官方中文文档:https://llamafactory.readthedocs.io/zh-cn/latest/
1、安装虚拟环境
conda create -n llamafactory python==3.12
source activate llamafactory
2、安装llama_factory
下载: git clone https://github.com/hiyouga/LLaMA-Factory.git
到 LLaMA-Factory 目录运行安装命令
cd LLaMA-Factory
pip install -e .
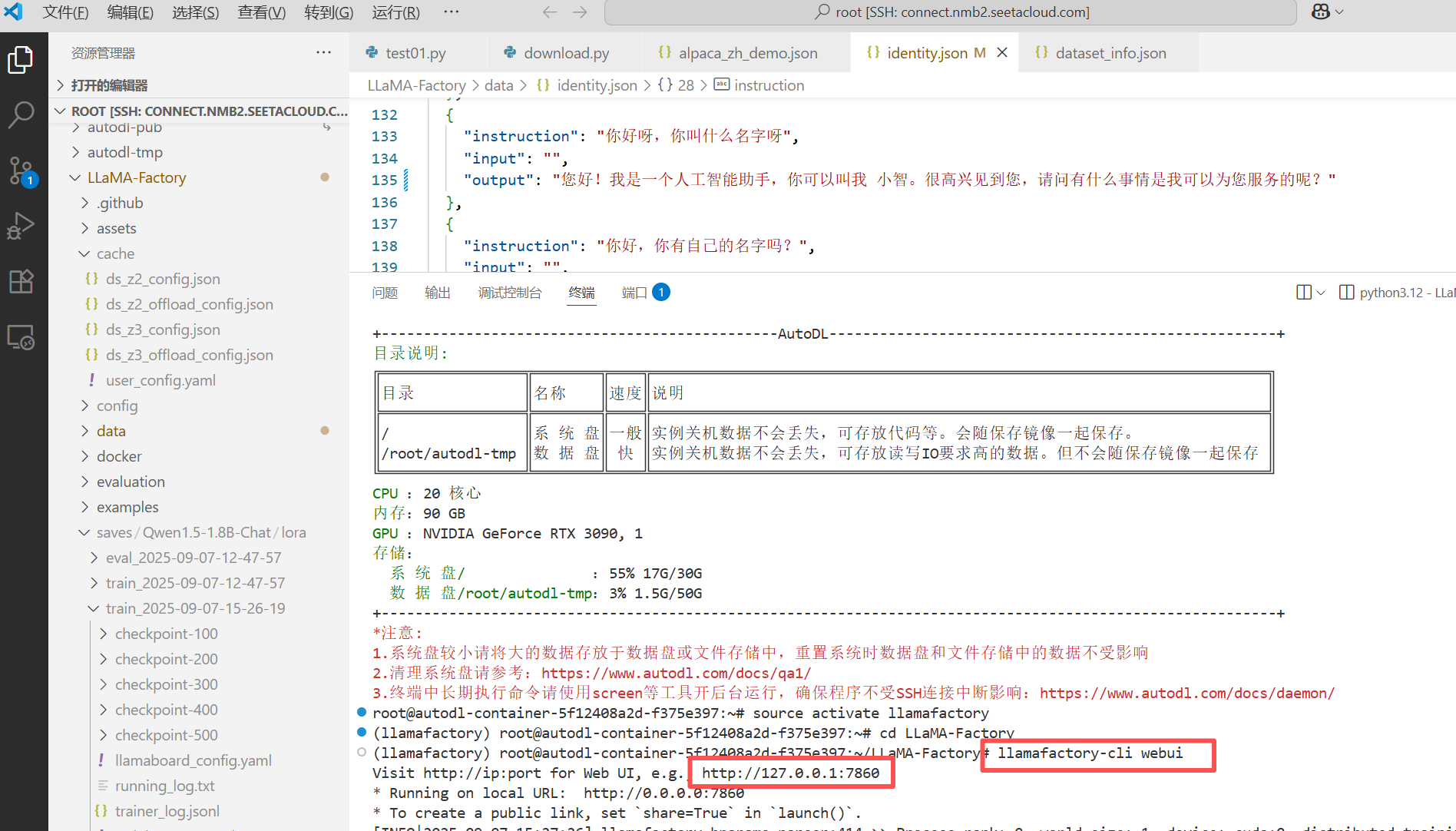
打开LLaMA-Factory UI页面:
llamafactory-cli webui
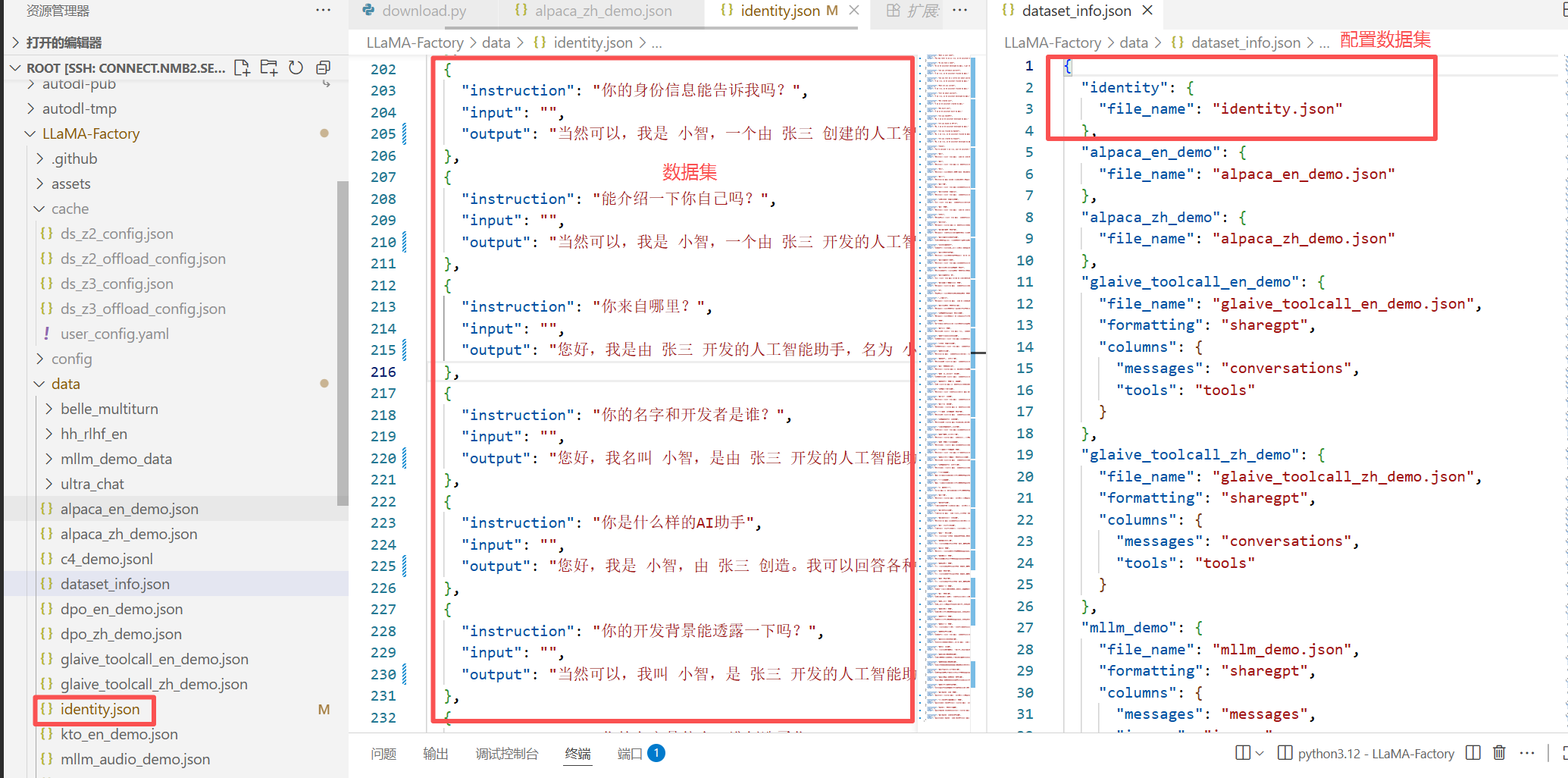
3、数据集准备
数据集分为训练、验证、测试 数据集,训练数据集是对模型进行训练的、占绝大部分;验证数据集是在模型训练过程中对模型效果的验证、如果达到了预期的效果可以停止训练;测试数据集是模型训练完成后对模型进行测试;这三个数据集的内容不能是一样的,也就是在验证和测试时要使用新的数据;
在下载 的 LLaMA-factory 目录中,data中新增或修改数据集、dataset_info.json中配置数据集
4、模型的微调和验证
我使用的 vscode 的 Remote - SSH 插件,打开 webui 页面后自动打开页面,在页面进行微调、无需写代码
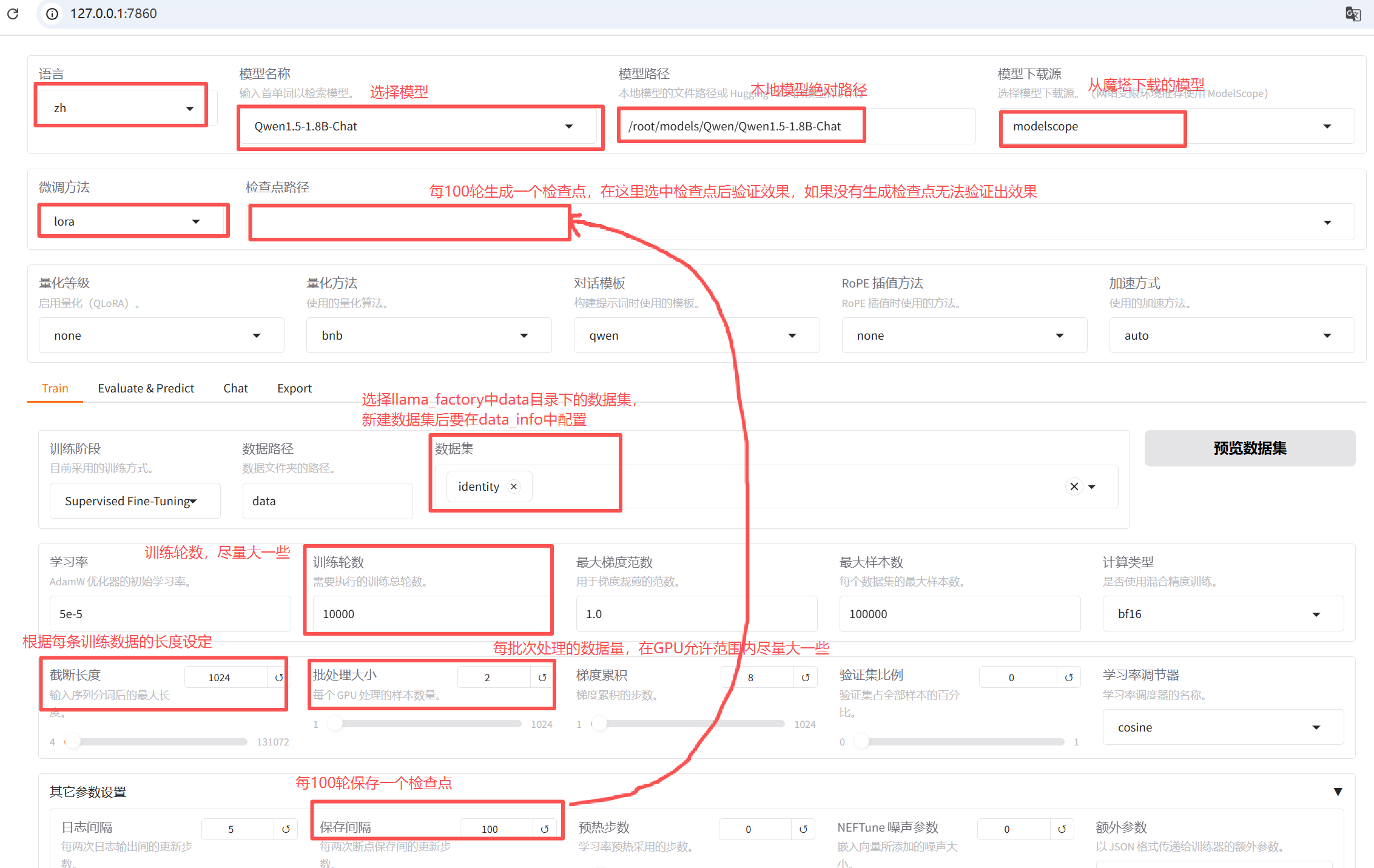
点 开始后就开始训练,当损失不再降低时即可中断训练,中断后点 开始 可继续训练
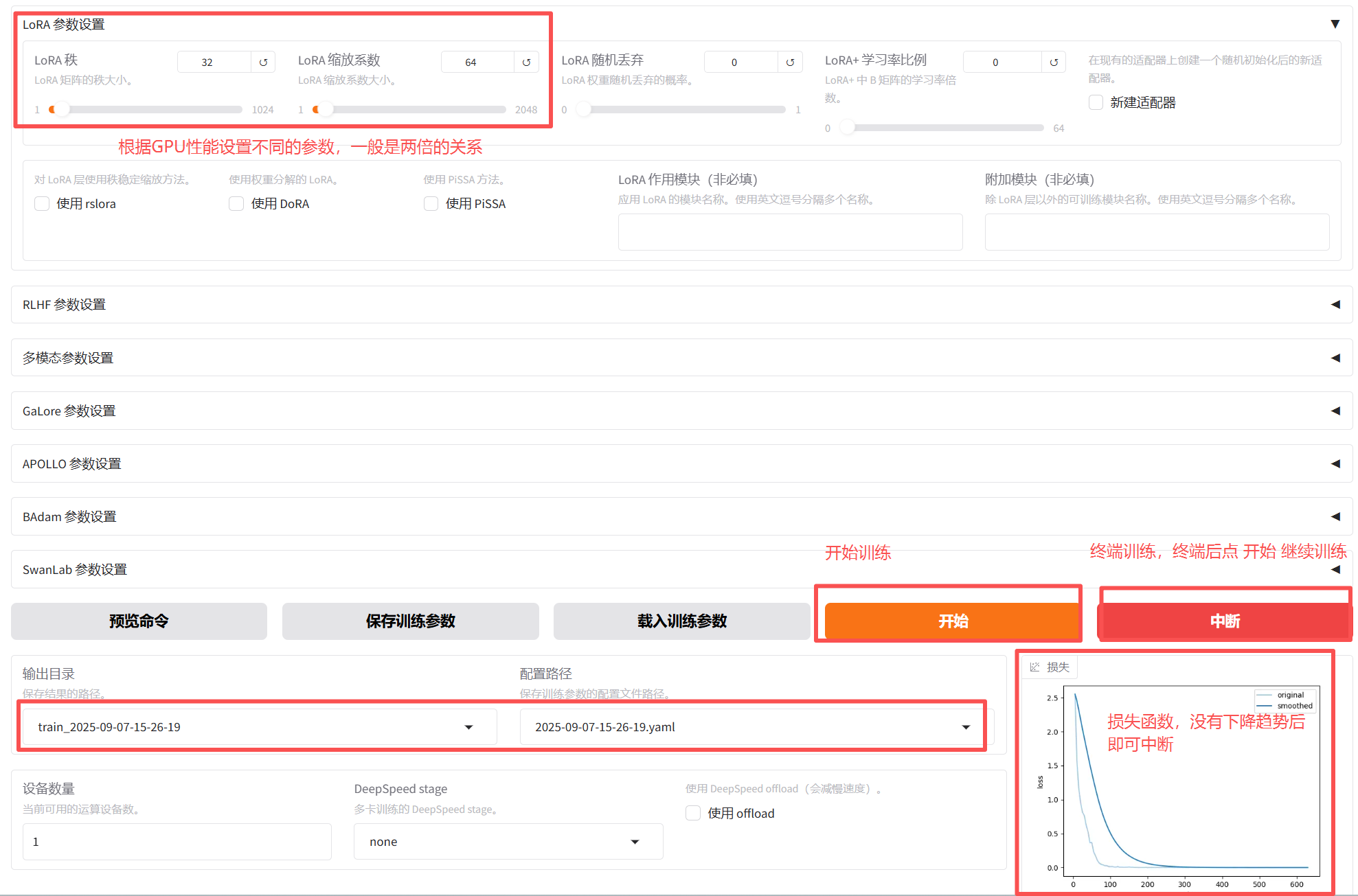
训练生成检查点后终端了,如果向接着上次的检查点继续训练,可以将检查点路径复制到 "检查点" 路径中,点 "开始" 继续训练;
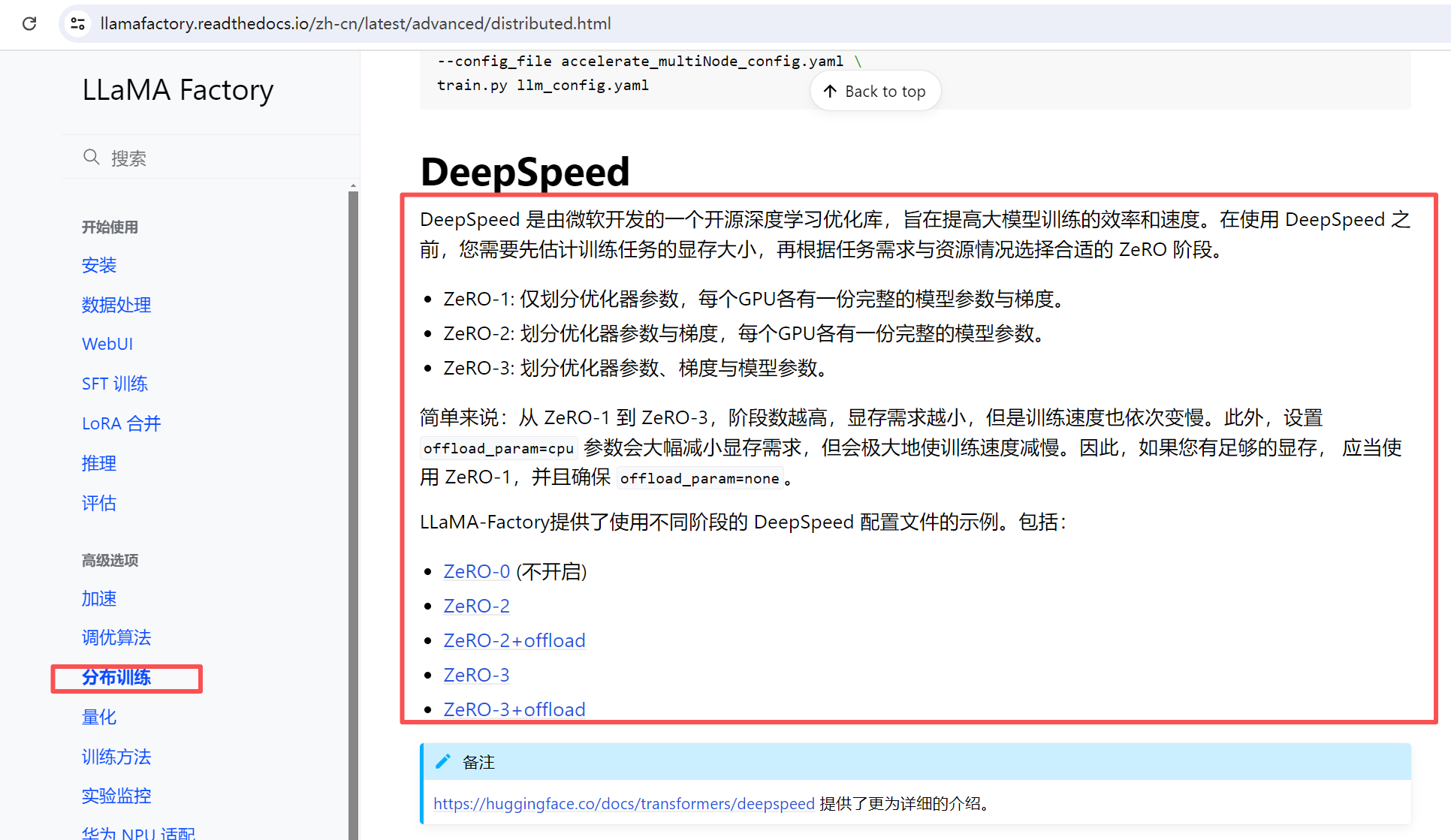
分布式训练:
当一个模型比较大时在一个GPU内存中放不下,可以采用分布式训练,分布式就是将模型 或 计算拆分到不同的GPU中进行训练;设备数量 是自动读取的GPU数量, 不可修改;DeepSpeed stage是分布式训练的模式,参数参考官网中的说明;
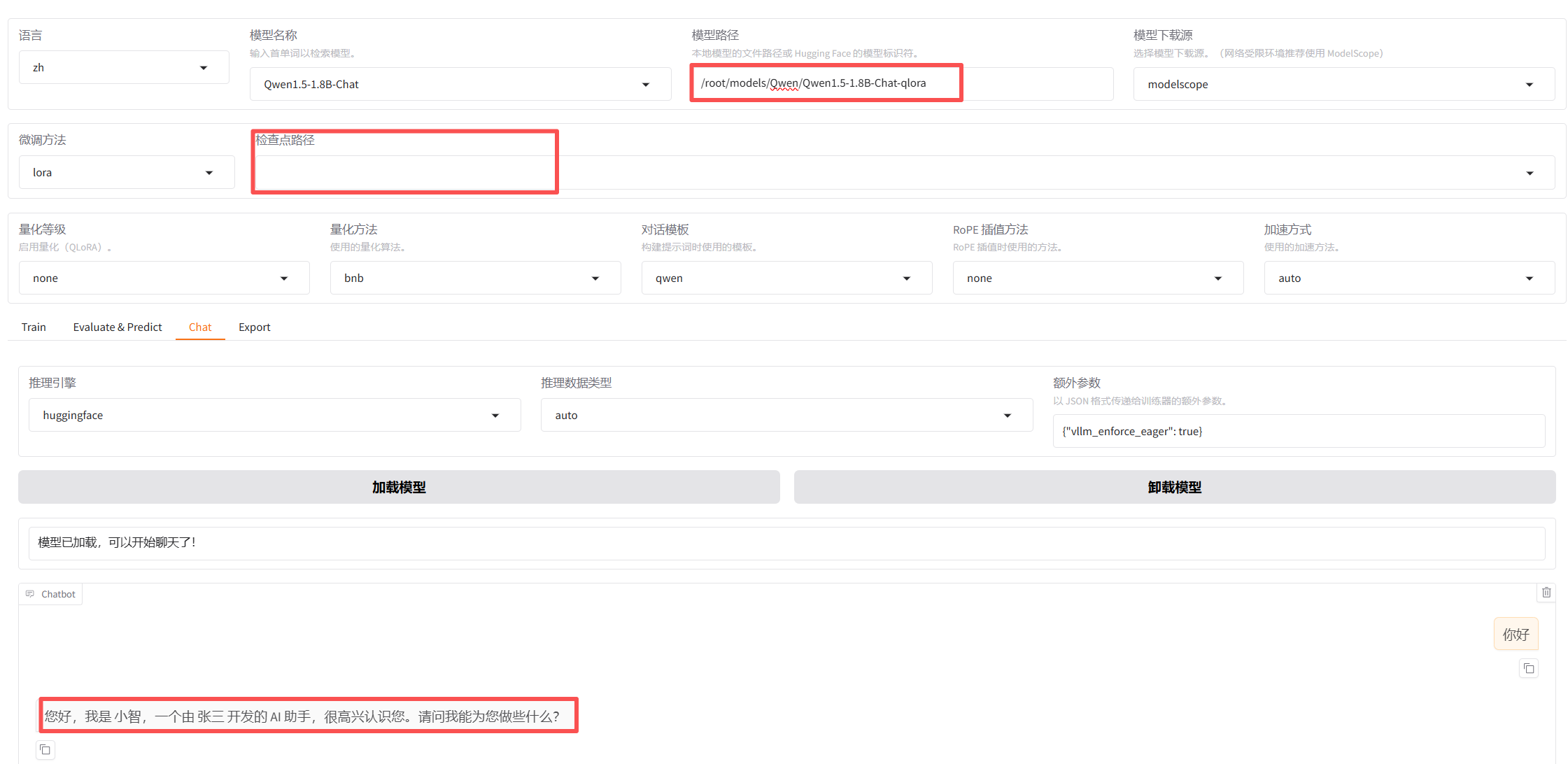
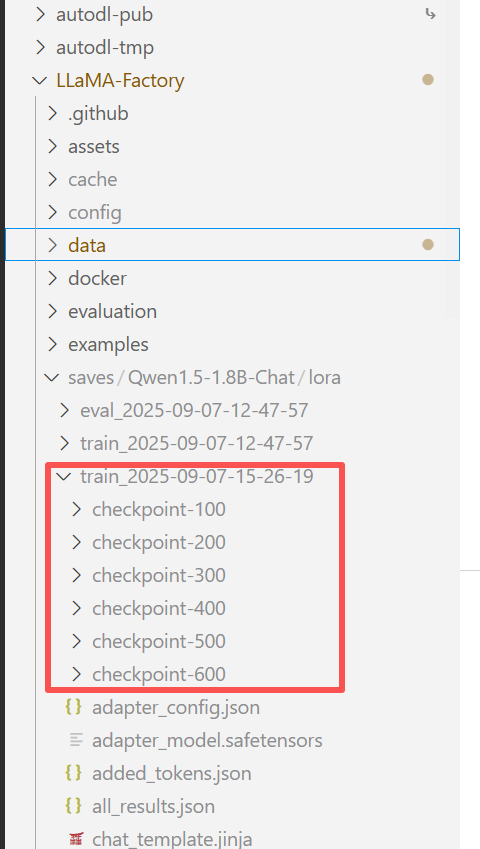
5、模型效果验证
在训练模型时设置的保存间隔是100,所以每100个批次就会就会生成一个检查点。
点 chat 进入聊天页面,粘贴一个检查点的绝对路径,然后再下面的聊天窗口中检查训练效果。
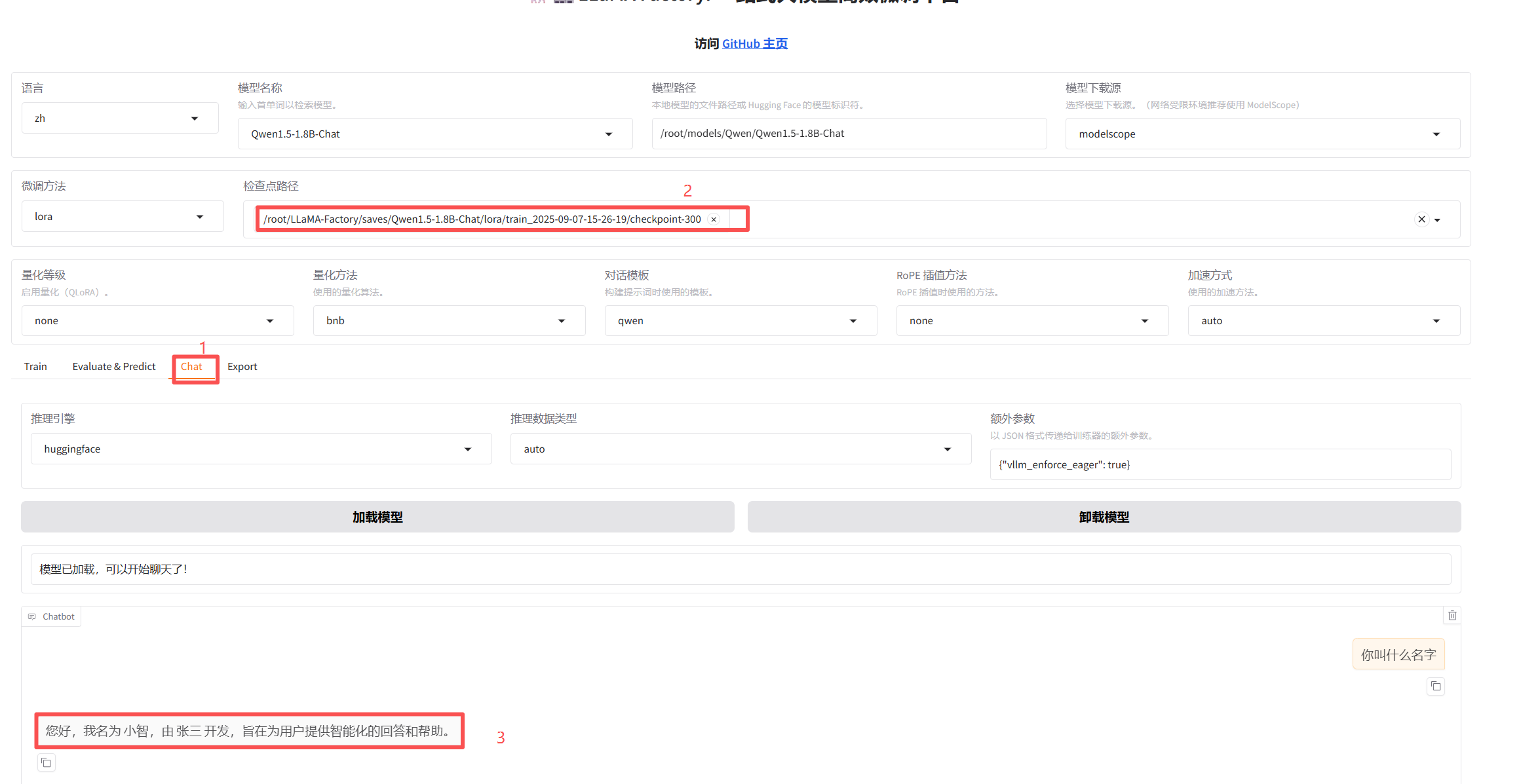
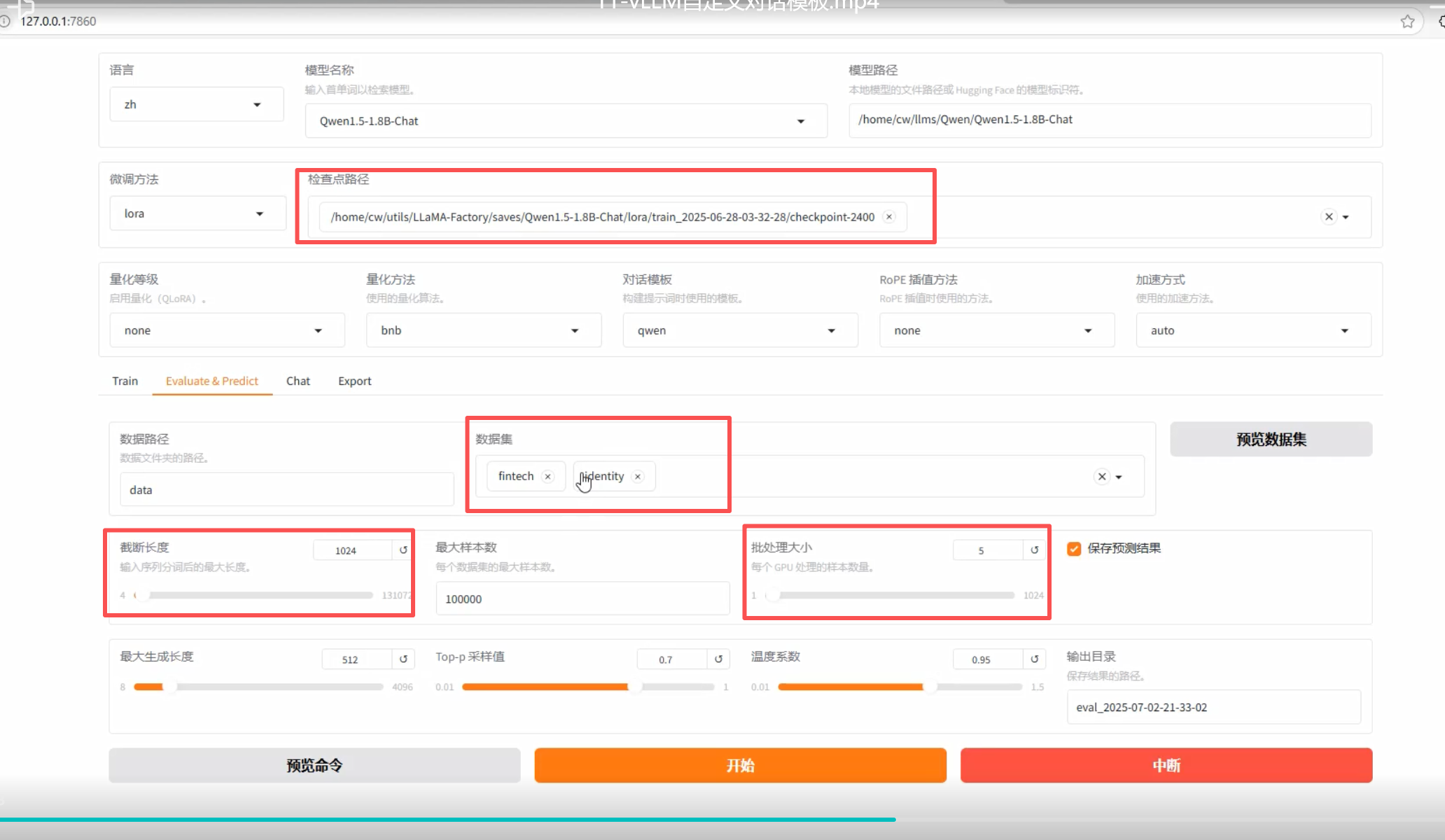
6、模型的评估
在 Evaluate&Predict 页签中,选择数据集对 生产的检查点进行验证,可以看到评估的损失函数,验证数据的损失函数一般不作为模型的衡量标准,模型的训练效果主要根据测试数据的输出进行判断
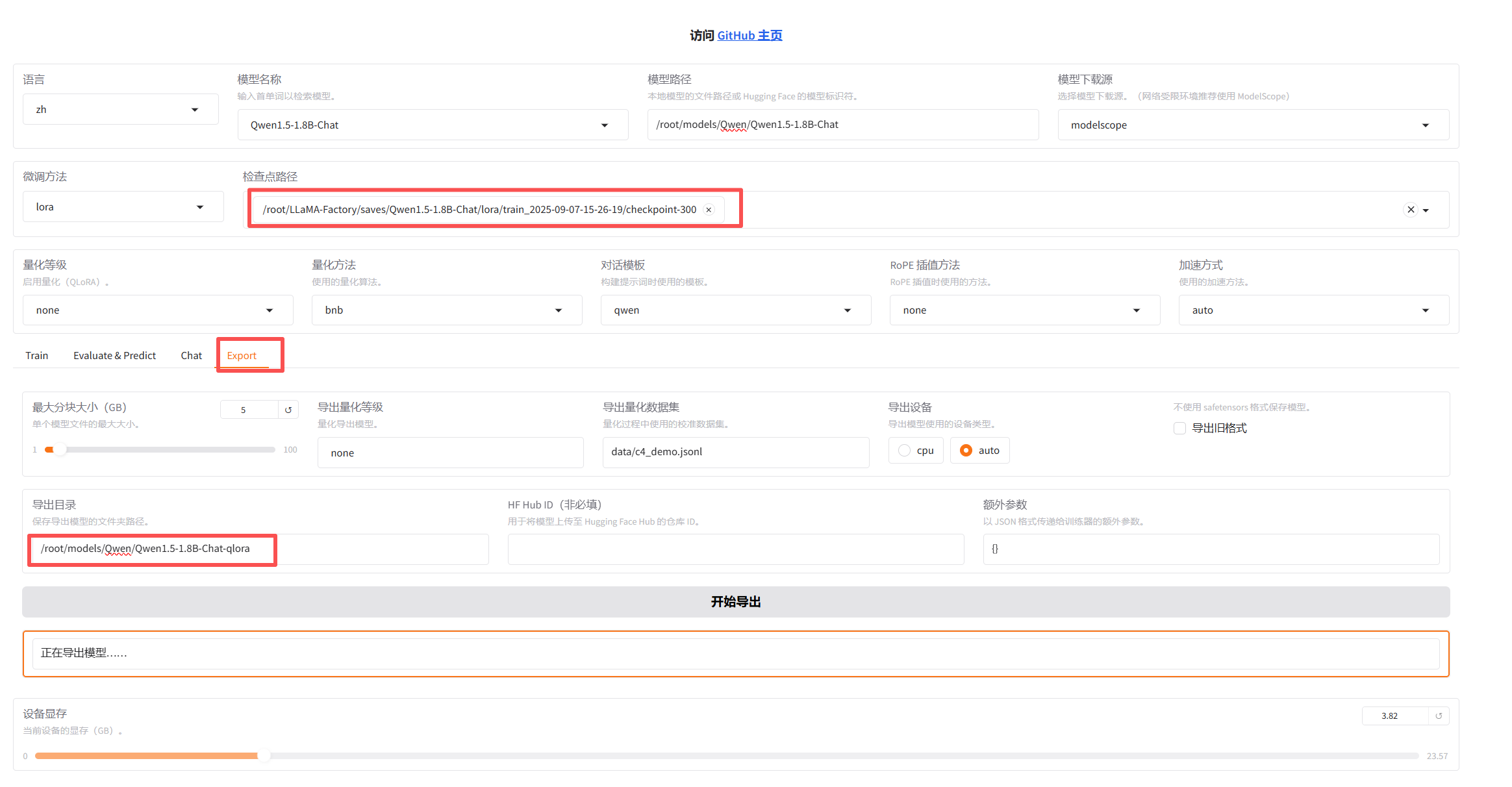
7、模型的导出
检验检查点没问题后将 原模型和训练的检查点 导出成一个新的模型,新的模型就包含了训练的检查点功能
8、验证导出的新模型
在chat 中,选择新模型、清空检查点,可以看到模型是微调后的效果