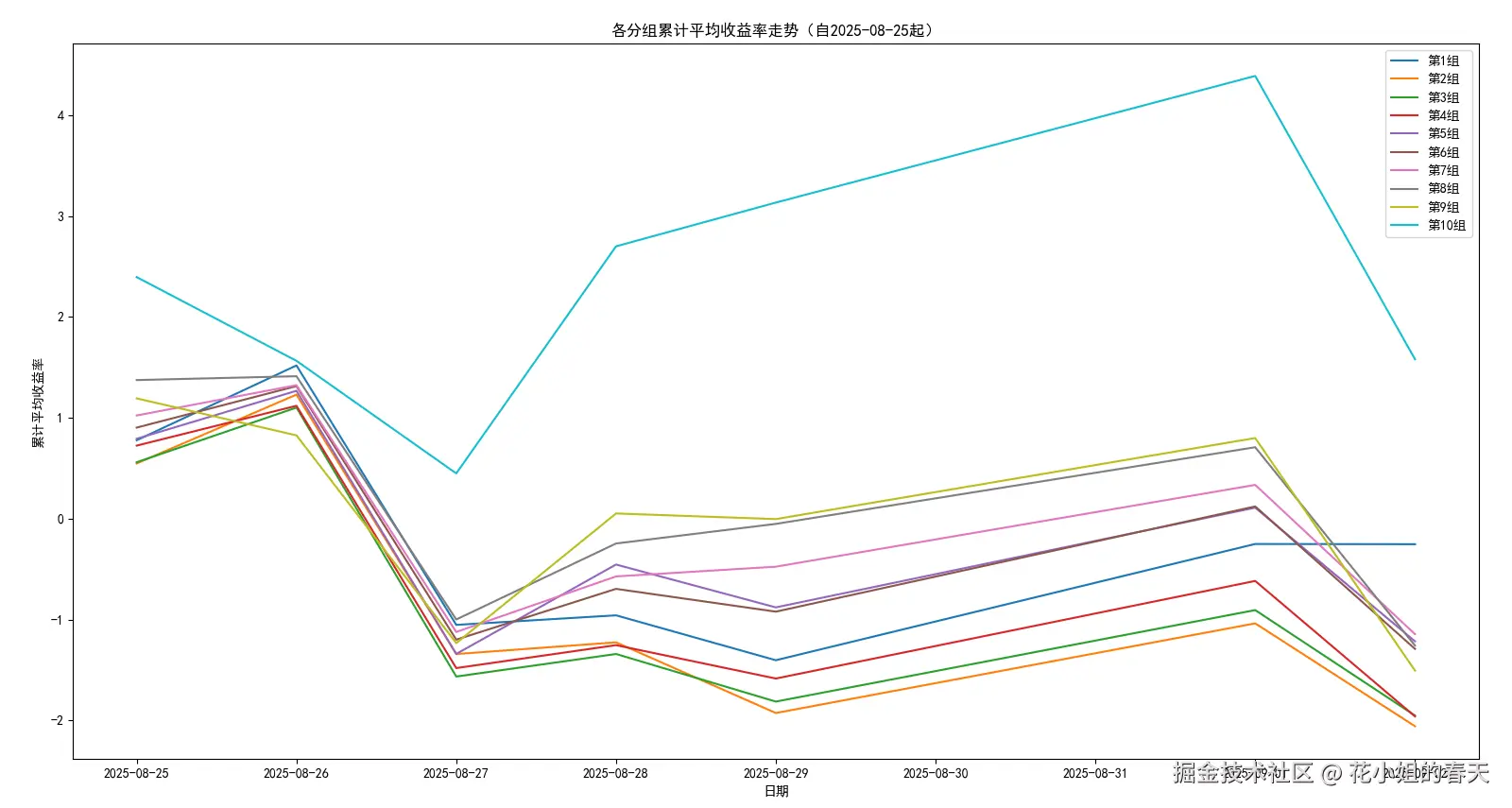
从图上我们可以看到10组的平均收益要明显高于其它分组,说明高价龙头股是这段时间的市场主线,资金主要集中在这类股票。
9月2日指数回调,近4000家个股下跌,除了1组其它回调都很大,可以从侧面验证资金可能开始切换到低价股了。
统计下每个分组这一段时间涨跌停情况 首先是一个计算涨跌停的方法,这里没考虑st的情况,在下载历史数据的时候我们已经用这个方法把涨跌停价格存放到行情数据文件里了。
python
def calc_limit_up_down(df: pd.DataFrame, code: str, close_col: str = 'preClose') -> pd.DataFrame:
"""
根据 preClose 列计算涨跌停价,并返回带 limitUp/limitDown 列的新 DataFrame
:param df: 含有 preClose 列的 DataFrame
:param code: 股票代码(用来判断涨跌幅限制)
:param close_col: 收盘价列名,默认是 'preClose'
:return: 新增 limitUp、limitDown 列的 DataFrame
"""
# 判断涨跌幅限制
if code[:2] in ['60','00']:
limit_ratio = 0.1
elif code[:2] in ['30','68','69']:
limit_ratio = 0.2
else: # 北交所(8、4、9 开头)
limit_ratio = 0.3
# 涨停价
def calc_limit_up(price: float) -> float:
return round(price * (1 + limit_ratio), 2)
# 跌停价
def calc_limit_down(price: float) -> float:
return round(price * (1 - limit_ratio), 2)
df = df.copy()
df['limitUp'] = df[close_col].apply(calc_limit_up)
df['limitDown'] = df[close_col].apply(calc_limit_down)
return df我们先统计下每个分组从start_date开始累计涨跌停次数
python
def count_limit_by_group(df: pd.DataFrame, start_date: str) -> pd.DataFrame:
"""
从 start_date 开始,统计各分组累计涨跌停次数
:param df: 包含列 [date, stock, close, limitUp, limitDown, group]
:param start_date: 起始日期
:return: 各组的累计涨跌停次数
"""
df = df.copy()
df = df[df['date'] >= start_date]
# 判断涨跌停
df['is_limit_up'] = (df['close'] >= df['limitUp']).astype(int)
df['is_limit_down'] = (df['close'] <= df['limitDown']).astype(int)
# 累计统计
stats = (
df.groupby('group')[['is_limit_up', 'is_limit_down']]
.sum()
.reset_index()
)
return stats这是从2025-08-25到2025-09-02的统计数据
txt
group is_limit_up is_limit_down
0 1 57 1
1 2 32 1
2 3 48 3
3 4 48 6
4 5 54 3
5 6 45 6
6 7 52 6
7 8 38 7
8 9 36 5
9 10 59 81️⃣涨停次数分布
- 最高:第 10 组(59 次)、第 1 组(57 次)、第 5 组(54 次)、第 7 组(52 次)
- 最低:第 2 组(32 次)、第 9 组(36 次)、第 8 组(38 次)
两头强,中间弱:低价组(1 组)和高价组(10 组)最活跃,涨停最多;中间分组(2、8、9 组)相对沉寂。 这很典型:
- 低价股 → 资金少,容易被资金炒作拉涨停;
- 高价股 → 可能集中在热门题材龙头,强势股更容易连续涨停;
- 中间价位股 → 缺乏资金关注,涨停活跃度不高。
2️⃣ 跌停次数分布
- 最多跌停:第 10 组(8 次)、第 8 组(7 次)、第 7/6/4 组(各 6 次)
- 最少跌停:第 1 组(1 次)、第 2 组(1 次)
👉 高价股风险更大 :第 10 组虽然涨停最多,但跌停也最多,说明波动更剧烈,风险和收益并存。 👉 低价股防守性好:第 1 组不仅涨停最多(57 次),而且跌停最少(仅 1 次),说明资金在低价股里推拉比较容易,但往下砸得少。
3️⃣ 强弱对比
- 性价比最高的分组:第 1 组(57 涨停 / 1 跌停),涨跌比 57:1,胜率非常高。
- 高风险高收益分组:第 10 组(59 涨停 / 8 跌停),资金偏好强势龙头,但波动大。
- 不活跃分组:第 2、8、9 组(涨停次数明显偏低,同时跌停次数也不低),说明资金关注度弱。
4️⃣ 启示 💡
- 如果做 短线博弈:第 1 组和第 10 组是资金最活跃的主战场。
- 如果偏好 低风险套利:第 1 组更优,涨停多跌停少。
- 如果偏好 高风险高收益:第 10 组可以捕捉龙头行情,但要小心回撤。
- 中间分组(2、8、9)几乎没有性价比,既不活跃也风险不低,可以忽略。
三、总结
总的来说这段时间资金极度偏好高价龙头股(第10组),而低价股虽然有涨停效应,但难以带来持续收益,中间价位的股票几乎没有存在感。不过9月2日低位股回调最小,也可以从侧面说明高低切,低价股开始启动。