一提 "C++ 值类别",估计很多刚啃完标准的兄弟当场就懵了!glvalue、prvalue、xvalue... 分不清谁是谁了!编译器还拿着这些玩意儿当规矩,管着表达式怎么创建、复制、移动临时对象 ------ 是不是听着就头大?

Part1先搞懂C++17的"值类别家族"
C++17 标准把表达式的 "值类别" 分成了几个核心角色,说白了就是给每个表达式贴个标签,告诉编译器这货该怎么用。
核心分类就这几个:
- glvalue:"泛左值",听着唬人,其实就是 "能确定身份的表达式"------ 它一评估,就能找到对应的对象、位字段或者函数在哪儿(有明确的 "身份")。
- prvalue:"纯右值",这货不负责确定身份,而是用来初始化对象、位字段,或者计算运算符的操作数 ------ 相当于 "临时产生的原料"。
- xvalue:"将亡值",属于 glvalue 的一种,但特殊在 "资源能复用"------ 就像快过期的牛奶,虽然快不能直接喝了,但还能倒进面团里利用起来(通常是因为它快到生命周期末尾了)。
然后基于这仨,又衍生出两个常见的:
- 左值:所有不是 xvalue 的 glvalue------ 就是咱们平时说的 "能取地址的那些"。
- 右值:prvalue 和 xvalue 的合称 ------ 剩下的那些 "不好直接取地址,但能用的"。
是不是还绕?咱画个简单的关系图:
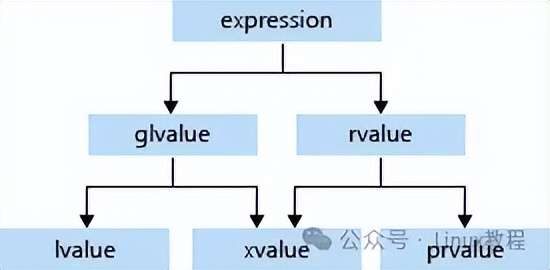
一句话总结:左值是 "活着的 glvalue",xvalue 是 "快死的 glvalue",prvalue 是 "天生临时的右值"。
Part2左值和右值的基本概念
2.1、左值:能 "站住脚" 的表达式
左值就是那种 "有固定身份" 的表达式,你能明确知道它在内存里在哪儿。简单说:能取地址的,基本都是左值。
比如这些都是左值:
- 变量名(包括 const 变量):int a; const int b;,a和b都是左值,你能&a、&b取地址。
- 数组元素:arr0------ 能取地址&arr0,是左值。
- 返回左值引用的函数:int& func() { ... },func()的结果是左值,能当左值用(比如func() = 5;)。
- 类成员、位字段、联合体成员:obj.member、obj->member这些,只要不是 xvalue,都是左值。
左值的特点:
- 可以放在赋值符号左边(除非被 const 锁死)
- 能对它用&取地址
- 是 "长期存在" 的数据(相对右值而言)
就像你家里的冰箱,放在固定位置(有地址),你可以往里面塞东西(赋值),就算加了锁(const),它也还在那个位置,你知道它在哪儿。
2.2、右值:"临时工" 一样的表达式
右值就不一样了,它们是 "临时的"、"用完就扔" 的表达式,没法取地址,也不能放在赋值符号左边。
常见的右值例子:
double x = 1.3, y = 3.8;
10; // 字面常量------纯纯的右值,&10试试?编译器直接报错
x + y; // 表达式的计算结果------临时产生的,算完就没了,不能&(x + y)
fmin(x, y); // 传值返回的函数结果------函数返回的是个临时拷贝,拿不到地址为啥这些是右值?看几个反例就知道了:
10 = 4; // 报错!右值不能放左边
x + y = 4; // 报错!同上
fmin(x, y) = 4; // 报错!还是右值的锅
&10; // 报错!右值不能取地址
&(x + y); // 报错!一样的道理
&fmin(x, y); // 报错!没地址可拿右值的特点:
- 只能待在赋值符号右边(给别人赋值)
- 不能用&取地址(因为是临时的,没固定地址)
- 是 "一次性" 的数据,用完就销毁
就像你去超市买的冰淇淋,拿在手里(临时存在),吃完了盒子就扔了 ------ 它没有固定 "住址"(地址),你也没法把别的东西塞回这个冰淇淋里(赋值)。
Part3左值引用和右值引用
一提 "引用",老 C++ 程序员都知道是给对象起个别名。
3.1、左值引用:给左值当 "替身"
左值引用就是 C++11 之前咱们用的那种引用,专门给左值起别名。写法简单,类型后面加个&就行。
比如这些都是左值引用:
int a = 3;
int* p = &a;
int& ra = a; // 给左值a起别名ra
int*& rp = p; // 给左值指针p起别名rp
int& r = *p; // 给左值*p(其实就是a)起别名r
const int b = 2;
const int& rb = b; // 给const左值b起别名rb左值引用的特点就一条:只能绑在左值上(毕竟叫左值引用嘛)。它就像给家里的冰箱挂个牌子 "这是我家冰箱",牌子(引用)和冰箱(左值)绑定了,你通过牌子就能操作冰箱。
3.2、右值引用:给右值 "续命"
右值引用是 C++11 新搞出来的,专门给右值起别名。写法是类型后面加两个&,也就是&&。
比如这些都是右值引用:
double x = 1.3, y = 3.8;
int&& rr1 = 10; // 给右值10起别名rr1
double&& rr2 = x + y; // 给右值x+y的结果起别名rr2
double&& rr3 = fmin(x, y);// 给右值函数返回值起别名rr3这里有个关键知识点:右值引用本身是左值!
啥意思?右值本来是没法取地址的,但被右值引用绑上之后,就像把 "临时工"(右值)请到了固定工位(特定内存位置),这时候你可以取这个引用的地址,甚至给它赋值:
double&& rr2 = x + y;
&rr2; // 合法!能取rr2的地址(因为它是左值)
rr2 = 9.4; // 合法!能给rr2赋值
const double&& rr4 = x + y;
&rr4; // 能取地址
// rr4 = 5.3; 报错!const修饰的不能改就像你把路边的共享单车(右值)骑回家锁起来(用右值引用绑定),它就成了你家的固定资产(左值),你能知道它在哪儿(取地址),还能给它换零件(赋值)。
3.3、引用规则大总结:谁能绑谁?
别被绕晕,记住下面这些规则,保准不会错:
左值引用的绑定规则:
-
普通左值引用(非 const):只能绑左值,不能直接绑右值
int t = 8;
int& rt1 = t; // 合法:绑左值
// int& rt2 = 8; // 报错:不能绑右值
const 左值引用:既能绑左值,也能绑右值(C++98 时代的万能接收者)
const int& rt3 = t; // 绑左值
const int& rt4 = 8; // 绑右值,合法!
const double& r1 = x + y; // 绑表达式结果(右值)为啥 const 左值引用这么特殊?因为 C++98 没右值引用,想让一个函数参数既能接变量(左值)又能接常量(右值),只能靠它!比如容器的push_back:
vector<int> v;
v.push_back(1); // 1是右值,靠const左值引用接收
v.push_back(t); // t是左值,也能接收右值引用的绑定规则:
-
普通右值引用(非 const):只能绑右值,不能直接绑左值
int&& rr1 = 10; // 合法:绑右值
int t = 10;
// int&& rrt = t; // 报错:不能直接绑左值
但右值引用可以绑被 std::move 处理过的左值
std::move就是个 "转换器",能把左值强行变成右值(其实是 xvalue),这样右值引用就能绑了:
int&& rrt = std::move(t); // 合法:t被move后成右值
int*&& rr4 = std::move(p); // 指针左值也能被move注意:std::move不会真的 "移动" 数据,只是给左值贴个 "可被移动" 的标签,让右值引用能绑它而已。
Part4左值引用为啥非得用它?
左值引用的两大杀招:做参数 + 做返回值
4.1、为啥要用它?
就俩字:省!钱!(省性能,省时间,省CPU)
直接上代码,说人话!
场景一:左值引用做函数参数 ------ 跟深拷贝说拜拜
void func1(string s) { ... } // 传值参数
void func2(const string& s) { ... } // 左值引用参数
int main()
{
string s1("Hello World!");
func1(s1); // 传值调用,会把s1深拷贝一份给形参s
func2(s1); // 左值引用,直接用s1的别名,啥拷贝都没有
return 0;
}- func1用传值参数,调用时会把s1完整复制一份(字符串这种对象的拷贝是深拷贝,代价贼大);
- 而func2用const string&做参数,相当于给s1起了个别名s,函数里操作s就跟操作s1一样,连字节都不用多复制一个。
尤其是处理大对象(比如长字符串、大容器)时,这差距能直接影响程序的运行速度 ------ 左值引用参数直接把拷贝的时间和空间成本砍到零,香不香?
场景二:左值引用做返回值 ------ 前提是对象 "活得够久"
当函数返回的对象出了函数作用域还活着的时候,用左值引用返回能省掉拷贝,效率杠杠的。
比如字符串的+=运算符重载:
string s2("hello");
// 如果是传值返回:string operator+=(char ch)
// 每次调用都会拷贝一个新字符串返回,成本高
// 用左值引用返回:string& operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this; // 返回当前对象的引用(别名)
}
s2 += '!'; // 直接在原对象上修改,返回别名,没任何拷贝这里*this是当前对象,出了函数作用域还好好的(因为对象在函数外面创建),所以返回它的引用完全没问题。调用者拿到的就是原对象的别名,不用等拷贝,直接就能用 ------ 这操作,效率直接拉满!
4.2、左值引用的实际意义
说到底,左值引用之所以牛,核心就一个:减少拷贝,尤其是深拷贝。
传值传参 / 返回时,编译器会把对象从头到尾复制一遍(深拷贝要复制所有数据),这对大对象来说简直是灾难 ------ 既费时间又占内存。而左值引用通过 "起别名" 的方式,让函数直接操作原对象,把这些拷贝开销全给省了,程序自然跑得更快。
可以说,左值引用是 C++ 里提高效率的基础操作,没它,很多代码早就因为拷贝太多而慢得没法看了!
4.3、左值引用的短板
虽然左值引用很牛,但也不是万能的。有个硬伤:不能返回函数里的局部对象的引用。
看这个+运算符重载的例子:
string operator+(const string& s, char ch)
{
string ret(s); // 局部对象,在函数里创建
ret.push_back(ch);
return ret; // 只能传值返回,不能返回引用
}为啥不能返回string&?因为ret是函数里的局部对象,函数一结束,ret就被析构销毁了。这时候要是返回它的引用(别名),调用者拿到的就是个 "野引用"------ 指向已经被销毁的内存,用起来轻则乱码,重则程序崩溃!
所以这种情况下,左值引用也没辙,只能老老实实传值返回,接受那一次拷贝的代价。
那有没有办法解决这个问题?嘿嘿,这就轮到后面要讲的右值引用和移动语义登场了 !
Part5右值引用 + 移动语义
左值引用解决了大部分拷贝问题,但碰到函数里的局部对象返回时就歇菜了 ------ 只能传值返回,逃不掉那讨厌的深拷贝。
这时候,C++11 掏出了右值引用和移动语义这对组合拳,直接把拷贝的开销给干没了!继续扒扒这俩货是怎么做到 "资源搬家" 的,看完你绝对会喊:这操作也太秀了!
5.1、移动语义:不是复制,是 "抢" 资源
移动语义(Move semantics)的核心思想特简单:把一个对象的资源直接 "搬" 到另一个对象里,原对象直接下岗。就像你搬家,不买新家具,直接把旧家的家具挪到新家 ------ 省了买新家具(拷贝)的钱和时间。
5.1.1、移动构造函数:专门干 "搬家" 的活儿
移动构造函数就是用来干这事儿的,它的参数是右值引用(T&&),专门接收右值(或被std::move过的左值),然后把对方的资源 "抢" 过来。
看个模拟 string 类的移动构造:
// 移动构造函数
string(string&& s)
: _str(nullptr) // 先把自己初始化干净
, _size(0)
, _capacity(0)
{
swap(s); // 直接交换资源!把s的家底全换过来
}这里的swap可不是简单交换数值,而是把s的堆内存指针、大小、容量全换过来。原来的s瞬间变成空壳子(_str为 nullptr),而新对象则直接拥有了s的所有资源 ------ 整个过程没有 new,没有拷贝,就一个交换,快得飞起!
拷贝构造 vs 移动构造:谁来干活看 "身份"
拷贝构造和移动构造是重载关系,编译器会根据参数的 "身份"(左值还是右值)选合适的:
- 拷贝构造函数:参数是const T&(const 左值引用),能接收左值和右值,但干活方式是 "复制"(深拷贝)。
- 移动构造函数:参数是T&&(右值引用),只接收右值(或被std::move的左值),干活方式是 "搬家"(资源转移)。
编译器的选择逻辑很实在:右值优先找移动构造,左值只能找拷贝构造。
举个例子:
string s("Hello World!"); // s是左值
string s1 = s; // 左值当参数,调用拷贝构造(深拷贝)
string s2 = std::move(s); // s被move成右值,调用移动构造(资源转移)执行后:
- s1是s的复制品(深拷贝,两份独立资源)。
- s2直接抢走了s的资源,s变成空壳子(一般别再用s了)。
移动构造,到底快在哪?
咱们拿函数返回局部对象的场景对比一下,就知道移动构造有多猛了。
实战:to_string(1234)到底发生了啥?
来看这行代码:
string ret = to_string(1234);我们模拟一个 to_string 函数:
string to_string(int n) {
string str;
// 把 n 转成字符串,存到 str
return str; // str 是局部对象,要返回它
}情况1:C++98(没有移动语义)
return str; // str 是左值,只能拷贝构造一个临时对象然后:
string ret = 临时对象; // 再次拷贝构造❌ 两次深拷贝!浪费!
⚠️ 但现代编译器会优化:返回值优化(RVO),直接在 ret 的位置构造 str,跳过拷贝。但这不是 always guaranteed!
情况2:C++11(有移动语义)
return str; // 编译器知道 str 要死了,自动视为右值!于是:
string ret = 移动构造(临时对象); // 调用移动构造,0拷贝!✅ 即使没有RVO,也只需要一次移动构造,而不是拷贝!
💡 更猛的是:如果编译器做 NRVO(命名返回值优化),甚至能直接构造到 ret 里,连移动都省了!
再看一个经典例子:函数传值返回大对象
Matrix createMatrix() {
Matrix m(1000, 1000); // 大矩阵,堆上分配内存
// 初始化...
return m; // m 是局部变量,要返回
}
Matrix ret = createMatrix(); // 接收- C++98:必须拷贝构造!1000x1000 的数据全复制一遍 → 慢!
- C++11:调用移动构造!只交换指针 → 几乎0开销!
🔥 这就是为啥现代C++可以"大胆返回大对象"------
因为移动语义让它变得廉价!
移动赋值:移动语义的另一半
除了移动构造,还有移动赋值运算符:
string& operator=(string&& s) {
if (this != &s) {
delete[] _str; // 释放自己原来的资源
_str = s._str; // 接管对方资源
_size = s._size;
_capacity = s._capacity;
s._str = nullptr; // 对方清空
s._size = 0;
s._capacity = 0;
}
return *this;
}用起来:
string a = "hello";
string b;
b = std::move(a); // a 的资源移给 b,a 变空现在你明白为啥 std::move 和 T&& 到处都是了吧?
因为它就是C++里的资源回收站,专捡"要扔的破烂",变废为宝!
5.1.2、移动赋值(Move Assignment)
移动赋值函数的作用,简单说就是:让一个已经存在的对象,接管另一个右值对象的资源,原对象的资源直接被替换掉。就像你买了套二手房,不重新装修,直接把原房主的家具家电全留下,自己的旧家具全扔掉 ------ 省时省力还省钱。
看个模拟 string 类的移动赋值实现:
// 移动赋值运算符重载
string& operator=(string&& s)
{
swap(s); // 直接交换资源,把s的家底换过来,自己的旧资源给s
return *this;
}这里的swap还是老规矩:把当前对象(*this)和右值s的资源(堆内存指针、大小、容量)全交换。交换后,s拿着当前对象的旧资源(很快会被销毁,自动释放),而当前对象则美滋滋地用上了s的新资源 ------ 整个过程没有深拷贝,就一个交换操作,快得没朋友!
拷贝赋值 vs 移动赋值:看参数 "身份" 下菜
跟构造函数一样,赋值运算符也有两个版本,编译器根据参数是左值还是右值来选:
- 拷贝赋值函数:参数是const T&(const 左值引用),接收左值或右值,干活方式是 "复制"(先释放自己的旧资源,再深拷贝对方的资源)。
- 移动赋值函数:参数是T&&(右值引用),接收右值(或被std::move的左值),干活方式是 "接管"(直接交换资源,原资源让对方带走销毁)。
编译器的选择逻辑也很直接:右值优先找移动赋值,左值只能找拷贝赋值。
举个例子:
string s("11111111111111111"); // s是左值
string s1("22222222222222222");
s1 = s; // s是左值,调用拷贝赋值(深拷贝,s1释放旧资源,复制s的资源)
string s2("333333333333333333");
s2 = std::move(s); // s被move成右值,调用移动赋值(s2和s交换资源,s的资源归s2)执行后:
- s1变成了s的复制品(深拷贝,两份资源独立)。
- s2接管了s的资源,s变成空壳子(别再用s了,它已经没资源了)。
② 移动赋值有无的差距:效率差在哪?
咱们拿一个实际场景对比下,就知道移动赋值有多香了。
场景:已有对象接收函数返回的临时对象
MyLib::string ret("111111111111111111111111");
ret = MyLib::to_string(12345); // to_string返回临时对象(右值)没有移动赋值(只有拷贝赋值和移动构造):
- 第一步:to_string里的局部对象str被移动构造为临时对象(没问题,零拷贝)。
- 第二步:临时对象是右值,但没有移动赋值,只能调用拷贝赋值 ------ret先释放自己的旧资源,再深拷贝临时对象的资源(大对象的话,这步巨慢)。
有移动赋值:
- 第一步:同上,str移动构造为临时对象(零拷贝)。
- 第二步:临时对象是右值,直接调用移动赋值 ------ret和临时对象交换资源(零拷贝),临时对象拿着ret的旧资源销毁(自动释放)。
就差这一步,有移动赋值的情况下,直接省掉了深拷贝的开销,尤其是对大字符串、大容器这种对象,效率提升可不是一星半点!
5.2、右值引用的使用场景
右值引用的三大杀招:移动语义、容器优化、完美转发!
5.2.1、实现移动语义:给大型对象 "轻装上阵"
移动语义的核心就是 "抢资源" 不 "复制资源",而右值引用就是这操作的 "通行证"。对于那些握有动态资源(比如堆内存、文件句柄)的大型对象,这招能直接把深拷贝的开销砍到零!
场景:动态数组类的资源转移
比如咱们自定义一个DynamicArray类,里面有堆上的数组:
class DynamicArray
{
private:
int* data_; // 堆内存资源
size_t size_;
public:
// 移动构造函数:从右值"偷"资源
DynamicArray(DynamicArray&& other) noexcept
: data_(other.data_) // 直接拿对方的指针
, size_(other.size_)
{
other.data_ = nullptr; // 原对象置空,避免析构时重复释放
other.size_ = 0;
}
// 移动赋值运算符:给已有对象换资源
DynamicArray& operator=(DynamicArray&& other) noexcept
{
if (this != &other)
{
delete[] data_; // 先释放自己的旧资源
data_ = other.data_; // 接管对方的新资源
size_ = other.size_;
other.data_ = nullptr; // 对方变成空壳子
other.size_ = 0;
}
return *this;
}
~DynamicArray() { delete[] data_; } // 析构时只释放自己的资源
};用的时候,想把一个对象的资源转给另一个,直接用std::move触发移动语义:
int main()
{
DynamicArray a; // a有一堆堆内存资源
DynamicArray b = std::move(a); // 触发移动构造,b直接拿走a的资源
// 此时a已经是空壳子,别再用了!
}这操作比深拷贝快多了 ------ 没有新内存分配,没有数据复制,就几个指针的赋值,简直是大型对象的 "续命丹"!
5.2.2、优化容器操作:让 STL 容器飞起来
C++11 之后,STL 容器(比如vector、list)都给自家接口加了右值引用版本,配合移动语义,往容器里塞东西再也不用心疼拷贝开销了。
场景:push_back和emplace_back的效率革命
以前往vector<string>里塞字符串,临时对象会被深拷贝进容器;现在有了右值引用,直接移动进去:
std::vector<std::string> vec;
// 塞临时字符串(右值)
vec.push_back("Hello"); // 临时string被移动进容器,无深拷贝
vec.push_back(std::string("World")); // 同样触发移动,效率拉满
// 更猛的:emplace_back直接在容器里构造,连移动都省了
vec.emplace_back("Hello"); // 直接在容器内存里构造字符串,零拷贝!为啥这么快?因为临时对象是右值,容器的push_back会调用移动构造把资源 "挪" 进去,而不是复制 ------ 对于长字符串这种大块头,这差距可不是一点半点!
5.2.3、完美转发:让参数传递 "原汁原味"
完美转发(Perfect Forwarding)是右值引用的另一大杀器,专门解决泛型编程里 "参数值类别丢失" 的问题。简单说,就是让参数从外层函数传到内层函数时,左值还是左值,右值还是右值,一点不走样。
为啥需要完美转发?
没有完美转发时,参数传递会 "变味":
// 中间转发函数
template<typename T>
void relay(T arg)
{
target(arg); // 这里的arg永远是左值,不管传进来的是啥!
}
// 目标函数的两个版本
void target(int& x) { std::cout << "左值版本\n"; }
void target(int&& x) { std::cout << "右值版本\n"; }
int main()
{
int x = 5;
relay(x); // 传左值,期望调用左值版本(没问题)
relay(10); // 传右值,但arg是左值,结果调用左值版本(出问题!)
}输出全是 "左值版本",因为relay里的arg不管源参数是左值还是右值,自己都是左值 ------ 右值的属性丢了,移动语义自然也触发不了。
右值引用 +forward实现完美转发
用右值引用配合std::forward,就能让参数 "原汁原味" 地传过去:
// 用右值引用做参数,加万能引用
template<typename T>
void relay(T&& arg) // T&&是万能引用,能接左值也能接右值
{
target(std::forward<T>(arg)); // forward保持值类别
}
// 目标函数不变
void target(int& x) { std::cout << "左值版本\n"; }
void target(int&& x) { std::cout << "右值版本\n"; }
int main()
{
int x = 5;
relay(x); // 传左值,调用左值版本
relay(10); // 传右值,调用右值版本(完美!)
}这里的T&&是 "万能引用"(不是普通右值引用),能根据传入的参数类型自动推导 ------ 传左值就变成左值引用,传右值就变成右值引用。再加上std::forward<T>,就能精确保持参数的原始值类别,让内层函数正确匹配重载版本。
完美转发在泛型编程(比如模板库、工厂模式)里太重要了 ------ 它保证了参数传递时不丢信息,该触发移动语义就触发,该调用哪个重载就调用哪个,一点不添乱!
5.3、完美转发的核心机制
完美转发到底是咋做到"左值变左值,右值变右值"的?
这背后全靠两大神器:通用引用(T&&) 和 std::forward
5.3.1、通用引用(T&&):参数的 "万能接收器"
通用引用不是普通的右值引用,它是模板里的 "变形金刚"------ 能根据传入的参数类型自动切换身份,既接左值又接右值,还能悄悄记下参数的原始值类别。
什么是通用引用?
当模板参数是 T&& ,并且 T 需要被编译器推导时,T&& 就成了通用引用(也叫万能引用)。比如:
template<typename T>
void relay(T&& arg) // 这里的T&&就是通用引用
{
// ...
}它的神奇之处在于:能绑定左值,也能绑定右值,还会通过 T 的推导结果记录原始值类别。
通用引用的类型推导规则
传入的参数是左值还是右值,会决定 T 的推导结果,进而决定arg的实际类型:
|---------------|---------|------------------------|
| 传入参数类型 | T 的推导结果 | arg 的实际类型(T&& 折叠后) |
| 左值(如 int&) | int& | int& && → 折叠为 int& |
| 右值(如 int&&) | int | int&& |
举个栗子:
- 当传入左值 int x = 5; relay(x);:
T 被推导为 int&,arg 类型是 int&(左值引用),记住 "原始参数是左值"。 - 当传入右值 relay(10);:
T 被推导为 int,arg 类型是 int&&(右值引用),记住 "原始参数是右值"。
就像一个万能插座,左插头(左值)插进来就变左接口,右插头(右值)插进来就变右接口,还默默记着插头的原始类型。
5.3.2、std::forward<T>:参数的 "身份还原器"
通用引用记下了参数的原始值类别,但arg在函数内部始终是左值(毕竟有名字的变量都是左值)。这时候就需要std::forward<T>登场 ------ 它能根据 T 的推导结果,把arg还原成原始的左值或右值。
std::forward 的原理:按 T 的类型 "还原"
std::forward<T>(arg) 的本质就是一句强制转换:static_cast<T&&>(arg),但它会根据 T 的类型智能选择还原方式:
- 若 T 是左值引用(如 int&):static_cast<int& &&>(arg) → 折叠为 static_cast<int&>(arg),返回左值引用,还原成左值。
- 若 T 是非引用类型(如 int):static_cast<int&&>(arg),返回右值引用,还原成右值。
比如前面的relay函数:
template<typename T>
void relay(T&& arg)
{
target(std::forward<T>(arg)); // 按T的类型还原arg的原始值类别
}- 当传入左值 x(T=int&):forward 返回左值引用,target 收到左值,调用左值版本。
- 当传入右值 10(T=int):forward 返回右值引用,target 收到右值,调用右值版本。
就像快递员根据面单(T 的类型)还原包裹的原始标签 ------ 该标 "左值" 就标 "左值",该标 "右值" 就标 "右值",保证收件人(内层函数)拿到的和寄件人(外层调用)发的一模一样。
5.3.3、完美转发应用场景
最典型的场景就是泛型编程中的参数转发,比如 STL 容器的emplace_back:
std::vector<std::string> vec;
vec.emplace_back("Hello"); // 直接在容器内存中构造stringemplace_back 用通用引用接收参数,再通过forward转发给 string 的构造函数,直接在容器的内存里构造对象,省去了临时对象的拷贝或移动 ------ 这效率,杠杠的!
5.3.4、完美转发 vs std::move:别搞混了!
很多人分不清std::forward和std::move,其实它们的分工完全不同:
|------|-------------------|--------------------|
| 特性 | std::forward | std::move |
| 用途 | 保留参数原始值类别(左 / 右值) | 强制把参数转为右值(用于移动) |
| 条件性 | 看 T 的类型,有条件转换 | 无条件转换(管你原来是什么) |
| 典型场景 | 泛型转发(如模板函数传参) | 明确转移资源(如移动构造 / 赋值) |
简单说:forward是 "还原身份",move是 "强行变性"。
5.3.5、注意事项:这些坑别踩!
① 避免多次转发:
同一个参数被forward多次可能出问题。比如右值被转发后可能已被移动(资源失效),再转发就成了 "悬空引用":
template<typename T>
void relay(T&& arg)
{
target1(std::forward<T>(arg)); // 右值可能被移动
target2(std::forward<T>(arg)); // 危险!arg可能已空
}② 通用引用与重载冲突:
通用引用的匹配能力太强,可能会 "抢" 走其他重载函数的活儿:
template<typename T>
void foo(T&& arg) { /* 通用引用版本 */ }
void foo(int x) { /* 专门处理int的版本 */ }
// 调用时:
foo(10); // 会匹配通用引用版本,而不是int版本!解决办法:用enable_if限制通用引用的匹配范围。
③ const 限定符要保留:
若参数带const,转发时要保证const不丢失。注意:const T&& 是普通右值引用,不是通用引用!
template<typename T>
void relay(const T&& arg) // 右值引用,非通用引用
{
target(std::forward<const T>(arg)); // 保留const
}理解了左值与右值,你会发现 C++ 的很多特性(如移动语义、智能指针、容器优化)都有了源头 ------ 它们本质上都是对 "对象资源如何高效管理" 这一问题的回答。
或许刚开始会觉得绕,但当你能熟练区分 "可长期访问的左值" 和 "即将销毁的右值",能灵活运用引用减少拷贝,能借助std::move和std::forward释放性能潜力时,就真正摸到了 C++ 高效编程的门径。
往期推荐
小米C++校招二面:epoll和poll还有select区别,底层方式?
顺时针螺旋移动法 | 彻底弄懂复杂C/C++嵌套声明、const常量声明!!!