本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6\&share_source=copy_web\&vd_source=404581381724503685cb98601d6706fb
上节课学习time模块中datetime类的使用,datetime模块中datetime类的使用,timedelta类的使用,第三方模块的安装与卸载,requests模块的使用,openpyxl模块的使用,pdfplumber模块的使用,本节课学习pandas模块与matplotlib模块的使用,PyEcharts模块的使用,POL模块图像的处理,jieba模块实现中文分词,PyInstaller模块打包源文件。
1.pandas模块与matplotlib模块的使用


使用的表格如上,命名为:
python
import pandas as pd
import matplotlib.pyplot as plt
#读取Excel文件
df=pd.read_excel('JD手机销售数据.xlsx')
#print(df)
#解决中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
#下面是绘图需要设置画布的大小
plt.figure(figsize=(10,6)) #以元组的形式
labels=df['商品名称'] #坐标轴名称(标签)
y=df['北京出库销量']
#print(labels)
#print(y)
#绘制饼图,startangle这个角度可以赋值也可以不赋值
#startangle的作用就是让饼图看起来更好看
plt.pie(y,labels=labels,autopct='%1.1f%%',startangle=90)
plt.axis('equal')
#设置x,y轴制度
plt.axis('equal')
plt.title('2020年1月北京各手机品牌出库量占比图')
#显示出来
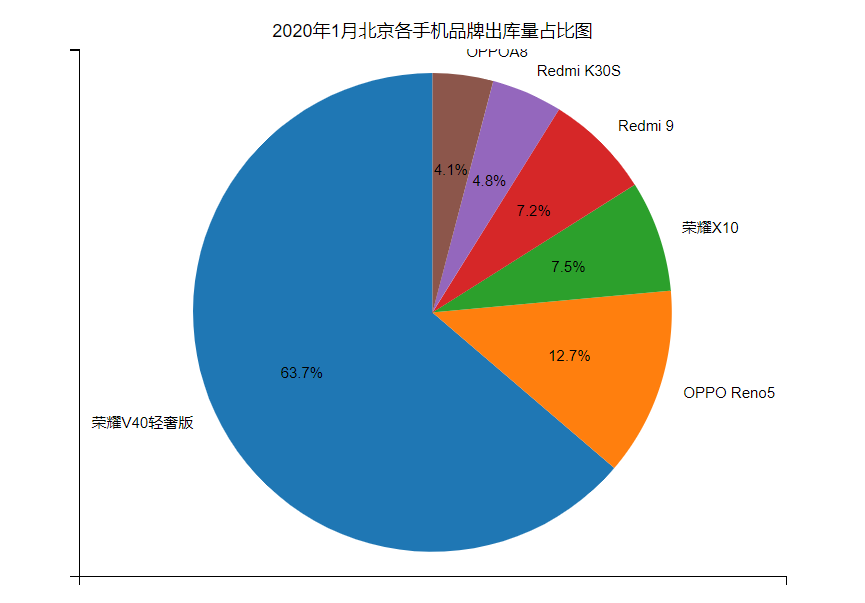
plt.show()其中对于下面这行代码:
plt.pie(y,labels=labels,autopct='%1.1f%%',startangle=90)运行结果是:(这个保证棕色扇形的线是垂直的好看点)
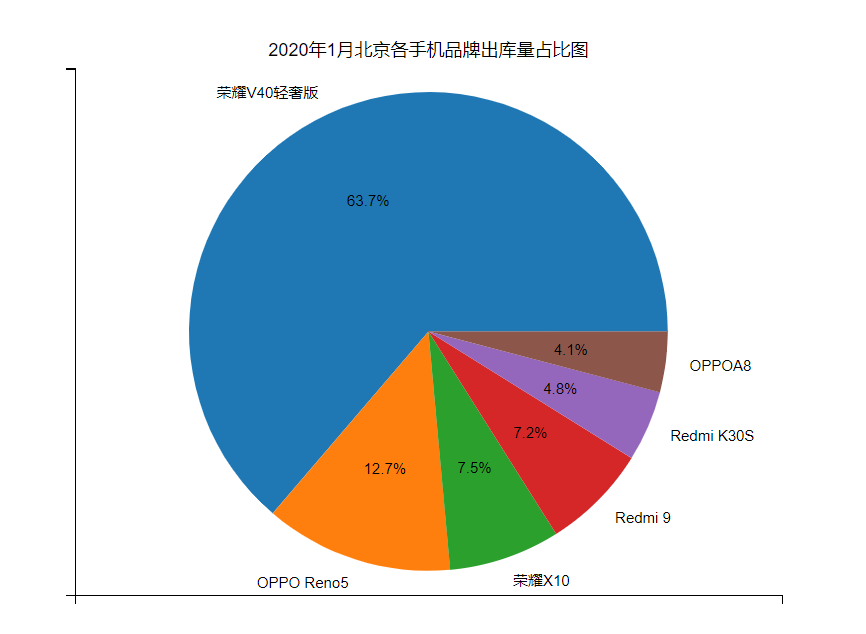
如果换成
plt.pie(y,labels=labels,autopct='%1.1f%%')效果就变成了(感觉不太好看)
2.PyEcharts模块的使用

该模块可以提供30多种图像,例如柱形渐变图,输入网址:
可以看见中文说明,打开基础图表,在饼图pie下找到demo,点开:


点开base那个,可以根据官方教程修改自己的代码。下面这些就是我们在使用这个库的时候导入得到模块名,直接复制上就行。

代码分析:
python
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
# c = (
# Pie()
# .add("", [list(z) for z in zip(Faker.choose(), Faker.values())])
# .set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例"))
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_base.html")
# )
#分析上面的代码内容,对于Pie()意思是绘制饼图,第二行就是add(添加)数据,即将数据打包
# [list(z) for z in zip(Faker.choose(), Faker.values())]是一个列表生成式,zip表示打包,打包后的结果就是z。我们修改这一行来输出不同的内容。
#下面我们看一下这个数组里面的内容是什么
print([list(z) for z in zip(Faker.choose(), Faker.values())])
运行结果:
[['草莓', 24], ['芒果', 26], ['葡萄', 135], ['雪梨', 96], ['西瓜', 108], ['柠檬', 51], ['车厘子', 127]]
进程已结束,退出代码为 0修改数组内容如下:
python
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
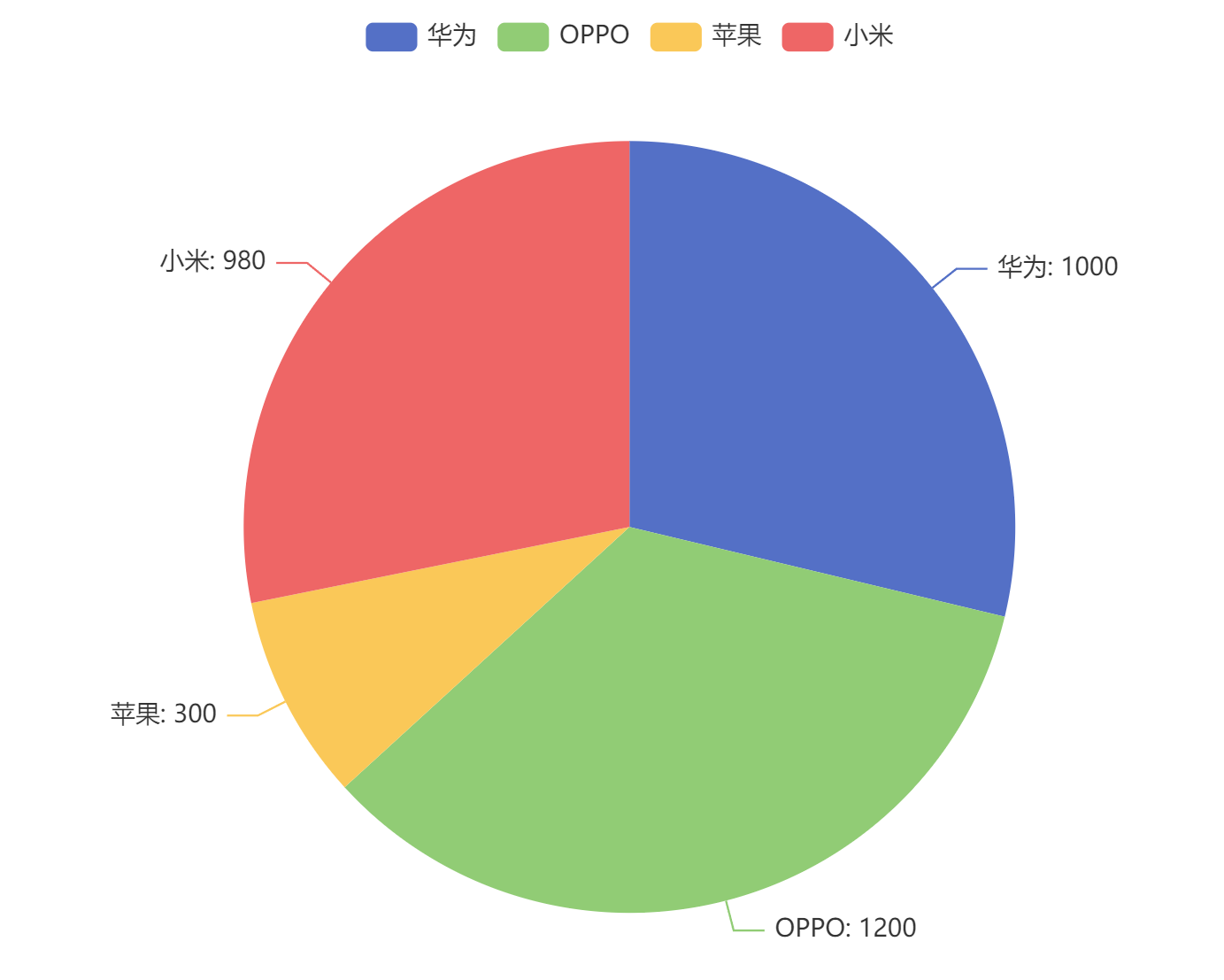
#准备数据
lst=[['华为',1000],['OPPO',1200],['苹果',300],['小米',980]]
c = (
Pie()
#.add("", [list(z) for z in zip(Faker.choose(), Faker.values())])
.add('',lst)
.set_global_opts(title_opts=opts.TitleOpts(title="2028年北京手机出库占比情况"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("phone.html")
)得到名为phone.html的图像文件,
对于上述的图片其他的颜色或者格式可以在这个说明界面里找到对应的示例:
喜欢什么格式就把对应代码复制在pycharm,只需要修改add部分,将自己的数据输入进去。
3.PIL模块图像的处理

先安装pillow,完成后,这里我们可以使用该模块做一个图像颜色的交换。
r表示red,g表示green,b表示blue。图片格式是四维的元组RGBA,通过调换位置将颜色互换。
python
from PIL import Image
#加载图片
im=Image.open('google.jpg')
print(type(im),im)
#提取RGB图片的颜色通道,返回结果是图像的副本
r,g,b=im.split()
# print(r)
# print(g)
# print(b)
# 合并通道
om=Image.merge(mode='RGB',bands=(r,b,g))
om.save('new_google.png')结果如下其中左为原图,右为新建的图形。


4.jieba模块实现中文分词

这里我们以豆瓣榜单前250个电影的名单为例,使用的链接为
http://movie.douban.com/top250先爬取这十页的内容,参考【(冒死上传)50分钟超快速入门Python爬虫 | 动画教学【2025新版】【自学Python爬虫教程】【零基础爬虫】】 https://www.bilibili.com/video/BV1EHdUYEEEj/?share_source=copy_web\&vd_source=404581381724503685cb98601d6706fb
编写代码如下:
python
import requests
from bs4 import BeautifulSoup
headers={
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.5061 SLBChan/112 SLBVPV/64-bit'
}
for start_num in range(0,250,25):
#print(start_num)
response = requests.get(f"http://movie.douban.com/top250?start={start_num}", headers=headers)
html=response.text
soup=BeautifulSoup(html,"html.parser")
all_titles=soup.find_all('span',attrs={'class':'title'})
for title in all_titles:
# print(title) #把class值为title的span元素都打印出来了
#print(title.string) #将span标签都忽视,只保留文字
title_string=title.string
if "/" not in title_string:
print(title_string)这样可以爬取出完整的电影清单,命名为"电影清单"的txt文件。在同文件夹中建立一个新的python文件,内容如下:
python
import jieba
#读取文件
with open('电影清单','r',encoding='utf-8') as file:
s=file.read()
#print(s)
#分词
lst=jieba.lcut(s)
print(lst)
#去重操作
set1=set(lst) #使用集合实现去重
#
d={} #key:词,value:出现的次数
for item in set1:
if len(item)>=2:
d[item]=0
# print(d)
for item in lst:
if item in d:
d[item]=d.get(item)+1
print(d) #统计词汇出现的频率,简称词频
new_lst=[]
for item in d:
new_lst.append([item,d[item]])
print(new_lst)
#列表排序
new_lst.sort(key=lambda x: x[1], reverse=True)
print(new_lst[0:11]) #显示的是前10项运行结果如下:

5.Pylnstaller打包模块
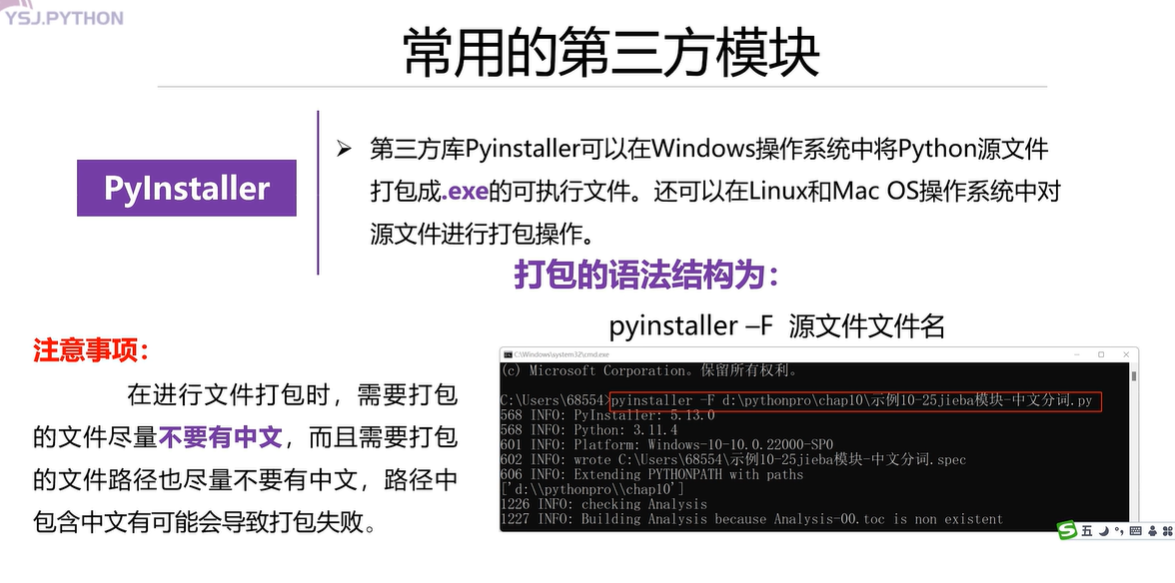
这个用法就是在运行程序框中将puinstaller -F 你想要打包的文件名,但是我们尽量使用英文来命名,因为中文命名可能会报错。打包完事再双击那个打包完成的python文件,就是一闪而过的(因为瞬间运行了),如果不想让这个程序运行以后啥也没有,就在原始的程序的最后部分输入input()
本节完