配置大模型
-
Dify启动后,默认为空的,从v1.0.0开始所有模型库(包括Ollama)都要通过插件的形式安装 -
在
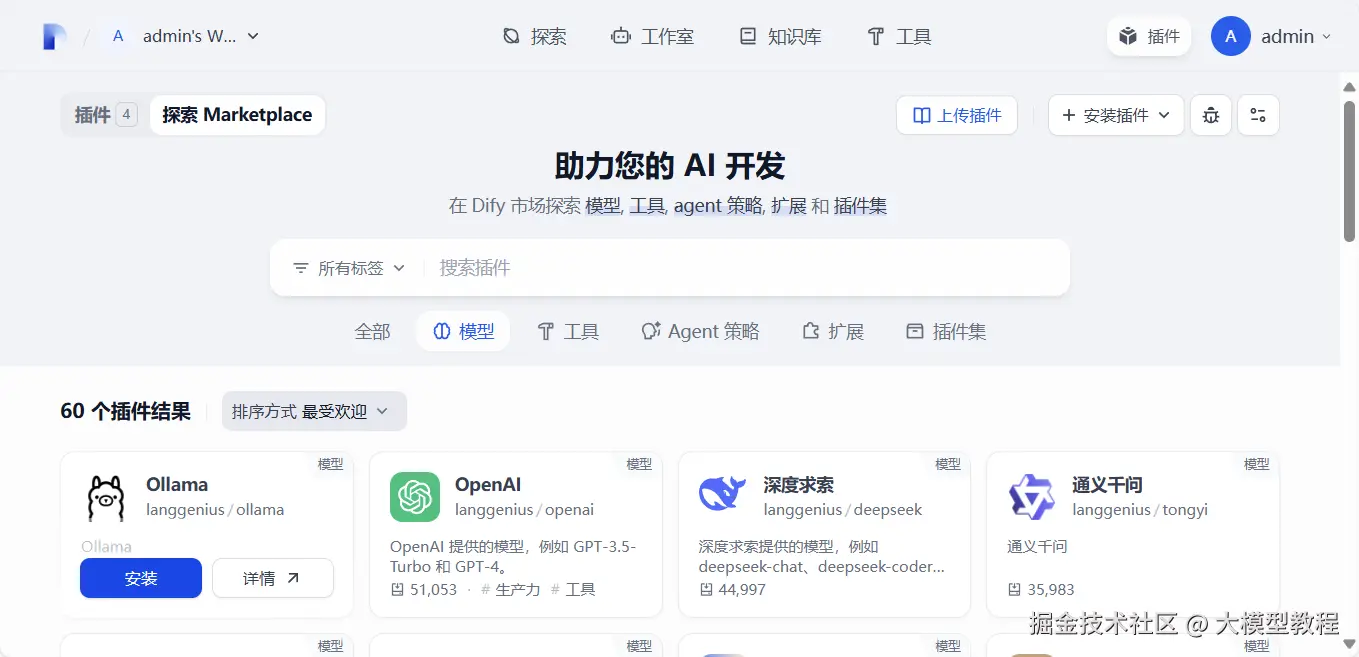
插件->探索 Marketplace->模型中找到Ollama,点击安装
-
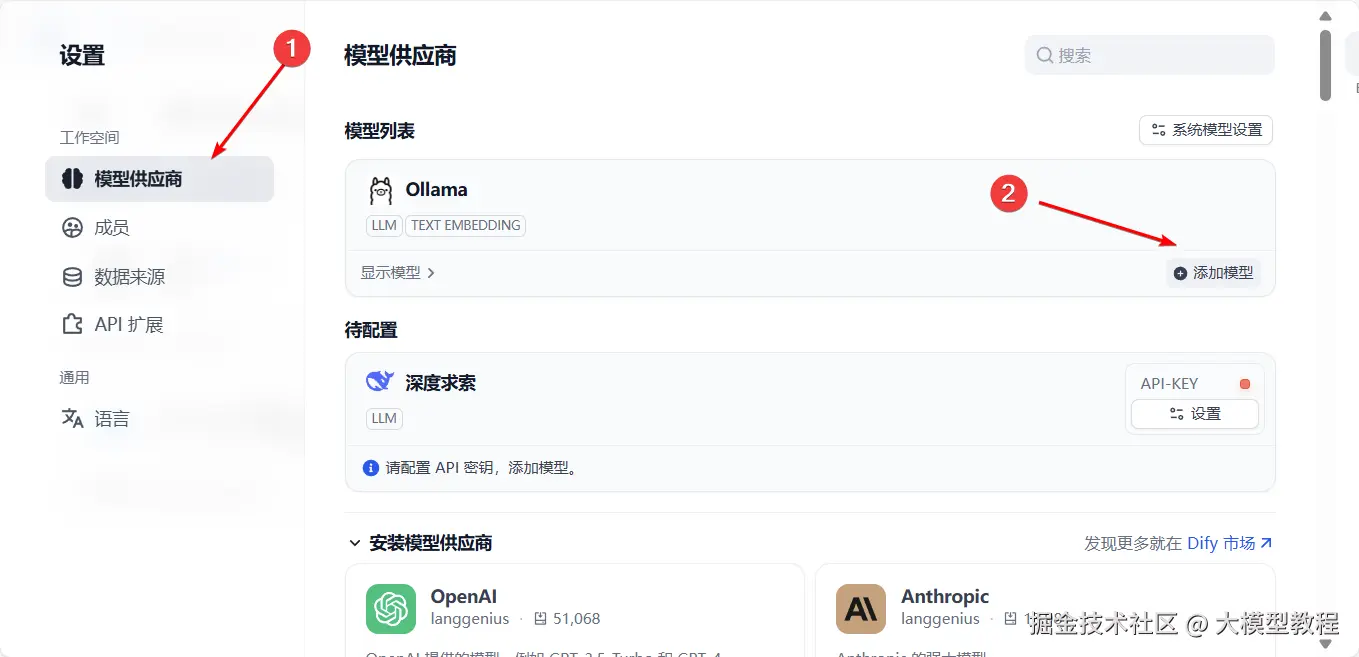
等待安装完成后,刷新页面,点击管理员头像,选择
配置,在模型供应商找到Ollama并点击添加模型
-
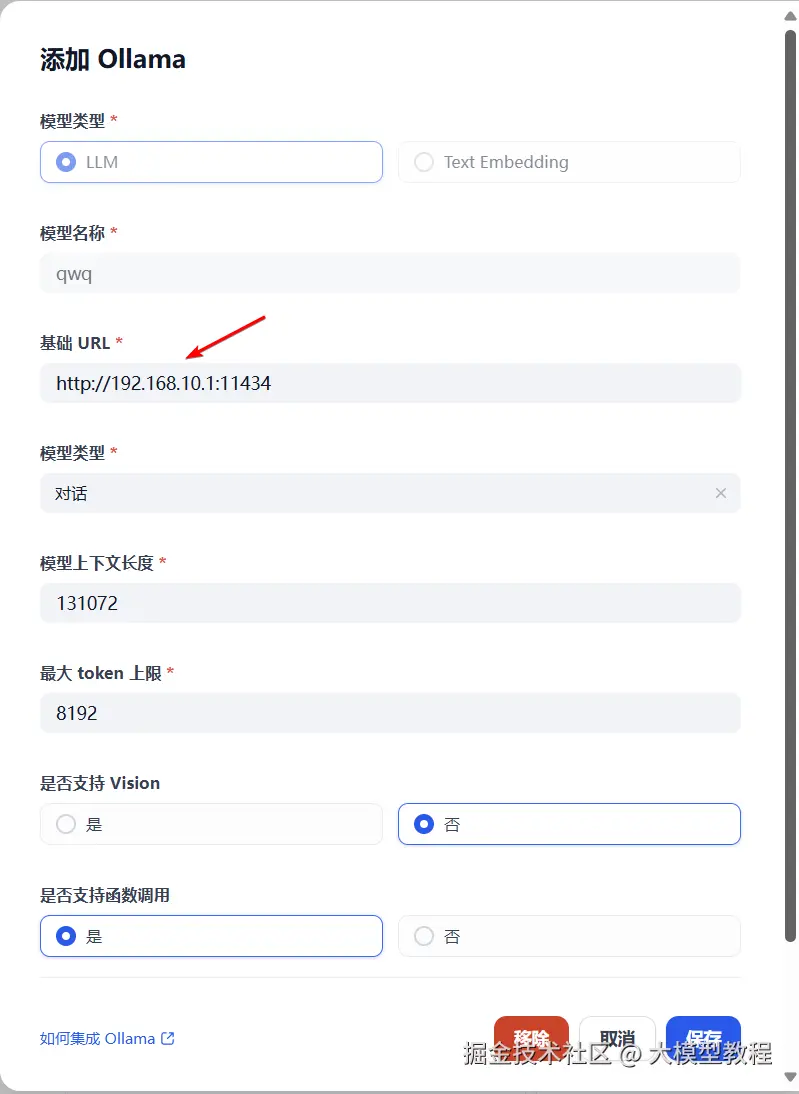
填写模型信息,注意
Ollama的地址
-
模型名称填写
Ollama上的对应的NAME,可通过ollama ls查看已下载的模型,名称中的:latest标识不需要填写makefileNAME ID SIZE MODIFIED gemma3:27b 30ddded7fba6 17 GB 11 days ago qwq:latest 38ee5094e51e 19 GB 2 weeks ago qwen2.5:32b 9f13ba1299af 19 GB 4 weeks ago deepseek-r1:70b 0c1615a8ca32 42 GB 4 weeks ago qwen2.5:14b 7cdf5a0187d5 9.0 GB 4 weeks ago qwen2.5:latest 845dbda0ea48 4.7 GB 4 weeks ago deepseek-r1:32b 38056bbcbb2d 19 GB 4 weeks ago nomic-embed-text:latest 0a109f422b47 274 MB 4 weeks ago bge-m3:latest 790764642607 1.2 GB 4 weeks ago deepseek-r1:1.5b a42b25d8c10a 1.1 GB 5 weeks ago deepseek-r1:7b 0a8c26691023 4.7 GB 5 weeks ago -
依次添加以下模型
-
qwq
-
bge-m3
- 模型类型选择
Text Embedding
- 模型类型选择
-
qwen:14b
-
-
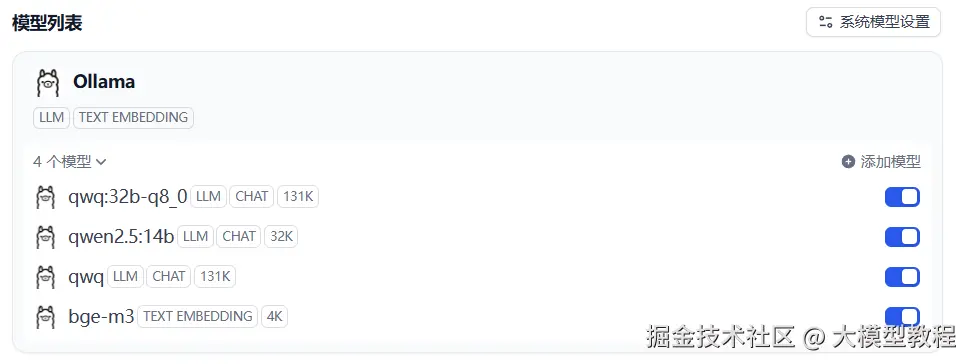
添加完成后如下显示
-
确认基础模型都添加完成后,刷新页面,再回到系统配置的
模型供应商页面; -
在
系统模型设置中配置系统默认模型
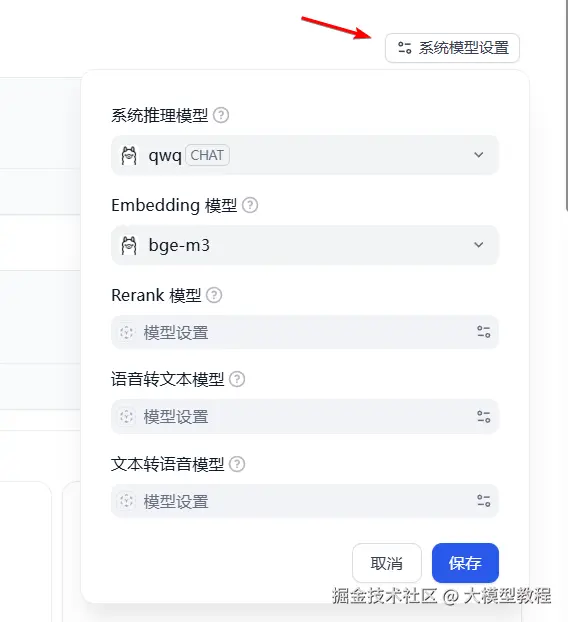
-
至此基础模型准备工作完成。
配置知识库
-
大模型准备完成后,就可以开始准备知识库了
-
知识库可以有很多种类型,可以是技术文档,公司制度等;
Dify目前支持多种格式的文件做为知识库来源,下面以Word文件为例; -
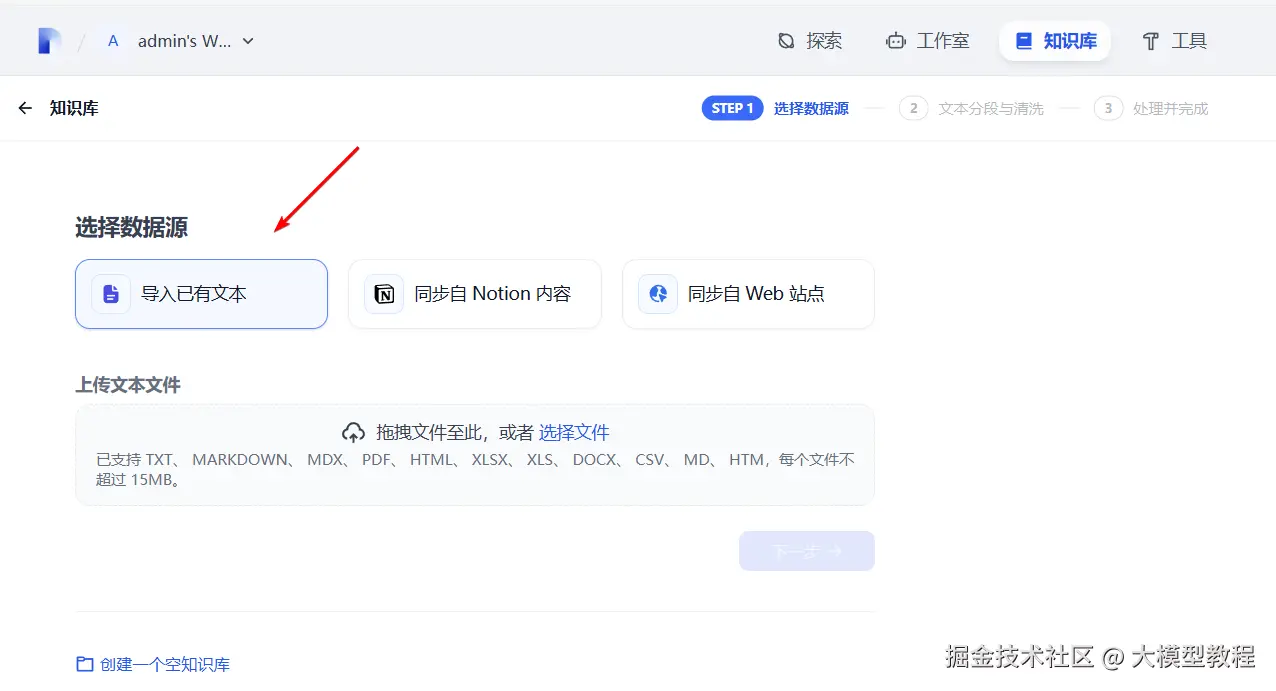
打开
Dify的知识库版块,点击创建知识库,选择导入已有文本
-
选择已准备好的文件,点击
下一步进入文本分段与清洗 -
分段设置有两种类型通用:默认的分段类型,适用于大多数场景父子分段:适用于结构分明的文档,像制度文件等
-
索引方式一般选择高质量 -
Embedding 模型选择之前配置好的bge-m3,如果此处没有可选择的模型,说明之前模型配置有误,需重新配置; -
检索设置一般选择混合检索 -
设置完成后,点击
保存并处理,系统开始将文档进行分段和向量化; -
知识库内的文档准备完成后,可对文档进行
召回测试,测试将显示文本(问题)召回的文档
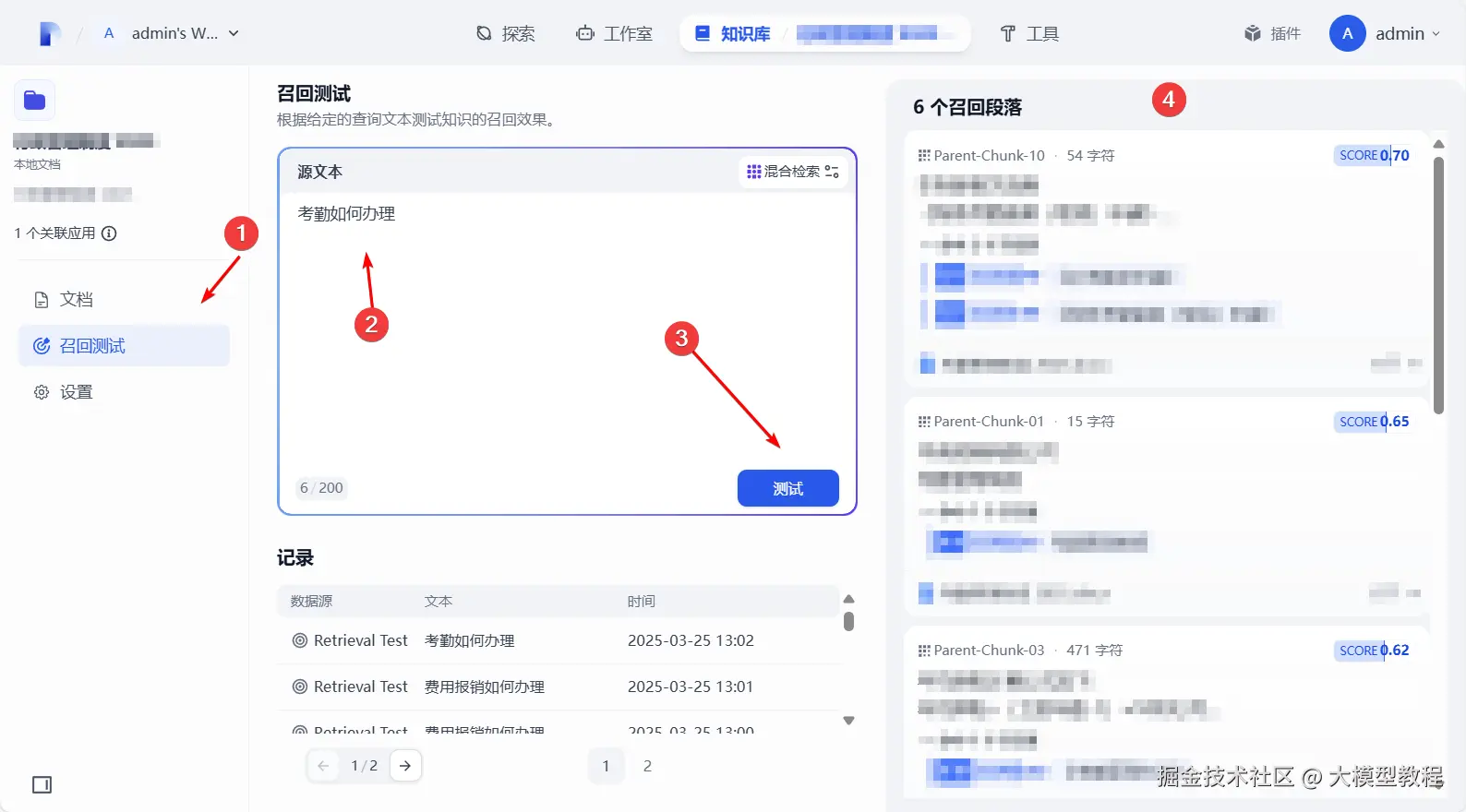
-
可以根据召回效果来对设置进行微调,找到一个适合的值;