DataWorks是阿里云重要的PaaS(Platform as a Service)平台产品,为用户提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、基于Flink的实时计算、机器学习PAI、图计算服务Graph Compute和交互式分析服务等,并且支持用户自定义接入计算和存储服务。DataWorks可以为用户提供全链路智能大数据及AI开发和治理服务。
用户可以使用DataWorks,对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。
| 视频讲解如下 |
|---|
| 【赵渝强老师】阿里云大数据集成开发平台DataWorks |
DataWorks提供以下九个核心功能模块。
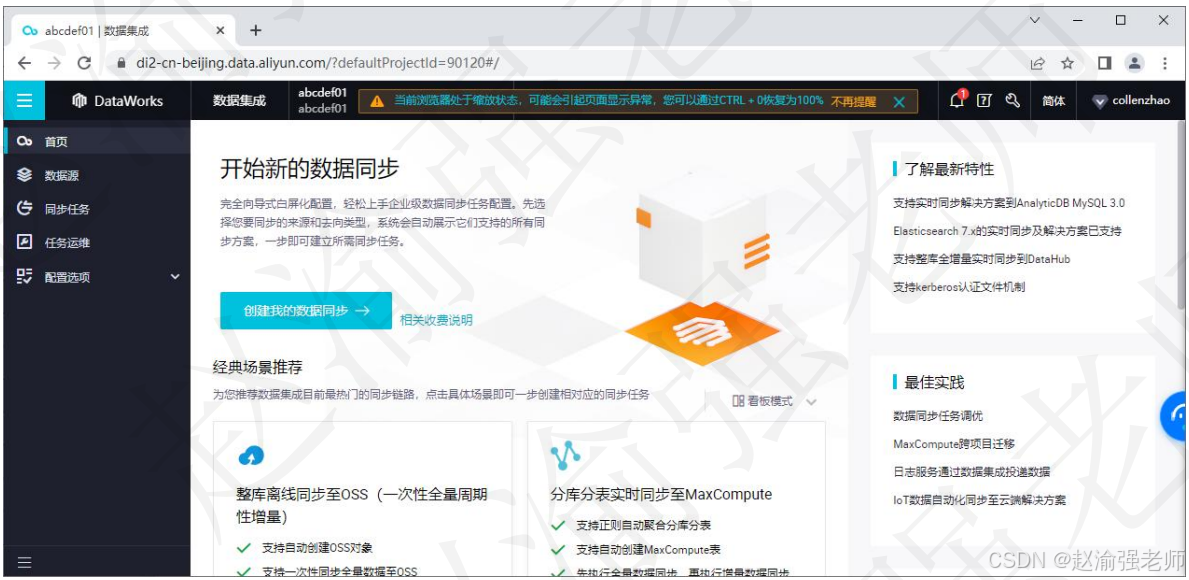
一、 数据集成
DataWorks的数据集成功能模块是稳定高效、弹性伸缩的数据同步平台,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。DataWorks数据集成支持离线同步、实时同步,以及离线和实时一体化的全增量同步。其中:
- 离线同步场景下,支持设置离线同步任务的调度周期。
- 支持数据库、数仓、NoSQL数据库、文件存储、消息队列等近50多种不同异构数据源之间的数据同步。
- 支持在各类复杂网络环境下,连通数据源的网络解决方案,在各种网络环境下均可使用DataWorks数据集成实现网络连通。
- 支持安全控制与运维监控,保障数据同步的安全、可控。
下图展示了DataWorks的数据集成页面。
二、 数据加工
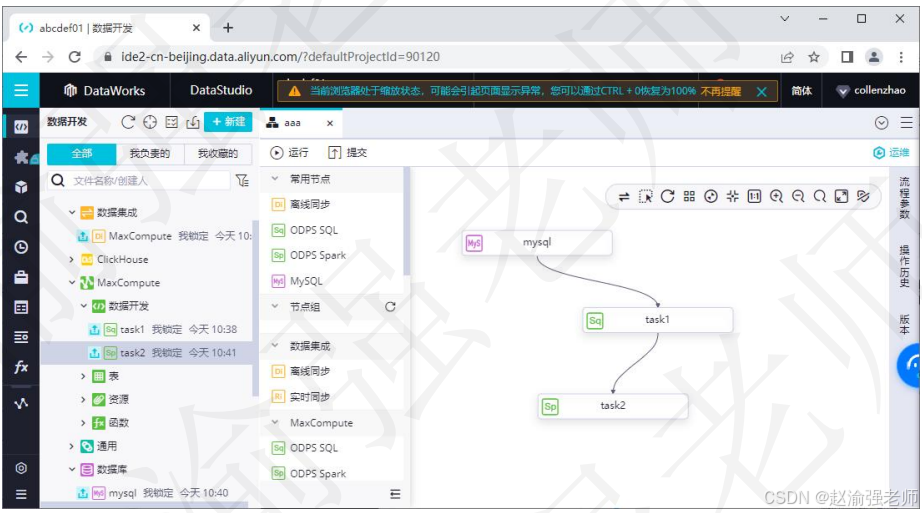
DataWorks的数据开发是数据加工的开发平台,运维中心是数据加工的管理平台。基于这两个功能模块,用户可以在DataWorks上规范、高效地构建和运维数据开发工作流。
DataWorks的数据开发平台可以使用工具DataStudio进行支持。DataStudio的数据开发工具提供的功能如下:
- DataStudio支持MaxCompute、EMR、CDH、Hologres、AnalyticDB、Clickhouse等多种计算引擎,支持在统一的平台上进行各类引擎任务的开发、测试、发布和运维等操作。
- DataStudio支持智能编辑器、可视化依赖编排,调度能力经过阿里集团内调度任务、复杂业务依赖的反复验证。
- DataStudio提供隔离的开发和生产环境,结合版本管理、代码评审、冒烟测试、发布管控、操作审计等配套功能,帮助企业规范地完成数据开发。
下图展示了DataStudio数据开发工具的主页面。
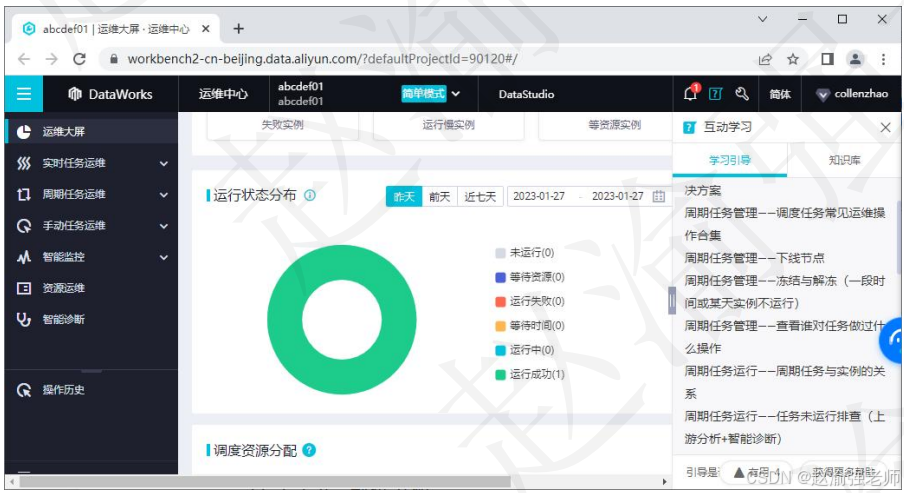
DataWorks运维中心支持数据时效性保障、任务诊断、影响分析、自动运维、移动运维等功能。下图展示了DataWorks运维中心的主页面。
三、 数据建模
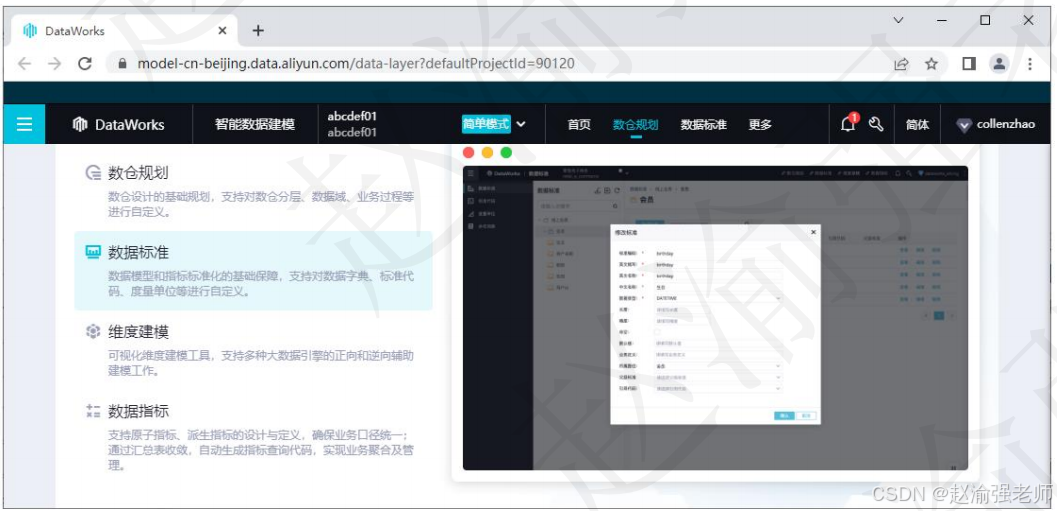
数据建模是阿里云DataWorks自主研发的智能数据建模产品,沉淀了阿里巴巴十多年来数仓建模方法论的最佳实践,包含数仓规划、数据标准、维度建模及数据指标四大模块,帮助企业在搭建数据中台、数据集市建设过程中提升建模及逆向建模的能力,并通过数据建模快速构建企业数据资产。
DataWorks数据建模可助力企业构建自身建模能力,挖掘企业的数据资产价值。它支持以下的场景:
- 海量数据的标准化管理:企业业务越庞大数据结构就越复杂,企业数据量会随着企业业务的快速发展而迅速增长,如何结构化有序地管理和存储数据是每个企业都将面临的一个挑战。
- 业务数据互联互通,打破信息壁垒:公司内部各业务、各部门之间数据独立自主形成了数据孤岛,导致决策层无法清晰、快速地了解公司各类数据情况。如何打破部门或业务领域之间的信息孤岛是企业数据管理的一大难题。
- 数据标准整合,统一灵活对接:同一数据不同描述,企业数据管理难、内容重复、结果不准确。如何制定统一的数据标准又不打破原有的系统架构,实现灵活对接上下游业务,是标准化管理的核心重点之一。
- 数据价值最大化,企业利润最大化:在最大程度上用好企业各类数据,使企业数据价值最大化,为企业提供更高效的数据服务。
下图展示了DataWorks数据建模的主页面。

四、 数据分析
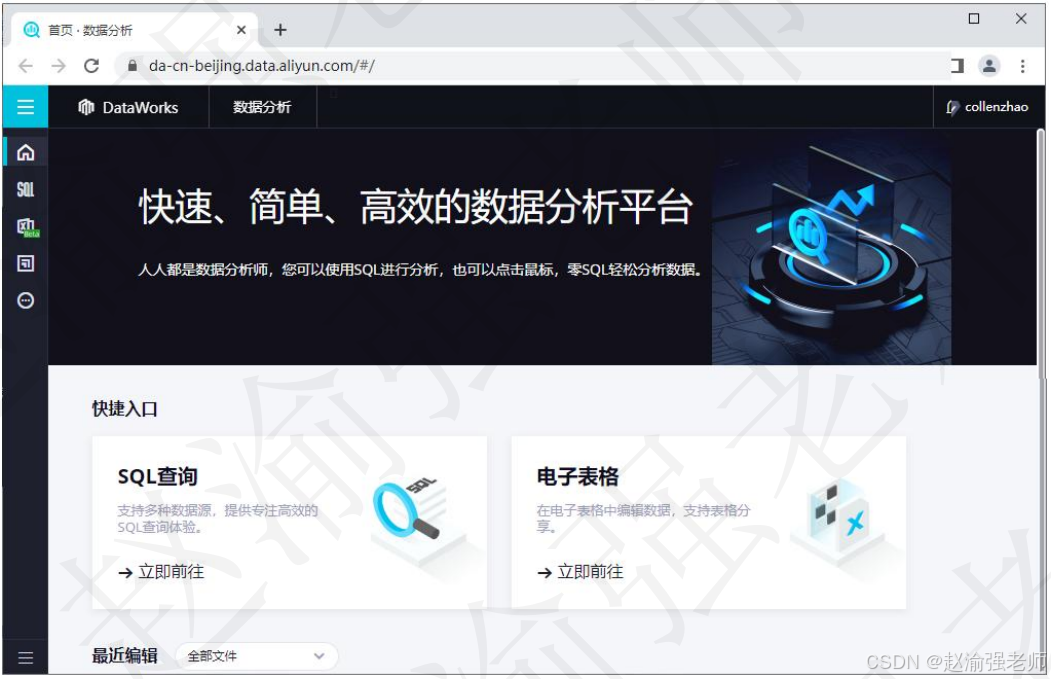
数据分析基于"人人都是数据分析师"的产品目标,旨在为更多非专业数据开发人员,如数据分析、产品、运营等工作人员提供更加简洁高效的取数、用数工具,提升大家日常取数分析效率。数据分析支持基于个人视角的数据上传、公共数据集、表搜索与收藏、在线SQL取数、SQL文件共享、SQL查询结果下载及用电子表格进行大屏幕数据查看等产品功能。
下图展示了DataWorks数据分析的主页面。
五、 数据质量
DataWorks的全流程数据质量监控功能为用户提供多种预设表级别、字段级别和自定义的监控模板。数据质量可以帮助用户第一时间感知到源端数据的变更与ETL(Extract Transformation Load)中产生的脏数据,自动拦截问题任务,有效阻断脏数据向下游蔓延。
数据质量以数据集(DataSet)为监控对象,支持监控MaxCompute数据表和DataHub实时数据流。当离线MaxCompute数据发生变化时,数据质量会对数据进行校验,并阻塞生产链路,以避免问题数据污染扩散。同时,数据质量提供历史校验结果的管理,以便用户对数据质量进行分析和定级。
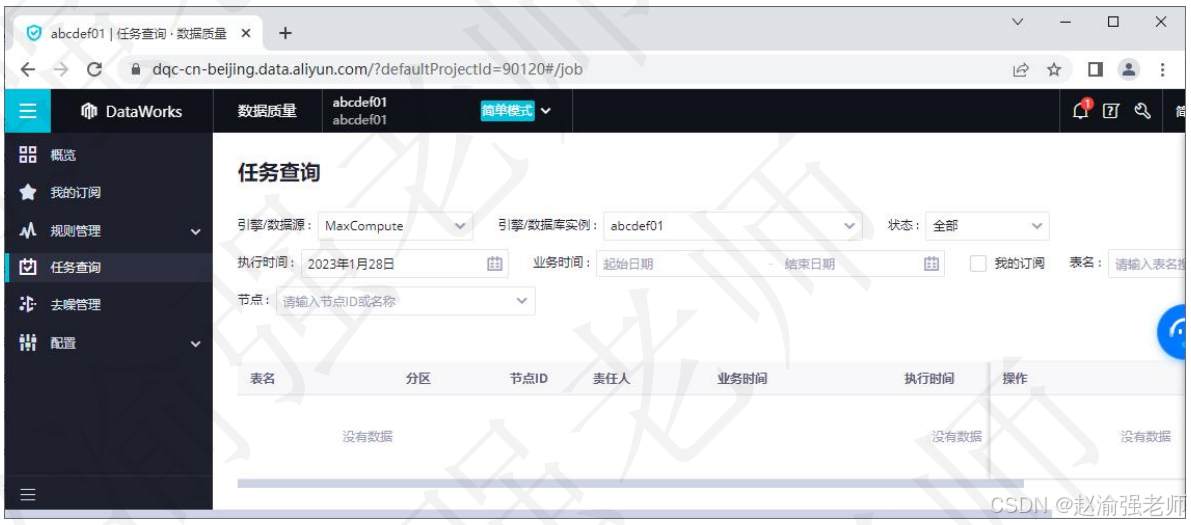
下图展示了DataWorks数据质量管理中的任务查询页面。
六、 数据地图
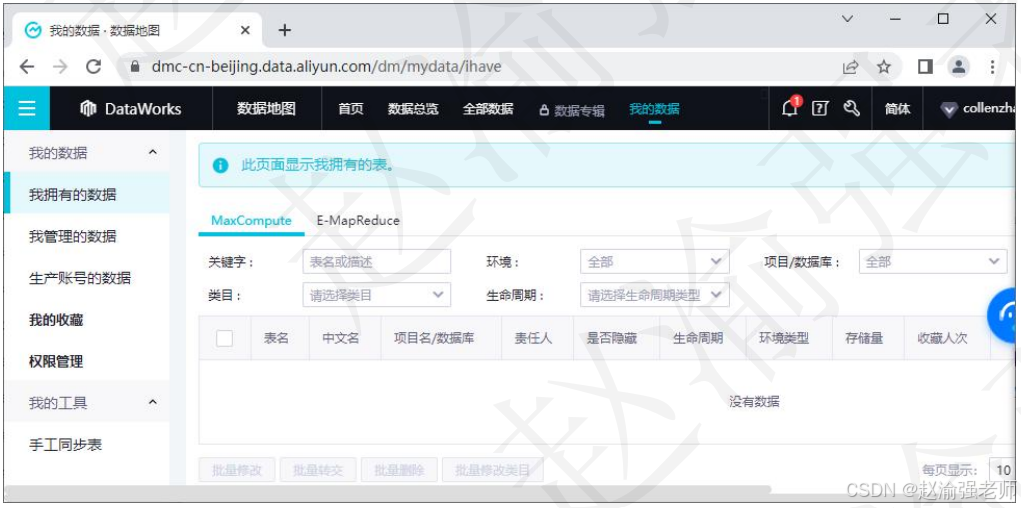
DataWorks的数据地图功能可以实现对数据的统一管理和血缘的跟踪。数据地图以数据搜索为基础,提供表使用说明、数据类目、数据血缘、字段血缘等工具,帮助数据表的使用者和拥有者更好地管理数据、协作开发。下图展示DataWorks的数据地图。
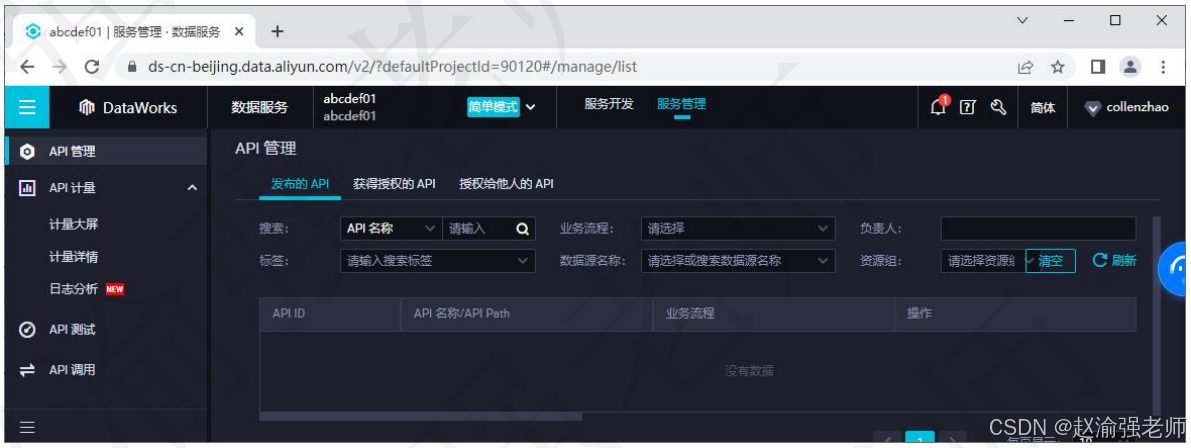
七、 数据服务
DataWorks的数据服务功能模块是灵活轻量、安全稳定的数据API构建平台,旨在为企业提供全面的数据共享能力,帮助用户从发布审批、授权管控、调用计量、资源隔离等方面实现数据价值输出及共享开放。下图展示DataWorks的数据服务。
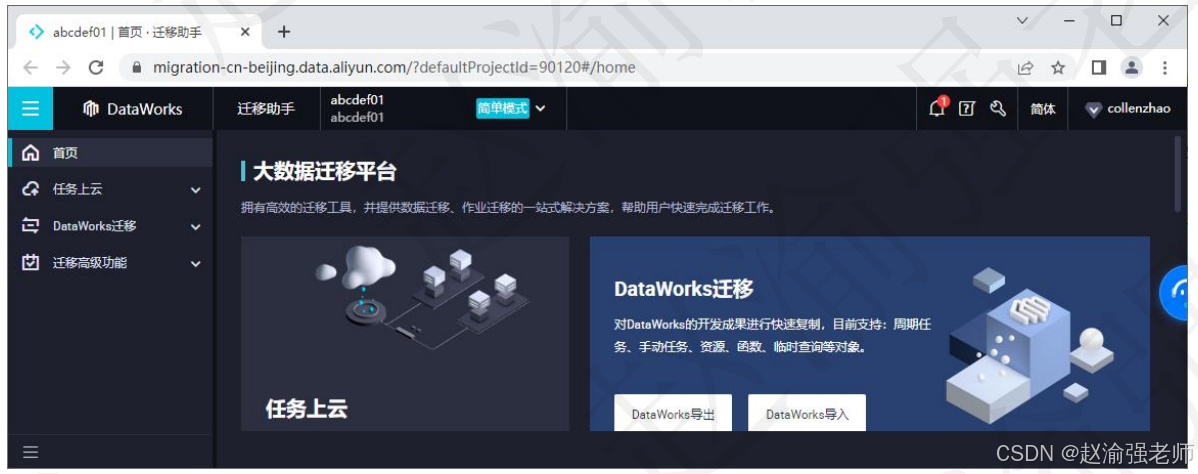
八、 数据迁移
DataWorks的数据迁移通过使用迁移助手支持将开源调度引擎的作业迁移至DataWorks,支持作业跨云、跨Region、跨账号迁移,实现DataWorks作业快速克隆部署,同时DataWorks团队联合大数据专家服务团队,上线迁云服务,帮助用户快速实现数据与任务的上云。下图展示DataWorks的数据迁移助手。
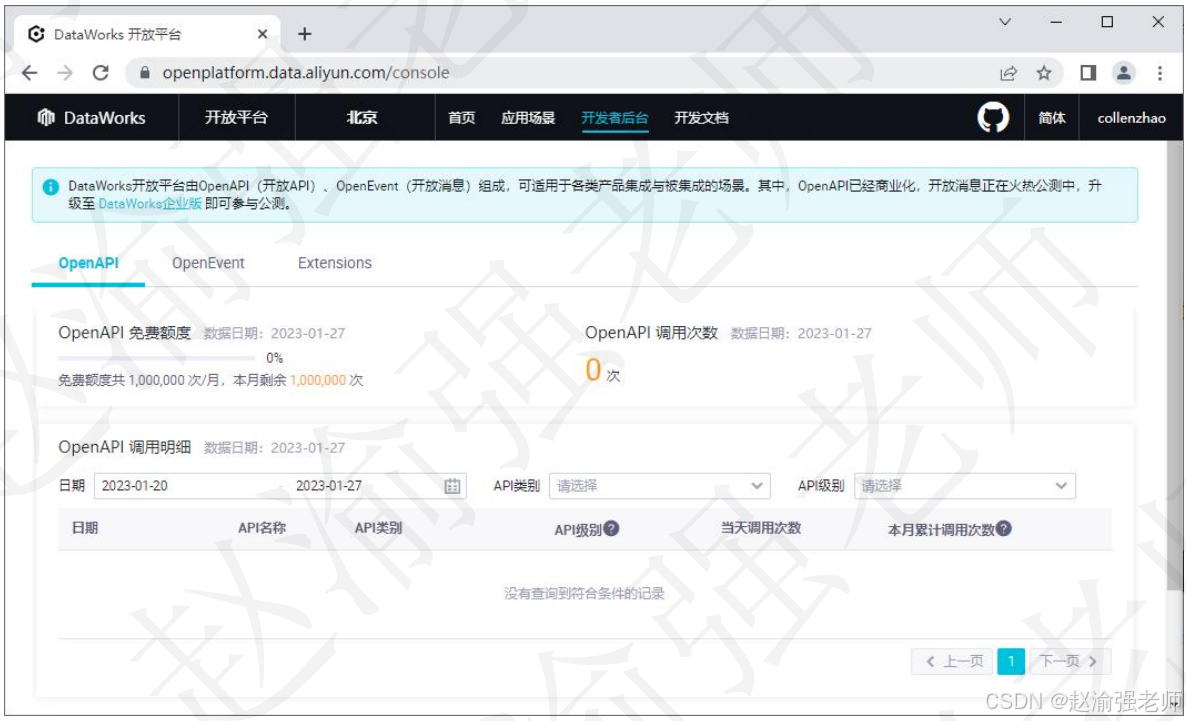
九、 开放平台
DataWorks开放平台是DataWorks对外提供数据和能力的开放通道。DataWorks开放平台提供开放API(OpenAPI)、开放事件(OpenEvent)、扩展程序(Extensions)的能力,可以帮助用户快速实现各类应用系统对接DataWorks、方便快捷的进行数据流程管控、数据治理和运维,及时响应应用系统对接DataWorks的业务状态变化。
下图展示DataWorks的开放平台。