目录
[第1步:准备Hadoop Windows安装包](#第1步:准备Hadoop Windows安装包)
[四、 实践操作:使用客户端](#四、 实践操作:使用客户端)
[1. 操作HDFS](#1. 操作HDFS)
[2. 提交MapReduce作业](#2. 提交MapReduce作业)
第1步:准备Hadoop Windows安装包
-
从老师提供的地址或上述GitHub仓库下载与你集群版本一致的Hadoop Windows包(例如:
hadoop-3.3.0)。 -
将其解压到一个没有中文和空格 的目录下,例如:
D:\BigData\hadoop-3.3.0。这个目录就是你的HADOOP_HOME。
第2步:获取并放置集群配置文件
-
从老师那里获取集群的四个核心配置文件:
-
core-site.xml(包含NameNode地址) -
hdfs-site.xml(包含HDFS副本数等配置) -
yarn-site.xml(包含ResourceManager地址) -
mapred-site.xml(包含MapReduce框架配置)
-
-
用这些文件覆盖 你本地
HADOOP_HOME\etc\hadoop\目录下的同名文件。- 例如,覆盖
D:\BigData\hadoop-3.3.0\etc\hadoop\下的文件。
为什么? 这样你的客户端才知道NameNode、ResourceManager等关键服务在哪里,才能正确连接到集群。
- 例如,覆盖
第3步:配置Windows环境变量
-
右键点击"此电脑" -> "属性" -> "高级系统设置" -> "环境变量"。
-
在"系统变量"区域,新建一个变量:
-
变量名(N) :
HADOOP_HOME -
变量值(V) :
D:\BigData\hadoop-3.3.0(你的Hadoop解压路径)
-
-
找到并编辑系统变量 中的
Path变量:-
点击"新建",添加一条新的记录:
%HADOOP_HOME%\bin -
为了确保优先使用,最好将其上移到顶部。
-
第4步:解决Windows本地依赖问题
Hadoop原生库主要在Linux下工作,在Windows上运行需要一些额外文件(winutils.exe和hadoop.dll)。
-
从上述GitHub仓库下载对应版本的
bin文件夹(里面包含winutils.exe等文件)。 -
将下载的
bin文件夹中的内容,全部复制 到你本地的%HADOOP_HOME%\bin目录下,覆盖原有文件。 -
将
hadoop.dll文件复制到C:\Windows\System32目录下。
这一步至关重要! 缺少这些文件会在执行命令时出现各种
java.lang.UnsatisfiedLinkError错误。
第5步:验证配置
-
重新打开一个新的命令提示符(CMD)或PowerShell,使环境变量生效。
-
输入以下命令测试环境变量是否配置正确:
bash
hadoop version如果配置成功,你会看到Hadoop的版本信息输出。
四、 实践操作:使用客户端
配置完成后,你的电脑就成为了一个Hadoop客户端,可以远程操作集群。
1. 操作HDFS
-
查看HDFS根目录下的文件:
bash
hadoop fs -ls / -
从本地磁盘上传文件到HDFS:
bash
# 命令格式:hadoop fs -put <本地路径> <HDFS路径> hadoop fs -put D:\test.txt /input/ echo "Hello Hadoop" > test.txt hadoop fs -put test.txt /input/ -
从HDFS下载文件到本地:
bash
# 命令格式:hadoop fs -get <HDFS路径> <本地路径> hadoop fs -get /output/part-r-00000 D:\result.txt -
查看HDFS上的文件内容:
bash
hadoop fs -cat /output/part-r-00000
2. 提交MapReduce作业
假设我们有一个经典的WordCount计算词频的Jar包。
-
提交作业到YARN集群:
bash
# 命令格式: hadoop jar <jar包路径> <主类名> <输入路径> <输出路径> # 示例: hadoop jar D:\hadoop-examples.jar wordcount /input/test.txt /output/wc_result -
查看作业运行状态:
-
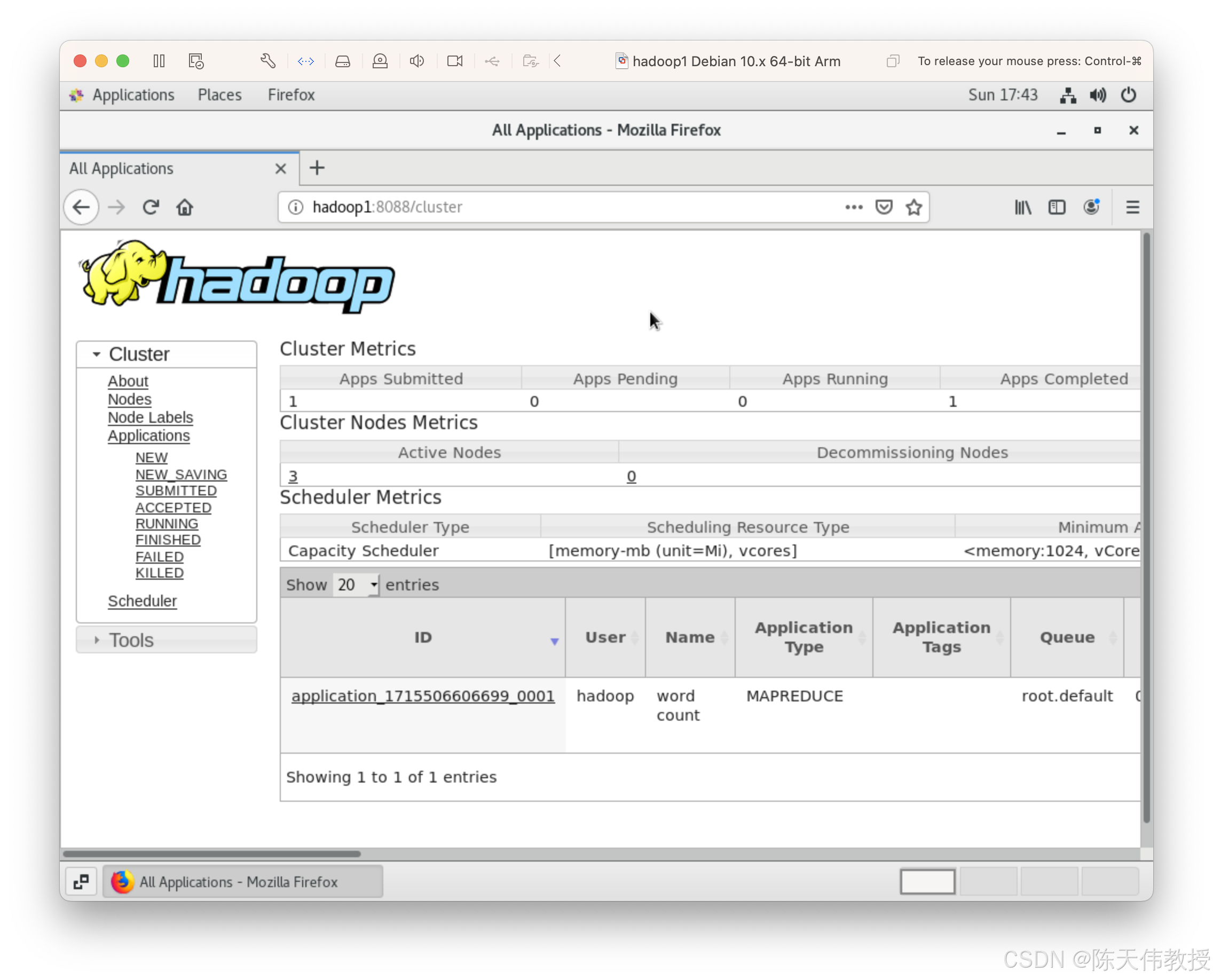
你可以通过YARN的Web UI(通常为
http://<resourcemanager-host>:8088)查看作业执行情况。 -
也可以在命令行使用
yarn命令查看:bash
yarn application -list
-