Prototype-Aware Multimodal Alignment for Open-Vocabulary Visual Grounding
Authors: Jiangnan Xie, Xiaolong Zheng, Liang Zheng
Deep-Dive Summary:
原型感知的多模态对齐用于开放词汇视觉定位
摘要
视觉定位(Visual Grounding, VG)旨在利用给定的自然语言查询在图像中定位特定目标对象。尽管当前的基于Transformer的方法在标准场景(即没有新颖对象的场景)中表现出强大的定位性能,但在开放词汇场景(即测试时包含熟悉和新颖对象类别)中存在显著局限性。这些局限性主要源于三个关键因素:(1) 视觉和语言模态之间的不完美对齐,(2) 跨模态特征融合不足,(3) 语义原型信息的利用效率不高。为解决这些挑战,我们提出了原型感知多模态学习(PAML) ,一个创新框架,通过以下关键组件系统性地解决这些问题:首先,我们利用ALBEF建立初始特征编码的稳健跨模态对齐。随后,我们的视觉区分特征编码器 选择性地增强显著对象表示,同时抑制无关视觉上下文。该框架还引入了一种新颖的原型发现与继承机制 ,提取并聚合同邻域语义原型以促进开放词汇识别。这些增强的特征通过我们的多阶段解码器进行全面的多模态融合,最终进行边界框回归。在五个基准数据集上的广泛实验验证了我们的方法,在标准场景中表现出竞争力的性能,同时在开放词汇场景中实现了最先进的表现。代码和模型可通过以下链接获取:https://github.com/plankXie/PAML。
1. 引言
视觉定位(VG),也称为短语定位(Phrase Grounding, PG)或指代表达式理解(Referring Expression Comprehension, REC),旨在根据给定的图像-语言查询对,准确地在图像中定位语言表达式描述的对象。由于其对视觉和文本模态的深入理解要求,VG任务的有效解决在多种多模态领域(如视觉-语言导航、视觉问答和人机交互)具有重要应用潜力。然而,当前大多数模型采用完全监督学习训练,需要访问带注释的区域边界框和指代表达式,手动标注大量此类数据成本极高。因此,近年来提出了多种方法来缓解这一问题,包括半监督学习(部分数据完全标注,部分数据部分标注)、弱监督学习(仅提供图像和对应文本,无边界框)以及无监督学习(仅提供图像,无任何任务相关标注)。此外,在复杂多样的现实场景中,待定位的对象往往在模型训练时未曾遇到。因此,相较于标准场景,解决模型在开放词汇场景中的性能更具实际意义。
开放词汇场景(测试集中可能包含训练集中未出现的对象)在一些文献中也被称为通用零样本设置。近年来,大规模视觉-语言预训练模型(如CLIP、ALBEF、VLMO、BLIP、CoCa和BEIT-3)展示了强大的特征表示能力,能够无缝转移到下游任务。然而,直接应用这些模型而不充分考虑图像和文本的内在信息可能对对象定位不利。TransCP论文创新性地提出了上下文解纠缠 和原型发现与继承两种方法,显著提高了模型在标准和开放词汇场景中的准确性。然而,该模型仅考虑内在上下文信息和最近原型信息,易受区分性关系信息的干扰。在上下文信息质量较低且表达式复杂的数据集(如ReferIt)上训练并在其他数据集上测试时,模型性能不佳。此外,该模型的模态融合仅依赖简单的Hadamard融合,其他类似的基于Transformer的方法也仅通过简单的注意力操作进行浅层模态融合。因此,更彻底的模态融合至关重要。
基于对先前工作的优缺点的全面分析,我们提出了PAML框架 ,旨在增强模型在标准和开放词汇场景中的性能。该框架集成了ALBEF模块,利用其强大的多模态表示和对齐能力,提取高度代表性和良好对齐的图像和语言特征。视觉区分特征编码器 增强显著对象的区分性表示,同时抑制无关上下文信息。此外,框架集成了多邻域原型发现与继承模块 ,使模型能够从原型库中学习,充分利用训练数据在两种场景中定位指代对象。此外,多阶段解码器模块促进模态融合,从而提升模型在两种场景中的定位能力。
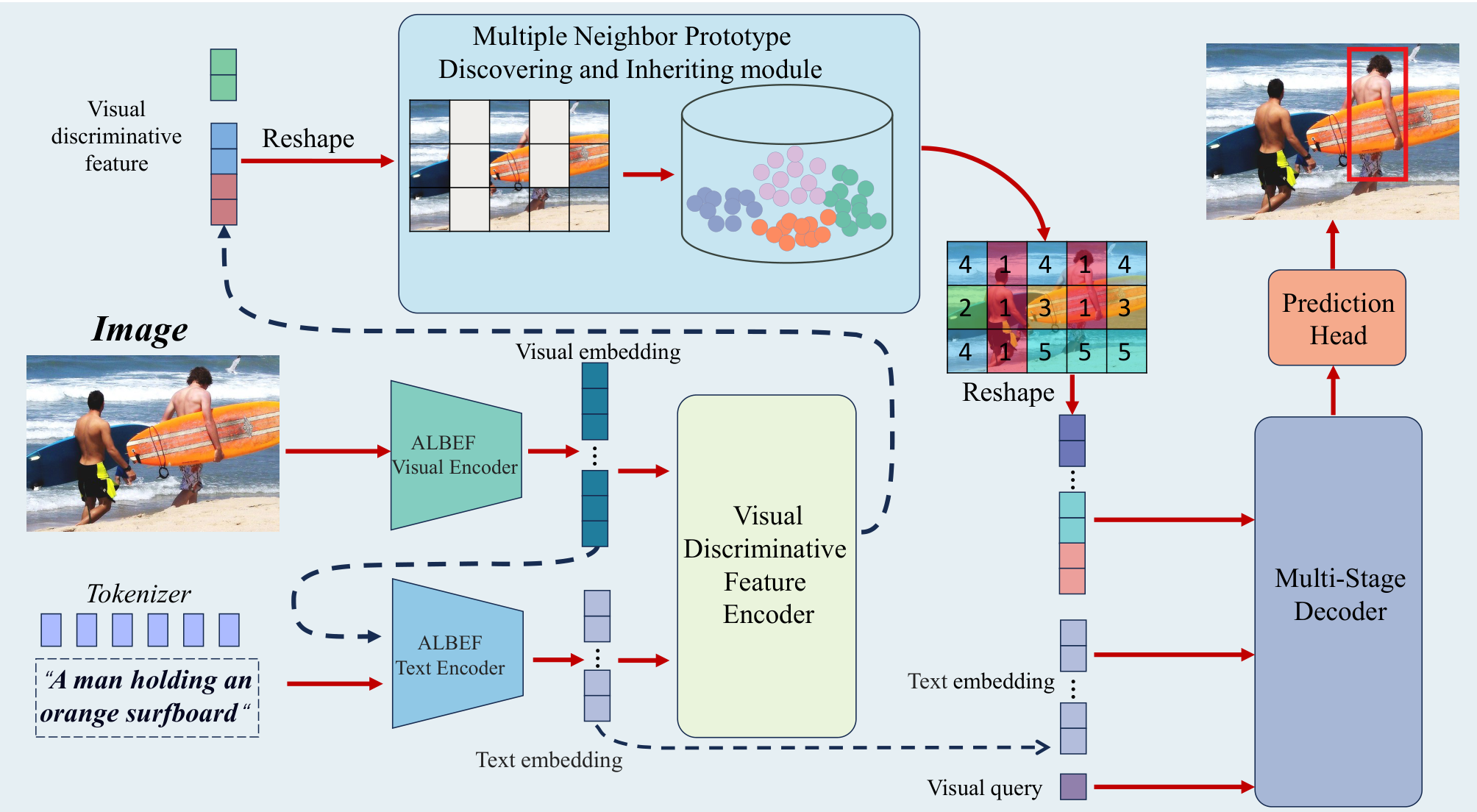
如图1所示,图像数据首先通过ALBEF视觉编码器处理以获得相应嵌入,文本数据则被分词并与嵌入的图像数据一起输入ALBEF文本编码器进行文本嵌入。这些多模态嵌入随后输入视觉区分特征编码器模块 以提取高度区分性的视觉特征。这些特征随后进入原型库进行发现和继承过程,从而获取多邻域视觉原型特征。视觉原型特征与未经过视觉区分特征编码器处理的视觉特征拼接,并与视觉查询及ALBEF文本编码器导出的语言特征结合。这些融合数据随后输入多阶段解码器 以促进模态融合。最后,视觉查询通过预测头处理以获得目标对象的边界框(BBOX)坐标。
总结而言,我们的贡献包括五方面:
- 我们提出了一个新颖且高效的模型PAML,各模块无缝协作,在标准和开放词汇场景中均表现出卓越性能,在多个基准数据集上实现最先进的结果。广泛的消融实验验证了每个组件的有效性。
- 我们直接利用预训练的ALBEF模块进行稳健的编码和跨模态对齐。
- 在TransCP的视觉上下文解纠缠模块基础上,我们通过引入拉普拉斯变换并通过可学习参数平衡两种变换的贡献,改进为视觉区分特征编码器。
- 我们扩展了TransCP的原型发现与继承,采用多邻域原型继承而非最近邻继承,增强原型表示的丰富性。
- 我们提出了一个新颖的多阶段解码器,解决先前基于Transformer的方法中直接对双模态数据进行注意力操作导致的模态融合不足问题。
2. 相关工作
2.1 视觉定位
现有VG模型根据多模态融合和推理范式可分为三类:两阶段方法、单阶段方法和基于Transformer的方法。
两阶段方法依赖预训练的目标检测器生成一组候选边界框,然后测量这些候选框与语言描述的相似性以定位目标对象。然而,该方法受限于预训练检测器的性能。如果生成的边界框未能包含需定位的目标对象,后续网络将完全无法准确确定对象位置。单阶段方法在嵌入多模态数据后进行视觉-语言融合,然后在预定义的密集锚点中输出得分最高的边界框。然而,复杂的模态融合模块及基于锚点的方法对模型定位性能施加了显著限制。
基于Transformer的方法较为优雅。TransVG率先利用Transformer直接嵌入并融合双模态数据,并使用特殊的REG标记直接回归目标对象的坐标。该模型表现出色,被广泛用作后续研究的基线。Zheng等人提出的ResVG模型利用稳定扩散模型生成大量合成数据,增强模型对细粒度语义和空间关系的理解。Dai等人提出的SimVG模型通过预训练多模态模型和补充对象标记,将视觉-语言特征整合与下游任务解耦,采用动态权重平衡蒸馏策略强化轻量级MLP路径,简化架构并显著加速推理速度。Xiao等人提出的HiVG模型通过跨模态桥梁建立视觉和文本模态的多层次连接,解决视觉特征与定位所需特征的不一致性,并引入HiLoRA适配跨模态特征,防止感知错误积累。基于Transformer的方法表现出色,逐渐成为视觉定位任务的主流方法。
2.2 零样本视觉定位
如第1节所述,开放词汇场景也被称为通用零样本设置。因此,零样本相关研究对开放词汇视觉定位的研究具有启发性。ZSGNet总结了四种评估模型性能的场景,并引入了用于零样本视觉定位的新颖数据集,提出利用外部知识构建多模态知识图谱以应对零样本视觉定位挑战。近年来,基于预训练视觉-语言模型的方法不断涌现。例如,Yao等人提出的CPT将视觉定位重构为基于图像和文本中颜色的共指标记的填空问题,从而最小化差距。ReCLIP模型通过孤立提案巧妙地将视觉定位问题转化为图像-文本匹配任务,充分利用CLIP的能力,并引入空间关系解析器解决CLIP在空间推理中的局限性。GroundVLP模型利用Grad-CAM突出与语言查询高度相关的区域,同时使用开放词汇目标检测器识别与表达式主体一致的所有对象,最终通过整合这两个组件定位目标对象。预训练视觉-语言模型在零样本视觉定位中的出色表现启发我们利用ALBEF和CLIP等模型增强开放词汇场景中的模型能力。
3. 方法
我们提出了PAML,一个新颖框架,旨在有效解决开放词汇场景视觉定位问题。如图1所示,整个网络主要由五个关键组件组成:(1) ALBEF编码器,(2) 视觉区分特征编码器,(3) 多邻域原型发现与继承模块,(4) 多阶段解码器,(5) 预测头。以下部分将详细阐述每个组件的设计原理。
3.1 ALBEF编码器
对于输入图像 I ∈ R B × 256 × 256 I \in \mathbb{R}^{B \times 256 \times 256} I∈RB×256×256 和对应的文本 T ∈ R B × L 0 T \in \mathbb{R}^{B \times L_0} T∈RB×L0( L 0 = 40 L_0 = 40 L0=40),图像数据首先输入ALBEF视觉编码器。该模块主要采用ViT-B/16架构。图像经过补丁嵌入处理,转化为图像标记,然后与初始化为零的可学习类(cls)标记 ∈ R B × 1 × C 0 \in \mathbb{R}^{B \times 1 \times C_0} ∈RB×1×C0 拼接。随后,组合标记通过12层Transformer编码器块处理,并通过线性插值扩展到400,以满足后续网络的维度要求,最终获得图像标记 f v ∈ R B × 400 × C 0 f_v \in \mathbb{R}^{B \times 400 \times C_0} fv∈RB×400×C0。
输入 T T T 和 f v f_v fv 被送入ALBEF文本编码器。 T T T 首先通过BertEmbeddings模块处理,随后 f e m b f_{emb} femb 和 f v f_v fv 输入BertEncoder模块。在每一层中,文本特征进行自注意力操作,随后进行文本与图像数据的跨注意力操作,共重复12次。我们直接使用在MSCOCO数据集上预训练的ALBEF模型,因此能够获得对齐的表示 f v f_v fv 和 f l f_l fl。
3.2 视觉区分特征编码器
突出图像中显著对象的特征并抑制无关上下文信息对后续原型发现和继承至关重要。因此,在第二步, f v f_v fv 和 f l f_l fl 输入视觉区分特征编码器以获得区分性图像特征。
首先, f v f_v fv 和 f l f_l fl 沿特征维度进行线性投影,特征维度从 C 0 C_0 C0 变为 C = 256 C = 256 C=256。通过公式(1),以 f v f_v fv 为查询, f l f_l fl 为键和值,执行MCA操作,获得语言特征 f l i n f o f_{l_{info}} flinfo,以突出图像中对象的语言信息:
f l i n f o = M C A ( f v , f l , f l ) f_{l_{info}} = \mathrm{MCA}(f_v, f_l, f_l) flinfo=MCA(fv,fl,fl)
然后,通过公式(2)计算 f l i n f o f_{l_{info}} flinfo 和 f v f_v fv 之间的余弦相似度,得到相似度得分 ϕ s i m ∈ R 400 × B × 1 \phi_{sim} \in \mathbb{R}^{400 \times B \times 1} ϕsim∈R400×B×1:
ϕ s i m = ∑ i ( f l i n f o ( i ) ∥ f l i n f o ∥ 2 ⋅ f v ( i ) ∥ f v ∥ 2 ) \phi_{sim} = \sum_i \left( \frac{f_{l_{info}}(i)}{\|f_{l_{info}}\|_2} \cdot \frac{f_v(i)}{\|f_v\|_2} \right) ϕsim=i∑(∥flinfo∥2flinfo(i)⋅∥fv∥2fv(i))
其中, i i i 是数据特征维度的索引。随后,对 ϕ s i m \phi_{sim} ϕsim 应用高斯变换和拉普拉斯变换以增强其鲁棒性和表达能力:
ϕ G = exp ( − 1 − ϕ s i m 2 2 σ 2 ) \phi_G = \exp\left(-\frac{1 - \phi_{sim}^2}{2\sigma^2}\right) ϕG=exp(−2σ21−ϕsim2)
ϕ L = − exp ( − ∣ 1 − ϕ s i m ∣ b ) \phi_L = -\exp\left(-\frac{|1 - \phi_{sim}|}{b}\right) ϕL=−exp(−b∣1−ϕsim∣)
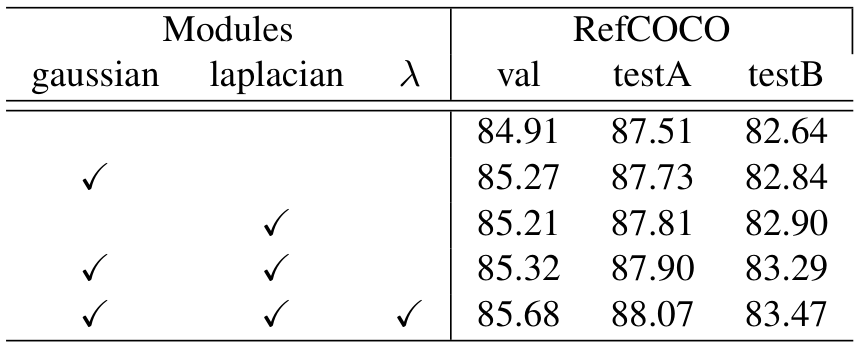
高斯变换(公式3)平滑 ϕ s i m \phi_{sim} ϕsim,使其数据分布更连续稳定,减轻噪声对相似度计算的影响,增强模型鲁棒性。高斯变换对接近1(高相似度)的值分配更高权重,抑制远离1的值,使模型更关注高相关图像区域和文本,提升特征融合质量。拉普拉斯变换(公式4)建模 ϕ s i m \phi_{sim} ϕsim 的绝对差异,更好处理异常值或噪声,增强模型在处理不准确相似度得分时的稳定性。拉普拉斯变换对高低相似度区域均分配一定权重,避免高斯变换过度强调高相似度区域的问题。最终,通过可学习参数 λ \lambda λ(公式5)组合两种变换的数据,灵活调整两者的权重,平衡高相似度区域的强调和对异常值的鲁棒性,初始 λ \lambda λ 设为0.5。
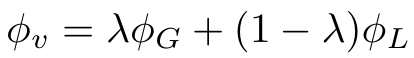
随后,类似公式(1),我们使用另一MCA层,以 f l i n f o f_{l_{info}} flinfo 作为查询, f v f_v fv 作为键和值,获得 f l c i n f o f_{lc_{info}} flcinfo,表示文本对图像特征的引导信息。随后,根据公式(6)调制图像特征:
f m v = ( f l c i n f o × α ) × f v + f l c i n f o × β f_{mv} = (f_{lc_{info}} \times \alpha) \times f_v + f_{lc_{info}} \times \beta fmv=(flcinfo×α)×fv+flcinfo×β
其中, α ∈ R C × C \alpha \in \mathbb{R}^{C \times C} α∈RC×C 和 β ∈ R C × C \beta \in \mathbb{R}^{C \times C} β∈RC×C 为权重参数, f m v ∈ R 400 × B × C f_{mv} \in \mathbb{R}^{400 \times B \times C} fmv∈R400×B×C,公式(6)将语言信息整合到图像特征中。
f l c v = M H A ( f m v , f m v , f v ) f_{lcv} = \mathrm{MHA}(f_{mv}, f_{mv}, f_v) flcv=MHA(fmv,fmv,fv)
随后,以 q = k = f m v q = k = f_{mv} q=k=fmv, v = f v v = f_v v=fv 执行MCA操作,增强图像特征的表示能力,同时丰富图像的上下文信息并捕获全局关系。最终,利用公式(8)生成区分性特征 f d i s v f_{disv} fdisv,通过LayerNorm(参数 e p s = 1 e − 5 eps = 1e^{-5} eps=1e−5)处理,拼接 f v f_v fv 和 f d i s v f_{disv} fdisv 输出到后续模块:
f d i s v = ( M O P T n ( f v ) + M O P T n ( f l c v ) ) × ϕ v f_{disv} = (M_{OPTn}(f_v) + M_{OPTn}(f_{lcv})) \times \phi_v fdisv=(MOPTn(fv)+MOPTn(flcv))×ϕv
与TransCP的视觉上下文解纠缠模块类似,但关键区别在于我们的双变换方法。TransCP仅依赖高斯变换进行特征调制,可能过度强调高相似度区域而强烈抑制低相似度区域。我们引入拉普拉斯变换提供更平滑的权重分布,并通过可学习参数 λ \lambda λ 动态平衡两者的贡献。消融研究(表8)验证了该组合在保留潜在有用弱相关特征的同时保持对强对齐区域的关注,表现出更强的鲁棒性。
3.3 多邻域原型发现与继承
原型信息在开放词汇场景中至关重要。然而,TransCP的原型发现与继承模块仅考虑与输入最近的标记。实际上,其他邻近原型也能在不同程度上有助于定位。为解决这一局限性,我们增强了该模块,有效捕获输入标记在一定距离阈值内的邻近原型信息。获得的 f d i s v f_{disv} fdisv 首先通过2D卷积层(步幅和核大小均为1)上采样到768维( C 1 = 768 C_1 = 768 C1=768),记为 X X X,然后输入原型库进行发现和继承过程,伪代码如算法1所示。
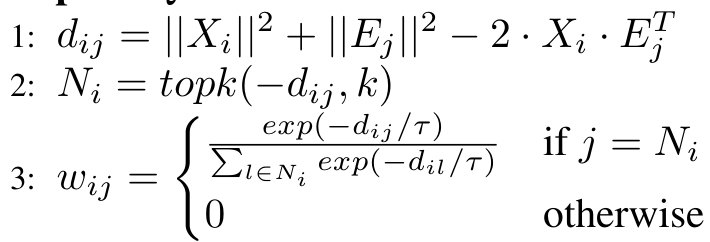
原型库中的原型嵌入 E ∈ R 2048 × C 1 E \in \mathbb{R}^{2048 \times C_1} E∈R2048×C1 初始化为零。计算 X X X 的每个元素与 E j E_j Ej 的平方欧几里得距离,基于此距离获得最近的 k k k 个原型标记的索引 N ∈ R B × 400 N \in \mathbb{R}^{B \times 400} N∈RB×400。随后, N N N 转换为权重矩阵 w ∈ R B × 400 × 2048 w \in \mathbb{R}^{B \times 400 \times 2048} w∈RB×400×2048,并在训练期间可学习。在训练期间,更新原型库 E E E 及其统计量。首先,计算每个原型标记 E j E_j Ej 的簇大小 s ∈ R 2048 s \in \mathbb{R}^{2048} s∈R2048(即分配给该原型标记的输入数据点数量)。然后,使用指数移动平均(EMA)更新簇大小 S ∈ R 2048 S \in \mathbb{R}^{2048} S∈R2048。为每个原型标记 E j E_j Ej 计算嵌入总和 C C C(即分配给该原型向量的所有输入数据点之和),并使用EMA更新嵌入平均值 C C C。衰减率 Q Q Q 设为0.4。为防止某些原型标记的簇大小为零,对 S S S 应用拉普拉斯平滑,并使用 S ′ S' S′ 归一化原型标记,完成 E E E 的更新。
随后,基于最近的 k k k 个原型标记量化输入数据,生成量化特征 Q ∈ R ( B × 400 ) × C 1 Q \in \mathbb{R}^{(B \times 400) \times C_1} Q∈R(B×400)×C1。实验结果(第4.3.4节)表明, k = 5 k = 5 k=5 时性能最佳。获得 Q Q Q 后,将其重塑为与 f i n f_{in} fin 相同空间维度的张量,记为 f q t f_{qt} fqt,并通过公式(9)对 T f e a t T_{feat} Tfeat 应用降维和softmax操作,生成 T S T_S TS。Gate()实现为2D卷积层,输入通道大小为1536,输出通道大小为2,步幅和核大小均为1。从 T S T_S TS 中提取第一个特征维度作为 E S E_S ES,第二个特征维度作为 I S ∈ R B × 1 × 20 × 20 I_S \in \mathbb{R}^{B \times 1 \times 20 \times 20} IS∈RB×1×20×20:
T S = S o f t m a x ( G a t e ( C o n v ( T f e a t ) ) ) T_S = \mathrm{Softmax}(\mathrm{Gate}(\mathrm{Conv}(T_{feat}))) TS=Softmax(Gate(Conv(Tfeat)))
通过公式(10)计算最终特征 P P P:
P = ⨁ O ( P ‾ + 1 2 P − 1 2 P + P 4 ( Ψ f + μ ) ) P = \bigoplus_{O}(\overline{P} + \frac{1}{2}P - \frac{1}{2}P + P_4(\Psi f + \mu)) P=O⨁(P+21P−21P+P4(Ψf+μ))
其中, C o n v t \mathrm{Conv}t Convt 为2D卷积层,输入通道大小为768,输出通道大小为256,步幅和核大小均为1。特征 f q t f{qt} fqt 捕获输入数据的全局结构和语义信息,有效表示高维空间中输入数据的分布,适合类间差异较大的任务。而 f i n f_{in} fin 保留输入数据的局部细节和低级特征,捕获细粒度信息。通过动态加权机制( I S I_S IS 和 E S E_S ES),模型自适应整合全局语义信息与局部细节信息,全面提取数据中的有价值信息。
3.4 多阶段解码器
先前研究主要采用注意力机制直接融合REG标记、视觉标记和文本标记的模态。相比之下,我们提出了多阶段模态融合方法。具体过程如下:初始化 T i n f o T_{info} Tinfo 为零,并根据公式(11)计算 T i n f o T_{info} Tinfo,提取与视觉查询相关的语义信息。随后,通过公式(12)推导 V i n f o V_{info} Vinfo,提取与文本查询相关的视觉信息。最后,通过公式(13)和公式(14)获得相应的视觉查询。FFN由两个线性层组成,中间使用ReLU激活函数,中间维度为2048,输入和输出维度均为256:
T i n f o n = M C A ( f v q n − 1 , f l , f l ) T_{info}^n = \mathrm{MCA}(f_{vq}^{n-1}, f_l, f_l) Tinfon=MCA(fvqn−1,fl,fl)
V i n f o n = M C A ( T i n f o n , f q , f v ) V_{info}^n = \mathrm{MCA}(T_{info}^n, f_q, f_v) Vinfon=MCA(Tinfon,fq,fv)
f v q t n = M C A ( f v q n − 1 , V i n f o n ) f_{vqt}^n = \mathrm{MCA}(f_{vq}^{n-1}, V_{info}^n) fvqtn=MCA(fvqn−1,Vinfon)
f v Q n l = M C A ( f v q t n l , F F N ( f v q t n l ) ) f_{vQ}^{nl} = \mathrm{MCA}(f_{vqt}^{nl}, \mathrm{FFN}(f_{vqt}^{nl})) fvQnl=MCA(fvqtnl,FFN(fvqtnl))
该模块设计相比传统多模态处理具有显著新颖性。文本和视觉信息的提取以解耦方式分别进行,使模型更灵活地处理不同模态的信息,避免模态间的直接干扰。同时,模型利用嵌套注意力机制,文本信息引导视觉信息的提取,视觉信息反过来优化文本信息的表示。这种嵌套架构使模型更有效地捕获模态间的复杂交互。
3.5 训练目标
多阶段解码器共包含6层,我们还利用中间层 f v q f_{vq} fvq。通过预测头获得相应的边界框坐标,如公式(15)所示:
B ^ i = M L P ( f v q i ) \hat{B}i = \mathrm{MLP}(f{vq}^i) B^i=MLP(fvqi)
MLP由三个线性层和Sigmoid激活函数组成。前两个线性层的输入和输出维度均为256,最后一个线性层的输出维度为4,表示边界框的四个坐标。遵循其他基于Transformer的方法,我们采用L1损失和GIoU损失作为训练阶段的损失函数:
L = ∑ i = 1 6 ( λ L 1 L L 1 ( B , B ^ i ) + λ G I o U L G I o U ( B , B ^ i ) ) \mathcal{L} = \sum_{i=1}^{6} (\lambda_{L1} \mathcal{L}{L1}(B, \hat{B}i) + \lambda{GIoU} \mathcal{L}{GIoU}(B, \hat{B}_i)) L=i=1∑6(λL1LL1(B,B^i)+λGIoULGIoU(B,B^i))
其中, λ L 1 \lambda_{L1} λL1 和 λ G I o U \lambda_{GIoU} λGIoU 经验性地设为5和2,以实现两种损失函数的最佳平衡。通过加入中间查询对应的损失,模型在训练过程中获得多阶段监督,促进定位任务的学习,降低过拟合风险,并增强模型在多样化场景中的泛化能力。此外,中间查询捕获不同尺度的特征信息,帮助模型全面理解目标上下文,从而更准确地定位目标。
3.6 理论分析
3.6.1 多邻域原型发现与继承
在开放词汇场景中,新颖对象通常位于特征空间的低密度区域,训练数据稀疏。先前依赖单一原型匹配的方法(如最近邻检索)在这些区域具有高方差,导致预测不稳定。我们的多邻域原型发现与继承模块 通过聚合多个语义相关原型的信息缓解这一问题。对于输入特征 ϕ ( x ) \phi(x) ϕ(x),继承的原型特征计算如下:
ϕ ^ ( x ) = ∑ k ∈ N k ( x ) w k ⋅ p k ( w k ∝ exp ( − ∥ ϕ ( x ) − p k ∥ 2 / τ ) ) \hat{\phi}(x) = \sum_{k \in \mathcal{N}_k(x)} w_k \cdot p_k \quad (w_k \propto \exp\left(-\left\|\phi(x) - p_k\right\|^2 / \tau\right)) ϕ^(x)=k∈Nk(x)∑wk⋅pk(wk∝exp(−∥ϕ(x)−pk∥2/τ))
其中, N k ( x ) \mathcal{N}_k(x) Nk(x) 表示最近的 K K K 个原型, τ \tau τ 为控制权重尖锐度的温度参数。该公式受流形假设启发,认为语义相似对象的高维视觉特征位于低维流形附近。当新颖对象特征位于流形低密度区域(如类间边界区域)时,单一原型匹配强制将其分配给最近的孤立原型,破坏流形的局部拓扑结构。通过在原型间插值,我们的方法有效平滑低训练数据区域的决策边界。新颖对象的泛化误差 L \mathcal{L} L 可分解为偏差和方差项:
L ≤ C K + L ⋅ E min p ∈ P ∥ ϕ ( x ) − p ∥ \mathcal{L} \leq \frac{C}{\sqrt{K}} + L \cdot \mathbb{E}\left\\min_{p \\in \\mathcal{P}} \\left\\\|\\phi(x) - p\\right\\\|\\right L≤K C+L⋅Ep∈Pmin∥ϕ(x)−p∥
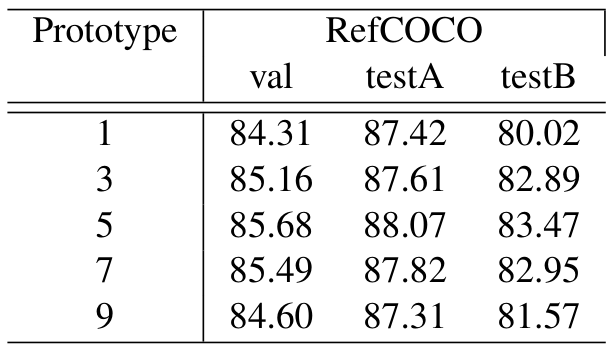
其中, C C C 为数据相关常数, L L L 为下游预测器的Lipschitz常数。右侧第一项表示方差项,第二项对应偏差项。随着 K K K 从1增加,方差项初始主导,误差以 O ( 1 / K ) O(1/\sqrt{K}) O(1/K ) 的速率下降。当 K K K 过大时,偏差项因引入无关原型而占主导,导致偏差增加。实验(表9)表明 K = 5 K = 5 K=5 实现最佳偏差-方差平衡。
3.6.2 多阶段融合作为迭代优化
受EM算法启发,多阶段解码器可分解为两步:(1) 计算跨模态注意力,估计视觉区域与语言标记的相关性;(2) 更新视觉查询 f v q f_{vq} fvq 以最大化模态间一致性。在阶段 n n n,更新规则为:
f v q n ⟶ ∏ ( f v q n − 1 , f M C A ( f v q n − 1 , f l , f v ) ) f_{vq}^n \longrightarrow \prod(f_{vq}^{n-1}, f_{\mathrm{MCA}}(f_{vq}^{n-1}, f_l, f_v)) fvqn⟶∏(fvqn−1,fMCA(fvqn−1,fl,fv))
其中, F F F 为非线性变换。该迭代过程逐渐缩小模态差距 D K L ( P v i s ∥ P t e x t ) D_{KL}(P_{vis} \| P_{text}) DKL(Pvis∥Ptext)。中间监督(公式16)在训练期间引入多个梯度信号,作为隐式正则化形式。总梯度为:
∇ θ L t o t a l = ∑ i = 1 6 λ i ∇ θ L i ≈ E ∇ θ L + O ( σ / N ) \nabla_\theta \mathcal{L}{\mathrm{total}} = \sum{i=1}^{6} \lambda_i \nabla_\theta \mathcal{L}_i \approx \mathbb{E}\left\\nabla_\\theta \\mathcal{L}\\right + \mathcal{O}\left(\sigma / \sqrt{N}\right) ∇θLtotal=i=1∑6λi∇θLi≈E∇θL+O(σ/N )
其中, σ \sigma σ 为梯度噪声。通过多阶段平均,梯度估计的方差降低 6 \sqrt{6} 6 倍,使优化更稳定,降低过拟合风险。
3.7. 模块间的协同作用
PAML框架的有效性源于其紧密耦合的流水线结构,其中每个模块的输出都策略性地为下一模块提供输入并增强其性能。ALBEF编码器提供的跨模态对齐表示是关键基础,使得视觉判别特征编码器能够针对性地抑制无关视觉上下文------这一净化过程直接优化了后续原型发现阶段的输入。多个邻居原型发现与继承模块利用这些降噪特征构建判别性语义簇,其多原型聚合机制由ALBEF的语言嵌入动态引导。这些丰富化的原型与原始视觉特征形成互补流,被多阶段解码器智能融合:在每一解码层中,视觉特征通过语言指导进行细化,而原型则通过视觉证据消除语言指代的歧义。这种双向、层次化的对齐方式实现了更精确的判别,从而生成更高质量的原型,最终提升融合和回归的准确性。模块间的相互依赖使其从孤立处理器转变为一个逐步弥合视觉与语言领域的集成推理系统。
4. 实验
4.1. 数据集
ReferIt
ReferIt数据集(也称为ReferItGame)包含从SAIAPR-12集合中获取的图像,每张图像关联一个或多个特定区域的指代表达式,尽管数据集中包含一些模糊查询(例如"任何""整体")和偶尔出现的标注错误。按照先前研究的标准协议,数据集分为三个子集:训练集包含54,127个表达式,验证集包含5,842个表达式,测试集包含60,103个表达式。验证集通常用于实验分析,测试集则作为方法比较的基准。
Flickr30K Entities
Flickr30K Entities数据集为Flickr30K数据集增加了短语到区域的标注,包含31,783张图像,每张图像有五个指代表达式,共生成427,000个局部短语-区域对。该数据集注重简洁的指代短语而非冗长描述,且不包括包含同一对象类别多个实例的图像。按标准协议,数据分为29,783张训练图像、1,000张验证图像和1,000张测试图像。
RefCOCO/RefCOCO+/RefCOCOg
这些数据集源自MSCOCO,构成了指代表达式理解的三个基准数据集。RefCOCO包含19,994张图像,标注了50,000个对象和142,209个表达式,分为训练(120,624)、验证(10,834)和两个测试集------testA(5,657,以人为中心)和testB(5,095,以对象为中心)。其扩展版本RefCOCO+规模相当(19,992张图像,49,856个对象,141,564个表达式),但禁止使用空间描述符,强调外观属性,分为训练、验证、testA和testB子集,分别包含120,191、10,758、5,726和4,889个表达式。RefCOCOg包含25,799张图像和95,010个表达式,具有两种评估协议:google分割(实验中采用以保持与先前工作一致)和umd分割。
4.2. 实现细节
输入
输入图像被调整为256×256分辨率,其中较长边缩放,较短边填充。对于指代表达式,保持固定序列长度为40个标记(包括特殊标记CLS和SEP)。超过38个标记的表达式被截断,短于此的序列在SEP标记后填充空标记以保持一致维度。
评估指标
根据既定评估协议,采用top-1定位准确率作为主要指标。当预测边界框与真实边界框的交并比(IoU)超过0.5时,视为正确。
训练细节
使用AdamW优化器训练模型,初始学习率设为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。ALBEF模型(参数量2.095亿)在MSCOCO数据集上预训练。图像编码器和文本编码器分支的学习率设为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5。可学习参数 o o o和 b b b分别初始化为0.5和1,平衡 Φ G \Phi_G ΦG和 Φ L \Phi_L ΦL贡献的 λ \lambda λ参数初始化为0.5。其他可学习参数使用Xavier初始化。模型在所有数据集上训练90个epoch,学习率在60个epoch后衰减至 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5。根据参考文献,设置 λ L 1 = 5 \lambda_{L1}=5 λL1=5和 λ G I o U = 2 \lambda_{GIoU}=2 λGIoU=2。
推理
模型遵循标准监督学习协议在基准数据集上训练,通过最高验证准确率进行模型选择。测试流程包括常规性能评估和开放词汇泛化能力分析,通过跨数据集评估策略(例如,在ReferIt上训练的模型在RefCOCO系列和Flickr30k上测试)验证模型处理新词汇的能力。
所有训练和推理在单个NVIDIA GeForce RTX 4090上执行。
4.3. 与最先进方法的比较
4.3.1 比较方法
比较方法分为三类:
- 两阶段方法:包括CMN、VC、ParalAttn等。
- 单阶段方法:包括SSG、FAOA、RCCF等。
- 基于Transformer的方法:包括RefTR、TransVG、Pseudo-Q等。
4.3.2 标准场景比较
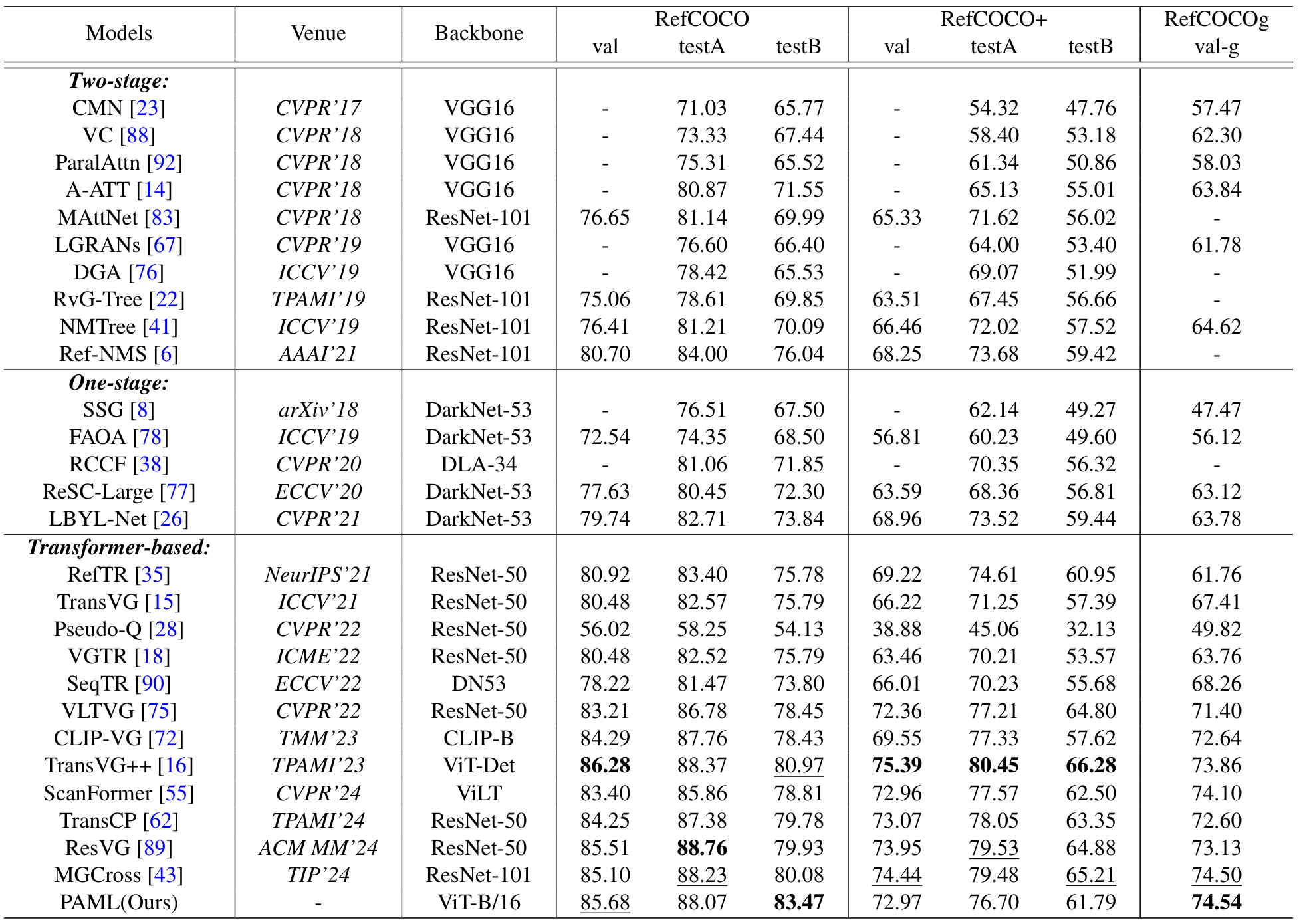
在RefCOCO系列数据集上,PAML方法表现出色,在验证集上达到85.68%的准确率,接近最佳方法TransVG++的86.28%。在testB数据集上,准确率达83.47%,超过次佳方法2.5%,表明其在处理非人物对象的鲁棒性。在RefCOCOg val-google数据集上,PAML以74.54%的准确率达到最先进水平,显示其处理复杂语言表达的能力。Transformer方法普遍优于两阶段和单阶段方法,例如在RefCOCO数据集上,最佳两阶段方法Ref-NMS在val、testA和testB子集上的准确率分别比PAML低4.98%、4.07%和7.43%。
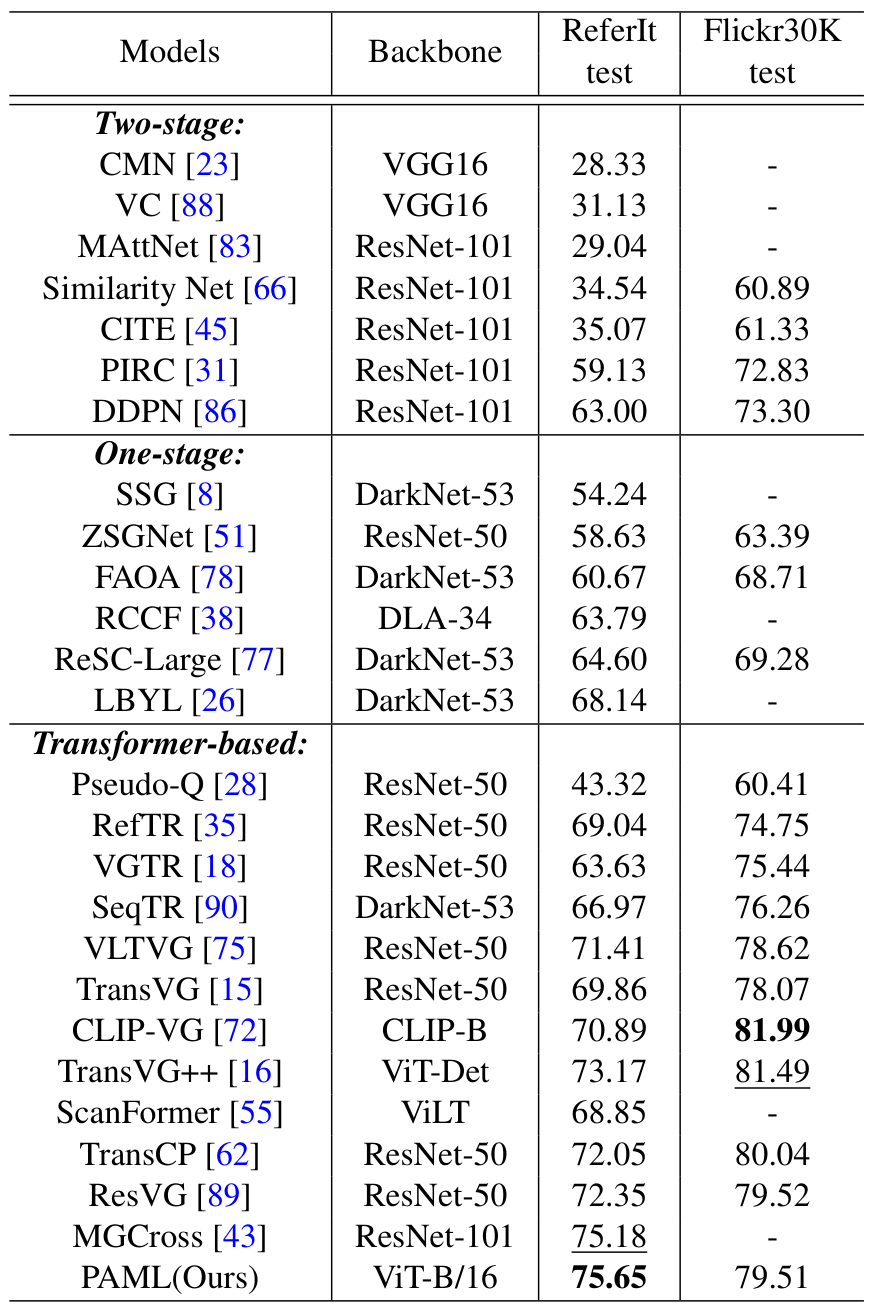
在ReferIt数据集上,PAML以75.65%的准确率达到最先进性能,展示了其处理同义词、共指关系和模糊表达的能力。图2展示了PAML在小对象定位和属性级描述上的优越性,例如准确识别"yellow bars"和"arms crossed"等。
4.3.3 开放词汇场景比较
在开放词汇场景中,PAML在跨数据集评估中表现优异,例如在ReferIt验证集和测试集上分别达到41.70%和42.78%的准确率,超越次佳方法2.84%和2.16%。在RefCOCO+上,验证集和testA的准确率分别为44.03%和47.43%,显示出强大的泛化能力。
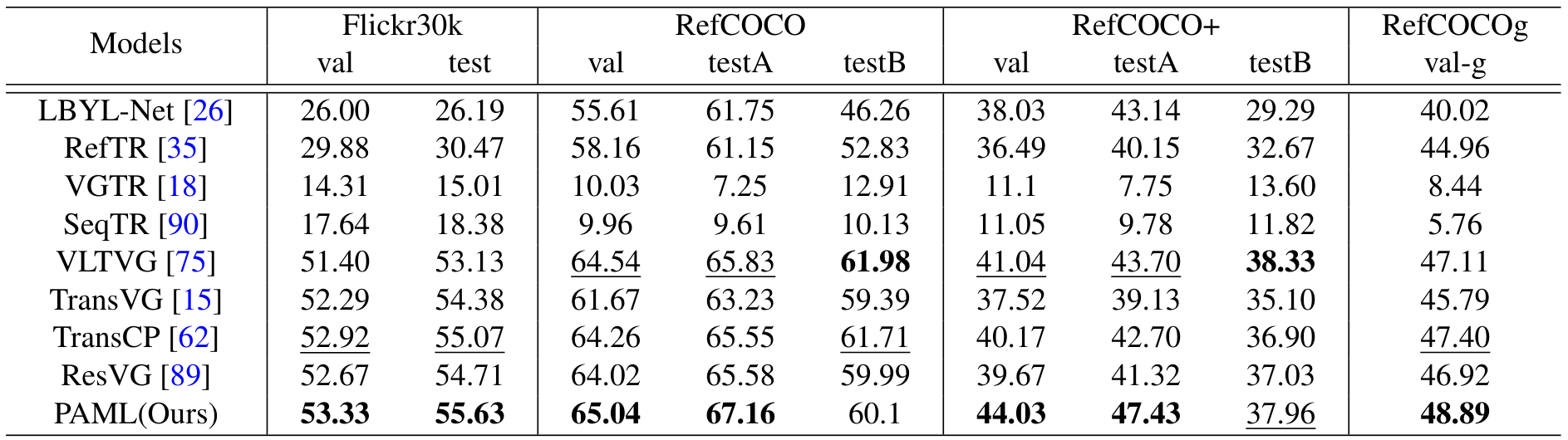

表4:在RefCOCO训练、ReferIt和Flickr30K测试的开放词汇场景中,PAML在Flickr30K上达到29.07%(验证)和27.75%(测试)的准确率,显示出强大的跨数据集泛化能力。
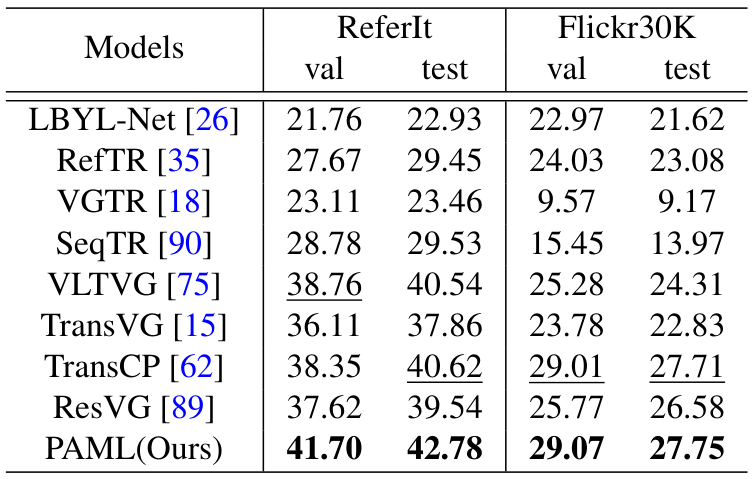
在Flickr30K训练、RefCOCO系列和ReferIt测试的设置中,PAML在大部分数据集上位居第二,但在testB上性能稍逊,可能因Flickr30K训练数据以人物和常见对象为主,难以捕捉稀有对象原型。
图3展示了PAML在开放词汇场景中的优势,例如准确定位单词查询"building"和小对象"blue shirt arm"。
4.3.4 消融研究
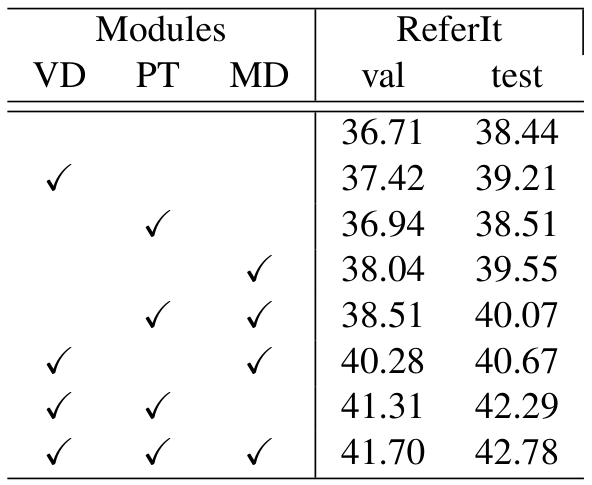
消融研究验证了各模块的贡献。表6和表7分别展示了标准场景和开放词汇场景的结果。ALBEF编码器(AL)、视觉判别特征编码器(VD)、多个邻居原型发现与继承模块(PT)和多阶段解码器(MD)的组合使用显著提升性能。例如,在RefCOCO数据集上,仅使用MD的性能提升分别为3.1%、3.05%和5.66%。VD与PT结合在ReferIt测试集上提升2.2%的准确率,显示出两者的协同效应。
公式(3)、(4)和(5)描述了输入 Φ s i m \Phi_{sim} Φsim通过高斯和拉普拉斯变换并通过可学习权重 λ \lambda λ组合生成 Φ v \Phi_v Φv的过程。表8验证了变换的有效性,未使用可学习权重时性能下降,表明两种变换和权重 λ \lambda λ对降噪和鲁棒性的重要性。
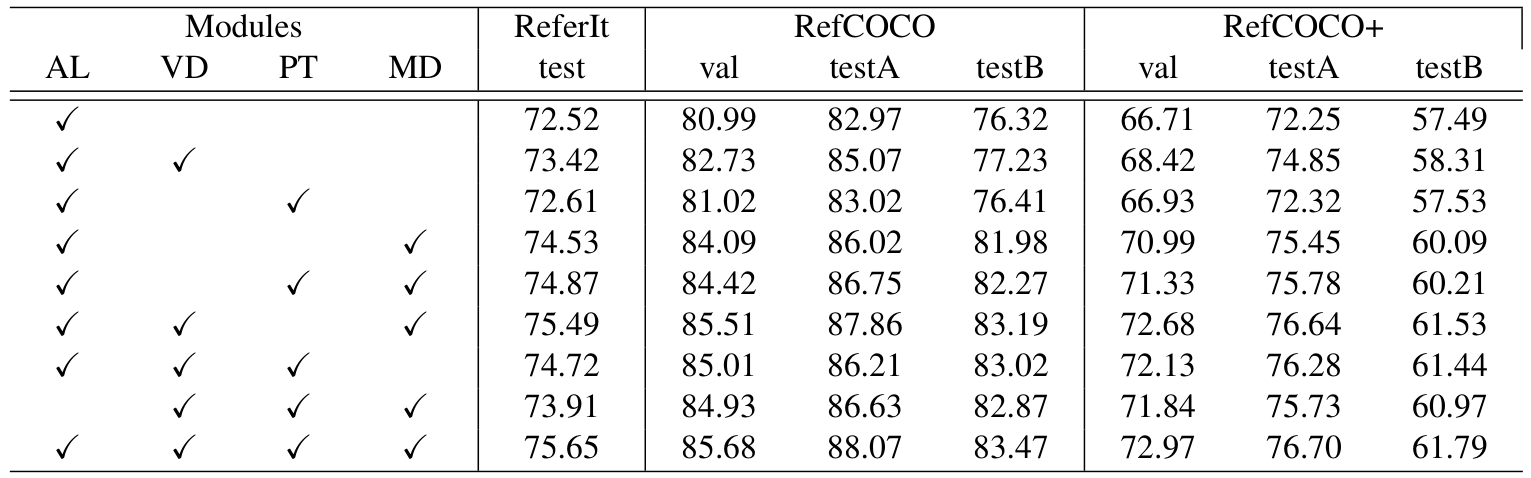
高斯变换强调高相似性区域,拉普拉斯变换处理离群值,二者平衡对模型性能至关重要。消融实验表明,使用5个最近原型取得最佳性能,过多或过少原型均降低准确率。
PAML的计算复杂度分析显示,其参数量、训练和推理时间与TransCP相比仅略增(+2%、+3.2%、+3.4%),但准确率提升5%,表明其高效性。
4.4. 可视化
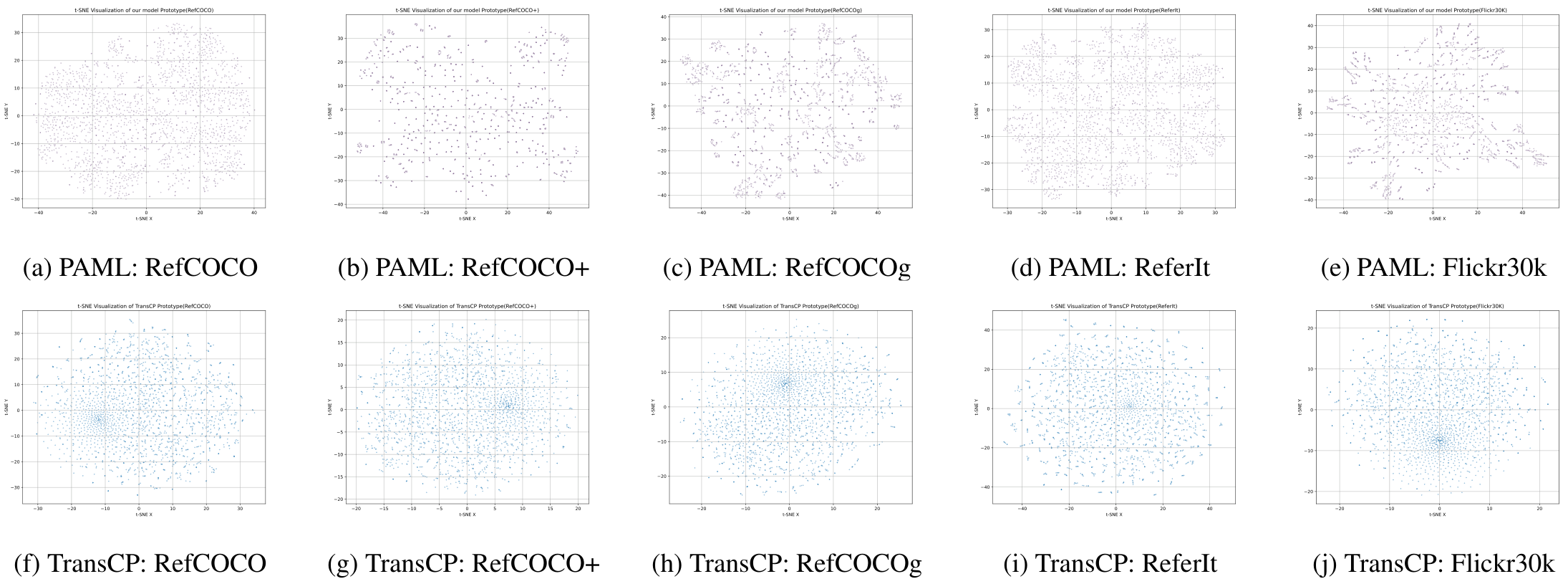
4.4.1 原型库
通过t-SNE将原型库从2048×768降维至2048×2进行可视化(图4)。PAML的原型分布较TransCP更密集,表明其原型表示学习更有效,特别是在开放词汇场景中。
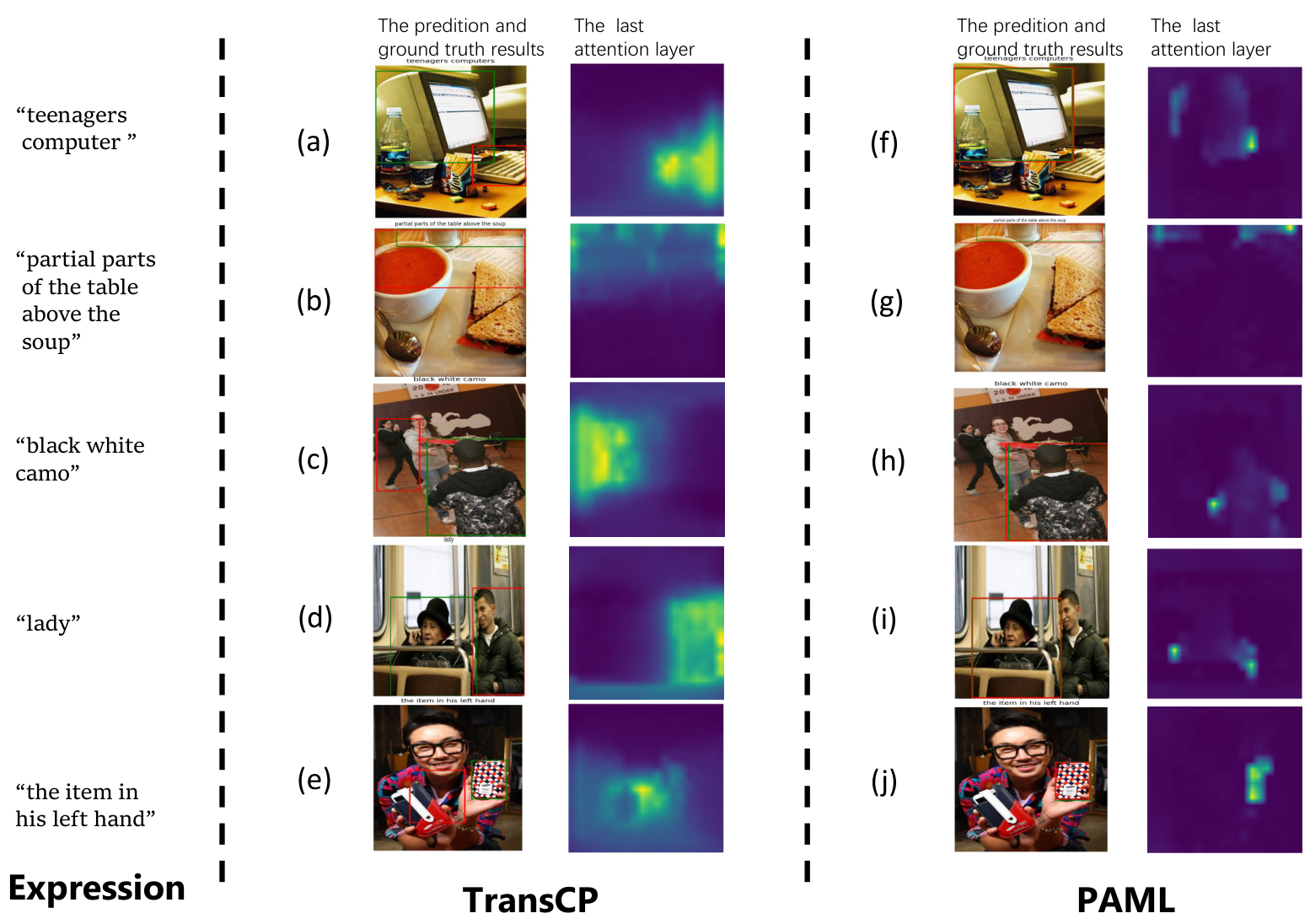
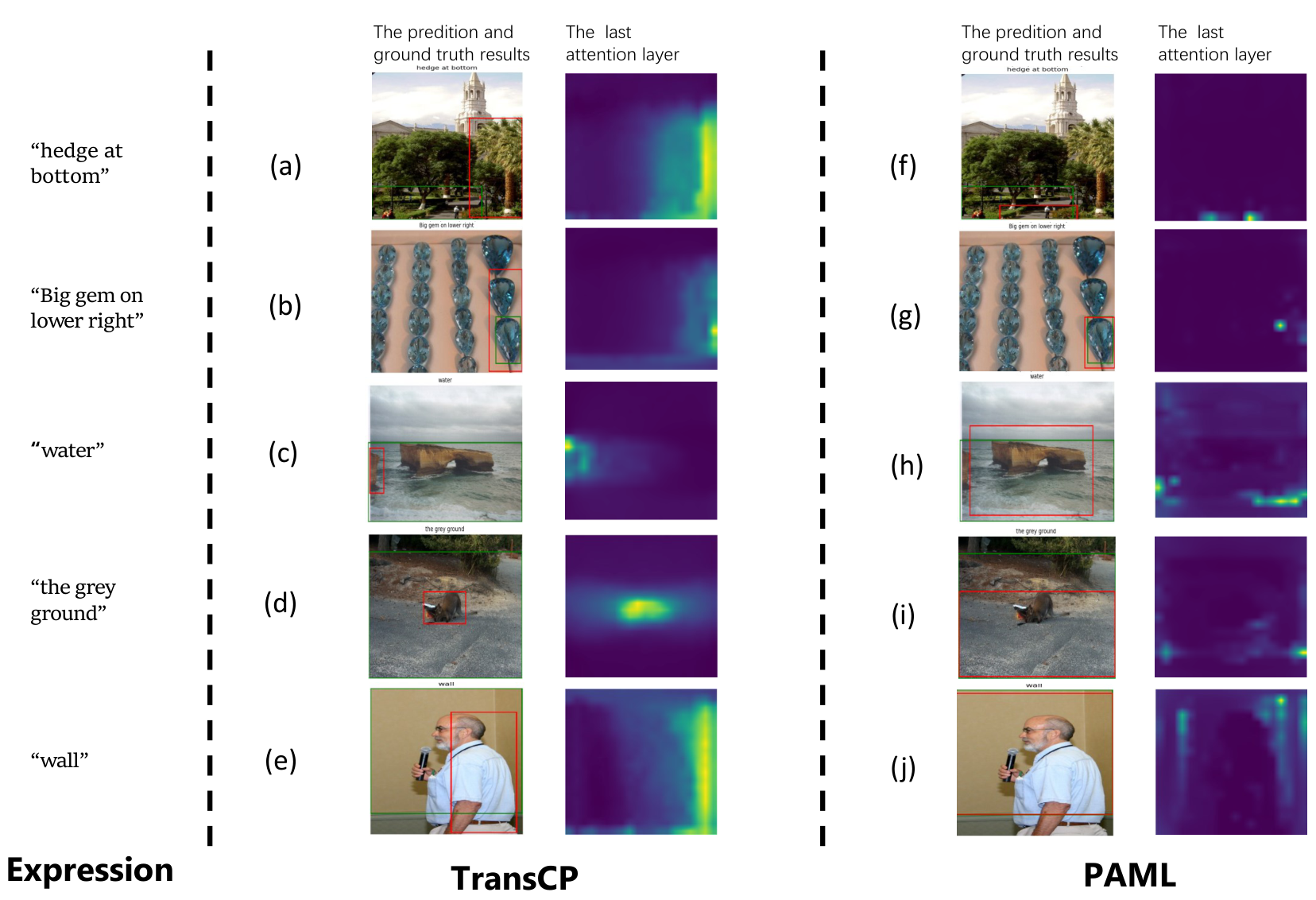
4.4.2 注意力图
图5和图6展示了PAML与TransCP在标准和开放词汇场景中的注意力图比较。PAML在细粒度词语理解、空间推理和领域特定词汇上表现更优,例如准确识别"lady""water"和"black white camo"等。
4.4.3 无关上下文抑制
图7比较了视觉判别特征编码器前后最终注意力层的注意力图。处理后,模型成功突出语言相关的对象,抑制无关背景信息,为后续模块优化了定位任务的基础。
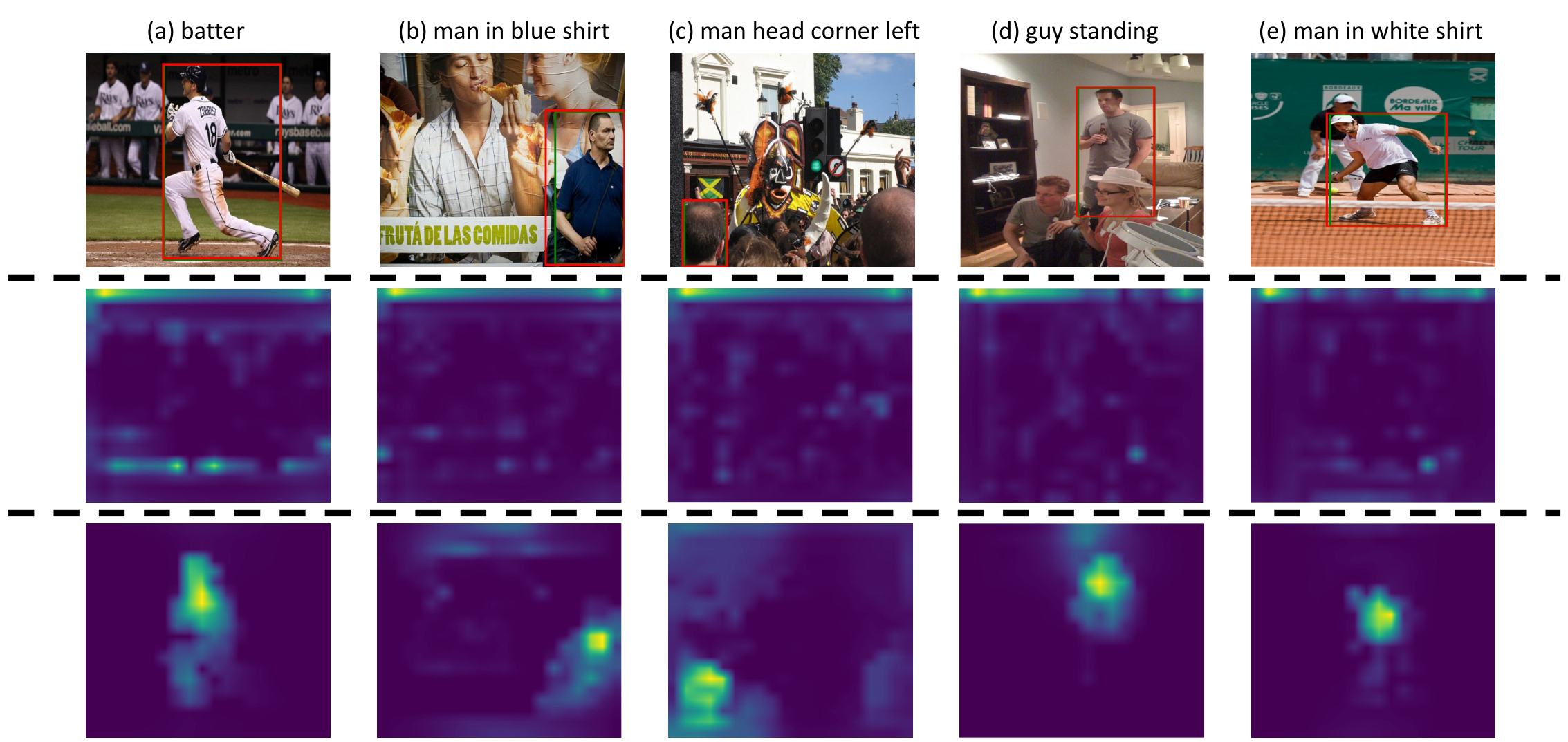
图7:展示视觉判别特征编码器前后最终注意力层的注意力图比较。顶部为输入图像和预测结果,中间为编码器前,底部为编码器后。红色:预测结果;绿色:真实值。
5. 结论
我们提出了PAML,一个用于开放词汇视觉定位的新颖框架,通过增强跨模态对齐、基于原型的推理和深度多模态融合来提升性能。PAML整合了ALBEF用于稳健的特征编码、视觉区分特征编码器用于突出对象增强、多个邻居原型发现和继承用于可泛化的原型学习与检索,以及多阶段解码器用于彻底的跨模态整合,在标准和开放词汇场景中均取得了最先进的性能。在五个基准测试上的广泛实验验证了其优越性,特别是在处理未见对象和复杂查询方面。
未来的改进可以集中在几个方面以提升模型性能。当前框架使用ALBEF进行数据编码,可以替换为更先进的视觉-语言模型以获得更好的性能。此外,原型库使用固定数量的预定义原型,而采用动态机制根据训练数据特性调整原型数量可能产生更具适应性的表示。此外,基于Transformer的方法仅依赖REG标记进行边界框回归,这引发了该设计是否足以实现多模态特征充分融合的问题。未来的工作可以探索替代的回归策略,以在保持有效多模态整合的同时提高定位精度。
CRediT authorship contribution statement
江楠谢:方法学,验证,数据整理,形式分析,调查,撰写初稿。
晓龙郑:方法学,调查,形式分析,监督,可视化,撰写初稿,撰写审稿与编辑。
梁郑:调查,形式分析。
Declaration of competing interest
作者声明没有已知的财务利益冲突或个人关系可能影响本研究报告的工作。
Data availability
本研究中使用的数据集来自公开可用的存储库,可通过相应的参考文献访问。本研究使用的代码可在https://github.com/plankXie/PAML 获取。
Acknowledgements
本研究得到中国国家重点研发计划(资助号:2024YFB4207200)的支持。
A. Preliminary
在深入探讨PAML模型细节之前,我们将首先简要介绍三种不同的注意力机制63。
A.1. Self-Attention Mechanism
自注意力机制用于捕获单一序列内元素之间的关系。给定输入序列 X = ( x 1 , x 2 , . . . , x n ) X = (x_1, x_2, ..., x_n) X=(x1,x2,...,xn),其中 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd,自注意力的计算过程如下:
Q = X W Q , K = X W K , V = X W V Q = X W_Q, \quad K = X W_K, \quad V = X W_V Q=XWQ,K=XWK,V=XWV
其中 W Q , W K , W V ∈ R d × d k W_Q, W_K, W_V \in \mathbb{R}^{d \times d_k} WQ,WK,WV∈Rd×dk
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{Q K^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
在公式(22)中, A t t e n t i o n Attention Attention 表示缩放点积注意力, d k d_k dk 表示键向量的维度。多头自注意力机制是单头自注意力机制的变体,虽然形式上与公式(22)类似,但每个注意力头可以看作是从不同"视角"学习序列中元素之间的关系。这种引入增强了模型对未见数据的泛化能力。在后续章节中,我们将用 M S A ( ) MSA() MSA() 表示多头自注意力机制操作。
A.2. Cross-Attention Mechanism
跨注意力机制旨在捕获不同序列之间的交互。给定来自不同模态的两个输入序列 X = ( x 1 , x 2 , . . . , x n ) X = (x_1, x_2, ..., x_n) X=(x1,x2,...,xn) 和 Y = ( y 1 , y 2 , . . . , y n ) Y = (y_1, y_2, ..., y_n) Y=(y1,y2,...,yn),其中 x i ∈ R d x x_i \in \mathbb{R}^{d_x} xi∈Rdx 和 y j ∈ R d y y_j \in \mathbb{R}^{d_y} yj∈Rdy,跨注意力的计算过程如下:
Q = X W Q , K = Y W K , V = Y W V Q = X W_Q, \quad K = Y W_K, \quad V = Y W_V Q=XWQ,K=YWK,V=YWV
其中 W Q ∈ R d x × d k W_Q \in \mathbb{R}^{d_x \times d_k} WQ∈Rdx×dk, W K , W V ∈ R d y × d k W_K, W_V \in \mathbb{R}^{d_y \times d_k} WK,WV∈Rdy×dk
C r o s s A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V CrossAttention(Q, K, V) = softmax\left(\frac{Q K^T}{\sqrt{d_k}}\right)V CrossAttention(Q,K,V)=softmax(dk QKT)V
类似地,我们用 M C A ( ) MCA() MCA() 表示多头跨注意力机制操作。
A.3. Attention mechanism+Relative Positional Encoding
这是结合注意力机制和相对位置编码的增强注意力机制,能够同时捕获序列中元素的语义关系和相对位置关系。给定三个不同序列 X = ( x 1 , x 2 , . . . , x n ) X = (x_1, x_2, ..., x_n) X=(x1,x2,...,xn), Y = ( y 1 , y 2 , . . . , y n ) Y = (y_1, y_2, ..., y_n) Y=(y1,y2,...,yn) 和 Z = ( z 1 , z 2 , . . . , z n ) Z = (z_1, z_2, ..., z_n) Z=(z1,z2,...,zn),其中 x i ∈ R d x x_i \in \mathbb{R}^{d_x} xi∈Rdx,计算过程如下:
Q = X W Q , K = Y W K , V = Z W V Q = X W_Q, \quad K = Y W_K, \quad V = Z W_V Q=XWQ,K=YWK,V=ZWV
其中 W Q ∈ R d x × d k W_Q \in \mathbb{R}^{d_x \times d_k} WQ∈Rdx×dk, W K ∈ R d y × d k W_K \in \mathbb{R}^{d_y \times d_k} WK∈Rdy×dk, W V ∈ R d z × d k W_V \in \mathbb{R}^{d_z \times d_k} WV∈Rdz×dk
A t t e n t i o n R P E ( Q , K , V ) = s o f t m a x ( Q K T + R d k ) V AttentionRPE(Q, K, V) = softmax\left(\frac{Q K^T + R}{\sqrt{d_k}}\right)V AttentionRPE(Q,K,V)=softmax(dk QKT+R)V
其中 R R R 表示相对位置编码,用于建模元素之间的相对位置关系。具体计算方法如下:
定义以下量:
- 批次大小 B B B,注意力头数 h h h,嵌入维度 d i m dim dim,图像高度和宽度维度 H , W H, W H,W
- 输入掩码 M ∈ { 0 , 1 } B × H W M \in \{0,1\}^{B \times HW} M∈{0,1}B×HW,其中 M b , i = k e y − p a d d i n g − m a s k b , i = − M M_{b,i} = key-padding-maskb, i = -M Mb,i=key−padding−maskb,i=−M(重塑后)
- 查询矩阵 Q ∈ R ( B ⋅ h ) × ( d i m / h ) × H W Q \in \mathbb{R}^{(B \cdot h) \times (dim/h) \times HW} Q∈R(B⋅h)×(dim/h)×HW
- 键权重矩阵 W K ∈ R d i m × d i m W_K \in \mathbb{R}^{dim \times dim} WK∈Rdim×dim
首先计算行和列的累积位置:
y b , i , j = ∑ k = 1 j I b , i , k ∀ b ∈ 1 , B , i ∈ 1 , H , j ∈ 1 , H x b , i , j = ∑ k = 1 i I b , k , j ∀ b ∈ 1 , B , j ∈ 1 , W \begin{array}{c c c} {y_{b,i,j} = \sum_{k=1}^{j} I_{b,i,k}} & {\forall b \in 1,B, i \in 1,H, j \in 1,H} \\ {x_{b,i,j} = \sum_{k=1}^{i} I_{b,k,j}} & {\forall b \in 1,B, j \in 1,W} \end{array} yb,i,j=∑k=1jIb,i,kxb,i,j=∑k=1iIb,k,j∀b∈1,B,i∈1,H,j∈1,H∀b∈1,B,j∈1,W
位置差异:
Δ y = y : , j , : − y : , None , : ∈ R B × H W × H W Δ x = x : , : , None − x : , None , : ∈ R B × H W × H W \begin{array}{c l c r} {\Delta y = y_{:,j,:} - y_{:,\text{None},:} \in \mathbb{R}^{B \times HW \times HW}} \\ {\Delta x = x_{:,:,\text{None}} - x_{:,\text{None},:} \in \mathbb{R}^{B \times HW \times HW}} \end{array} Δy=y:,j,:−y:,None,:∈RB×HW×HWΔx=x:,:,None−x:,None,:∈RB×HW×HW
定义位置嵌入矩阵(可学习或固定):
D x ∈ R x _ r a n g e × ( d i m / 2 ) \mathcal{D}_x \in \mathbb{R}^{x\_range \times (dim/2)} Dx∈Rx_range×(dim/2)
通过键权重投影:
K y = P y W K : , d i m / 2 , : T ∈ R y _ r a n g e × d i m K x = D x W K d i m / 2 : , : T \begin{array}{l l} {\mathcal{K}_y = P_y W_K:, dim/2,:^T \in \mathbb{R}^{y\_range \times dim}} \\ {\mathcal{K}_x = D_x W_Kdim/2:,:^T} \end{array} Ky=PyWK:,dim/2,:T∈Ry_range×dimKx=DxWKdim/2:,:T
重塑并准备多头注意力:
H Σ ′ ⊂ R ( B ⋅ h ) × ( d i m / h ) × y _ r a n g e T Z ′ ⊂ R 1 × ( d i m / h ) × ( d i m / h ) × x _ r a n g e \begin{array}{l} {H_{\Sigma}' \subset \mathbb{R}^{(B \cdot h) \times (dim/h) \times y\_range}} \\ {TZ' \subset \mathbb{R}^{1 \times (dim/h) \times (dim/h) \times x\_range}} \end{array} HΣ′⊂R(B⋅h)×(dim/h)×y_rangeTZ′⊂R1×(dim/h)×(dim/h)×x_range
计算原始注意力分数:
A y r a w → ( R A y ′ T ) ≤ R ( B ⋅ h ) × H W × y _ r a n g e A x r a w → ( R A x ′ T ) ∝ R ( B ⋅ h ) × H W × x _ r a n g e \begin{array}{l} {\mathcal{A}_y^{raw} \rightarrow (R A_y' T) \leq \mathbb{R}^{(B \cdot h) \times HW \times y\_range}} \\ {\mathcal{A}_x^{raw} \rightarrow (R A_x' T) \propto \mathbb{R}^{(B \cdot h) \times HW \times x\_range}} \end{array} Ayraw→(RAy′T)≤R(B⋅h)×HW×y_rangeAxraw→(RAx′T)∝R(B⋅h)×HW×x_range
重塑并计算位置索引:
I y y = Δ y : , None , : , : + posindex Offset ∈ Z B × h × H W × H W I x x = Δ x : , None , : , : + posindex Offset ∈ Z B × h × H W × H W \begin{array}{l} {I_{yy} = \Delta y_{:,\text{None},:,:} + \text{posindex}\text{Offset} \in \mathbb{Z}^{B \times h \times HW \times HW}} \\ {I{xx} = \Delta x_{:,\text{None},:,:} + \text{posindex}_\text{Offset} \in \mathbb{Z}^{B \times h \times HW \times HW}} \end{array} Iyy=Δy:,None,:,:+posindexOffset∈ZB×h×HW×HWIxx=Δx:,None,:,:+posindexOffset∈ZB×h×HW×HW
收集最终位置注意力分数:
A y b , h , i , j = A y r a w b , h , i , I y y \[ b , h , i , j ] A x b , h , i , j = A x r a w b , h , i , I x x \[ b , h , i , j ] \begin{array}{l} {\mathbf{A}_yb,h,i,j = A_y^{raw}b,h,i,I_{yy}\[b,h,i,j]} \\ {\mathbf{A}_xb,h,i,j = A_x^{raw}b,h,i,I_{xx}\[b,h,i,j]} \end{array} Ayb,h,i,j=Ayrawb,h,i,Iyy\[b,h,i,j]Axb,h,i,j=Axrawb,h,i,Ixx\[b,h,i,j]
组合位置注意力分数:
R → ( A y + A x ) ⊆ R ( B ⋅ h ) × H W × H W \mathcal{R} \rightarrow (\mathcal{A}_y + \mathcal{A}_x) \subseteq \mathbb{R}^{(B \cdot h) \times HW \times HW} R→(Ay+Ax)⊆R(B⋅h)×HW×HW
Original Abstract: Visual Grounding (VG) aims to utilize given natural language queries to
locate specific target objects within images. While current transformer-based
approaches demonstrate strong localization performance in standard scene (i.e,
scenarios without any novel objects), they exhibit notable limitations in
open-vocabulary scene (i.e, both familiar and novel object categories during
testing). These limitations primarily stem from three key factors: (1)
imperfect alignment between visual and linguistic modalities, (2) insufficient
cross-modal feature fusion, and (3) ineffective utilization of semantic
prototype information. To overcome these challenges, we present Prototype-Aware
Multimodal Learning (PAML), an innovative framework that systematically
addresses these issues through several key components: First, we leverage ALBEF
to establish robust cross-modal alignment during initial feature encoding.
Subsequently, our Visual Discriminative Feature Encoder selectively enhances
salient object representations while suppressing irrelevant visual context. The
framework then incorporates a novel prototype discovering and inheriting
mechanism that extracts and aggregates multi-neighbor semantic prototypes to
facilitate open-vocabulary recognition. These enriched features undergo
comprehensive multimodal integration through our Multi-stage Decoder before
final bounding box regression. Extensive experiments across five benchmark
datasets validate our approach, showing competitive performance in standard
scene while achieving state-of-the-art results in open-vocabulary scene. Our
code is available at https://github.com/plankXie/PAML.
PDF Link: 2509.06291v1
部分平台可能图片显示异常,请以我的博客内容为准
