一:不同的存储类型的使用场景
1.1:块存储
块存储在使用的时候需要格式化为指定的文件系统,然后挂载使用,其对操作系统的兼容性相对比较好(可以格式化为操作系统支持的文件系统),挂载的时候通常是每个服务单独分配独立的块存储、即各服务的块存储是独立且不共享使用的,如Redis的master和slave的块存储是独立的、zookeeper各节点的块存储是独立的、MySQL的mater和slave的块存储是独立的、也可以用于私有云与公有云的虚拟机的系统盘和云盘等场景,此类场景适合使用块存储
cephFS:对于需要在多个主机实现数据共享的场景,比如多个nginx读取由多个tomcat写入到存储的数据,可以使用cephFS
对象存储:而对于数据不会经常变化、删除和修改的场景,如短视频、APP下载等,可以使用对象存储。
1.2:分布式存储数据特性:
数据分为数据和元数据:
元数据即是文件的属性信息(文件名、权限(属主、属组)、大小、时间戳等),在分布式存储(cephfs文件存储)中当客户端或者应用程序产生的客户端数据被写入到分布式存储系统的时候,会有一个服务(Name Node)提供文件元数据的路由功能,即告诉应用程序去哪个服务器去请求文件内容,然后再有(Data Node)提供数据的读写请求及数据的高可用功能。

块存储:需要格式化,将文件直接保存到磁盘上。
文件存储:提供数据存储的接口,是由操作系统针对块存储的应用,即由操作系统提供存储接口,应用程序通过调用操作系统将文件保存到块存储进行持久化。
对象存储:也称为基于对象的存储,其中的文件被拆分成多个部分并散布在多个存储服务器,在对象存储中,数据会被分解为称为"对象"的离散单元,并保存在单个存储库中,而不是作为文件夹中的文件或服务器上的块来保存。,对象存储需要一个简单的HTTP应用编程接口(API),以供大多数客户端(各种语言)使用。
二:Ceph基础
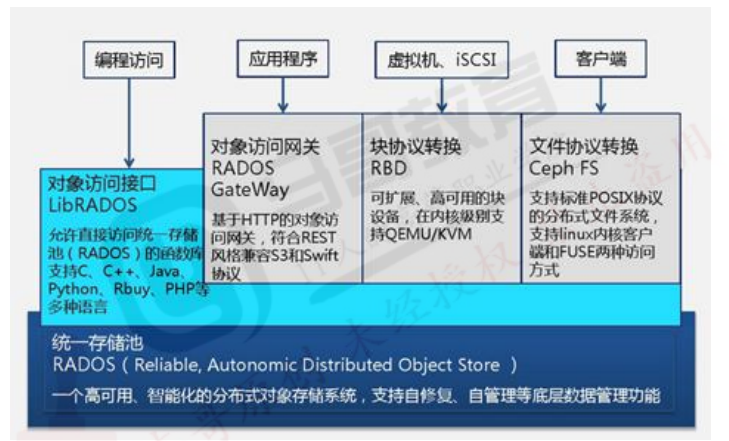
Ceph是一个开源的分布式存储系统,同事支持对象存储、块设备、文件系统
Ceph支持EB(1EB=1,000,000,000GB)级别的数据存储,ceph把每一个待管理的数据流(文件等数据)切分为一到多个固定大小(默认4兆)的对象数据,并以其为原子单元(原子是构成元素的最小单元)完成数据的读写。
Ceph的底层存储服务是由多个存储主机(host)组成的存储集群,该集群也被称之为RADOS(reliable automatic distributed object store)存储集群,即可靠的,自动化的,分布式的对象存储系统。
librados是RADOS存储集群的API,支持C/C++/JAVA/Python/GO等编程语言客户端。
2.1:Ceph的发展史
Ceph项目起源与2003年的加州大学圣克鲁兹分校攻读博士期间的研究课题(Lustre环境中的可扩展问题)。
text
Lustre是一种平行分布式文件系统,早在1999年,由皮特-布拉姆(Peter Braam)创建的集群文件系统公司(Cluster File System Inc)开始研发,并于2003年发布Lustre1.0版本。2007年Sage Weil(赛奇-威尔)毕业后,Sage Weil继续全职从事Ceph工作,2010年3月19日,Linus Torvalds将Ceph客户端合并到2010年5月16日发布的linux内核版本2.6.34,2012年Sage Weil创建了Lnktank Storage用于为Ceph提供专业服务和支持,2014年4月Redhat以1.75亿美元收购inktank公司并开源。

2.2:ceph的设计思想:
Ceph的设计旨在实现一下目标:
每一组皆可扩展
无单点故障
基于软件(而非专用设备)并且开源(无供应商锁定)
在现有的廉价硬件上运行
尽可能自动管理,减少用户干预2.3:ceph的版本历史
Ceph的第一个版本是0.1,发布日期为2008年1月,多年来ceph的版本号一直采用递归更新的方式没变,直到2015年4月0.94.1(Hammer的第一个修正版)发布后,为了避免0.99(以及0.100或1.00),后期的命名方式发生了改变。
x.0.z - 开发版 (给早期测试者和勇士们)
x.1.z - 候选版 (用于测试集群、高手们)
x.2.z - 稳定、修正版(给用户们)
x将从9算起,它代表Infernalis(首字母I是英文单词中的第九个字母),这样我们第九个发布周期的第一个卡发版就是9.0.0,后续的开发版依次是9.0.0->9.0.1->9.0.2等,测试版本就是9.1.0->9.1.1->9.1.2,稳定版本就是9.2.0->9.2.1->9.2.2
2.4:ceph集群角色定义:
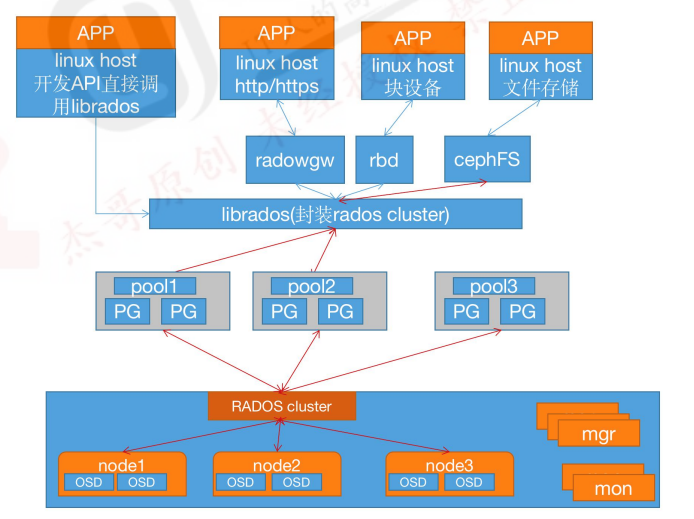
LIBRADOS、RADOSGW、RBD、和CephFS统称为Ceph客户端接口,RADOSGW、RBD、CephFS是基于LIBRADOS提供的多编程语言接口开发的。一个ceph集群的组成部分:
若干的Ceph OSD(对象存储守护程序)
至少需要一个Ceph Monitors监视器
两个或以上的Ceph管理器managers,运行ceph文件系统客户端时还需要高可用的Ceph Metadata Server(文件系统元数据服务器)
RADOS cluster:由多台host存储服务器组成的ceph集群
OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间
Mon(Monitor):ceph的监视器,维护OSD和PG的集群状态,一个ceph集群至少有一个mon,可以是一三五七等等这样的奇数个。
Mgr(Manager): 负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载等2.4.1:Monitor(ceph-mon)ceph监视器:
在一个主机上运行的一个守护进程,由于维护集群状态映射(maintains maps of the cluster state),比如ceph集群中有多少存储池、每个存储池有多少PG以及存储池和PG的映射关系等,monitor map,manager map,the OSD map,the MDS map,and theCRUSH map,这些映射是Ceph守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用cephX协议),通常至少需要三个监视器才能实现允余和高可用性。
2.4.2:Managers(ceph-mgr)的功能:
在一个主机上运行的一个守护进程,Ceph Manager守护程序(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载,Ceph Manager守护程序还托管基于python的模块来管理和公开Ceph集群信息,包括基于Web的Ceph仪表板和REST API,高可用性通常至少需要两个管理器。
2.4.3:Ceph OSDs(对象存储守护程序ceph-osd):
提供存储数据,操作系统上的一个磁盘就是一个OSD守护程序,OSD用于处理ceph集群数据复制,恢复,重新平衡,并通过检查其他Ceph OSD守护程序的心跳来向Ceph监视器和管理器
2.4.4:MDS(ceph元数据服务器ceph-mds):
代表ceph文件系统(NFS/CIFS)存储元数据,(即Ceph块设备和Ceph对象存储不使用MDS)
2.4.5:Ceph的管理节点:
- ceph的常用管理接口是一组命令行工具程序,例如rados、ceph、rbd等命令,ceph管理员可以从某个特定的ceph-mon节点执行管理操作。
- 推荐使用部署专用的管理节点对ceph进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限只对管理人员开放,可以避免一些不必要的误操作的发生。
2.5:Ceph逻辑组织架构
Pool:存储池、分区,存储池的大小取决于底层的存储空间。
PG(placement group):一个pool内部可以有多个PG存在,pool和PG都是抽象的逻辑概念,一个pool中有多少个PG可以通过公式计算。
OSD(Object Storage Daemon,对象存储设备):每一块磁盘都是一个osd,一个主机由一个或多个osd组成。
ceph集群部署好之后,要先创建存储池才能向ceph写入数据,文件在向ceph保存之前要先进行一致性hash计算,计算后会把文件保存在某个对应的PG的,此文件一定属于某个pool的一个PG,在通过PG保存在OSD上。
数据对象在写到主OSD之后再同步对从OSD以实现数据的高可用。
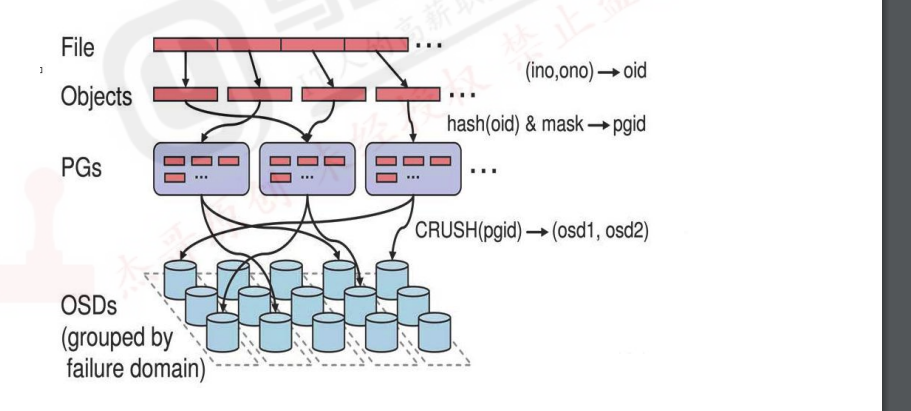
注:存储文件过程:
第一步:计算文件到对象的映射:
bash
计算文件到对象的映射,假如file为客户端要读写的文件,得到oid(object id)=ino+ono ino:inode number(INO),File的元数据序列号,File的唯一id
ono:object number(ONO),File切片产生的某个object的序号,默认以4M切分一个块大小第二步:通过CRUSH把对象映射到PG中的OSD
通过一致性HASH计算Object到PG,Object->PG映射hash(oid)&mask->pgid第三步:通过CRUSH把对象映射到PG中的OSD
通过CRUSH算法计算PG到OSD,PG->OSD映射:[CURSH(pgid)->(osd1,osd2,osd3)]
64-1=63(0~63=累计64个)
1100100=100(对象的hash值)100&64=36,200&64=8
0111111=63(PG总数)
--------------------
0100100=36(与运算结果)第四步:PG中的主OSD将对象写入到硬盘
第五步:主OSD将数据同步给备份OSD,并等待备份OSD返回确认
第六步:主OSD将写入完成返回给客户端
2.6:ceph元数据保存方式:
Ceph对象数据的元数据信息放在哪里呢?对象数据的元数据以key-value的形式存在,再RADOS中有两种实现:xattrs和omap:
ceph可选后端支持多种存储引擎,比如filestore,bluestore,kystore,memstore,ceph使用bluestore存储对象数据的元数据信息。2.6.1:xattrs(扩展属性)
是将元数据保存在对应文件的扩展属性中并保存到系统磁盘上,这要求支持对象存储的本地文件系统(一般是XFS)支持扩展属性。
2.6.2:omap(object map 对象映射):
omap: 是object map的简称。是将元数据保存在本地文件系统之外的独立key-value存储系统中,在使用filestore时是leveldb,在使用bluestore时是rocksdb,由于filestore存在功能问题(需要将磁盘格式化为XFS格式)及元数据高可用问题等问题,因此在目前ceph主要使用bluestore。
2.6.2.1:filestore与leveldb
ceph早期基于filestore使用google的levelDB保存对象的元数据,LevelDB是一个持久化存储的KV系统,和Redis这种内存型的KV系统不同,leveldb不会像Redis一样将数据放在内存从而占用大量的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘上的leveldb空间格式化为文件系统(XFS).
FileStore将数据保存到与Posix兼容的文件系统(例如:Btrfs、XFS、Ext4).在Ceph后端使用传统的Linux文件系统尽管提供了一些好处,但也有代价,如性能、对象属性与磁盘本地文件系统属性匹配存在限制等。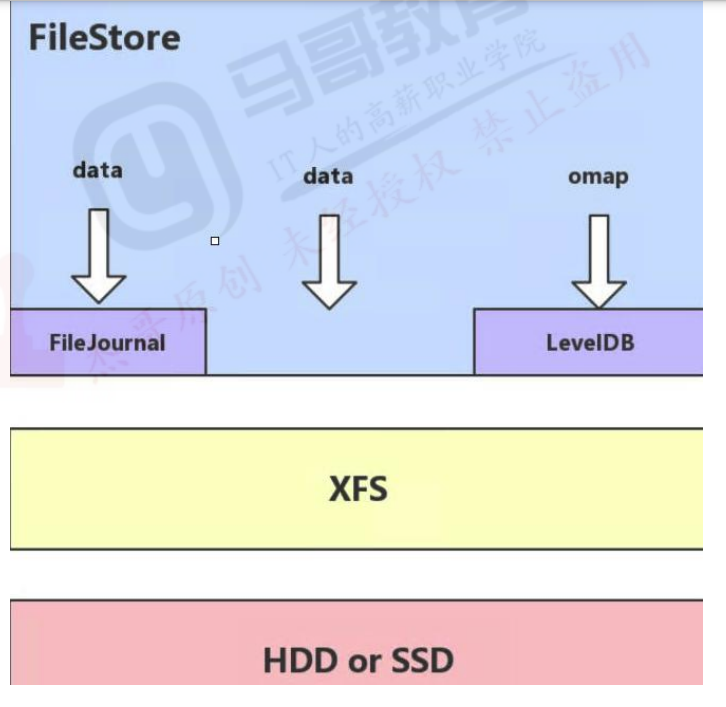
2.6.2.2:bluestore与rocksdb:
由于levelDB依然需要磁盘文件系统的支持,后期facebook对levelDB进行改进为RocksDB,RocksDB将对象数据的元数据保存在RocksDB,但是RocksDB的数据又放在哪里呢?放在内存怕丢失,放在本地磁盘但是解决不了高可用,ceph对象数据放在了每个OSD中,那么就在当前OSD中划分出一部分空间,格式化为BlueFS文件系统用于保存RockesDB中的元数据信息(称为BlueStore),并实现元数据的高可用,BlueStore最大的特点是构建在裸辞设备之上,并且对诸如SSD等新的存储设备做了很多优化工作。
对全SSD及全NVMe SSD闪存适配
绕过本地文件系统层,直接管理裸设备,缩短IO短径
严格分离元数据和数据,提高索引效率
使用KV索引,解决文件系统目录结果遍历效率低的问题。
支持多种设备类型。
解决日志"双写"问题
期望带来至少2倍的写性能提升和同等读性能
增加数据校验及数据压缩等功能RockesDB通过中间层BlueRocksDB访问文件系统的接口,这个文件系统与传统的Linux文件系统(例如Ext4和XFS)是不同的,它不是在VFS下面的通用文件系统,而是一个用户态的逻辑,BlueFS通过函数接口(API,非POSIX)的方式为BlueRocksDB提供类似文件系统的能力
RocksDB通过中间层BlueRocksDB访问文件系统的接口。这个文件系统与传统的Linux文件系统(例如Ext4和XFS)是不同的,它不是在VFS下面的通用文件系统,而是一个用户态的逻辑,BlueFS通过函数接口(API,非POSIX)的方式为BlueRocksDB提供类似文件系统的能力。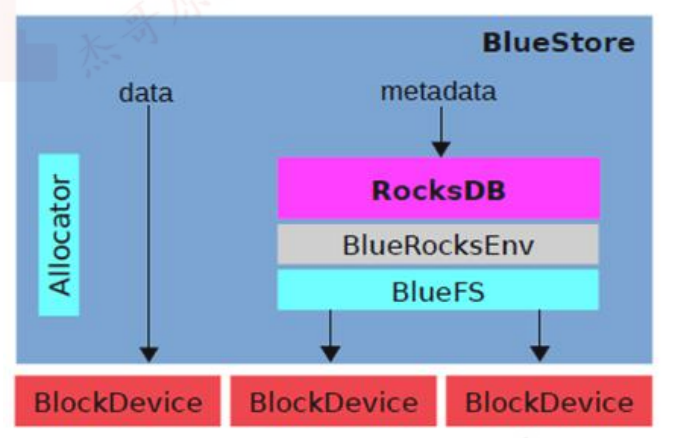
BlueStore的逻辑架构如上图所示,模块的划分都还比较清晰,我们来看下各模块的作用
tex
Allocator: 负责裸设备的空间管理分配
RocksDB:rocksdb是facebook基于leveldb开发的一款kv数据库,BlueStore将元数据全部存放至RocksDB中,这些元数据包括存储预写式日志、数据对象元数据、Ceph的omap数据信息、以及分配器的元数据。
BlueRocksEnv: 这是RocksDB与BlueFS交互的接口;RocksDB提供了文件操作的接口EnvWrapper(Env装饰器),可以通过继承实现该接口来自定义底层的读写操作,BlueRocksEnv就是继承自EnvWrapper实现对BlueFS的读写。
BlueFS:BlueFS是BlueStore针对RocksDB开发的轻量级文件系统,用于存放RocksDB产生的.sst和.log等文件。
BlockDecive: BlueStore抛弃了传统的ext4、xfs文件系统,使用直接管理裸盘的方式;BlueStore支持同时使用多种不同类型的设备,在逻辑上BlueStore将存储空间划分为三层:慢速(Slow)空间、高速(DB)空间、超高速(WAL)空间,不同的空间可以指定使用不同的设备类型,当然也可以使用同一块设备。BlueStore的设计考虑了FileStore中存在的一些硬伤,抛弃了传统的文件系统直接管理裸设备,缩短了IO路径,同时采用ROW的方式,避免了日志双写的问题,再写入性能上有极大的提高。
2.7:Ceph CRUSH算法简介:
Controller replication under scalable hashing #可控的、可复制的、可伸缩的一致性hash算法
Ceph使用CURSH算法来存放和管理数据,它是Ceph的智能数据分发机制,Ceph使用CRUSH算法来准确计算数据应该被保存到哪里,以及应该从哪里获取,和保存元数据不同的是,CRUSH按需计算出元数据,该过程也称为CRUSH查找,然后和OSD直接通信。
1.如果是把对象直接映射到OSD之上会导致对象与OSD的对应关系过于紧密和耦合,当OSD由于故障发生变更时将会对整个ceph集群产生影响。
2.于是ceph将一个对象映射到RADOS集群的时候分为两步走:
首先使用一致性hash算法将对象名称映射到PG2.7
然后将PG ID基于CRUSH算法映射到OSD即可查到对象
3.以上两个过程都是以"实时计算"的方式完成,而没有使用传统的查询数据与块设备的对应表的方式,这样有效避免了组件的"中心化"问题,也解决了查询性能和冗余问题,使得ceph集群扩展不再受查询的性能限制。
4.这个实时计算操作使用的就是CRUSH算法
Controller replication under sclable hashing #可控的、可复制的、可伸缩的一致性hash算法。
CRUSH 是一种分布式算法,类似于一致性hash算法,用于为RADOS存储集群控制数据的分配三:部署ceph集群
https://docs.ceph.org.cn/install/manual-deployment #简要部署过程
版本历史:
https://docs.ceph.com/en/latest/releases/index.html
https://docs.ceph.com/en/latest/release/octopus #ceph15 即octopus版本支持的系统
3.1:部署方式
ceph-ansible: https://github.com/ceph/ceph-ansible #python
ceph-salt: https://github.com/ceph/ceph-salt #python
ceph-container: https://github.com/ceph/ceph-container #shell
ceph-chef: https://github.com/ceph/ceph-chef #Ruby
cephadm: https://docs.ceph.com/en/reef/cephadm/ #ceph官方在ceph15版本加入的ceph部署工具
ceph-deploy: https://github.com/ceph/ceph-deploy #python
是一个ceph官方维护的基于ceph-deploy命令行部署ceph集群的工具,基于ssh执行可以sudo权限的shell命令以及一些python脚本 实现ceph集群的部署和管理维护
Ceph-deploy只用于部署和管理ceph集群,客户端需要访问ceph,需要部署客户端工具。3.2:服务器准备:
构建可靠的、低成本的、可扩展的、与业务紧密结合使用的高性能分布式存储系统
3.2.1:Ceph分布式存储集群规划原则/目标
1. 较低的TCO(Total Cost of Ownership,总拥有成本)
使用廉价的X86服务器
2. 较高的IOPS(Input/Output Operations Per Second,每秒可完成的读写次数)
使用SSD/PCI-E SSD/NVMe硬盘提高存储集群数据以提高读写性能
3. 较大的存储空间
使用2T/4T或更大容量的磁盘,提高单台服务器的总空间,节省服务器总数,降低机柜使用量
4. 较快的网络吞吐
使用10G、40G、100G或更快的光纤网络
5. 更好的数据冗余:
数据可以以三副本机制分别保存到不同的主机,宕机2台也不会丢失数据3.2.2:服务器硬件选型:
monitor、mgr、radosgw:
4C 8G-16G(小型,专用虚拟机)、8C 16G-32G(中型,专用虚拟机)、32C-64C 64G-96G(大型、超大型、物理机)
OSD节点CPU:
每个OSD进程至少有一个CPU核心或以上,比如服务器一共2颗CPU每个12核心24线程,那么服务器总计有48核心CPU,这样最多最多可以放48块磁盘
OSD节点内存:
OSD硬盘空间在2T或以内的时候每个硬盘2G内存,4T的空间每个OSD磁盘4G内存,即大约每1T的磁盘空间(最少)分配1G的内存空间做数据读写缓存
(总内存/OSD磁盘总空间)=X>1G内存
比如:(总内存128G/36T磁盘总空间)=3G/每T>1G内存3.2.3:数据分类存储
是否存在访问量不高的业务备份数据(数据库备份、配置文件备份)和访问量比较高的业务数据(静态文件、对象存储数据)都在ceph集群存储的场景,如果有的话可以分开不同的磁盘存储。
备份数据:SAS 7.2k/10K/15k硬盘
热点数据: SSD固态硬盘3.2.4:ceph集群规划图:
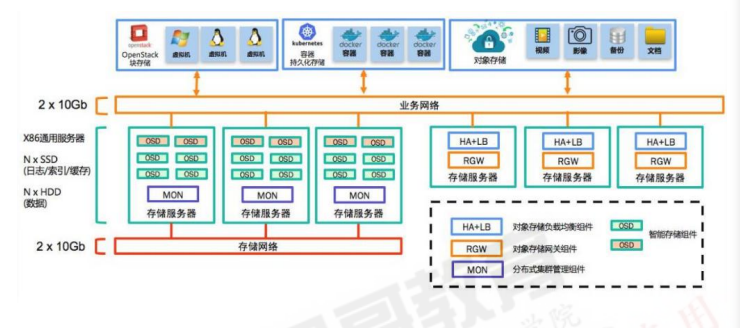
3.2.5:部署环境
-
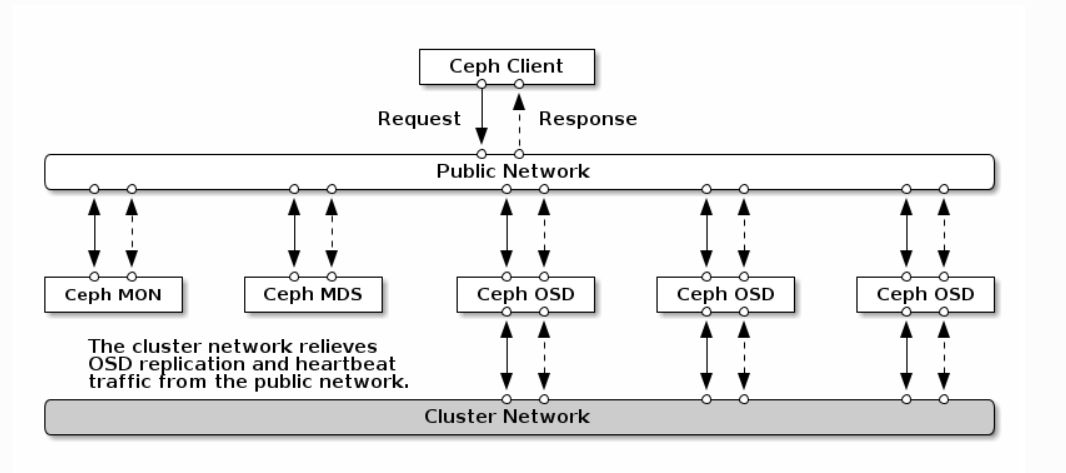
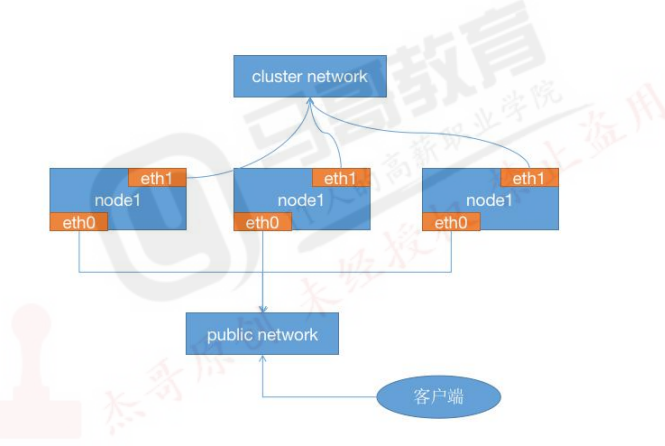
四台服务器作为ceph集群OSD存储服务器,每台服务器支持两个网络,public网络针对客户端访问,cluster网络用于集群管理及数据同步,每台三块或以上的磁盘
172.16.10.100/192.168.163.100 172.16.10.101/192.168.163.101 172.16.10.102/192.168.163.102 172.16.10.103/192.168.163.103 172.16.10.104/192.168.163.104 172.16.10.105/192.168.163.105 172.16.10.106/192.168.163.106 172.16.10.107/192.168.163.107 172.16.10.108/192.168.163.108 各存储服务器磁盘划分: /dev/sdb /dev/sdc /dev/sdd /dec/sde /dev/sdf #100G -
三台服务器作为ceph集群Mon监视服务器,每台服务器可以和ceph集群的cluster网络通信
172.16.10.101/192.168.163.101
172.16.10.102/192.168.163.102
172.16.10.103/192.168.163.103 -
两个ceph-mgr管理服务器,可以和ceph集群的cluster网络通信
172.16.10.104/192.168.163.104
172.16.10.105/192.168.163.105 -
一个服务器用于部署ceph集群即安装ceph-deploy,也可以和ceph-mgr等服用
172.16.10.100/192.168.163.100
-
创建一个普通用户,能够通过sudo执行特权命令,配置主机名解析,ceph集群部署过程中需要对各主机配置不同的主机名,另外如果是centos系统则需要关闭各服务器的防火墙和selinux
-
网络环境:
https://docs.ceph.com/en/reef/rados/configuration/network-config-ref/
3.3:系统环境初始化
时间同步(各服务器时间必须一致)
关闭selinux和防火墙(如果是Centos)
配置主机域名解析或通过DNS解析
3.4:部署RADOS集群
https://mirrors.tuna.tsinghua.edu.cn/ceph/ #清华大学镜像源
3.4.1:仓库准备:
各节点配置ceph apt仓库
导入key文件:
bash
# 支持https镜像仓库源
# apt install -y apt-transport-https ca-certificates curl software-properties-common
# 导入key
# wget -q -O- 'https://download.ceph.com/keys/release.asc' | apt-key add -
# echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list3.4.2:创建ceph集群部署用户cephadmin:
推荐使用指定的普通用户部署和运行ceph集群,普通用户只要能以非交互方式执行sudo 命令执行一些特权命令即可,新版的ceph-deploy 可以指定包含root的在内只要可以执行sudo命令的用户,不过任然推荐使用普通用户,ceph集群安装完成后会自动创建ceph用户(ceph集群默认会使用ceph用户运行各服务进程,如ceph-osd等),因此推荐使用除了ceph用户之外的比如cephuser、cephadmin这样的普通用户去部署和管理ceph集群
tex
cephadmin仅用于通过ceph-deploy部署和管理ceph集群的时候使用,比如首次初始化集群和部署集群、添加节点、删除节点等,ceph集群在node节点、mgr等节点会使用ceph用户启动服务进程。在包含ceph-deploy节点的存储节点、mon节点、mgr节点等创建cephadmin用户
cephadmin@ceph-deploy:~$ groupadd -r -g 2088 cephadmin && useradd -r -m -s /bin/bash -u 2088 -g 2088 cephadmin && echo cephadmin:123456 | chpasswd
各服务器允许cephadmin用户以sudo执行特权命令:
cephadmin@ceph-deploy:~$ echo "cephadmin ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers配置免密钥登录:
在ceph-deploy节点配置密钥分发,允许cephadmin用户以非交互式的方式登录到各ceph/node/mon/mgr节点进行集群部署及管理操作,即在ceph-deploy节点生成密钥对,然后分发公钥到各被管理节点。
bash
cephadmin@ceph-deploy:~$ ssh-keygen
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.100
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.101
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.102
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.103
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.104
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.105
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.106
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@172.16.10.1073.4.3:配置主机名解析:
bash
cephadmin@ceph-deploy:~$ vim /etc/hosts
172.16.10.100 ceph-deploy.example.local ceph-deploy
172.16.10.101 ceph-mon1.example.local ceph-mon1
172.16.10.102 ceph-mon2.example.local ceph-mon2
172.16.10.103 ceph-mon3.example.local ceph-mon3
172.16.10.104 ceph-mgr1.example.local ceph-mgr1
172.16.10.105 ceph-mgr2.example.local ceph-mgr2
172.16.10.106 ceph-node1.example.local ceph-node1
172.16.10.107 ceph-node2.example.local ceph-node2
172.16.10.108 ceph-node3.example.local ceph-node33.4.4:安装ceph部署工具:
在ceph部署服务器安装部署工具ceph-deploy
bash
cephadmin@ceph-deploy:~$ apt install python 各节点安装python2
cephadmin@ceph-deploy:~$ sudo apt install python-pip #ceph-deploy安装
cephadmin@ceph-deploy:~$ pip install ceph-deploy==2.0.1 -i https://mirrors.aliyun.com/pypi/simple #ceph-deploy安装
cephadmin@ceph-deploy:~$ sudo ln -sv /home/cephadmin/.local/bin/ceph-deploy /usr/bin/ceph-deploy3.4.5:初始化mon节点:
在管理节点初始化mon节点:
cephadmin@ceph-deploy:~$ mkdir ceph-cluster #保存当前集群的初始化配置信息
cephadmin@ceph-deploy:~$ cd ceph-cluster
COMMAND description
new 开始部署一个新的ceph的存储集群,并生成CLUSTER.conf集群配置文件和keyring认证文件
install 在远程主机上安装ceph相关的软件包,可以通过--release指定的安装的版本
rgw 管理RGW守护程序(RADOSGW,对象存储网关)
mgr 管理MGR守护程序(ceph-mgr,Ceph Manager DaemonCeph管理器守护程序)
mon 管理Mon守护程序(ceph-mon,ceph监视器)
mds 管理MDS守护程序(Ceph Metadata Server, ceph源数据服务器)
gatherkeys 从指定获取提供新节点的验证keys,这些keys会添加新的MON/OSD/MD加入的时候使用
disk 管理远程主机磁盘
osd 在远程主机准备数据磁盘,即将指定远程主机的指定磁盘添加到ceph集群作为osd使用
admin 推送ceph集群配置文件和client.admin认证文件到远程主机。
repo 远程主机仓库管理
config 将ceph.conf配置文件推送到远程主机或从远程主机拷贝
uninstall 从远程主机删除安装包
purge 删除远端主机的安装包和所有数据
purgedata 从/var/lib/ceph删除ceph数据,会删除/etc/ceph下的内容
calamari 安装并配置一个calamari web节点,calamari是一个web监控平台
forgetkeys 从本地主机删除所有的验证keyring,包括client.admin,monitor,bootstrap等认证文件
pkg 管理远端主机的安装包初始化mon节点过程如下:
Ubuntu 各服务器需要单独安装Python2:
cephadmin@ceph-deploy:~$ apt install python 各节点安装python2
bash
cephadmin@ceph-deploy:~ceph-cluster$ ceph-deploy new --cluster-network 192.168.163.0/24 --public-network 172.16.10.0/24 ceph-mon1验证初始化:
cephadmin@ceph-deploy:~ceph-cluster$ ll
ceph.conf #自动生成的配置文件
ceph-deploy-ceph.log #初始化日子还
ceph.mon.keyring #用于ceph mon节点北部通讯认证的密钥环文件3.4.6:安装ceph-mon服务
在各mon几点安装组件ceph-mon,并通初始化mon节点,mon节点HA还可以后期横向扩容
3.4.6.1:安装ceph-mon:
cephadmin@ceph-mon1:~$apt install ceph-mon -y3.4.6.2:ceph集群添加ceph-mon服务
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial3.4.7:验证mon节点
验证在mon节点已经自动安装并启动了ceph-mon服务,并且后期在ceph-deploy节点初始化目录会生成一些bootstrap ceph mds/mgr/osd/rgw 等服务的keyring认证文件,这些初始化文件拥有对ceph集群的最高权限,所以一定要保存好
3.4.8:分发admin密钥:
在ceph-deploy节点把配置文件和admin密钥拷贝至Ceph集群需要执行ceph管理命令的节点,从而不需要后期通过ceph命令对ceph集群进行管理配置的时候每次都需要指定ceph-mon节点地址和ceph.client.admin.keyring文件,另外各ceph-mon节点也需要同步ceph的集群配置文件与认证文件
如果在ceph-deploy节点管理集群:
cephadmin@ceph-deploy:~/ceph-cluster$ sudo apt install ceph-common -y
#初始化node节点,此步骤必须执行,否则ceph集群的后续安装步骤会报错
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 #--no-adjust-repos 不修改已有的apt仓库源(默认使用官方仓库) --nogpgcheck 不进行校验
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-node1 ceph-node2 ceph-deploy ceph-mon1 #推送证书给ceph-deploy才能管理集群
认证文件的属主和属组为了安全考虑,默认设置为了root用户和root组,如果需要ceph用户也能执行ceph命令,那么就需要对ceph用户进行授权
cephadmin@ceph-deploy:~/ceph-cluster$ sudo setfacl -m u:cephadmin:rw /etc/ceph/ceph.client.admin.keyring #每个服务器都执行3.4.9:部署ceph-mgr节点
mgr节点需要读取ceph的配置文件,即/etc/ceph目录中的配置文件
cephadmin@ceph-mgr1:~$ apt install -y ceph-mgr
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr13.4.10:测试ceph命令:
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: cf7274b6-f403-4eac-abc7-66be79bb0812
health: HEALTH_WARN
mon is allowing insecure global_id reclaim #需要禁用非安全模式通信
OSD count 0 < osd_pool_default_size 3 #集群的OSD数据小于3
services:
mon: 1 daemons, quorum ceph-mon1 (age 33m)
mgr: ceph-mgr1(active, since 30s)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph config set mon auth_allow_insecure_global_id_reclaim false #需要禁用非安全模式通信3.4.11:初始化存储节点:
OSD节点安装运行环境:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node1 #擦除磁盘之前通过deploy节点对node节点执行安装ceph基本运行环境
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-node1 #列出对端主机有哪些磁盘可用
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdb #先擦除磁盘,在添加
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node2 /dev/sdb3.4.12:添加OSD:
3.4.12.1:数据分类保存方式:
-
单块磁盘:
- 机械硬盘或者SSD:
- data:即ceph保存的对象数据
- block:rocks DB数据即元数据
- block-wal:数据库的wal日志
- 机械硬盘或者SSD:
-
两块磁盘
- SSD
- block:rocks DB数据即元数据
- block-wal:数据库的wal日志
- 机械硬盘:
- data:即ceph保存的对象数据
- SSD
-
三块磁盘
-
NVME:
- block:rocks DB数据即元数据
-
SSD:
- block-wal:数据库的wal日志
-
机械硬盘:
- data:即ceph保存的对象数据
root@gf:~/Flow1andFlow2# ceph-deploy osd --help
usage: ceph-deploy osd [-h] {list,create} ...Create OSDs from a data disk on a remote host:
ceph-deploy osd create {node} --data /path/to/deviceFor bluestore, optional devices can be used::
ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device ceph-deploy osd create {node} --data /path/to/data --block-wal /path/to/wal-device ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device --block-wal /path/to/wal-deviceFor filestore, the journal must be specified, as well as the objectstore::
ceph-deploy osd create {node} --filestore --data /path/to/data --journal /path/to/journal #使用filestor的数据和文件系统的日志的路径,journal是systemd的一个组件,用于捕获系统日志信息、内核日志信息、磁盘的日志信息等。
-
3.4.12.2:添加OSD
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdb#添加一个磁盘会生成相对应的ID
#添加磁盘 服务器 id
ceph-deploy osd create ceph-node1 --data /dev/sdb 0
ceph-deploy osd create ceph-node1 --data /dev/sdc 1
ceph-deploy osd create ceph-node1 --data /dev/sdd 2
ceph-deploy osd create ceph-node2 --data /dev/sdd 3
ceph-deploy osd create ceph-node2 --data /dev/sdc 4
ceph-deploy osd create ceph-node2 --data /dev/sdb 53.4.13:从RADOS移除OSD:
Ceph集群中的一个OSD是一个Node节点的服务进程且对应于一个物理磁盘设备,是一个专用的守护进程,在某OSD设备出现故障,或管理员出于管理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后在进行移除操作,对于Luminous及其之后的版本来说,停止和移除命令的格式分别如下所示:
bash
1. 停用设备:ceph osd out {osd-num}
2. 停止进程:sudo systemctl stop ceph-osd@{osd-num}
3. 移除设备: ceph osd purge {id} --yes-i-really-mean-it若类似如下的OSD的配置信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除
不过,对于Luminous之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备。
1. 于CRUSH运行图中移除设备:ceph osd crush remove {name}
2. 移除OSD的认证key: ceph auth del osd.{osd-num}
3. 最后移除OSD设备: ceph osd rm {osd-num}3.4.14:测试上传与下载数据
存取数据时,客户端必须首先连接至RADOS集群上某存储池,然后根据对象名称由相关的CRUSH规则完成数据对象寻址。于是,为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池mypool,并设定其PG数量为32个。
创建pool
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool 32 32
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool mypool| awk '{print $1,$2,$15}' #验证PG和PGP的组合当前的ceph环境还没有部署使用块存储和文件系统使用ceph,也没有使用对象存储的客户端,但是ceph的rados命令可以实现访问ceph对象存储的功能
上传文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /var/log/syslog --pool=mypool#把syslog文件上传到mypool并指定对象id为msg1列出文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados ls --pool=mypool文件信息
ceph osd map命令可以获取到存储池中数据对象的具体位置信息:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd map mypool msg1下载文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados get msg1 --pool=mypool /opt/my.txt修改文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /var/log/1.log --pool=mypool
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados get msg1 --pool=mypool /opt/my.txt删除文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados rm msg1 --pool=mypool
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados ls --pool=mypool3.5:扩展ceph集群实现高可用
主要扩展ceph集群的mon节点以及mgr节点,以实现集群高可用
3.5.1:扩展ceph-mon节点:
Ceph-mon是原生具备自选举以实现高可用机制的ceph服务,节点数据通常是奇数
cephadmin@ceph-mon2:~$ apt install ceph-mon -y
cephadmin@ceph-mon3:~$ apt install ceph-mon -y
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon33.5.2:扩展ceph-mgr节点:
cephadmin@ceph-mgr2:~$ apt install ceph-mgr
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-mgr2 #公布配置文件到ceph-mgr2四:ceph集群应用基础
ceph的集群应用
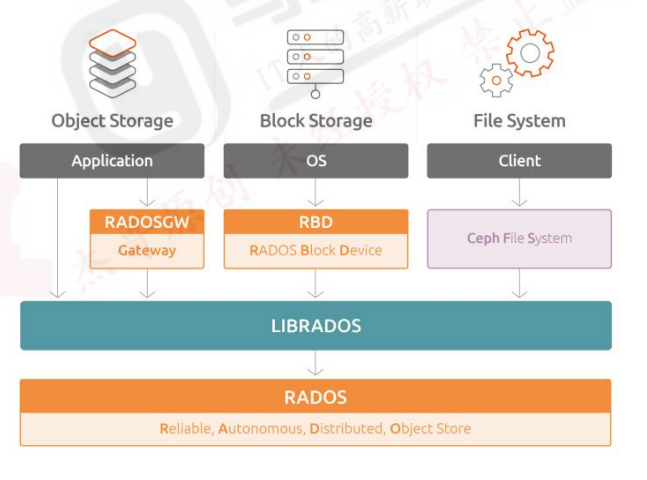
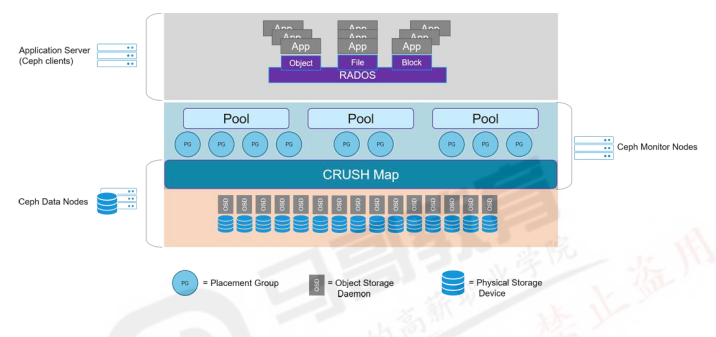
4.1:块存储(RBD)基础:
RBD(RADOS Block Devices)即为块存储设备,RBD可以为KVM、Vmare等虚拟化技术和云服务(如Openstack、kubernetes)提供高性能和无限可扩展性的存储后端,客户端基于librbd库即可将RADOS存储集群用作块设备,不过,用于rbd的存储池需要事先启用rbd功能并进行初始化。例如,下面的命令创建一个名为myrdb1的存储池,并在启用rbd功能后对其进行初始化:
4.1.1:创建RBD:
创建存储池命令格式
$ ceph osd pool create <poolname> pg_num pgp_num {replicated|erasure}
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create myrdb1 64 64 #创建存储池,指定pg和pgp的数量,pgp是对存在于pg的数据进行组合存储,pgp通常等于pg的值。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool application enable myrdb1 rbd #对存储池启用rbd功能
cephadmin@ceph-deploy:~/ceph-cluster$ rbd pool init -p myrdb1 #通过RBD命令初始化存储池
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool ls4.1.2:常见并验证img:
不过,rbd存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用,rbd命令可用于创建、查看及删除块设备在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作,例如:
cephadmin@ceph-deploy:~/ceph-cluster$ rbd create myimg1 --size 1G --pool myrdb1
cephadmin@ceph-deploy:~/ceph-cluster$ cephadmin@ceph-deploy:/etc/ceph$ rbd create myimg2 --size 1G --pool myrdb1 --image-format 2 --image-feature layering
# 后续步骤会使用myimg2镜像,但是由于centos系统内核不支持更多image-feature特性、因此无法挂载使用,所以只开启部分特性,除了layering其它特性需要高版本内核支持
cephadmin@ceph-deploy:~/ceph-cluster$ rbd ls --pool myrbd1
cephadmin@ceph-deploy:~/ceph-cluster$ rbd --image myimg1 --pool myrdb1 info #查看指定rdb的信息4.1.3:客户端使用块存储
4.1.3.1:当前ceph状态
cephadmin@ceph-deploy:~/ceph-cluster$ ceph df #查看存储池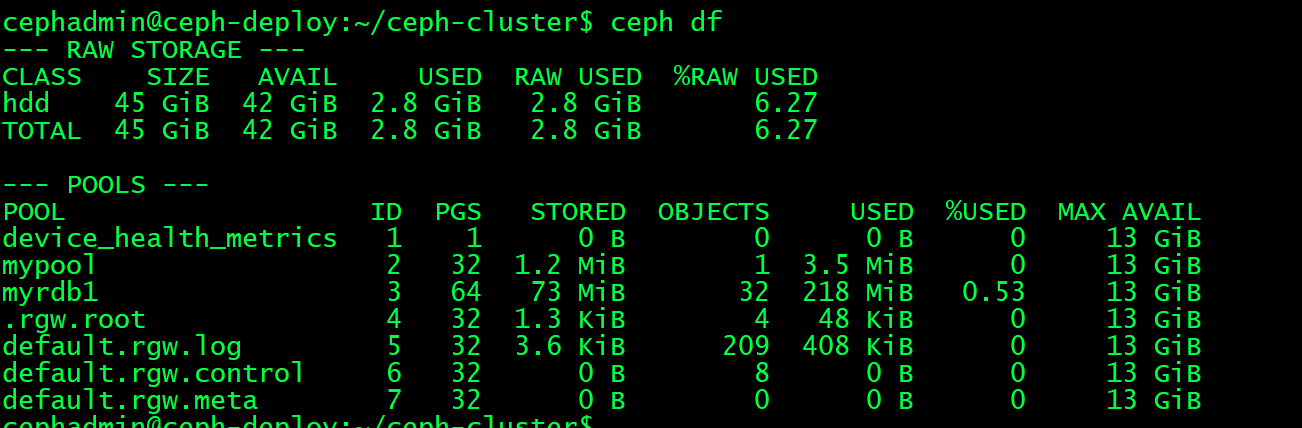
4.1.3.2:在客户端安装ceph-common:
cephadmin@ceph-deploy:~/ceph-cluster$ apt install ceph-common -y4.1.3.3:客户端映射img:
客户端使用ceph存储池
scp ceph.client.admin.keyring ceph.conf 172.16.10.19:/etc/ceph
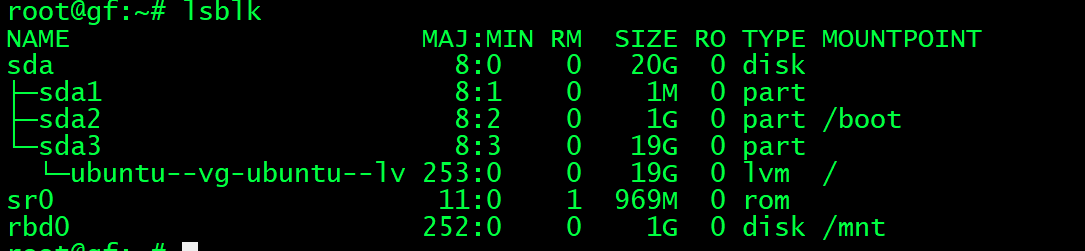
root@gf:~# rbd -p myrdb1 map myimg2 #挂在ceph存储池
/dev/rbd0
root@gf:~# mkfs.ext4 /dev/rbd0 格式化
root@gf:~# ls /mnt/
root@gf:~# mount /dev/rbd0 /mnt/ 挂在ceph df 验证存储的数据
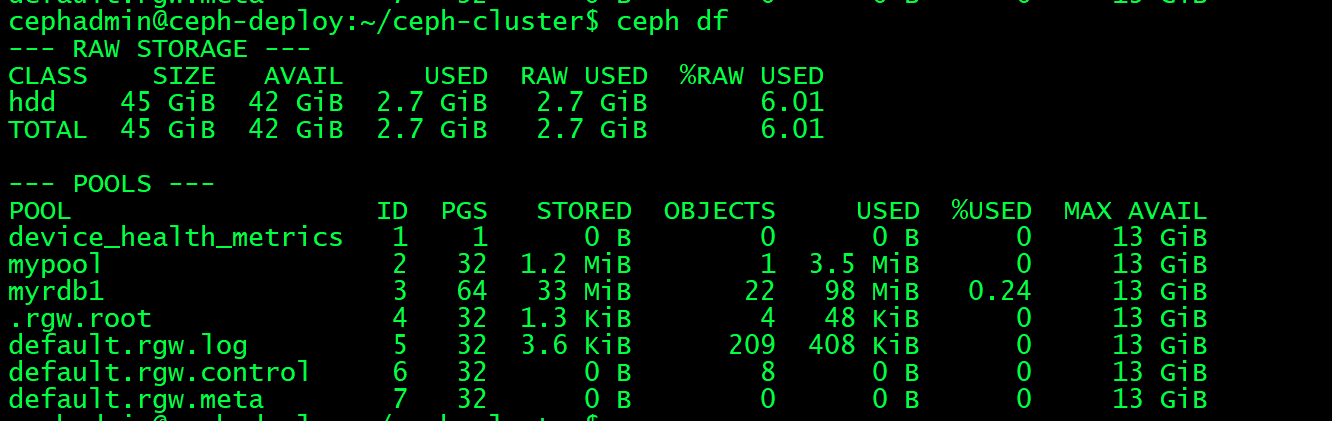
4.1.3.4:客户端验证
root@gf:/mnt# dd if=/dev/zero of=/mnt/file1 bs=1M count=20 生成20的1M4.1.3.5:卸载
root@gf:~# umount /mnt 取消挂载
root@gf:~# rbd -p myrdb1 unmap myimg2 #卸载 4.2:ceph radosgw(RGW)对象存储网关:
RGW提供的是REST风格的API接口,客户端通过http与其进行交互,完成数据的增删改查等管理操作
radosgw用在需要使用RESTful API接口访问ceph 数据的场合,因此在使用RBD即块存储的场合或者使用cephFS的场合可以不用启用radosgw功能。
4.2.1:部署radosgw服务:
如果是在使用radosgw的场合,则一下命令将ceph-mgr1服务器部署为RGW主机
安装radosgw
root@ceph-mgr1:~# apt install radosgw -y 监听在7480
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf rgw create ceph-mgr1 #deploy节点 4.2.2:验证radosgw服务:
gf@ceph-mgr1:~$ ps -aux |grep rados
ceph 1133 0.3 2.9 6276320 58372 ? Ssl 02:14 0:04 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr1 --setuser ceph --setgroup ceph
4.2.3:验证ceph状态:
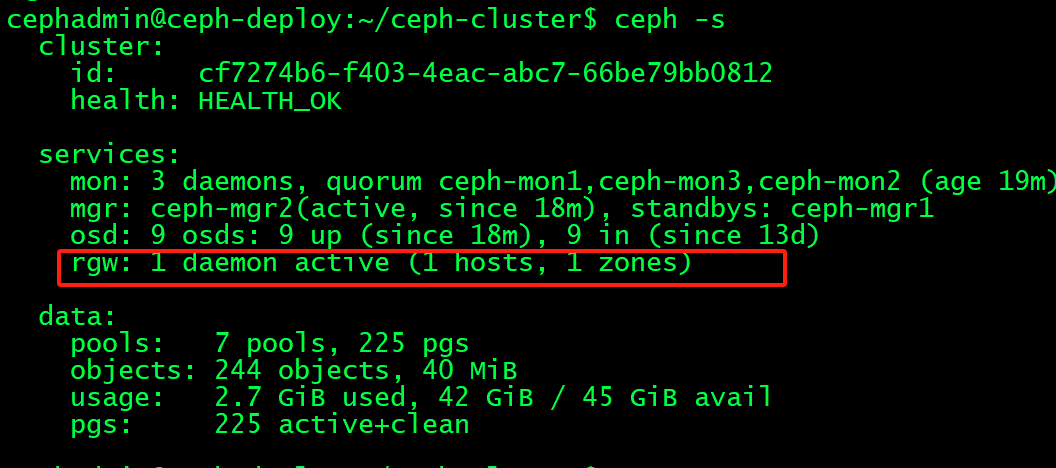
4.2.4:验证radosgw存储池:
初始化完成radosgw后,会初始化默认的存储池如下;
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
myrdb1
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta4.3:Ceph-FS文件存储
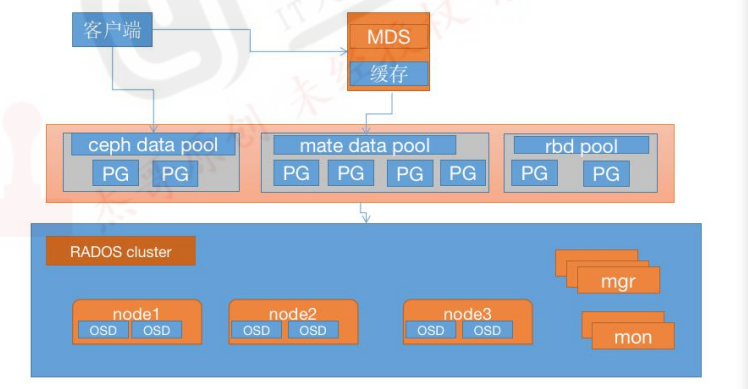
Ceph FS即ceph filesystem,可以实现文件系统共享功能,客户端通过ceph协议挂载并使用ceph集群作为数据存储服务器
Ceph FS需要运行Meta Data Service(MDS)服务,其守护进程为ceph-mds,ceph-mds进程管理与cephFS上存储的文件相关的元数据,并协调对ceph存储集群的访问。
如下图:
数据的元数据保存在单独的一个存储池 cephfs-metadata(名字可字定义),因此元数据也是基于3副本提高可用性,另外使用专用的MDS服务器在内存缓存元数据信息以提高对客户端的读写响应性能
4.3.1:部署MDS服务:
在指定的ceph-mds服务器部署ceph-mds服务,可以和其他服务器混用(如ceph-mon、ceph-mgr)
bash
gf@ceph-mgr1:~$ sudo apt-cache madison ceph-mds
gf@ceph-mgr1:~$ sudo apt install -y ceph-mds
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mgr1
4.3.2:验证MDS服务:
MDS服务目前还无法正常使用,需要为MDS创建存储池用于保存MDS的数据
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mds stat
1 up:standby #当前状态为备用状态,需要分配pool才可以使用4.3.3:创建Ceph FS metadata和data存储池:
使用CephFS之前需要事先集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池,如下命令将创建名为mycephfs的文件系统,它使用cephfs-metadata作为元数据存储池,使用cephfs-data为数据存储池:
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create cephfs-metadata 32 32
pool 'cephfs-metadata' created #保存metadata的pool
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create cephfs-data 64 64
pool 'cephfs-data' created #保存数据的pool
cephadmin@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: cf7274b6-f403-4eac-abc7-66be79bb0812
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon3,ceph-mon2 (age 37m)
mgr: ceph-mgr2(active, since 36m), standbys: ceph-mgr1
osd: 9 osds: 9 up (since 36m), 9 in (since 13d)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
pools: 9 pools, 321 pgs
objects: 244 objects, 40 MiB
usage: 2.7 GiB used, 42 GiB / 45 GiB avail
pgs: 321 active+clean4.3.4:创建cephFS并验证:
bash
ceoh fs new <fs_name> <metadata> <data> [--force] [--allow-dangerous-metadata-overlay
cephadmin@ceph-deploy:~/ceph-cluster$ ceph fs new mycephfs cephfs-metadata cephfs-data
Pool 'cephfs-data' (id '9') has pg autoscale mode 'on' but is not marked as bulk.
Consider setting the flag by running
# ceph osd pool set cephfs-data bulk true
new fs with metadata pool 8 and data pool 9
cephadmin@ceph-deploy:~/ceph-cluster$ ceph fs ls
name: mycephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
4.3.5:验证cephFS服务状态:
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mds stat
mycephfs:1 {0=ceph-mgr1=up:active} #cephfs状态现在已经转变为活动状态4.3.6:客户端挂载cephFS:
在ceph的客户端测试cephfs的挂载,需要指定mon节点的6789端口;
bash
cephadmin@ceph-deploy:~/ceph-cluster$ cat ceph.client.admin.keyring
[client.admin]
key = AQAPQmZnZN/JJBAA2XFYNT8K4Gu+9lPiTqRm1Q==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
root@gf:~# mount -t ceph 172.16.10.101:6789:/ /mnt -o name=admin,secret=AQAPQmZnZN/JJBAA2XFYNT8K4Gu+9lPiTqRm1Q==
#验证挂载点
bash
root@gf:/mnt# cp /var/log/syslog /mnt/ #验证数据
测试数据写入:

验证ceph存储池数据空间:
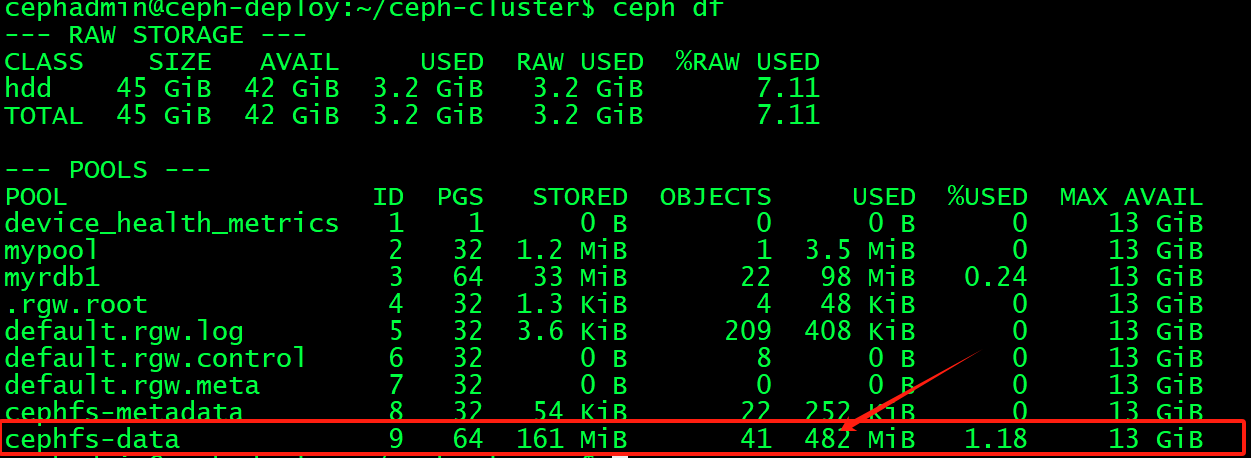
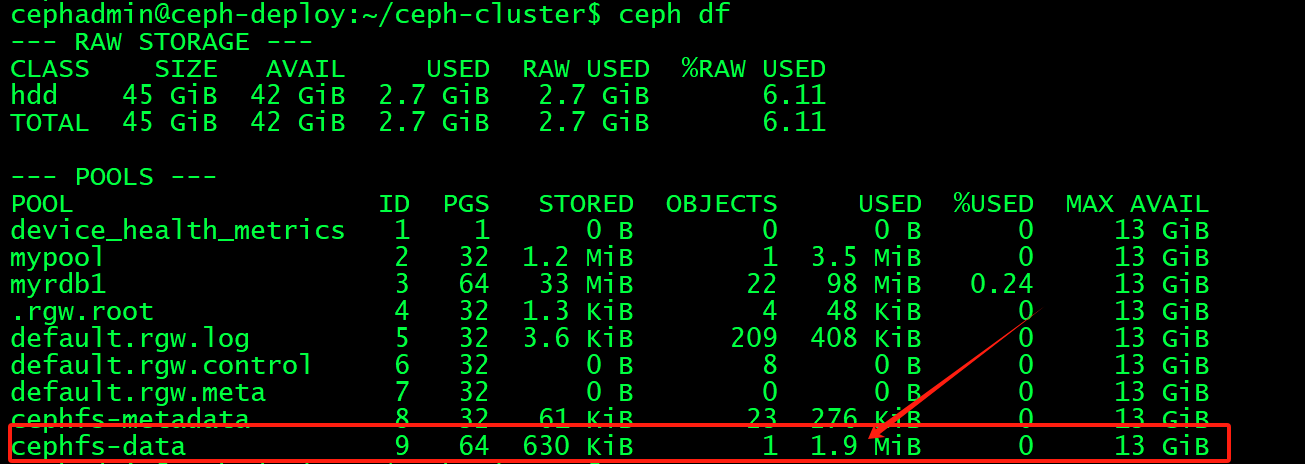
删除数据:
4.3.7: 命令总结:
只显示存储池:
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
myrdb1
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta
cephfs-metadata
cephfs-data
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd lspools #列出存储池并显示id
1 device_health_metrics
2 mypool
3 myrdb1
4 .rgw.root
5 default.rgw.log
6 default.rgw.control
7 default.rgw.meta
8 cephfs-metadata
9 cephfs-data
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg stat #查看pg状态
321 pgs: 321 active+clean; 41 MiB data, 2.7 GiB used, 42 GiB / 45 GiB availcephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool stats mypool #查看指定pool或所有的pool的状态
pool mypool id 2
nothing is going on
cephadmin@ceph-deploy:~/ceph-cluster$ ceph df #查看集群存储状态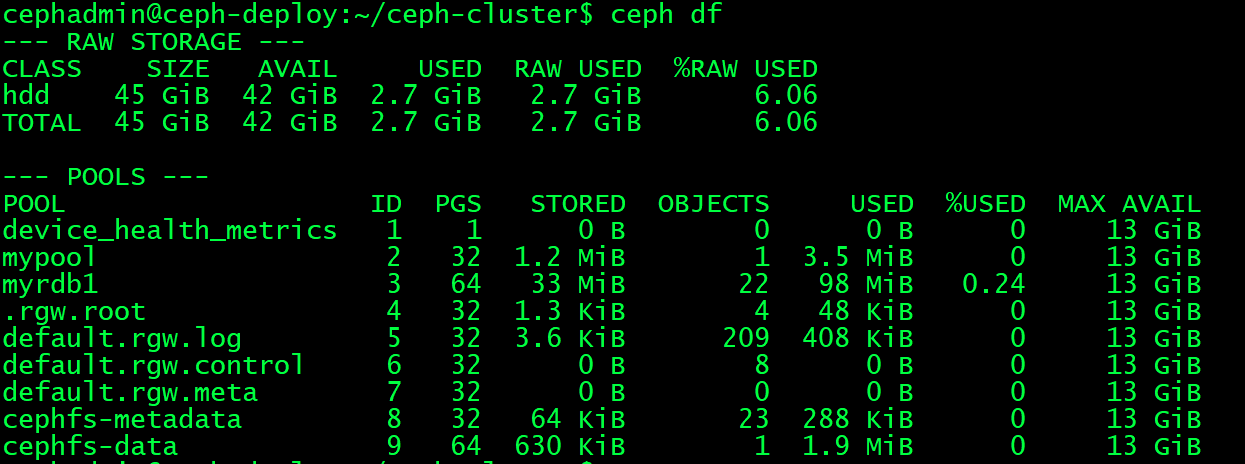
cephadmin@ceph-deploy:~/ceph-cluster$ ceph df detail #查看集群存储状态详情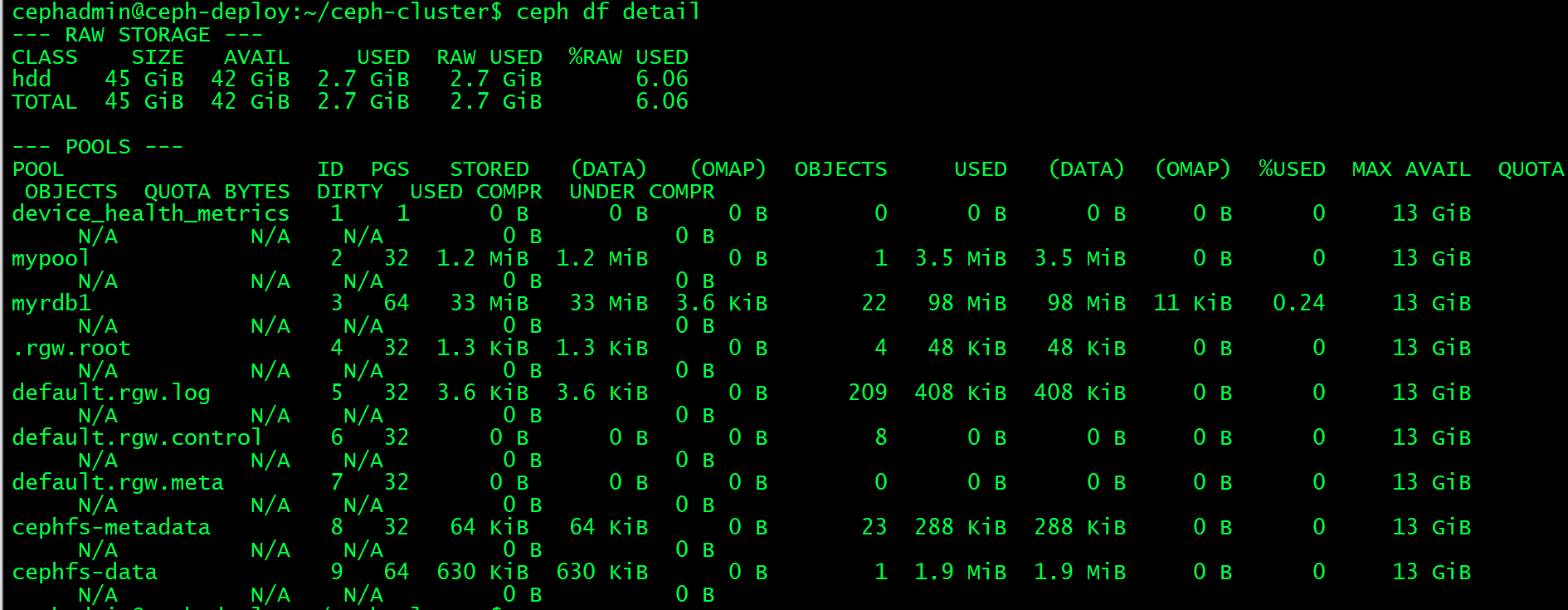
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd stat #查看osd状态
9 osds: 9 up (since 83m), 9 in (since 2w); epoch: e131
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd dump #显示OSD的底层详细信息
epoch 131
fsid cf7274b6-f403-4eac-abc7-66be79bb0812
created 2024-12-21T04:20:31.616930+0000
modified 2025-01-05T02:59:52.507093+0000cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd tree #显示OSD和节点的对应关系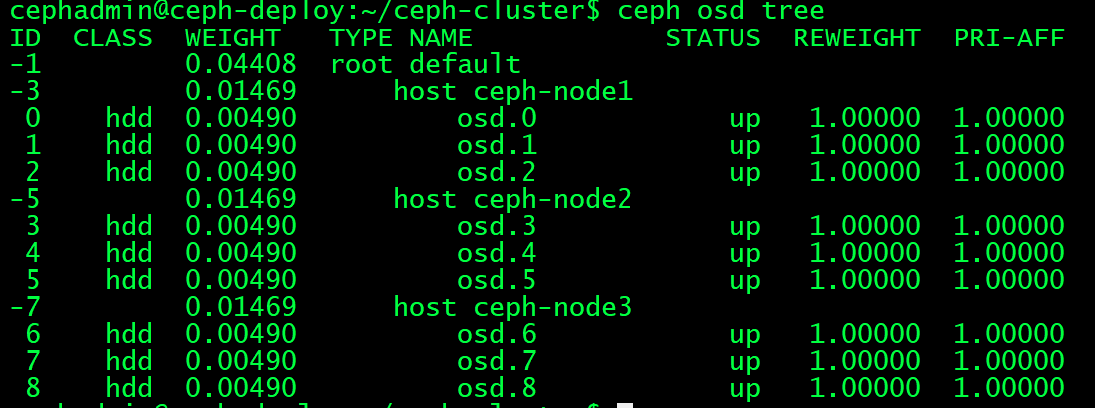
查找OSD对应的硬盘:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd tree #先找出异常osd的ID,加入ID为2的OSD故障
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.04408 root default
-3 0.01469 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
1 hdd 0.00490 osd.1 up 1.00000 1.00000
2 hdd 0.00490 osd.2 up 1.00000 1.00000到OSD对应的node节点查看与OSD对应的硬盘
root@ceph-node1:~# ll /var/lib/ceph/osd/ceph-2/block
lrwxrwxrwx 1 ceph ceph 93 Jan 5 02:14 /var/lib/ceph/osd/ceph-2/block -> /dev/ceph-dcff6c9a-7a21-4026-a15e-67ff20cdb3b4/osd-block-6f471fcb-6246-4c81-897f-9cc9056aa010 
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mon stat #查看mon节点状态
e3: 3 mons at {ceph-mon1=[v2:172.16.10.101:3300/0,v1:172.16.10.101:6789/0],ceph-mon2=[v2:172.16.10.102:3300/0,v1:172.16.10.102:6789/0],ceph-mon3=[v2:172.16.10.103:3300/0,v1:172.16.10.103:6789/0]} removed_ranks: {}, election epoch 36, leader 0 ceph-mon1, quorum 0,1,2 ceph-mon1,ceph-mon3,ceph-mon2cephadmin@ceph-deploy:~/ceph-cluster$ ceph mon dump #查看mon节点的dump信息
epoch 3 #Ceph OSD守护进程和PG的每个状态改变的历史(称之为"epoch"),osd.N的失效会导致osd map变化,epoch值也会自动调整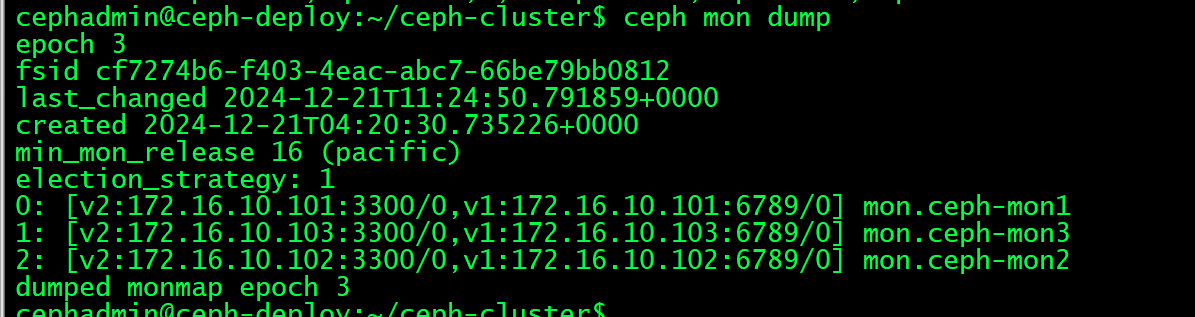
4.4:ceph集群维护
4.4.1:通过套接字进行单机管理:
node节点:
bash
root@ceph-node1:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 100 Jan 5 02:14 ./
drwxr-xr-x 28 root root 920 Jan 5 02:15 ../
srwxr-xr-x 1 ceph ceph 0 Jan 5 02:14 ceph-osd.0.asok=
srwxr-xr-x 1 ceph ceph 0 Jan 5 02:14 ceph-osd.1.asok=
srwxr-xr-x 1 ceph ceph 0 Jan 5 02:14 ceph-osd.2.asok=mon节点:
bash
root@ceph-mon1:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 60 Jan 5 02:14 ./
drwxr-xr-x 28 root root 920 Jan 5 02:15 ../
srwxr-xr-x 1 ceph ceph 0 Jan 5 02:14 ceph-mon.ceph-mon1.asok=
#可在node节点或mon节点通过ceph命令进行单机管理本机的mon或osd服务:
#先将admin认证文件同步到mon或node节点:
cephadmin@ceph-deploy:~/ceph-cluster$ scp ceph.client.admin.keyring root@172.16.10.101:/etc/ceph
root@ceph-node1:/etc/ceph# ceph --admin-socket /var/run/ceph/ceph-osd.0.asok4.4.2:ceph集群的停止或重启
重启之前,要提前设置ceph集群不要将OSD标记为out,避免node节点关闭服务后被踢出ceph集群外
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd set noout #关闭服务前设置noout
noout is set
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset noout #启动服务后取消noout
noout is uns4.4.2.1:关闭顺序:
bash
#关闭服务前设置noout
关闭存储客户端停止读写数据
如果使用了RGW,关闭RGW
关闭cephfs元数据服务
关闭Ceph OSD
关闭Ceph manager
关闭Ceph monitor4.4.2.2:启动顺序:
启动ceph monitor
启动ceph manager
启动ceph OSD
关闭cephfs元数据服务
启动RGW
启动存储客户端
#启动服务后取消 noout-->ceph osd unset noout 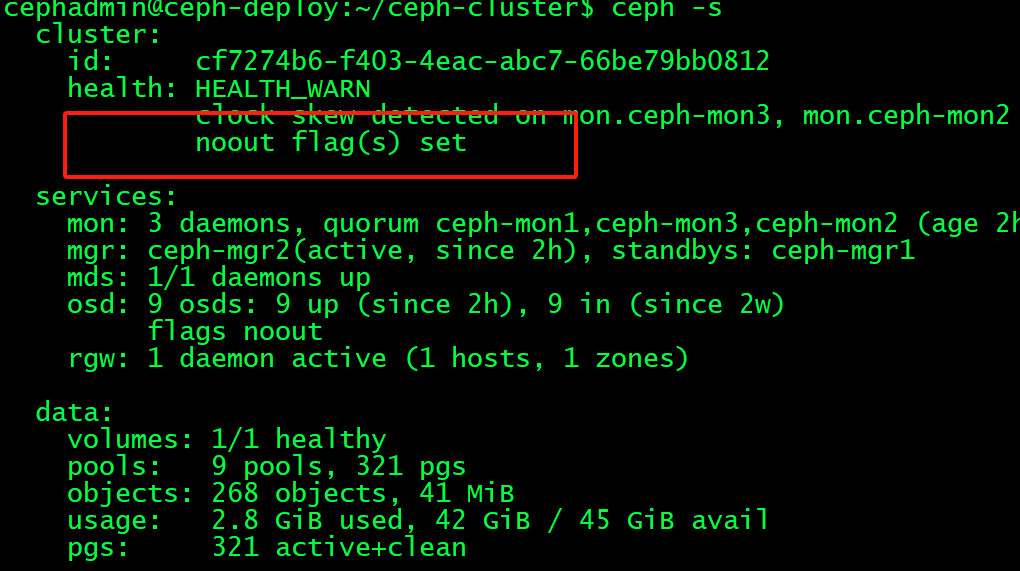
4.4.2.3:添加服务器
1.先添加仓库源
2. ceph-deploy install --release pacific ceph-node1
3. 擦除磁盘 ceph-deploy disk zap ceph-node1 /dev/sdc
4. 添加osd
ceph-deploy osd create ceph-node1 --data /dev/sdc 04.4.2.4:删除OSD或服务器:
把故障的OSD从ceph集群删除
bash
1.把osd提出集群
ceph osd out 1
2.等待一段时间
3.停止osd.x进程
4.删除osd
ceph osd rm 14.4.2.5:删除服务器
停止服务器之前要把服务器的OSD先停止并从ceph集群删除
bash
1.把osd提出集群
ceph osd out 1
2.等待一段时间
3.停止osd.x进程
4.删除osd
ceph osd rm 1
5.当前主机的其他磁盘重复以上操作
6.OSD全部操作完成后下线主机
7.ceph osd crush rm ceph-node1 #从crush删除ceph-node14.6:存储池、PG与CRUSH:
副本池:replicated,定义每个对象在集群中保存为多少个副本,默认为三个副本,一主两备,实现高可用,副本池是ceph默认的存储池类型。
纠删码池(erasure code): 把各对象存储为N=K+M个块(chunk),其中K为数据块数量,M为编码块数量,因此存储池的总大小N等于K+M
即数据保存在K个数据块,并提供M个冗余块提供数据高可用,那么最多能故障的块就是M个,实际的磁盘占用就是K+M块,因此相比副本池机制比较节省存储资源,一般采用8+4机制(默认为2+2),即8个数据块+4个冗余块,那么也就是12个数据块有8个数据块保存数据,有4个实现数据冗余,即1/3的磁盘空间用于数据冗余,比默认副本池的三倍冗余节省空间,但是不能出现大于一定数据块故障。
但是不是所有的应用都支持纠删码池,RBD只支持副本池和radosgw则可以支持纠删码池
4.6.1:副本池IO:
将一个数据对象存储为多个副本
将客户端写入操作时,ceph使用CRUSH算法计算出与对象相对应的PG ID和primary OSD根据设置的副本数、对象名称、存储池名称和集群运行图(cluster map)计算出PG的各辅助OSD,然后由主OSD将数据在同步给辅助OSD。
bash
读取数据:
1.客户端发送读请求,RADOS将请求发送到主OSD。
2.主OSD从本地磁盘读取数据并返回数据,最终完成读请求。
写入数据:
1. 客户端APP请求写入数据,RADOS发送数据到主OSD。
2. 主OSD识别副本OSDs,并发送数据到各副本OSD
3. 副本OSDs写入数据,并发送写入完成信号给主OSD
4. 主OSD发送写入完成信号给客户端APP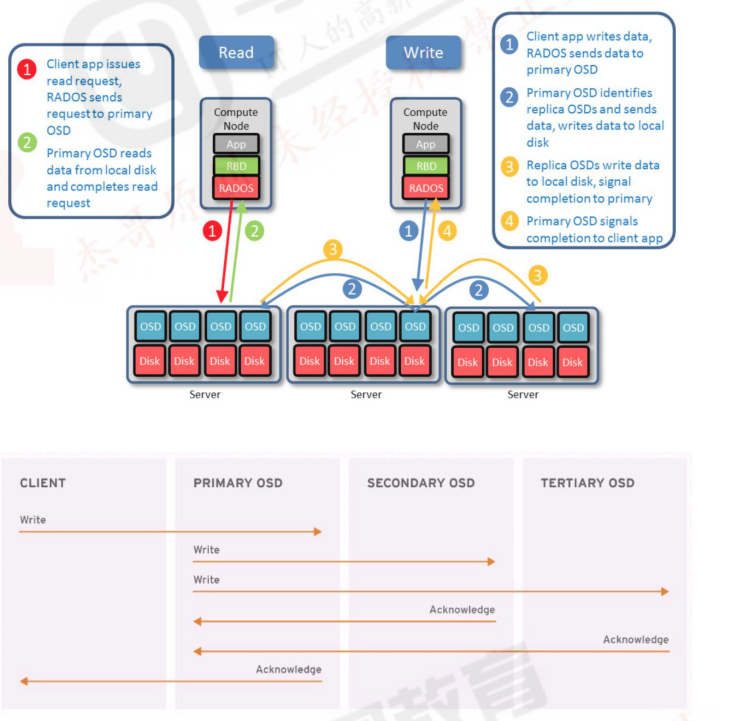
4.6.2:纠删码池IO:
Ceph从Firefly版本开始支持纠删码,但是不推荐在生产环境使用纠删码池。
纠删码池降低了数据保存所需要的磁盘总空间数量,但是读写数据的计算成本要比副本池高
RGW可以支持纠删码池,RBD不支持
纠删码池可以降低企业的前期TCO总拥有成本
bash
纠删码写:
数据将在主OSD进行编码然后分发到相应的OSDs上去
1.计算合适的数据块并进行编码
2.对每个数据块进行编码并写入OSD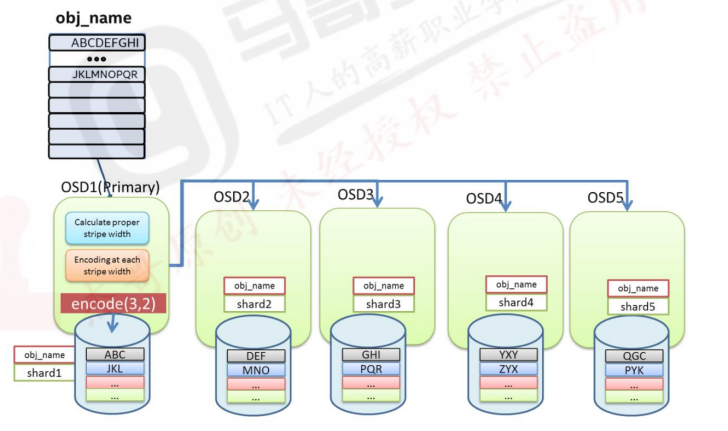
#创建纠删码池
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create erasure-testpool 16 16 erasure
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd erasure-code-profile get default
k=2 #k为数据块的数量,即要将原始对象分割成的块数量,例如,如果k=2,则会将一个10kB对象分割成两个(k)各为5kb的对象
m=2 #编码块(chunk)的数量,即编码函数计算的额外块的数据,如果有2个编码块,则表示有两个额外的备份,最多可以从当前pg中宕机2个OSD,而不会丢失数据。
plugins=jerasure #默认的纠删码池插件
technique=reed_sol_van
#写入数据:
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put -p erasure-testpool testfile1 /var/log/syslog
#验证数据
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd map erasure-testpool testfile1
#验证当前pg状态
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool erasure-testpool |awk '{print $1,$2,$15}'
#测试获取数据
cephadmin@ceph-deploy:~/ceph-cluster$ rados --pool erasure-testpool get testfile1 -
cephadmin@ceph-deploy:~/ceph-cluster$ rados get -p erasure-testpool testfile1 /tmp/testfile1纠删码读:
从相应的OSDs中获取数据后进行解码
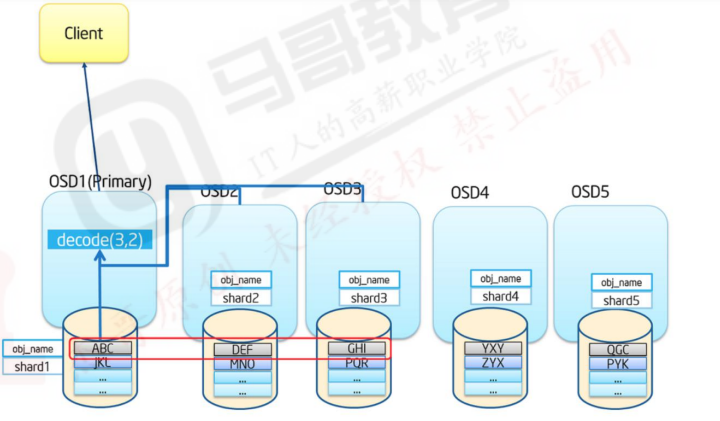
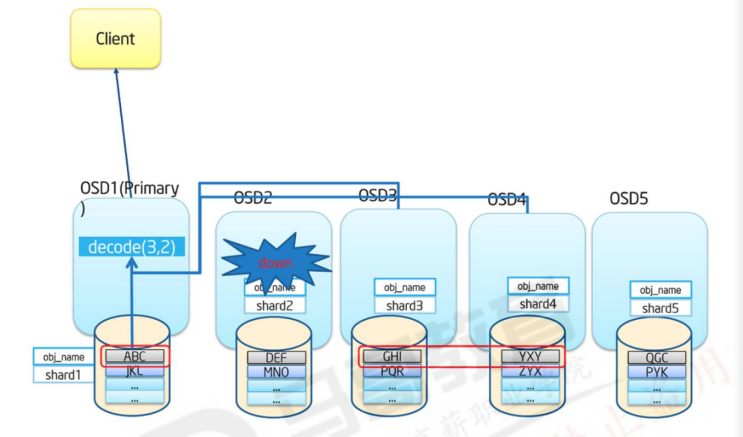
如果此时数据丢失,Ceph会自动从存放校验码的OSD中读取数据进行解码
4.6.3:PG与PGP:
PG= Placement Group #归置组,默认每个PG三个OSD(数据三个副本)
PGP=Placement Group for Placement purpose #规制组的组合,pgp相当于是pg对应osd的一组逻辑排列组合关系(在不同的PG内使用不同组合关系的OSD。
加入PG=32,PGP=32,那么:
数据最多被拆分为32份(PG),写入到有32种组合关系(PGP)的OSD上。
规制组(placement group)是用于跨越多OSD将数据存储在每个存储池中的内部数据结构。
规制组在OSD守护进程和ceph客户端之间生成一个中间层,CRUSH算法负责将每个对象动态映射到一个归置组,然后在将每个规制组动态映射到一个或多个OSD守护进程,从而能够支持在新的OSD设备上线时进行数据重新平衡。
相对于存储池来说,PG是一个虚拟组件,它是对象映射到存储池时使用的虚拟层。
可以自定义存储池中的归置组数量。
ceph出于规模伸缩及性能方面的考虑,ceph将存储池细分份多个规制组,将每个单独的对象映射到归置组,并为归置组分配一个主OSD。
存储池由一系列的归置组组成,而CRUSH算法则根据集群运行图和集群状态,将个PG均匀、伪随机(基于hash映射,每次的计算结果够一样)的分布到集群中的OSD上。
如果某个OSD失败或需要对集群进行重新平衡,ceph则移动或复制整个归置组而不需要单独对每个镜像进行寻址。4.6.4:PG与OSD的关系:
ceph基于crush算法将归置组PG分配至OSD
当一个客户端存储对象的时候,CRUSH算法映射每一个对象至归置组(PG)
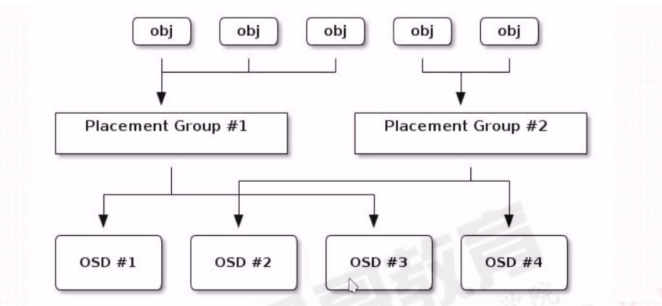
4.6.5:PG分配计算:
归置组(PG)的数量是由管理员在创建存储池的时候指定的,然后由CRUSH负责创建和使用,PG的数量是2的N次方的倍数,每个OSD的PG不要超出250个PG,官方是每个OSD 100个左右。
bash
确保设置了合适的归置组大小,我们建议每个OSD大约100个,例如,osd总数乘以100除以副本数量(即osd池默认大小),因此,对于10个osd、存储池为4个,我们建议每个存储池大约(100*10)/4=21.通常,PG的数量应该是数据的合理力度的子集
例如:一个包含256个PG的存储池,每个PG中包含大学1/256的存储池数据。
2.当需要将PG从一个OSD移动到另一个OSD的时候,PG的数量会对性能产生影响。
PG的数量过少,一个OSD上保存的数据会相对加多,那么ceph同步数据的时候产生的网络负载将对集群的性能输出善生一定影响。
PG过多的时候,ceph将会占用过多的CPU和内存资源用于记录PG的状态信息。
3.PG的数量在集群分发数据和重新平衡时扮演者重要的角色作用
在所有OSD之间进行数据持久存储以及完成数据分布会需要较多的归置组,但是他们的数量应该减少到实现ceph最大性能所需的最小PG数量值,以节省CPU和内存资源
一般来说,对于有着超过50个OSD的RADOS集群,建议每个OSD大约有50-100个PG以平衡资源使用及取得更好的数据持久性和数据分布,而在更大的集群中,每个OSD可以有100-200个PG
至少一个pool应该使用多少个PG,可以通过下面的公式计算后,将pool的PG值四舍五入到最近的2的N次幂,如下先计算出ceph集群的总PG数:
Total OSDs * PGPerOSD/replication factor => total PGs
磁盘总数 × 每个磁盘PG数/副本数 => ceph集群总PG数(略大于2^n次方)
官方计算公式:
Total PGs = (Total_number_of_OSD * 100)/max_replication_count
单个pool的PG计算如下:
有100个osd,3副本,5个pool
Total PGs=100*100/3=3333
每个pool的PG=3333/5=512,那么创建pool的时候就指定pg为512
需要结合数据数量、磁盘数量及磁盘空间计算出PG数量,8、16、32、64、128、256等2的N次方
一个RADOS集群上会存在多个存储池,因此管理员还需要考虑所有存储池上的PG分布后每个OSD需要映射的PG数量。
$ ceph osd pool create testpool2 60 60
$ ceph osd pool create testpool3 40 30
$ ceph osd pool create testpool4 45 45
ceph的pg数量推荐是2的整次幂,比如2的平方叫二次幂,立方叫三次幂,幂的大小是整数,如果不是2的整次方会有提示:4.6.6:验证PG与PGP组合
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool mypool
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool mypool|awk '{print $1,$2,$15}'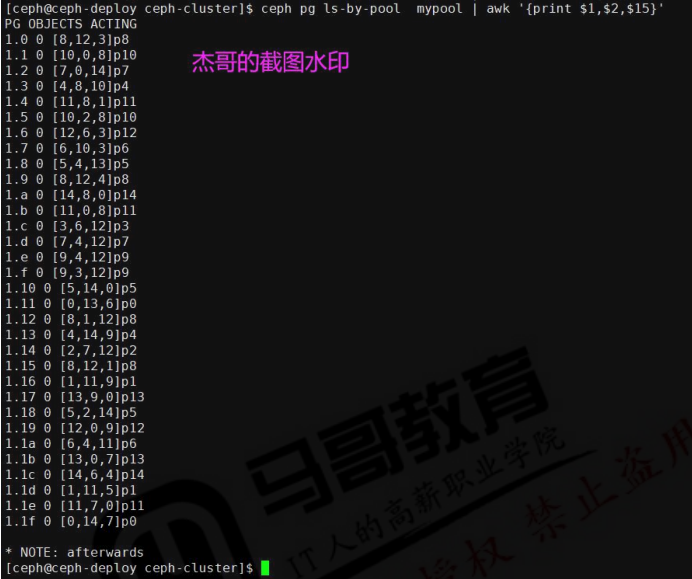
4.7:PG的状态
PG的常见状态如下:
4.7.1:Peering:
正在同步状态,同一个PG中的OSD需要将准备数据同步一致,而Peering(对等)就是OSD同步过程中的状态。
4.7.2:Activating:
Peering已经完成,PG正在等待所有PG实例同步Peering的结果(info、Log等)
4.7.3:Clean
干净太,PG当前不存在待修复的对象,并且大小等于存储池的副本数,即PG的活动集(Acting set)和上行集(Up Set)为同一组OSD内容一致。
活动集(Acting Set): 由PG当前主的OSD和其余处于活动状态的备用OSD组成,当前PG内的OSD负责处理用户的读写请求。
上行集(Up Set):在某一个OSD故障时,需要将故障的OSD更换为可用的OSD,并主PG内部的主OSD同步数据到新的OSD上,例如PG内有OSD1、OSD2、OSD3,当OSD3故障后需要用OSD4替换OSD3,那么OSD1、OSD2、OSD3就是上行集,替换后OSD1、OSD2、OSD4就是活动集,OSD替换完成后活动集最终要替换上行集。
4.7.4:Active:
就绪状态或活跃状态,Active表示主OSD和备OSD处于正常工作状态,此时的PG可以正常处理来自客户端的读写请求,正常的PG默认就是Active+Clean状态。
bash
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg stat4.7.5:Degraded:降级状态:
降级状态出现于OSD被标记为down以后,那么其他映射到此OSD的PG都会转换到降级状态
如果此OSD还能重新启动完成并完成Peering操作后,那么使用此OSD的PG将重新恢复为clean状态
如果此OSD被标记为down的时间超过5分钟还没有修复,那么此OSD将会被ceph踢出集群,然后ceph会对降级的PG启动恢复操作,直到所有由于此OSD而被降级的PG重新恢复为clean状态
恢复数据会从PG内的主OSD恢复,如果是主OSD故障,那么会在剩下的两个备用OSD重新选择一个作为主OSD。
4.7.6:Stale:过期状态:
正常状态下,每个主OSD都要周期性的向RADOS集群中的监视器(Mon)报告其作为主OSD所持有的所有PG的最新统计数据,因任何原因导致某个OSD无法正常向监视器发送汇报信息的、或者由其他OSD报告某个OSD已经down的时候,则所有以此OSD为主PG则会立即标记为stale状态,即他们的主OSD已经不是最新的数据了,如果是备份的OSD发送down的时候,则ceph会执行修复而不会触发PG状态转换为stale状态。
4.7.7:undersized:
PG当前副本数小于其存储池定义的值的时候,PG会转换为undersized状态,比如两个备份OSD都down了,那么此时PG中的只有一个主OSD了,不符合ceph最少要求一个主OSD加一个备OSD的要求,那么就会导致使用此OSD的PG转化为undersized状态,直到添加备份OSD添加完成,或者修复完成。
4.7.8:Scrubbing:
scrub是ceph对数据的清洗状态,用来保证数据完整性的机制,Ceph的OSD定期启动scrub线程来扫描部分对象,通过与其他副本比对发现是否一致,如果存在不一致,抛出异常提示用户手动解决,scrub以PG为单位,对于每一个pg,ceph分析该pg下所有的object,产生一个类似于元数据信息摘要的数据结构,如对象大小、属性等。叫scrubmap,比较主与副scrubmap,来保证是不是有object丢失或者不匹配,扫描分为轻量级扫描和深度扫描,轻量级扫描也叫做light scrubs或者shallow scrubs或者simply scrubs即轻量级扫描
4.7.9:Recovering:
正在恢复态,集群正在执行迁移或同步对象和他们的副本,这可能是由于添加了一个新的OSD到集群中或者某个OSD宕掉后,PG可能会被CRUSH算法重新分配不同的OSD,而由于OSD更换导致PG发生内部数据同步的过程中的PG会被标记为Recovering。
4.7.10:Backfilling:
正在后台填充态,backfill是recover的一种特殊场景,指peering完成后,如果基于当前权威日志无法对Up Set(上行集)当中的某些PG实例实施增量同步(例如承载这些PG实例的OSD离线太久,或者是新的OSD加入集群导致的PG实例整体迁移)则通过完全拷贝当前Primary所有对象的方式进行全量同步,此过程中的PG会处于backfilling。
4.7.11:Backfill-toofull:
某个需要被Backfill的PG实例,其所在的OSD可用空间不足,Backfill流程当前被挂起时PG给的状态。
五:ceph优化