写在前面的话
这是作为一个RAG小白,25年3月份时,为了解RAG发展情况,我自己做的调研。我把所有复杂的技术都用最简化的语言表述了下,只能帮大家了解RAG大致有哪些技术,从而以后更深入的学习。
1.什么是RAG
通用人工智能(AGI)------具有类人智能和自学能力的软件。这是人工智能领域研究的终极理想。当然实际上目前我们不知道如何具体实现它,有多种尝试路径。其中LLM就是其中最出名,得到最广泛应用的一种技术路径。LLM基于Transformer模型,通过扩展模型参数和训练数据规模、基于RLHF等技术,体现出了惊人的能力,最广人认知的就是ChatGPT。

从2022年11月的ChatGPT发布以来,大模型技术迭代速度日新月异,模型的基础能力得到了巨大提升。但是LLM是基于通用数据集训练的,在特定领域可能表现的效果不佳,而且模型存在幻觉情况,给出的答案不准确。对于特定的任务,比如针对某学科领域给出更专业的回答,提高回答质量等,可以通过微调fine-tuning来提高质量,但是面临数据缺少,训练成本高昂,费时费力等问题。

通过Retrieval-Augmented Gernation(RAG)技术,在当前模型能力固定的基础上,通过让模型结合问题相关的知识库进行检索回答,生成更专业更准确的结果。
2.使用RAG的目的
假设当前使用的LLM的基座能力固定的情况下,可以通过RAG技术,将企业或组织内部的丰富文档知识库信息结合起来,从而增强大模型对于符合需求的内容的生成和回答能力。
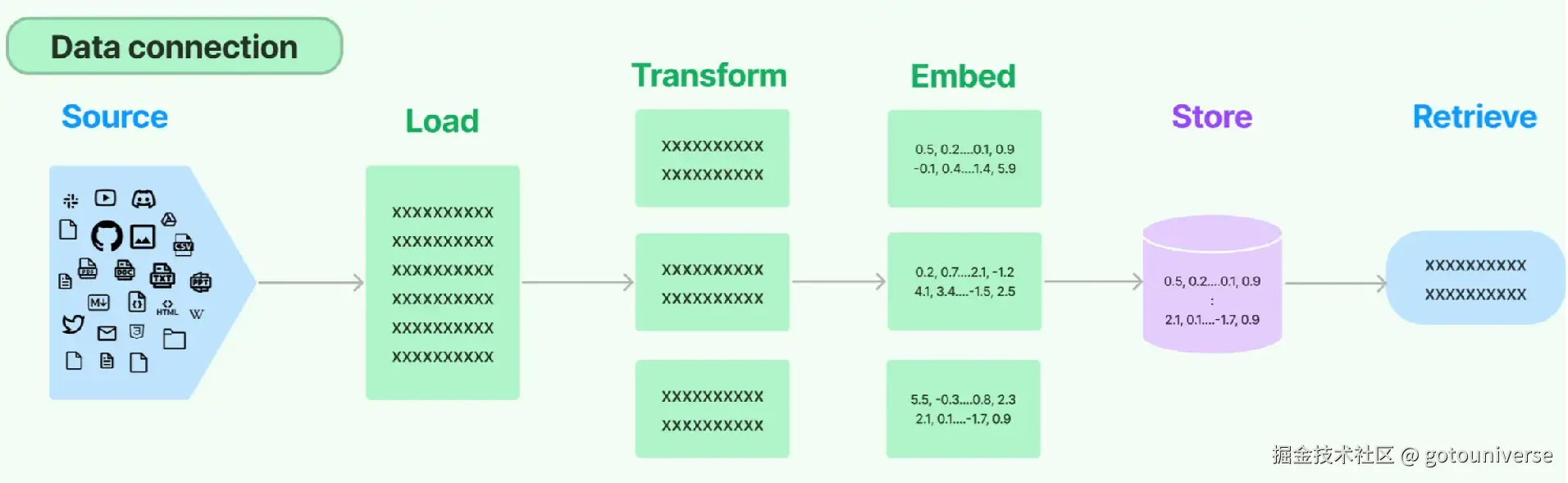
这些知识库内的文档格式不一,类别格式区别很大,比如markdown、pdf,word,表格网页等。从RAG最顶层的视角来看,可以简单分成数据的表示和存储、检索,然后模型的增强输出。
3.RAG基本流程
RAG增强模型回答能力的基本流程如下。
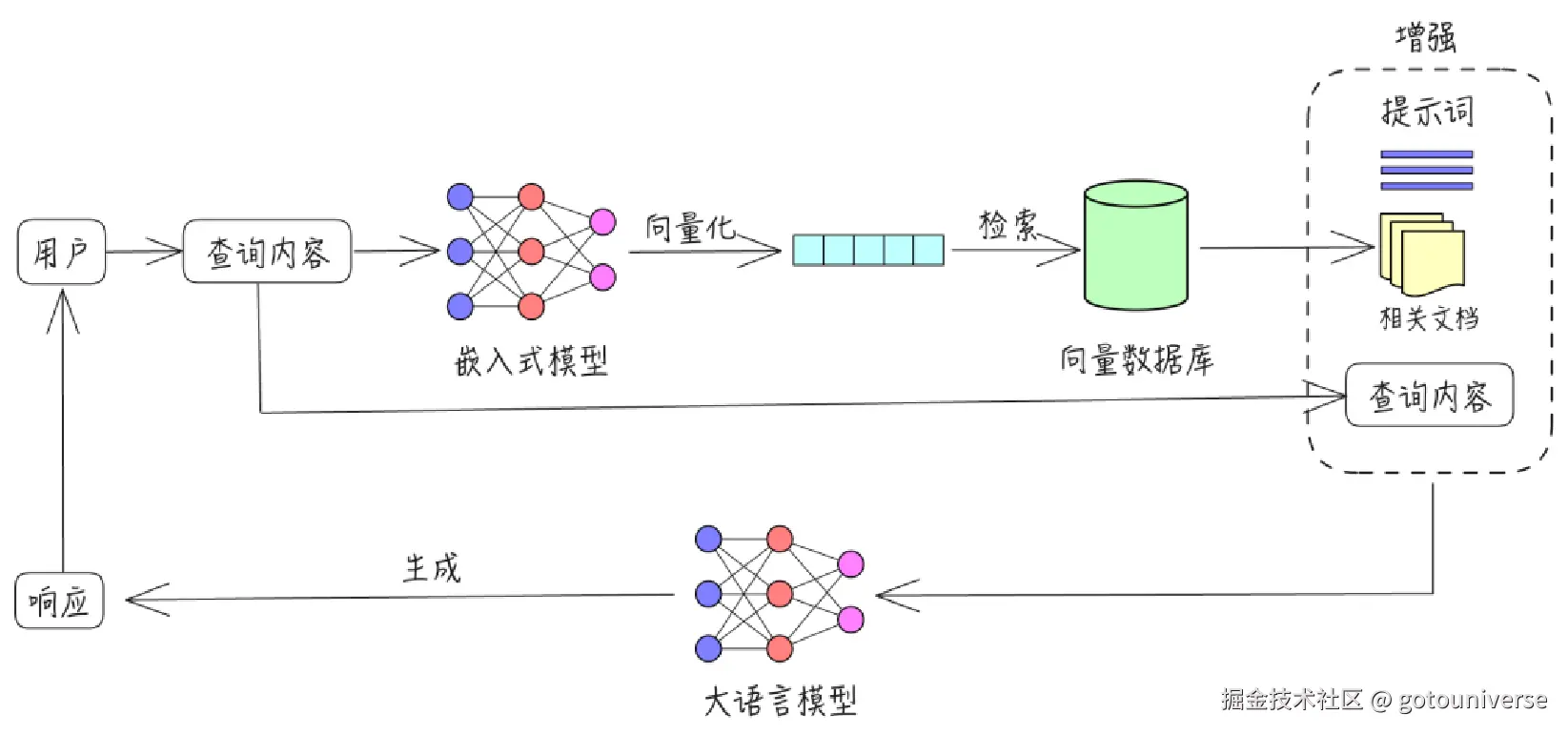
首先是用户提出问题,用户的问题会被嵌入式模型转化为向量的形式,然后在数据库中检索和该问题余弦相似度接近(或其它方法)的数据,通过检索出的数据,结合提示词,以及用户的问题,给出最终的回答。
有了基本流程的概念,我们就可以了解具体我们可以对哪些步骤进行入手,从而达到我们的目的。
4.优化方向
通过前一张图,我们回顾了RAG基本流程。下面我们将对流程中可优化的方向进行详细的说明。这一部分是最主要的内容,非常长,所以我们分成四大块来介绍。我们首先介绍是检索向量数据库之前的步骤,第二部分我们介绍检索数据后如何优化生成结果,第三部分介绍流程外其它方法对RAG可以进行哪些改进。最后一部分是我根据自己理解,假如我要开展工作,下一步的行动指南。
检索前
数据质量
首先我们介绍4.1检索前。这里第一步可以优化之处是数据质量。类似我们机器学习任务时候把数据标准化一样,虽然很简单,但是对后续结果影响还是很大的。
这一部分还是比较机械和工程的,主要的一些技巧包括这几个方面:一是给文档添加元数据,如文档结构,时间、文档用处等。这可以帮助后续的检索步骤进行初步过滤,以提高匹配度。比如给某函数添加时间标签,如A时期版本和B时期版本,只需要注释添加一行即可,就能帮助提高后续的检索效率。二是要文档精简,剔除冗余无关数据,减少检索时匹配错误的概率。
这部分可以通过代码文档等规范,typo check等提升,不再展开了
分块策略
chunk是一种将长文档拆分为片段式技术,它可以帮助后续的检索过程,从而提高模型的回答准确度。
我调研到的最重要的原则就是没有最好的策略,只有最适合的分块策略。因此把它写在前面。
首先我们需要对chunk建立一个最直观的认识,大致可以分为对以下几种类型的chunk

按照分隔符划分
首先第一种是根据换行符,逗号等进行语义分割。指定chunk_size,chunkoverlap等参数。第一个是被切割字符的最大长度,后一个是重叠字符数量,这个参数是为了保证块之间有一定的重叠,确保上下文语义的完整。比如这个例子"abcdefghijklmnopqrstuvwxyz",这是一个26个字符的字符串,chunk_size=10,chunk_overlap=4,那么最终划分结果就是
'abcdefghij', 'ghijklmnop', 'mnopqrstuv', 'stuvwxyz'。
该方法看似简单,但是却是最常见最直接的方法。实际上chunk策略类似于机器学习中的数据预处理步骤,它很重要,但是方法已经比较固定,不会有太大的差别,实际工作中根据需要调整即可。
按照token划分
token就是最小词语单位,按照token划分本质是使用embedding模型将要划分的文档向量化,然后同样设置参数来划分,只不过最小单位变为了token,比如下面的代码,根据token划分,得到foo bar 但是没有识别bazzyfoo,因为它不认为这是一个单词,就把它分开了
python
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)
>>> ['foo', ' bar', ' b', 'az', 'zy', 'foo']我们这里举例是langchain框架,它的tokentextsplitter函数给出了很多嵌入模型的供调用,来帮助进行chunk
按照元数据划分
本质是根据格式化文档的多级标题,将文档划分为一块一块,特别适合markdown这样的文档格式。
划分后的每一个chunk包含其自身所在级别的信息。比如这个例子,这是一个简单的markdown文件,包含一些多级目录
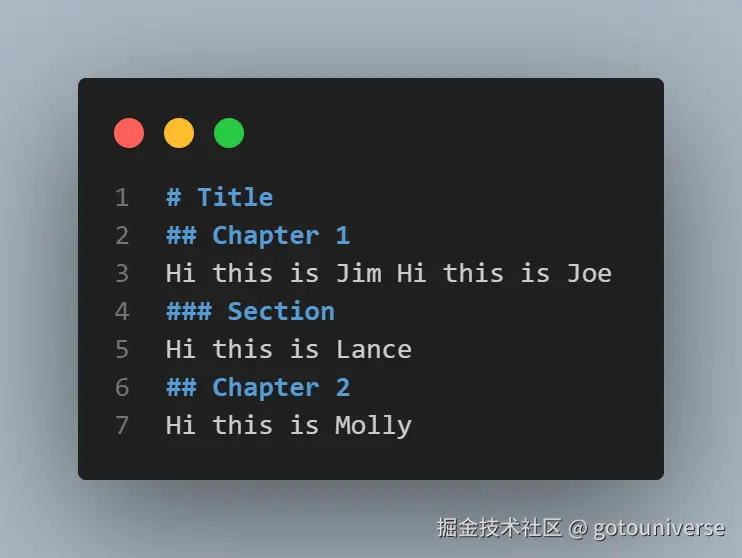
其划分后是这样的
css
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'}), Document(page_content='Hi this is Lance', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'}), Document(page_content='Hi this is Molly', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 2'})]这样,能够让之后的检索更快和更准确的去定位相关文本
代码分割
对于代码文件,我们需要对对应语言的规则,来特制分割chunk的规则,但是其本质还是第一种,按照分隔符划分,只不过定制了规则罢了。比如对于python

得到的分割结果是
[Document(page_content='def hello_world():\n print("Hello, World!")'),
Document(page_content='# Call the function\nhello_world()')]
这里它是根据关键词def以及注释符号#来划分,其它还有java,html等,不再一一举例
除了以上列举的chunk策略之外,还有诸多其它策略,但是本质都是以上的一些变种,了解了这些基本的,再根据实际遇到的情况,研究适合什么样的chunk策略即可
嵌入模型
chunk将文档分割好后,我们最终还是需要将分割后的文本通过嵌入模型转换为向量的形式存入向量数据库之中。
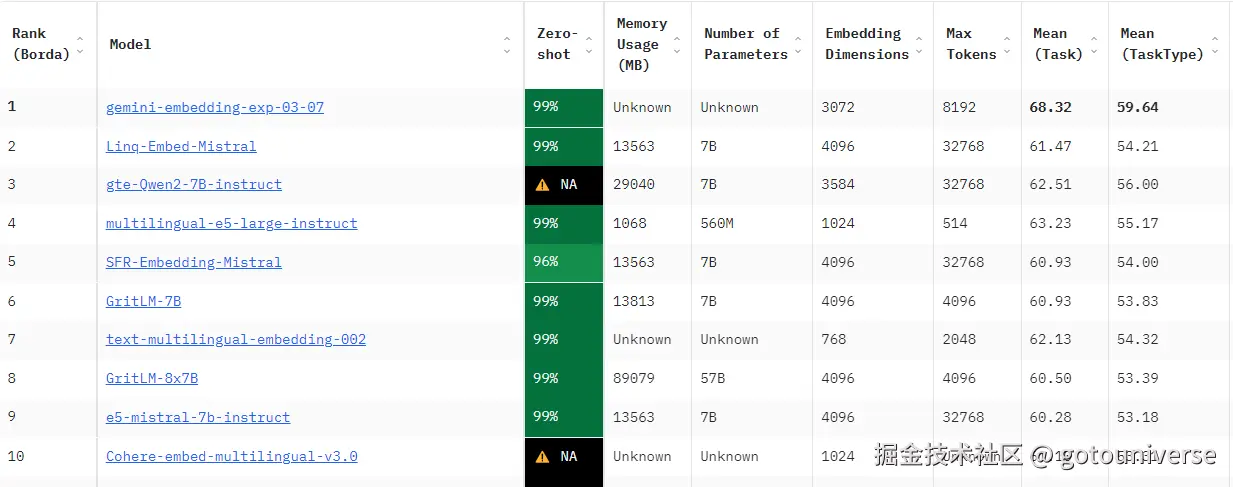
如今的嵌入模型和LLM一样百花齐放,这张图展示的是huggingface上面基于MTEB数据集的各个嵌入模型benchmark的排行榜,METB是一个涵盖了250多种语言,多种学科领域,测试任务的数据集,是目前验证嵌入模型能力的流行指标。不同的嵌入模型将文本的嵌入维度大小不同,对结果有很大的影响。因此需要根据实际情况选择适合的嵌入模型。
索引、查询
就像前面提到的,数据准备部分可以准备多一些元数据。其实目的就是嵌入向量数据库的时候可以构建索引,帮助后续查询过程快速找到相关数据。且可以构建多层次索引,比如摘要类,具体问题类,时序数据等,需具体问题具体分析,是非常复杂的过程。可以将查询快速路由导航至合适的数据,大大提高检索速度和精准度
查询query本质是通过将用户的问题向量化,来根据关键词和语义相似程度找到相关chunk数据。下面这张图展示的是可视化的问题对应的数据库中附近数据的位置

随着问题复杂程度不同,简单的寻找语义相似度可能耗时很大,或者效果不好,因此对于查询演化出了一些优化方案,比如Hyde
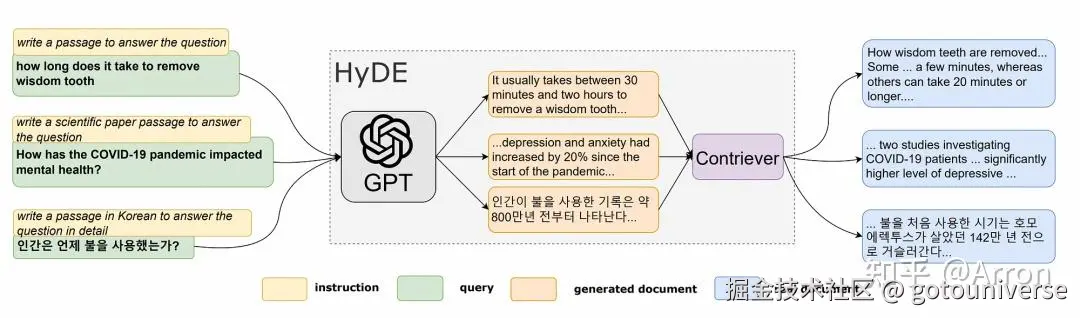
本质是LLM根据自身模型做出回答,大概知道回答的话语是什么样的,然后根据回答的内容去匹配对应的语义,寻找相似的答案。
另一种是子问题查询,类似思维链的方式,让LLM将问题拆分为多个简单小问题,从而帮助检索准确信息
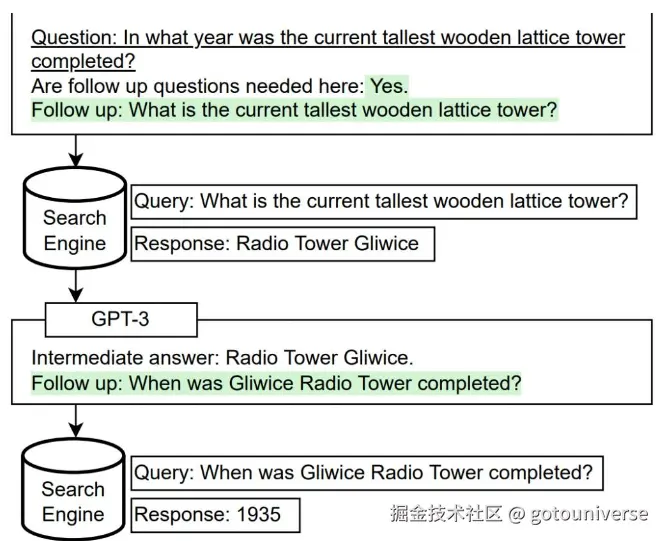
比如这张图,问题是当前世界最高的木制塔是哪一年建成的。分为两个问题,最高的木制塔是什么,它是哪一年建成的。
实际查询过程中可以设置一些参数,比如稀疏稠密搜索权重,结果数量,相似度度量方法等来给出查询结果,这些参数可以控制查询侧重词语,返回结果数据,用什么方法来衡量语义相似度等(常用的是余弦相似度)。通常RAG框架给出非常丰富的相关方法,限于篇幅这里不再一一介绍。
检索后
以上我们讲完了检索及其之前的工作,得到的检索返回的内容。一个最简单的RAG到这里就可以结束了,根据返回的内容给出答案即可。
上下文压缩
然而,RAG的复杂性到这里仍然体现。一个问题是我们检索得到的相关块可能过大,包含太多不相干的信息,消耗token的同时也降低了回答的精确性。因此有必要引入上下文压缩,将检索后的内容进行压缩,提取精华,从而提高回答能力。比如这里的RECOMP方法
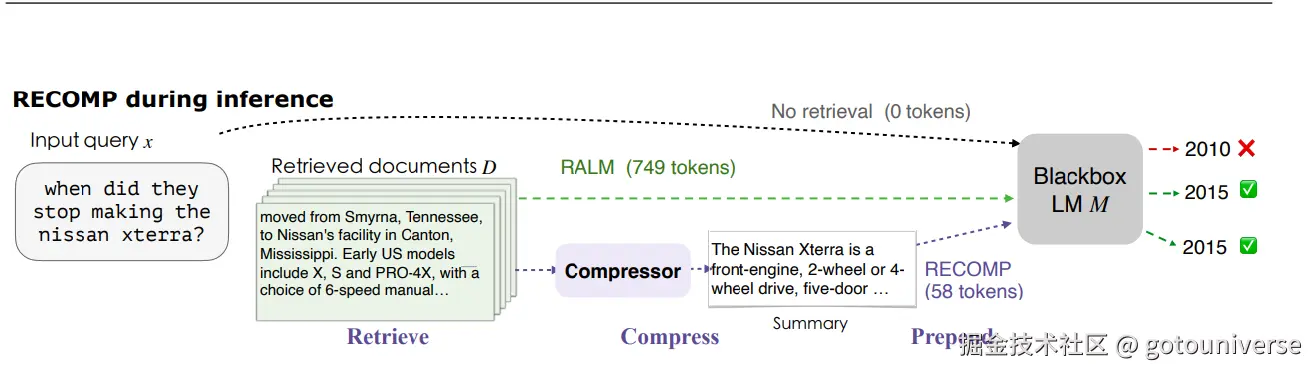
该方法很容易理解,就是将检索到的相关文档通过compressor进行压缩,给出精炼的,信息密度高的简略版,然后大模型再根据相关内容结合问题进行回答。
然而很多情况下,相关的文本是非常长的,长文本的压缩本身就是一个非常困难的问题,为了解决这个问题,另一种方法是CompAct,即概念蒸馏,将相关文本转化为语义图,提取出文本最关键核心的关键词,忽略冗余信息
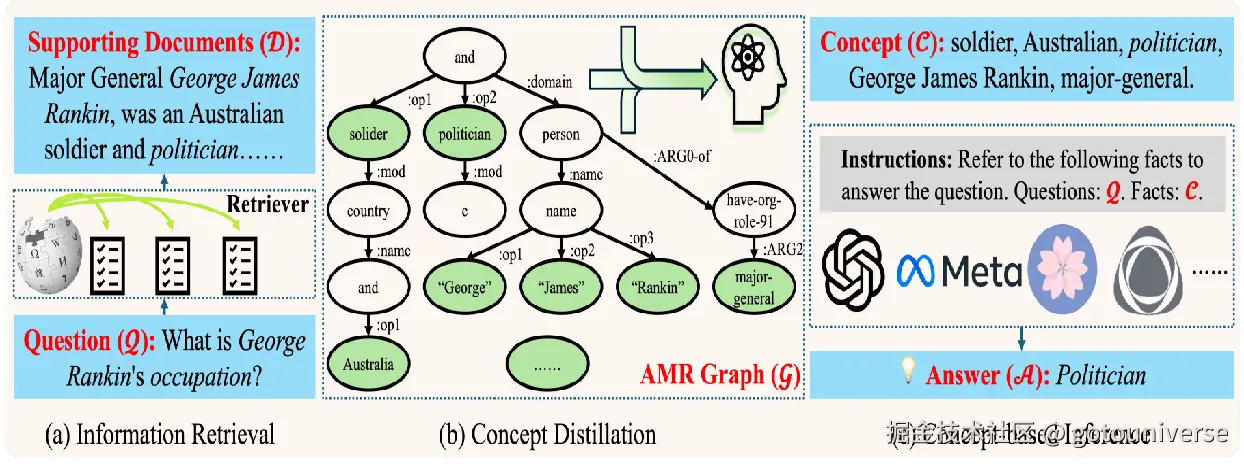
这里我们只展示这两个例子,实际上上下文压缩是RAG领域非常热门的研究方向,新的论文层出不穷,这里不再多介绍。
重新排序
我们之前讲检索部分的时候提到过我们检索有个参数叫做结果数量,返回多个问题相关块。重新排序相当于对这些返回结果再次进行检查,判断它们和问题的相关度,给定权重,提高最终的效果。
目前主流的技术方向是使用嵌入模型对查询块进行rerank(这些模型衡量块和问题的相关度,给出排序)
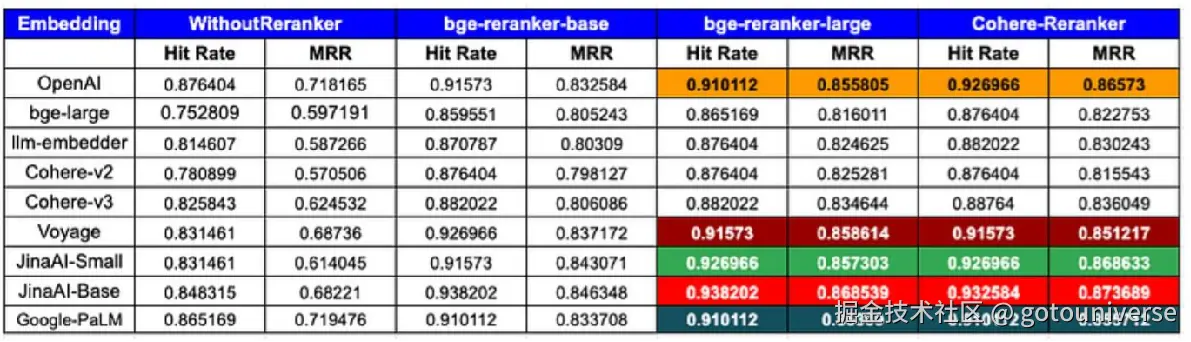
这张图展示的是使用重排序和不适用重排序,最后得到结果的评价指标。可以看到不管是哪一个大模型,使用重排序后,效果都有明显的提升。这里的bge-reranker,Cohere-Reranker是不同的rerank模型
其它
到这里我们就对RAG的基本流程和技术细节做了快速的回顾,这里介绍一些其它的RAG优化
多模态嵌入
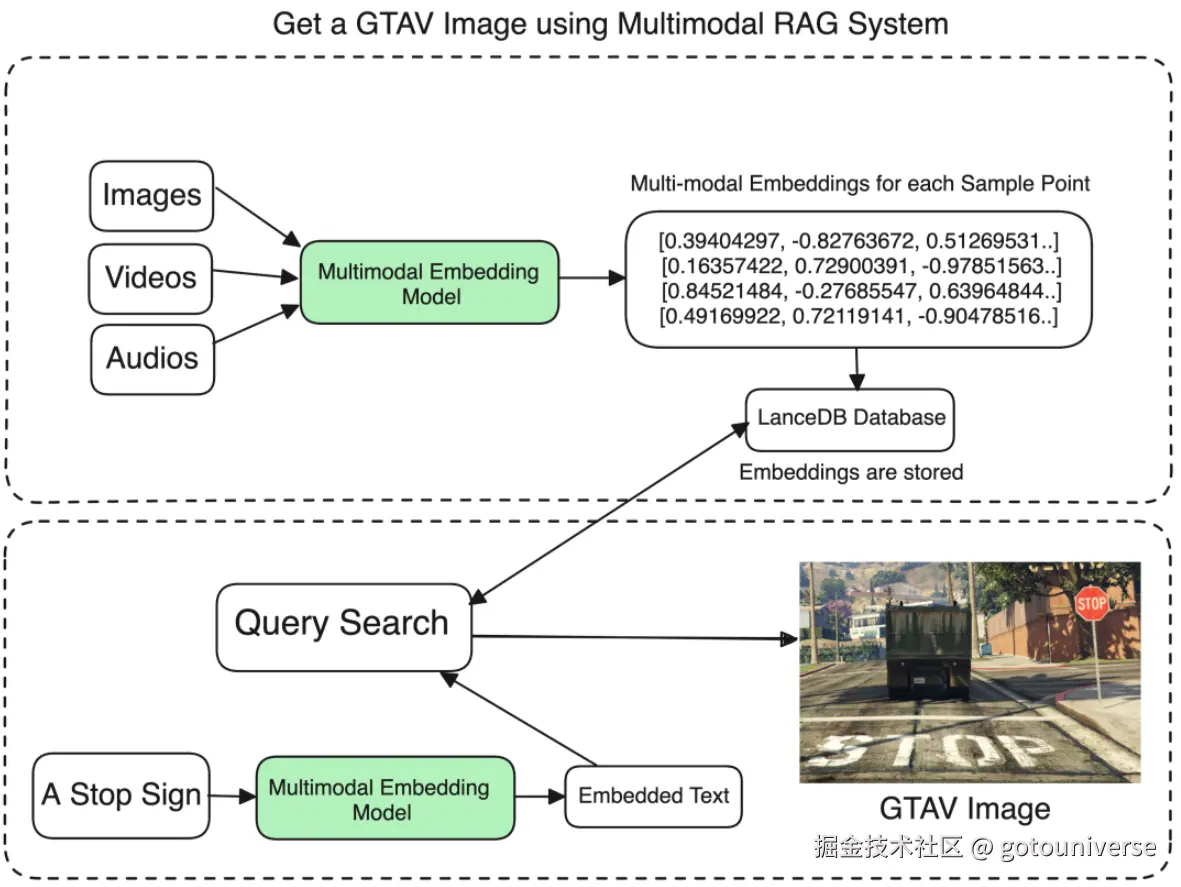
最新的大模型基本都具有多模态的能力,多模态本身是一个趋势了。很多文档都是包含文字,图片甚至视频的,如何对这些多模态数据进行嵌入是一个很前沿同时非常有前景的方向,比如下面这个图展示的是图片的嵌入,基于Meta的ImageBind多模态嵌入模型。很大的问题是如何对图片进行全面简洁的描述,查询的算法复杂度等问题。
GraphRAG
微软于2024年7月开源该模型。
其本质和我们前面介绍的RAG流程一致。创新点是数据库的嵌入和索引方式的创新。它将输入语料库创建知识图谱,将chunk组织关联起来。远离类似我们之前提到的元数据,这样可以快速帮助查询到关联和对应的信息,提高查询能力。而且添加知识图谱比我们人类自己去思考元数据类型等要全面方便的多,效果更好。
通过使用LLM生成的知识图谱,GraphRAG极大地改进了RAG的'检索'部分,用更高的相关性内容填充上下文窗口,从而获得更好的答案并捕获证据出处。GraphRAG需要的token比替代方法少26%到97%,这不仅使它提供更好的答案,而且更便宜、更可扩展。
混合RAG框架
尽管图RAG能够显著提高相关信息检索能力,但是处理复杂文档时,但是在召回能力上有欠缺。而传统的向量嵌入在上下文精确度上没有图RAG好。混合RAG框架就是希望能结合这两种方式的优势。
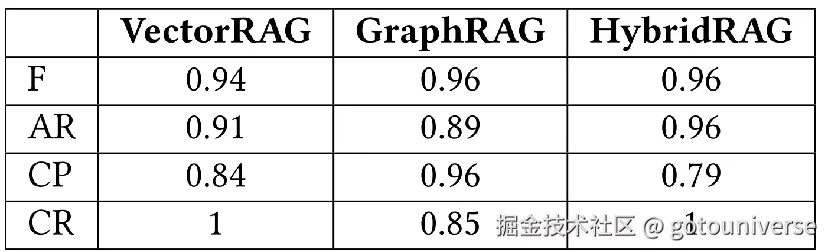
-
准确性 (F) :GraphRAG 和 HybridRAG 均表现优异,得分为 0.96,而 VectorRAG 略低,得分为 0.94。
-
答案相关性 (AR) :HybridRAG 以 0.96 的得分领先,优于 VectorRAG 的 0.91 和 GraphRAG 的 0.89。
-
上下文精确度 (CP) :GraphRAG 以 0.96 的得分领先,超过 VectorRAG 的 0.84 和 HybridRAG 的 0.79。
-
上下文召回率 (CR) :VectorRAG 和 HybridRAG 达到完美的 1 ,而 GraphRAG 得分为 0.85。
可以看到其效果非常好,只是在上下文精确度上有一些不足之处,目前其还未开源.
Self-Reasoning
模型的推理可以减少模型的幻觉。像o1,deepseek的推理能力都证明了这点。RAG流程结合推理能力也能极大提升模型的效率,比如百度24年的这个工作
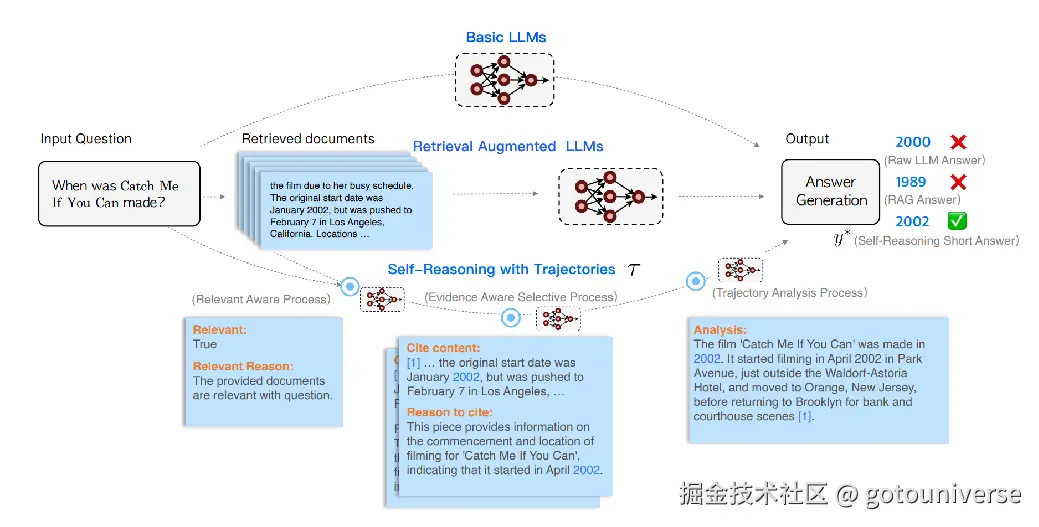
比较三种流程,一是LLM直接回答,2是LLM结合提取的chunk回答,3是根据chunk,思考相关问题,决定使用哪些数据。可以看到第三中给出了正确答案
建议行动指南
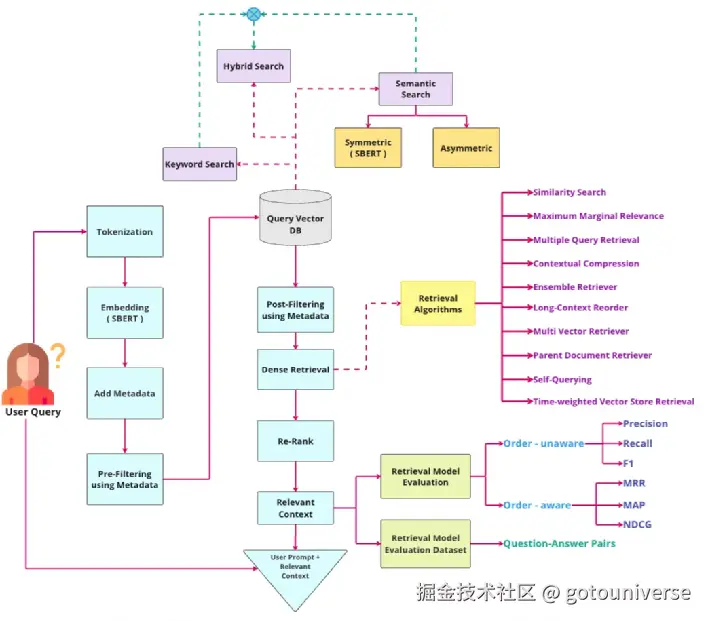
讲了这么多,最后,我们再来回顾一下RAG的流程,这次是详细版本
这里面的每一步都可以是我们优化的方向,实际工作中只能从某方面入手,逐渐改进。而不是这碰一下那改一下,否则难以评估究竟是哪里提升了,改进的效果使用范围是多少。包括可以看到的是,哪怕是大公司发布的论文或者框架都是对其中一部分进行创新,比如微软的图RAG就是对数据存储和提取部分的创新,百度的自推理是对提取部分的创新。
针对企业的问题,根据企业文档,提高回答问题的准确度,就可以按照上述的思路。需要自建评价指标,类似METB(比如常问的一些问题,格式等)。关于代码生成,现有的指标是生成代码的正确程度和通过测试。然而如果是需求根据当前已有代码,不同目录,代码结构等,根据前文信息生成一次ac的代码,该部分效率也能很大程度提升,主要问题同样是没有评价指标,需要构建。
任何人都可以随意使用、转载本文章。
参考文献
- Gao, L., Ma, X., Lin, J. and Callan, J., 2023, July. Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1762-1777).
- Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N.A. and Lewis, M., 2022. Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350.
- 读懂RAG这一篇就够了,万字详述RAG的5步流程和12个优化策略
- Singh, I.S., Aggarwal, R., Allahverdiyev, I., Taha, M., Akalin, A., Zhu, K. and O'Brien, S., 2024. ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems. arXiv preprint arXiv:2410.19572.
- Xu, F., Shi, W. and Choi, E., 2023. Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408.
- Shi, K., Sun, X., Li, Q. and Xu, G., 2024. Compressing long context for enhancing rag with amr-based concept distillation. arXiv preprint arXiv:2405.03085.
- zhuanlan.zhihu.com/p/263215128...
- Clavié, B., 2024. Rankers: A Lightweight Python Library to Unify Ranking Methods. arXiv preprint arXiv:2408.17344.
- www.llamaindex.ai/blog/boosti...
- Sun, W., Yan, L., Ma, X., Wang, S., Ren, P., Chen, Z., Yin, D. and Ren, Z., 2023. Is ChatGPT good at search? investigating large language models as re-ranking agents. arXiv preprint arXiv:2304.09542.
- vipul-maheshwari.github.io/2024/02/14/...
- microsoft.github.io/graphrag/
- Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R.O. and Larson, J., 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130.
- Sarmah, B., Mehta, D., Hall, B., Rao, R., Patel, S. and Pasquali, S., 2024, November. Hybridrag: Integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction. In Proceedings of the 5th ACM International Conference on AI in Finance (pp. 608-616).
- Xia, Y., Zhou, J., Shi, Z., Chen, J. and Huang, H., 2024. Improving Retrieval Augmented Language Model with Self-Reasoning. arXiv preprint arXiv:2407.19813.
- pub.towardsai.net/why-rag-app...