梯度(Gradient)是数学中的一个重要概念,在深度学习中有特殊的意义。
数学定义
梯度是一个向量,表示多元函数在某点处变化最快的方向和变化率:
对于单变量函数:梯度就是导数
对于多变量函数:梯度是由各个偏导数组成的向量
可以把梯度想象成坡度(就像山坡的陡峭程度),方向指引(告诉你朝哪个方向走能最快上升或下降)和敏感度(表示输入的小变化会引起输出多大的变化)
在机器学习中,我们通常使用梯度来更新模型参数,使损失函数最小化。
PyTorch中的含义
在深度学习框架中,梯度有以下特点:
- 表示变化率:
- 梯度指示了损失函数相对于模型参数的变化方向和大小
- 用于指导参数更新(如梯度下降算法)
- 自动微分:
- PyTorch通过自动微分(autograd)系统自动计算梯度
- 当 requires_grad=True 时,张量会跟踪所有操作以便计算梯度
代码案例
import torch
import numpy as np
# Create a tensor which requires gradient
tensor_requires_grad = torch.rand(2, 3, requires_grad=True)
print("创建一个张量,该张量需要梯度:")
print(tensor_requires_grad)
tensor_grad_result = tensor_requires_grad * 2
print("\n张量乘以2:")
print(tensor_grad_result)
tensor_requires_grad.backward(torch.ones_like(tensor_requires_grad))
print("\n计算叶子张量的梯度:")
print(tensor_requires_grad.grad)
print("\n计算非叶子张量的梯度:")
tensor_grad_result.retain_grad()
tensor_grad_result.backward(torch.ones_like(tensor_grad_result))
print(tensor_grad_result.grad)import torch
import numpy as np
# Create a tensor which requires gradient
tensor_requires_grad = torch.rand(2, 3, requires_grad=True)
print("创建一个张量,该张量需要梯度:")
print(tensor_requires_grad)
tensor_grad_result = tensor_requires_grad * 2
print("\n张量乘以2:")
print(tensor_grad_result)
tensor_requires_grad.backward(torch.ones_like(tensor_requires_grad))
print("\n计算叶子张量的梯度:")
print(tensor_requires_grad.grad)
print("\n计算非叶子张量的梯度:")
tensor_grad_result.retain_grad()
tensor_grad_result.backward(torch.ones_like(tensor_grad_result))
print(tensor_grad_result.grad)执行结果
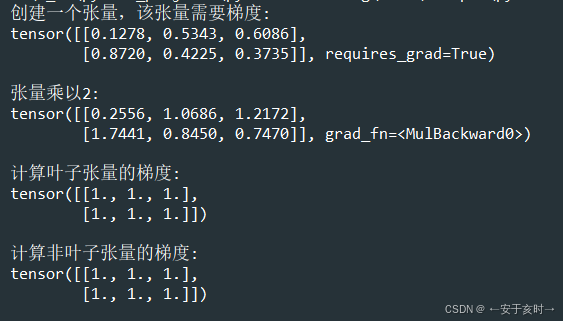
要点解析
叶子张量(leaf tensor):直接创建的张量,如 tensor_requires_grad
非叶子张量(non-leaf tensor):通过计算操作产生的张量,如 tensor_grad_result = tensor_requires_grad * 2
梯度计算机制, PyTorch默认只保存叶子张量的梯度,非叶子张量的梯度在反向传播后不会自动保存,以节省内存。
tensor_grad_result.retain_grad() 允许非叶子张量保存其梯度值
PyTorch默认只保存叶子张量(leaf tensor)的梯度,非叶子张量的梯度在反向传播后会被清除以节省内存。调用retain_grad()方法后,该张量会在反向传播后保留其梯度值,可以通过 .grad 属性访问。
tensor_grad_result.backward(torch.ones_like(tensor_grad_result)) ,对张量执行反向传播计算梯度。torch.ones_like(tensor_grad_result) 创建了一个与 tensor_grad_result 形状相同的全1张量,作为梯度权重。tensor_grad_result = tensor_requires_grad * 2,反向传播会计算损失相对于 tensor_grad_result 的梯度,由于乘以了2,梯度也会相应变化。
这里的梯度还不是很理解,留着后面再深入研究。大家要是有更好的理解,还请不吝赐教。