在AI领域,有一个存在已久的问题,那便是模型输出的不确定性。例如,当我们多次向 ChatGPT 询问相同的问题时,会产生不同的结果。这导致从大型语言模型中获得可重复的结果非常困难。
即使在温度参数设为 0 的情况下,传统大语言模型仍会对相同输入产生不同输出。
但今天,这一难题被攻克了。
近日,前 OpenAI 首席技术官 Mira Murati 创办的 Thinking Machines Lab 发布最新万字研究报告,成功解决了大语言模型输出不确定性问题。这项突破意味着 AI 生成将首次实现 100% 一致性输出,为 AI 技术在企业关键场景的应用铺平道路。

Thinking Machines Lab 成立仅 7 个月,专注于 AI 基础技术研究。该实验室此前已获得 20 亿美元种子轮融资,并计划在未来几个月推出首款产品。
回到这项研究。对于 LLM 推理引擎的不确定性,过去常见的假设是,浮点非结合性和并发执行的某种组合导致了非确定性。研究团队称之为「并发+浮点数」假设。
然而,团队深度研究后发现这种假设并没有完全揭示全貌,并发现了导致 LLM 推理引擎不确定性的两个核心技术原因。
首先,浮点数加法的非结合性问题在GPU并行计算环境中会导致细微计算差异,例如,(a+b)+ c 与 a + (b+c) 的计算结果可能存在细微差异,这些差异在复杂的神经网络中会被逐层放大。
更关键的是,并行计算策略的变化会因不同批量大小、序列长度和KV缓存状态影响GPU内核选择策略,从而改变计算执行顺序。这也是输出不确定性的根本原因。
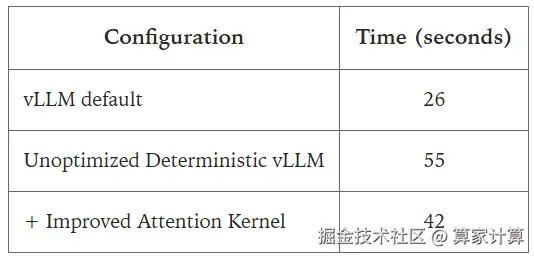
针对这一挑战,研究团队提出了 batch-invariant 解决方案。该方案要求所有关键计算核在处理不同批量大小或序列分割时,都能保持相同的计算顺序和结果。团队还针对 RMSNorm、矩阵乘法和注意力机制等具体计算模块提供了详细优化方法。
为验证方案有效性,研究团队选用拥有 2350 亿参数的 Qwen3-235B-A22B-Instruct-2507 模型进行实验。经过 1000 次重复测试,该模型在相同输入条件下实现了 100% 的输出一致性,这在大语言模型发展史上尚属首次。
这项技术突破的重要意义在于,在一些对准确性和一致性要求极高的应用场景,例如金融风控、医疗诊断、法律文书审核等,确定性的结果能提高决策可靠性、减少误诊风险以及准确性。AI 系统的可靠性和实用性也会获得显著提升。
该研究不仅解决了模型输出的可预测性问题,也为 AI 系统从实验工具向生产工具的转型提供了技术基础。
对整个 AI 行业来说,这代表着技术成熟度的重要提升。