
一. 前言
最近在查看各行业垂类 AI Agent 应用落地的案例,同时也在反思自己过去做过的一些 AI 应用。结合在AI Engineer World Fair (4th June 2025)上看到《Own your vertical: A playbook for building a domain-native LLM application》一文中的思路,我整理并延伸出一份关于垂类 AI 应用落地的实施方案。我尝试从整体框架到实施细节进行一次系统化梳理,希望能为正在探索 AI 垂直化落地的团队提供参考,也期待与同行交流与讨论。
垂类 AI 应用的关键在于"拥有你的垂直领域",即不仅仅依赖通用大模型,而是将行业知识、业务流程、专家反馈等深度嵌入到 AI 系统中,从而解决"最后一公里"问题。当前随着大模型能力的提升,垂类应用的基础表现往往已经能达到"70-80 分"的水平(即完成大部分通用任务)。然而,真正要让应用达到"95 分甚至 98 分以上",并在关键业务环节具备可用、可信、合规的表现,就必须深度挖掘行业专家的知识,并让专家持续参与到 AI 应用的建设与迭代中。这一环节正是"最后一公里"的真正挑战所在。本文将从五个主要阶段展开:
- 定义问题与目标
- 构建领域知识本体
- 设计反馈与专家在环机制
- 建立评估与监控体系
- 持续迭代与优化
每个阶段不仅涉及技术方法,也涵盖一些组织管理与产品思考。
二. 定义问题与目标
2.1 明确"最后一公里"问题
垂直 AI 应用不能仅停留在"回答问题"层面,而是要深入到行业实际工作流中。例如:
- 医疗:不仅回答医学知识,而是辅助医生在电子病历系统中快速决策。
- 法律:不仅总结法规,而是生成可直接用于合同审查或合规报告的输出。
- 金融:不仅解释财务术语,而是嵌入风控、审计等关键流程中。
- HR 招聘:不仅回答招聘流程问题,而是能嵌入招聘管理系统中,自动筛选简历、生成面试问题并辅助 HR 做出更高质量的招聘决策。
实施要点:
- 明确目标用户是谁(医生、律师、审计员、HR、客服人员等)。
- 确定"正确输出"的标准(法律合规性、医学诊断安全性、财务准确性、招聘公平性与效率等)。
- 正确输出的标准例子有:
-
医疗行业
- 正确性:诊断、用药、治疗建议必须符合循证医学与临床指南。
- 安全性:不能给出存在重大风险的错误建议,尤其是药物剂量与禁忌症。
- 可解释性:输出要能被医生理解和追溯,而不是黑箱式结论。
-
HR 招聘行业
- 公平性:AI 输出需避免性别、年龄、种族等歧视性偏差
- 合规性:遵循劳动法、反歧视法规以及个人隐私保护
- 效率性:帮助招聘流程提效,但不能牺牲候选人体验或透明度。
- 可信性:候选人和企业双方都应能理解 AI 输出的依据
-
- 正确输出的标准例子有:
- 识别业务中 AI 能创造最大价值的场景,而非试图大而全覆盖。
2.2 建立问题陈述框架
建议采用以下问题框架:
- 我们要解决的核心痛点是什么?
- 现有流程的主要瓶颈在哪里?
- 目标用户在意的核心指标是哪些?
- 如果 AI 系统完全失败,会造成什么风险?
📋 问题陈述收集样表
| 模块 | 具体问题 | 示例(医疗 / 法律 / 金融 / HR) | 需填写内容 |
|---|---|---|---|
| 核心痛点 | 我们要解决的核心痛点是什么? | - 医疗:医生写病历耗时、诊断辅助缺乏工具 - 法律:合同条款审核效率低 - 金融:投研报告生成耗时 - HR:简历筛选耗费大量人力 | 填写本行业/场景的具体痛点 |
| 流程瓶颈 | 现有流程的主要瓶颈在哪里? | - 医疗:病历非结构化,信息难以复用 - 法律:判例繁多,律师检索效率低 - 金融:数据源分散、报表人工整理慢 - HR:大量重复性初筛工作,候选人体验差 | 描述当前业务环节的主要卡点 |
| 用户核心指标 | 目标用户在意的核心指标是哪些? | - 医疗:诊断准确率、病历撰写效率、患者安全 - 法律:合规性、风险识别率、审查速度 - 金融:数据准确性、分析速度、合规性 - HR:招聘周期、候选人公平性、体验满意度 | 明确要优化或提升的指标 |
| 失败风险 | 如果 AI 系统完全失败,会造成什么风险? | - 医疗:误诊导致医疗事故 - 法律:合同审核失误导致法律纠纷 - 金融:错误分析导致重大经济损失或合规违规 - HR:歧视性筛选导致法律风险和品牌损害 | 列举 AI 失败带来的严重后果 |
👉 使用方式:
- 在实际项目启动时,由 产品经理 / 研究员 / 领域专家 共同填写此表。
- 可作为立项文档的一部分,用于明确"最后一公里"问题的业务价值与风险边界。
这样可以在项目早期就能先从需求和风险出发,梳理清楚核心痛点。
三. 构建领域知识本体
3.1 知识本体的重要性
垂直行业的知识往往是非结构化、隐性的:
- 医疗记录、诊断流程、病理数据
- 法律判例、合同条款、法规解释
- 金融审计流程、合规标准、数据表格
- 招聘流程、岗位说明、面试评价、候选人画像
单纯依赖通用 LLM 难以保证准确性,因此必须对知识进行结构化与模块化,构建领域知识本体(Ontology)。
3.2 构建步骤
- 概念梳理:与领域专家一起明确行业核心概念和流程。
- 知识映射:将非结构化知识(文档、记录)转化为可被检索、引用的结构化数据。
- 工具链集成:在知识层之上叠加检索增强生成(RAG)、知识图谱或数据库。
3.3 示例
- 医疗场景:建立疾病-症状-药物的知识图谱。
- 法律场景:建立合同条款的标准模板库,并映射常见风险点。
- 金融场景:建立会计科目与合规要求的对应关系表。
- HR 场景:建立岗位要求与能力模型的对应关系库,整理不同岗位的招聘标准与常见面试问题。
核心原则:知识本体不是一次性工作,而是一个动态更新的资产库。
3.4 📚 构建 HR 招聘领域知识本体 ------ 以 JD 岗位与人才画像为例
1. 确定目标与边界
- 目标:让 AI 系统能理解岗位需求(JD)与候选人画像,并进行匹配与推荐。
- 边界 :只关注招聘流程中的 岗位需求分析 - 候选人筛选 - 匹配度评估,暂不涉及 onboarding、绩效管理。

2. 知识对象识别(实体抽取)
识别招聘领域的核心实体:
-
岗位相关
- 岗位名称(Job Title)
- 职责描述(Responsibilities)
- 任职资格(Requirements)
- 技能需求(Skills)
- 经验要求(Experience)
- 学历要求(Education)
- 软技能(Soft Skills)
- 薪资范围(Compensation Range)
- 工作地点(Location)
-
候选人相关
- 基本信息(Name, Age, Contact)
- 学历背景(Education Background)
- 工作经验(Work Experience)
- 技能集合(Skills Set)
- 职业偏好(Job Preference)
- 语言能力(Language Proficiency)
- 证书/资质(Certificates & Licenses)
- 软技能表现(Soft Skills Evidence)
3. 建立关系(Relations)
定义不同实体之间的逻辑联系:
岗位需求 (JD)------ 包含 ------> 技能、学历、经验要求候选人------ 具备 ------> 技能、学历、经验候选人------ 匹配 ------> 岗位技能------ 对应 ------> 技能等级 / 熟练度经验------ 关联 ------> 行业 / 岗位类别岗位------ 属于 ------> 行业 / 部门
4. 属性标准化(Normalization)
为避免歧义,对常见属性建立标准化标签:
- 技能标签化(如"Python"→ 技术技能 / "沟通能力"→ 软技能)
- 经验分级(如"3-5年经验"→ Level 2 工作经验)
- 学历标准化(本科/硕士/博士 → Education Level 1/2/3)
- 匹配分数计算公式(硬技能匹配、经验匹配、软技能匹配,分权重加权)
5. 知识本体示例(简化版)
json
{
"Job": {
"title": "数据分析师",
"requirements": {
"skills": ["SQL", "Python", "数据可视化"],
"experience": "3年以上相关经验",
"education": "本科及以上",
"soft_skills": ["沟通能力", "逻辑思维"]
},
"location": "北京",
"compensation_range": "20k-30k/月"
},
"Candidate": {
"name": "张三",
"education": "硕士",
"experience": "4年数据分析经验",
"skills": ["Python", "Tableau", "SQL"],
"soft_skills": ["沟通能力", "团队协作"],
"job_preference": "北京,数据分析相关岗位"
},
"Match_Score": {
"hard_skills": 0.9,
"experience": 1.0,
"education": 1.0,
"soft_skills": 0.7,
"overall": 0.88
}
}6. 应用场景
- 智能 JD 分析:自动将 JD 文本解析成结构化知识本体。
- 候选人画像生成:解析简历,提取标准化标签。
- 匹配度计算:利用知识本体,自动计算候选人与 JD 的匹配分数。
四. 设计反馈与专家在环机制
4.1 为什么专家必须"在环"
大模型的通用能力强,但行业的细节与规范往往需要专家判断。仅在训练初期引入专家是不够的,真正可落地的系统必须让专家持续参与
- 审核与纠错 AI 的输出
- 标注失败案例
- 通过反馈直接影响模型的下一次行为
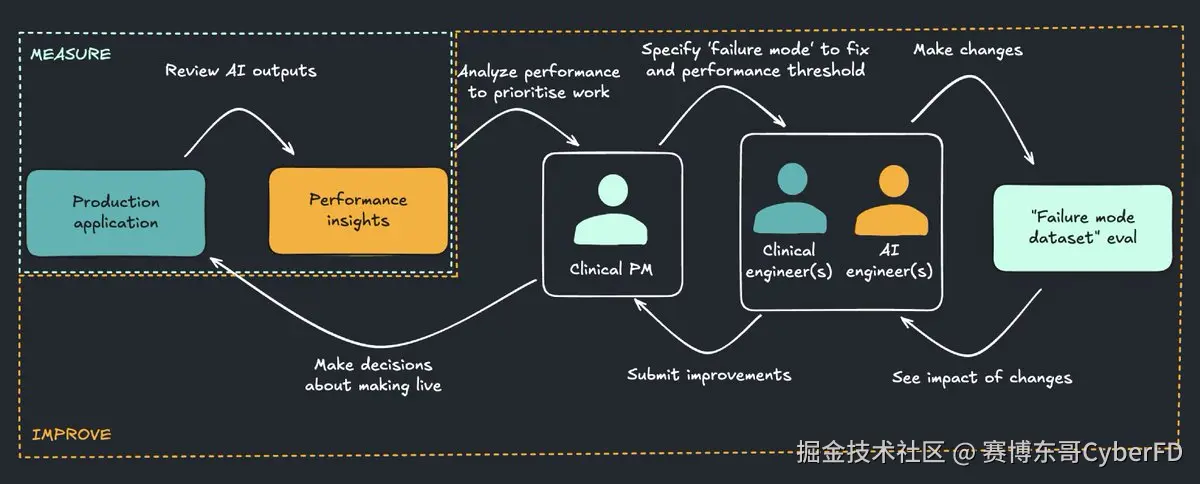
4.2 实施方法
- 反馈闭环:为每个 AI 输出提供"可评分、可纠错、可注释"的界面。
- 专家平台:建立专家协作平台,让医生、律师、审计员、HR 等直接参与标注与迭代。
- 自适应引擎:将专家反馈转化为可执行的改进指令(如知识库更新、Prompt 优化、模型微调)。
4.3 案例
- 医疗 AI 助手:医生可在病历建议旁边直接点击"正确/错误/部分正确",并填写原因。
- 法律文书生成器:律师可高亮标记 AI 输出中存在风险的条款,并保存为训练样本。
- HR 招聘助手:招聘专员可对 AI 给出的简历筛选结果和面试问题进行标注,指出是否合理,并将错误样例反馈回系统以优化未来的推荐逻辑。
关键点:专家反馈必须低摩擦、可量化、可闭环,而不是停留在"意见收集"上。
五. 建立评估与监控体系
5.1 评估体系的重要性
通用模型常见的评估方式(如 BLEU、ROUGE)不适用于垂直领域。真正有价值的评估体系必须贴近业务目标:
- 法律:输出是否合规,是否遗漏风险?
- 医疗:诊断建议是否安全,是否符合指南?
- 金融:报告是否符合监管标准,是否存在逻辑漏洞?
- HR 招聘:候选人推荐是否符合岗位要求,面试问题是否合理,筛选是否公平且符合法规?
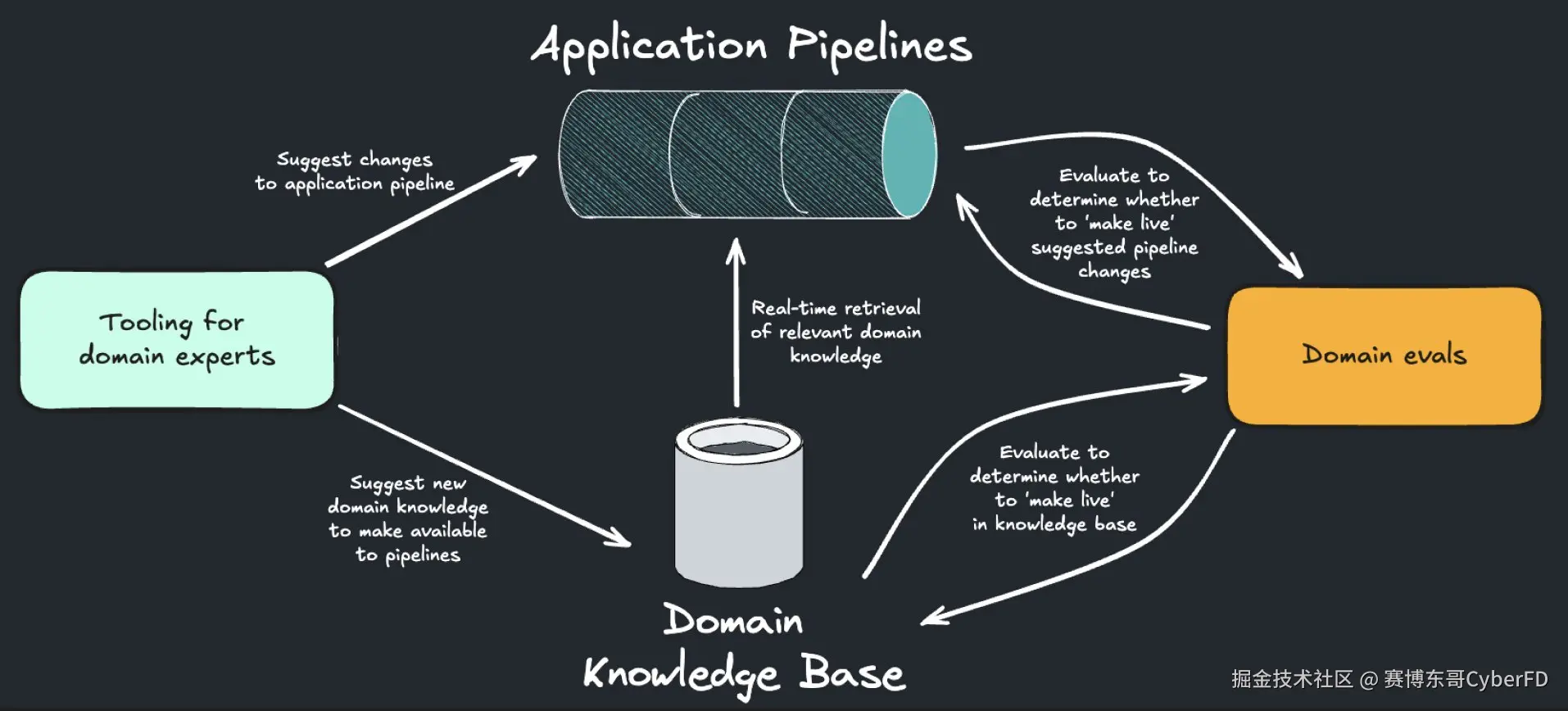
5.2 评估体系设计
- 离线评估:构建标准化的评估数据集(黄金标准案例)。
- 在线评估:在生产环境中实时监控模型表现。
- 用户满意度:通过用户交互行为(采纳/修改/拒绝)衡量。
- 失败模式分类:自动聚合错误案例,形成改进方向。
5.3 实施工具
- 自定义评估仪表盘:可视化展示正确率、用户满意度、失败率等。
- 回归检测机制:新版本上线前自动检测是否出现性能回退。
- 风险警报系统:一旦 AI 输出触碰到高风险错误,自动标记并通知人工干预。
六. 持续迭代与优化
6.1 数据闭环
成功的垂类 AI 应用不是"一次性交付",而是持续演化:
- 实时收集用户交互数据
- 将错误案例转化为新的训练样本
- 更新知识库与 Prompt
6.2 多层次优化
- Prompt 工程:不断优化指令,确保稳定性。
- 模型微调:基于真实反馈样本进行小规模微调。
- 知识库更新:增加新法规、最新临床指南、新的财务审计标准、新的招聘流程与岗位需求。
- 产品迭代:根据用户体验反馈优化交互界面与集成方式。
6.3 组织保障
- 设立跨职能团队:技术 + 产品 + 领域专家。
- 建立快速迭代流程:小步快跑、快速试错。
- 保证合规与风险控制机制始终在位。
七. 实施方案全景表
| 阶段 | 关键任务 | 方法 | 输出成果 |
|---|---|---|---|
| 1. 定义问题 | 明确"最后一公里",识别用户与风险 | 用户访谈、业务流程分析 | 问题陈述文档、需求清单 |
| 2. 知识本体 | 梳理核心概念与失败模式 | 知识图谱、RAG、数据库 | 领域知识本体、失败模式库 |
| 3. 反馈机制 | 设计专家在环系统 | 专家协作平台、低摩擦反馈界面 | 专家标注数据、实时纠错机制 |
| 4. 评估体系 | 构建离线与在线评估 | 评测数据集、仪表盘、警报系统 | 评测数据集、实时监控仪表盘、风险预警机制 |
| 5. 持续迭代 | 数据闭环优化 | Prompt 调优、微调、知识库更新 | 持续演进的模型与应用 |
八. 总结
垂类 AI 应用的落地,并不是单纯"用 LLM + Context上下文管理 + 微调"的技术问题,而是一整套"系统工程":
- 从问题定义到风险控制
- 从知识本体到专家在环
- 从评估监控到持续迭代
其中最重要的启示是:垂直 AI 的胜利不属于最大模型的公司,而属于最懂行业的团队。
未来的竞争,不仅是模型大小之争,而是"谁能把 AI 真正嵌入业务流程,解决最后一公里"。